rust学习-所有权
运行程序必须管理使用内存的方式
(1)一些语言中具有垃圾回收机制,程序运行时不断寻找不再使用的内存
(2)一些语言中,开发者必须亲自分配和释放内存
(3)Rust 通过所有权系统管理内存。编译器在编译时会根据一系列的规则进行检查。在运行时,所有权系统的任何功能都不会减慢程序。
堆和栈的比较
栈中所有数据都必须占用已知且固定的大小
在编译时大小未知或大小可能变化的数据,要改为存储在堆上。
堆上分配内存(allocating on the heap),缺乏组织:当向堆放入数据时,内存分配器(memory allocator)在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer)。将指向堆内存的指针推入栈中,当需要实际数据时,必须访问栈上的指针。
入栈比在堆上分配内存要快,因为(入栈时)分配器无需为存储新数据去搜索内存空间;其位置总是在栈顶。
堆上分配内存则需要更多的工作,这是因为分配器必须首先找到一块足够存放数据的内存空间,并接着做一些记录为下一次分配做准备。
访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。处理器在处理的数据彼此较近的时候(比如在栈上)比较远的时候(比如可能在堆上)能更好的工作。在堆上分配大量的空间也可能消耗时间。
所有权系统的功能
跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上重复数据数量,以及清理堆上不再使用的数据确保不会耗尽空间,管理堆数据
(1)Rust 中的每一个值都有一个被称为 所有者(owner)的变量
(2)值在任一时刻有且只有一个所有者
(3)当所有者(变量)离开作用域,这个值将被丢弃
Rust:内存在拥有它的变量离开作用域后就被自动释放
Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何自动的复制可以被认为对运行时性能影响较小
String类型管理被分配到堆上的数据,所以能够存储在编译时未知大小的文本。下面以String为例来讲解。
变量与数据交互的方式(一):移动
仅拷贝栈上数据
错误代码,let s2 = s1 之后,Rust 认为 s1 不再有效
因此 Rust 不需要在 s1 离开作用域后清理任何东西
let s1 = String::from("hello");
let s2 = s1; // s2有了堆内存的管理权,s1丢失,不是简单的浅拷贝
println!("{}, world!", s1);

变量与数据交互的方式(二):克隆
拷贝栈上数据+堆上数据
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
仅栈上数据拷贝
像整型这样在编译时已知大小的类型被整个存储在栈上,所以拷贝实际值很快。没有理由在创建变量 y 后使 x 无效。这里没有深浅拷贝的区别
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
示例-所有权和函数
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里
// 这里s不再有效
// 在调用 takes_ownership 后使用 s 时,Rust 会抛出一个编译时错误
// 这些静态检查使我们免于犯错
let x = 5; // x 进入作用域
makes_copy(x); // x 应该移动函数里,
// 但 i32 是 Copy 的,所以在后面可继续使用 x
} // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走,所以不会有特殊操作
fn takes_ownership(some_string: String) { // some_string 进入作用域
println!("{}", some_string);
} // some_string 移出作用域并调用 `drop` 方法。占用的内存被释放
fn makes_copy(some_integer: i32) { // some_integer 进入作用域
println!("{}", some_integer);
} //some_integer 移出作用域。不会有特殊操作
示例-所有权和返回值
fn main() {
let s1 = gives_ownership(); // gives_ownership 将返回值移给 s1
let s2 = String::from("hello"); // s2 进入作用域
let s3 = takes_and_gives_back(s2); // s2 被移动到takes_and_gives_back 中
// 它也将返回值移给 s3
} // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,所以什么也不会发生。s1 移出作用域并被丢弃
fn gives_ownership() -> String { // gives_ownership 将返回值移动给调用它的函数
let some_string = String::from("yours"); // some_string 进入作用域
some_string // 返回 some_string 并移出给调用的函数
}
// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // 返回 a_string 并移出给调用的函数
}
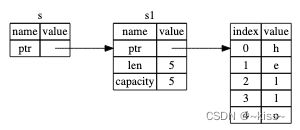
借用borrowing
函数使用一个值但不获取所有权
如果还要接着使用它的话,每次都传进去再返回来就有点烦人
fn main() {
// 变量默认不可变,引用也(默认)不允许修改引用的值
