[PyTorch][chapter 44][时间序列表示方法3]
简介:
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单、高效,因此引起了很多人的关注。由于 word2vec 的作者 Tomas Mikolov
![[PyTorch][chapter 44][时间序列表示方法3]_第1张图片](http://img.e-com-net.com/image/info8/3831efca846345f9ae01238800ce07a8.jpg)
其主要知识点
![[PyTorch][chapter 44][时间序列表示方法3]_第2张图片](http://img.e-com-net.com/image/info8/50d33f638b504e479331a30406db775f.jpg)
目录:
- word2vec 基本思想
- Skip-gram
- cbow
- Hierarchical softmax
- Negative sampling
- Subsampling of Frequent words
一 word2vec 基本思想
1.1 语言模型基本思想:
句子中下一个词出现和前面的词是有关系的,所以可以使用前面的词预测下一个词
1.2 word2vec 基本思想:
句子中相近的词是有联系的,如下:
| 今天 |
早上 |
| 中午 |
|
| 晚上 |
Word2Vec 基本思想: 使用词来预测词
Skip-gram 基本思想: 使用中心词 预测 周围词
cbow 基本思想: 使用周围词 预测 中心词
二 Skip-gram
2.1 简介
使用中心词 预测 周围词
|
|
|
|
|
向量 |
|
| 我 |
今天 |
下午 |
打 |
羽毛球 |
词 |

![[PyTorch][chapter 44][时间序列表示方法3]_第3张图片](http://img.e-com-net.com/image/info8/128ba1e7a9b94d4ba64adebc7f3f9e83.jpg)
我们分别预测了
![]()
![]()
![]()
![]()
2.2 模型结构
![[PyTorch][chapter 44][时间序列表示方法3]_第4张图片](http://img.e-com-net.com/image/info8/3ae0ba8038c7455c861a8ed78c06df8d.jpg)
输入层:![]()
使用 one-hot 编码 的词向量
中心词矩阵![]() :最终通过训练得到的矩阵
:最终通过训练得到的矩阵
![]() (中心词向量)
(中心词向量)
矩阵的shape 【input size, output size】
下面softmax 公式中
隐藏层
![]()
其中权重系数矩阵
![]()
输出层
![]()
![[PyTorch][chapter 44][时间序列表示方法3]_第5张图片](http://img.e-com-net.com/image/info8/eeb3d7e7f0214947bded3833335f1035.jpg)
其中
周围词向量
中心词向量
例: 我们最后训练出来的W,用来代表该词向量
损失函数
![[PyTorch][chapter 44][时间序列表示方法3]_第6张图片](http://img.e-com-net.com/image/info8/59d03692d57546d7afb4142c98adb22a.jpg)
例1
![[PyTorch][chapter 44][时间序列表示方法3]_第7张图片](http://img.e-com-net.com/image/info8/ef4abb2d328a48c697617d553d2f9177.jpg)
三 CBOW(Continuous Bag-of-Word)
3.1 简介
利用周围词预测中心词
![[PyTorch][chapter 44][时间序列表示方法3]_第8张图片](http://img.e-com-net.com/image/info8/34de2e5d9ffd443eb0c27ad39f3eb6d8.jpg)
3.2 模型
![[PyTorch][chapter 44][时间序列表示方法3]_第9张图片](http://img.e-com-net.com/image/info8/3e15ae34cb02440d98c00fdd3163e237.jpg)
输入:
4个[v,1]的 One-hot 编码向量
![]()
乘以一个[v,d]矩阵得到4个【d,1】的向量
![]()
![]()
![]()
![]()
把4个向量加起来或者求平均值得到 上下文词向量![]()
该词也称为窗口内上下文词向量[d,1]
其中W的shape 为[v,d]
隐藏层:
![]()
![]() 还是按照 【input size, output size】
还是按照 【input size, output size】
输出层
![]()
损失函数:
![[PyTorch][chapter 44][时间序列表示方法3]_第10张图片](http://img.e-com-net.com/image/info8/e4731ddee4fa417c97152abed28c75d0.jpg)
四 hierarchical softmax
4.1 核心思想:
如下是一个skip-gram 模型
词向量的维度v都非常大,直接做softmax 计算量非常大.
把 softmax 计算转换为求解sigmod 计算,降低运算量。
跟原模型相比:
原来激活函数softmax 函数,现在改成了如下图
的层次sigmoid 结构
![[PyTorch][chapter 44][时间序列表示方法3]_第11张图片](http://img.e-com-net.com/image/info8/508fd041fa51457d8c01cdbad90f9085.jpg)
4.2 流程:
1: 构建Huffman 树
![[PyTorch][chapter 44][时间序列表示方法3]_第12张图片](http://img.e-com-net.com/image/info8/2942bdbd03b841c2906bf4dc1101cd94.jpg)
左分支概率<0.5,
右分支概率>0.5
比如skip-gram中我们要通过中心词求周围词I的概率
![[PyTorch][chapter 44][时间序列表示方法3]_第13张图片](http://img.e-com-net.com/image/info8/aade6d9fdb94430c814fe943b17292f0.jpg)
![[PyTorch][chapter 44][时间序列表示方法3]_第14张图片](http://img.e-com-net.com/image/info8/de32ed706ffe4a97a330f26a255ab05f.jpg)
4.3 : skip-gram 例子
![[PyTorch][chapter 44][时间序列表示方法3]_第15张图片](http://img.e-com-net.com/image/info8/1d8f16a3056241eba84167def08aa888.jpg)
其中:
![]()
代表: 当前的节点 是否为其父节点的右节点
如上图,I 为其父节点的左节点,所以取值为-1.
