【C#】并行编程实战:同步原语(1)
在第4章中讨论了并行编程的潜在问题,其中之一就是同步开销。当将工作分解为多个工作项并由任务处理时,就需要同步每个线程的结果。线程局部存储和分区局部存储,某种程度上可以解决同步问题。但是,当数据共享时,就需要用到同步原语。
因篇幅所限,本章为第1篇。本章主要介绍互锁操作、.NET中的内存屏障、锁原语。
本教程对应学习工程:魔术师Dix / HandsOnParallelProgramming · GitCode
1、关于同步原语
同步原语是基础平台(操作系统)提供的简单软件机制,它们有助于对内核进行多线程处理。同步原语在内部使用低级原子操作以及内存屏障(Memory Barrier),这意味着使用同步原语不必担心需要自己实现锁和内存屏障。
同步原语的一些常见示例是锁(Lock)、互斥锁(Mutex)、条件变量(Conditional Variable)和信号量(Semaphore)。.NET Framework 提供了一系列同步原语,大致分为以下5类:
-
互锁操作
-
锁
-
信号
-
轻量级同步类型
-
Spin Wait
2、互锁操作
互锁(Interlocked)的类封装了同步原语,并被用于为线程间共享的变量提供原子操作(Atomic Operation)。另外,Interlocked 类提供诸如 Increment、Decrement、Add、Exchange 和 CompareExchange 之类的方法。代码示例如下:
private void RunAddValue()
{
TestValue = 0;
var task = Task.Run(() =>
{
var ret = Parallel.For(0, 1000, async x =>
{
await Task.Delay(x);
TestValue++;//理论上执行1000次,应该结果是1000;
});
});
}这里没有使用同步原语,TestValue 是我在属性面板上显示的值。那么点击运行后,等待一段时间,结果如下:
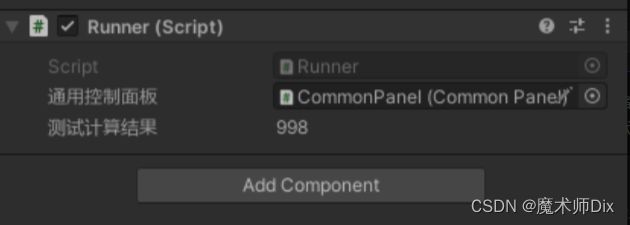
这个值就不确定了,有时是998,有时是995或者其他的值,但总之都与期望值不匹配。这个原因就是线程竞争了,就是说两个线程同时在写入导致异常。要解决这个问题也很简单,代码修改如下:
TestValue++;//不考虑线程安全,结果可能不是1000
Interlocked.Increment(ref SafeTestValue);//线程安全,结果总是1000这里我们加了一个值来显示差异:
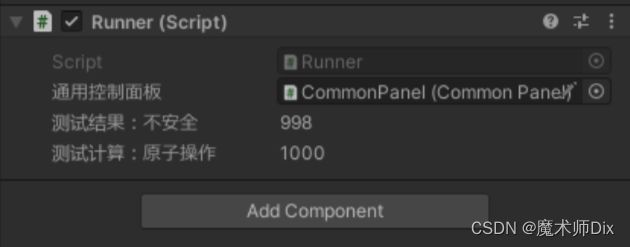
在完成计数时,可以看到原子操作的值总是为 1000 , 而默认的方法不总是期望值。
当然,Interlocked 类里还有很多别的操作,这里我认为就是按需要进行 API 调用即可,不需要再额外写代码示例了,大家可以参考以下资料学习:
Interlocked 类 (System.Threading) | Microsoft Learn为多个线程共享的变量提供原子操作。 https://learn.microsoft.com/zh-cn/dotnet/api/system.threading.interlocked?view=netstandard-2.1#methods
https://learn.microsoft.com/zh-cn/dotnet/api/system.threading.interlocked?view=netstandard-2.1#methods
3、.NET 中的内存屏障
在单核处理器上,只有一个线程获得 CPU 分片,而其他线程等待。这样当线程访问内存时,其顺序都是正确的,该模型称为顺序一致模型(Sequential Consistency Model)。