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
可变引用
在同一时间,只能有一个对某一特定数据的可变引用
带来的好处是Rust 可以在编译时避免数据竞争
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
错误代码
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
注,数据竞争由三个行为造成:
(1)两个或更多指针同时访问同一数据
(2)至少有一个指针被用来写入数据
(3)没有同步数据访问的机制
Rust避免数据竞争的方式是不会编译存在数据竞争的代码,牛逼
一个引用的作用域从声明的地方开始一直持续到最后一次使用
不能在拥有不可变引用的同时拥有可变引用
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
println!("{} and {}", r1, r2);
// 此位置之后 r1 和 r2 不再使用
let r3 = &mut s; // 没问题
println!("{}", r3);
上述r1r2和r3作用域没有重叠,代码可以编译。
编译器在作用域结束之前判断不再使用的引用的能力被称为非词法作用域生命周期(Non-Lexical Lifetimes,简称 NLL)
错误代码
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
let r3 = &mut s; // 大问题
println!("{}, {}, and {}", r1, r2, r3);
悬垂引用(Dangling References)
释放内存时保留指向它的指针而错误地生成一个悬垂指针,指向的内存可能已经被分配给其它持有者
Rust编译器确保引用永远也不会变成悬垂状态:当拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域。
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle 返回一个字符串的引用
let s = String::from("hello"); // s 是一个新字符串
&s // 返回字符串 s 的引用
} // 这里 s 离开作用域并被丢弃。其内存被释放。
// 危险!
解决方式
fn no_dangle() -> String {
let s = String::from("hello");
s
}
这样就没有任何错。所有权被移出,没有值被释放。
Slice
一个没有所有权的数据类型 slice
slice 允许你引用集合中一段连续的元素序列,而不用引用整个集合
字符串 slice(string slice)是 String 中部分值的引用
示例:接收一个字符串,并返回该字符串中的第一个单词
如果该字符串中并未找到空格,返回整个字符串。
// 将 s 参数的类型改为字符串 slice
fn first_word(s: &str) -> &str {
// as_bytes 方法将 String 转化为字节数组
let bytes = s.as_bytes();
// iter 方法在字节数组上创建一个迭代器
// enumerate 包装了 iter 的结果,将这些元素作为元组的一部分来返回
// i 是索引,&item是字符的不可变引用
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
println!("my_string={}", my_string);
// `first_word` 接受 `String` 的切片,无论是部分还是全部
let word = first_word(&my_string[0..6]);
println!("word={}", word);
let word = first_word(&my_string[..]);
println!("word={}", word);
// `first_word` 也接受 `String` 的引用,
// 这等同于 `String` 的全部切片
let word = first_word(&my_string);
println!("word={}", word);
let my_string_literal = "hello world";
println!("my_string_literal={}", my_string);
// `first_word` 接受字符串字面量的切片,无论是部分还是全部
let word = first_word(&my_string_literal[0..6]);
println!("word={}", word);
let word = first_word(&my_string_literal[..]);
println!("word={}", word);
// 因为字符串字面值**就是**字符串 slice,
// 这样写也可以,即不使用 slice 语法!
// 如果有一个 String,则可以传递整个 String 的 slice 或对 String 的引用
let word = first_word(my_string_literal);
println!("word={}", word);
}
字符串字面量被储存在二进制文件中
字符串字面量就是 slice
let s = "Hello, world!";
s 的类型是 &str:它是一个指向二进制程序特定位置的 slice
字符串字面量不可变;&str 是一个不可变引用
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];

总结
任意给定时间,要么只能有一个可变引用,要么只能有多个不可变引用
引用必须总是有效