哈夫曼编码(Huffman Coding),又称霍夫曼编码,通过编码后把高频词放在上面,
低频词放下面,使得带权路径最短。
4.4 损失函数
因为最终输出值是一个概率,依然使用CrossEntroy 交叉熵作为损失函数模型
,通过反向传播,更新参数。
要注意的是训练的时候: 根据label 标签值 比如 001,决定分支路径,
计算当前的分支的概率值。
五: Negative sampling
这种方案是目前常用的,hierarchical softmax基本不用了
5.1 核心思想:
将多分类问题,变成二分类问题。
以skip-gram 为例:输入单词w,
从周围词 U中随机采样一个![]() 作为正标签
作为正标签
从所有词中随机采样3-10  个作为负标签
个作为负标签
正样本: [w,![]() ]
]
负样本: 【w,】
![[PyTorch][chapter 44][时间序列表示方法3]_第16张图片](http://img.e-com-net.com/image/info8/5ac382df62de475a8e3b520e86d94f2a.jpg)
5.2 损失函数
![[PyTorch][chapter 44][时间序列表示方法3]_第17张图片](http://img.e-com-net.com/image/info8/607006217f974ac8afdfe9ce3b73ebe6.jpg)
K 为随机采样的负样本个数,正常3-10个
5.3 如何采样
![]()
P(w) 是词w在数据集中出现的概率,
Z为归一化的参数,使得求解之后的概率和依旧为1.
作用: 增大频率小的抽样概率,减少频率大的抽样概率
例:
已知
P(a)=0.01
p(b)=0.99
则:
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 11 14:09:20 2023
@author: chengxf2
"""
import numpy as np
import random
def run():
pa = 0.01
pb = 0.99
power_a= np.power(pa,0.75)
power_b = np.power(pb,0.75)
z = power_a+power_b
pa = power_a/z
pb = power_b/z
print("\n pa: %4.2f"%pa, "\t pb:%4.2f "%pb)
def sampling():
# 定义概率分布
probabilities = [0.1, 0.2, 0.3, 0.4]
# 定义待抽样元素
elements = ['A', 'B', 'C', 'D']
# 使用 random.choices() 函数进行抽样
result = random.choices(elements, probabilities)
#print(result)
return result[0]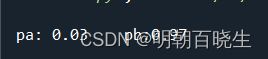
5.4 例子
以skip-gram 为例,中心词为 of
句子 It is a technically demanding piece of music to play.
| 正样本 |
负样本 |
| [of, music] |
[of ,play] |
| [of ,it] |
|
| [of ,is] |
|
| [of , technically ] |
5.5 CBOW 负采样
![[PyTorch][chapter 44][时间序列表示方法3]_第18张图片](http://img.e-com-net.com/image/info8/569f36c2b1474c818c8eabb02b33d45d.jpg)
六 Sub-sampling of Frequent words
6.1 简介
文档或者数据集中 高频词 往往携带的 信息较少。
例如 [the is a and ],而低频词 携带信息多。
例如:
搜索 “什么是青蛙”,
按照词频: “什么“ 词频最高
那匹配的结果应该是第一个,
实际上用户搜索的是第二个
![[PyTorch][chapter 44][时间序列表示方法3]_第19张图片](http://img.e-com-net.com/image/info8/b5564a8718cc4a8eb1550af11e45d14c.jpg)
6.2重采样的原因:
跟多训练重要词对,
例如训练 France 和 pairs 关系
比 训练 France 和 the 之间关系更重要
高频词很快就训练好了,而低频词需要跟多的轮次
6.3 方案:
![[PyTorch][chapter 44][时间序列表示方法3]_第20张图片](http://img.e-com-net.com/image/info8/a17c67883c51400d87b099e9b4c1b2ac.jpg) 比如:
比如:
![]() ,相对
,相对 ![]() ,
,![]() 删除概率更小
删除概率更小
高频单词,删除概率也高
参考:
NLP-baseline-word2vec补充2-2_哔哩哔哩_bilibili
层次softmax (hierarchical softmax)理解_BGoodHabit的博客-CSDN博客
层次softmax (hierarchical softmax)理解_BGoodHabit的博客-CSDN博客
word2vec原理及其Hierarchical Softmax优化_hierarchical softmax word2vec_编程密码的博客-CSDN博客