多核处理器上,多个线程同时运行,系统中不能保证顺序一致,因为硬件或即时编译器(Just In Time,JIT)都可能会重新排序内存指令以提高性能。此外,处于提升缓存性能、负载推测(Load Speculation)或延迟存储操作等目的,也可能会对内存指令进行重新排序。
出于性能考虑,当编译器遇到加载和存储语句时,它们并不总是以与编写时相同的顺序执行,而会对它们进行重新排序。
3.1、重新排序
对于内存模型较弱的多核处理器(如 Intel Itanium 处理器),代码重新排序是以一个问题。但对于顺序一致模型,在单核情况下是没有影响的。
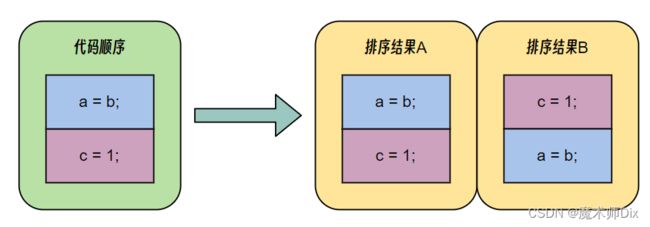
对于同一段代码,其在不同运行环境下,其排序结果可能是不同的。
这里为了说明,我们上一段示例代码:
private static int TestValueA;
private static int TestValueB;
private static bool m_IsFinishOnce;
public static void RunTestAddFunction()
{
TestValueA = 0;
TestValueB = 0;
Task.Run(() =>
{
Parallel.For(0, 10000, x =>
{
TestValueA = x;
TestValueB = x;
m_IsFinishOnce = TestValueA >= TestValueB;
});
});
}
public static void DebugResult()
{
Task.Run(() =>
{
Parallel.For(0, 10000, x =>
{
if (!m_IsFinishOnce)
{
Debug.LogError($"值不对了:{TestValueA} >= {TestValueB} = {m_IsFinishOnce}");
}
});
Debug.Log("测试完成");
});
}按照道理来讲,m_IsFinishOnce 应该一直为true才对,毕竟我们这段代码,A、B都是同时赋值的。当我们多线程运行的时候,却发现情况并非如此:
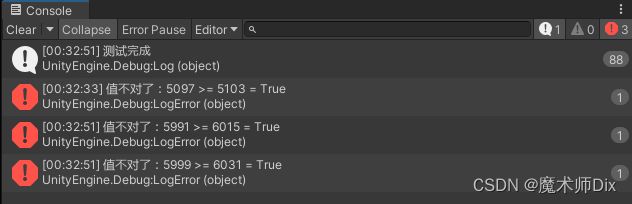
多次测试中,偶尔会发生一两次 A B 的值并不相等的情况。而 m_IsFinishOnce 的值,前一行还为 false,后一行就为 true 了(这其实在多线程编程中很常见)。我觉得可能的解释就是这段代码进行重新排序了,并不是严格按照 赋值A → 赋值B → 判定相等的顺序执行的。
当然,上述代码也有另一种情况:
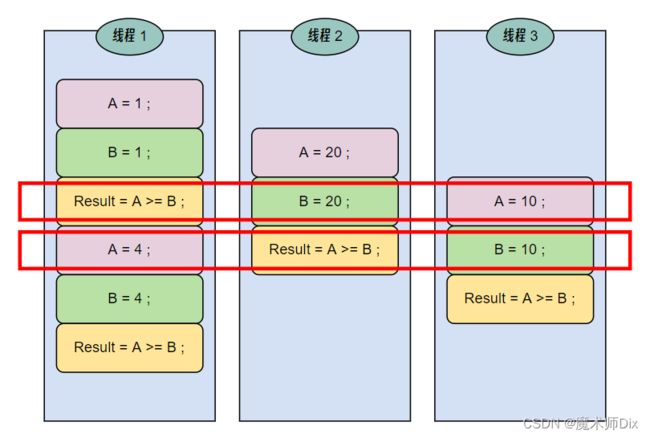
多线程操作中,虽然每次代码排序是正确的,但是由于多个线程在同时写入,导致读取时拿不到正确的值(如红框中所示)。总之上述的代码就是错误的多线程操作代码,这里只是为了演示。
3.2、内存屏障的类型
内存屏障的意义在于确保屏障之上和之下的任何代码语句都不会越过屏障,从而强制保证代码顺序。内存屏障有以下 3 种类型:
-
存储(写入)内存屏障:不让存储操作跨屏障移动
-
加载(读取)内存屏障:不让加载操作跨屏障移动
-
全能型内存屏障(Full Memory Barrier):不让存储和加载操作跨屏障移动
C# 的 Interlocked.MemoryBarrier() 就是一种全能型内存屏障:
Interlocked.MemoryBarrier 方法 (System.Threading) | Microsoft Learn按如下方式同步内存存取:执行当前线程的处理器在对指令重新排序时,不能采用先执行 MemoryBarrier() 调用之后的内存存取,再执行 MemoryBarrier() 调用之前的内存存取的方式。https://learn.microsoft.com/zh-cn/dotnet/api/system.threading.interlocked.memorybarrier?source=recommendations&view=netstandard-2.1 而 Interlocked.MemoryBarrierProcessWide 则是一种进程范围和系统范围的内存屏障。
Interlocked.MemoryBarrierProcessWide 方法 (System.Threading) | Microsoft Learn提供覆盖整个过程的内存屏障,确保来自任何 CPU 的读写都不能越过该屏障。https://learn.microsoft.com/zh-cn/dotnet/api/system.threading.interlocked.memorybarrierprocesswide?view=netstandard-2.1
3.3、避免使用构造对代码进行重新排序
书上这一章节,说实话没有看懂。书上说要使用内存屏障避免操作越过屏障,但是我使用时并没有感觉到有什么明显变化…… 3.1的示例代码我尝试了很多方式,并不能实现保证执行顺序。
只是书上提到,尽量不要用 Thread.MemoryBarrier ,而用 Interlocked.MemoryBarrier 代替。
我想的是,可能在一些追求性能的无锁代码,会使用内存屏障,而在关键位置还是要用锁。当然也可能是我这里没有正确使用内存屏障。如果后面研究结果下来,内存屏障的正确用法,我会补充在这里。如果内存屏障不是重要知识点,就忽略这一章。
4、锁原语
锁可用于限制对受保护资源的访问,使受保护的资源尽可以被单个现场或一组线程访问。当锁应用于共享资源时,需要执行以下步骤:
-
一个线程或一组线程通过获取锁来访问共享资源。
-
其他无法访问锁的线程进入等待状态。
-
一旦有线程释放了锁,另一个线程就会获取该锁,并开始执行。
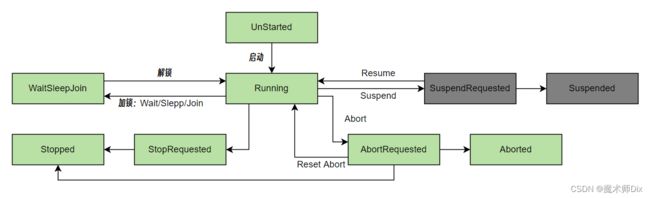
4.1、线程状态
在线程的生命周期的任何时候,都可以使用该线程的 ThreadState 属性来查询线程状态:
ThreadState 枚举 (System.Threading) | Microsoft Learn指定 Thread 的执行状态。https://learn.microsoft.com/zh-cn/dotnet/api/system.threading.threadstate?view=netstandard-2.1#-- 简单介绍如下:
namespace System.Threading
{
[Flags]
public enum ThreadState
{
Running = 0,//运行中
StopRequested = 1,//等待停止
SuspendRequested = 2,//已调用 Suspend 方法被请求挂起
Background = 4,//后台线程
Unstarted = 8,//未启动
Stopped = 16,//已停止
WaitSleepJoin = 32,//通过调用 Wait、Sleep、Join方法,导致该线程阻塞
Suspended = 64,//已挂起
AbortRequested = 128,//调用 Abort 方法,但是尚未终止,而是等待 ThreadAbortException 终止线程
Aborted = 256//已终止
}
}各个状态的切换关系如下:
4.2、阻塞与自旋
阻塞的线程在指定时间内放弃了处理器的时间片,这样,处理器的时间片就可以用于其他线程以提高性能。但是,这也增加了上下文切换的开销。因此,在线程会阻塞相当长的时间的时间才意义。
如果等待时间很短,则在不放弃处理器时间片的情况下进行自旋是很有意义的。例如写个死循环用于检查工作进度,虽然浪费了处理器时间,但如果等待时间不是很长,仍然可以显著提高性能。
(未完待续)
本教程对应学习工程:魔术师Dix / HandsOnParallelProgramming · GitCode