【视图与索引】
数据库视图与索引
-
- 1.视图
-
- 1.1视图介绍
- 1.2优点
- 1.3对视图的操作
- 2.索引
-
- 2.1 索引介绍
- 2.2索引的优缺点
- 2.3索引的分类
- 2.4索引的设计原则
- 2.5索引的创建
-
- 2.5.1.创建普通索引
- 2.5.2创建唯一索引
- 2.5.3创建全文索引
- 2.5.4创建单列索引
- 2.5.5创建多列索引
- 2.5.6创建空间索引
- 2.6MySQL使用场景
- 2.7SQL如何使用索引
- 2.8聚簇索引和非聚簇索引
1.视图
1.1视图介绍
数据库中的视图是一个虚拟表。同真实地表格一样,包含一系列带有名称的行和列数据。行和列数据来自由定义视图查询所引用的表,并且在引用视图时,动态生成。
视图是一个虚拟表,是从数据库中的一个或多个表中导出来的表。它可以从已经存在的视图的基础上定义。一旦定义后便存储在数据库中,与其对应的数据并没有像表那样在数据库中再存储一份,通过视图看到的数据知识放在基本表中的数据。对视图的操作与对表的操作一样,可以查询、修改、删除。当通过视图看到的数据进行变化时,相应的基本表中的数据也要发生变化;同时,若基本表的数据发生变化,则这种变化会自动反映到视图中。
1.2优点
1.简单化
视图不仅可以简化用户对数据的理解,也可以简化
它们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必
为以后的操作每次指定全部的条件。
2.安全性
通过视图用户只能查询和修改他们所能见到的数据。数据库中的其他数
据则既看不见也取不到。数据库授权命令可以使每个用户对数据库的检索限
制到特定的数据库对象上,但不能授权到数据库特定行和特定的列上。通过
视图,用户可以被限制在数据的不同子集上:
(1)使用权限可被限制在基表的行的子集上。
(2)使用权限可被限制在基表的列的子集上。
(3)使用权限可被限制在基表的行和列的子集上
(4)使用权限可被限制在多个基表的连接所限定的行上。
(5)使用权限可被限制在基表中的数据的统计汇总上。
(6)使用权限可被限制在另一视图的一个子集上,或是一些视图和基
表合并后的子集上。
3.逻辑数据独立性
视图可帮助用户屏蔽真实表结构变化带来的影响。
1.3对视图的操作
#创建视图;
create view v_sanguo as select * from sanguo where id <10;
select * from v_sanguo;
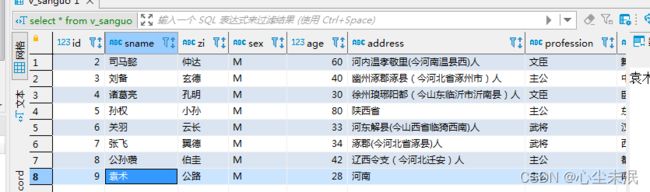
#修改视图,若视图存在则覆盖原视图;括号内的为对应列的视图名称;
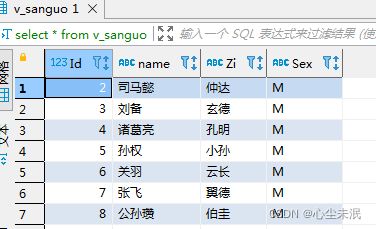
create or replace view v_sanguo(Id,name,Zi,Sex)
as select id,sname,zi,sex from sanguo where id < 9;
alter view v_sanguo(hao,nm,zihao,xing)
as select id,sname,zi,sex from sanguo where id<4;

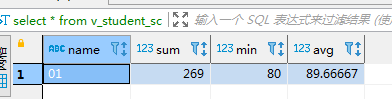
#将两张表进行联合创建视图;
create view v_student_sc (name,sum,min,avg)
as select student.SId,sum(score),min(score),avg(score) from student,sc
where student.SId = sc.SId and student.SId = '01' group by sc.SId;
select * from v_student_sc;
#删除视图;
drop view v_student;
#查看视图的详细结构;
show create view v_student_sc;

2.索引
2.1 索引介绍
索引是一种特殊的数据库结构,可以用来快速查询数据库表中的特定记录。索引是提高数据库性能的重要方式。MySQL中,所有的数据类型都可以被索引。MySQL的索引包括普通索引、惟一性索引、全文索引、单列索引、多列索引和空间索引等。
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
模式(schema)中的一个数据库对象 在数据库中用来加速对表的查询 通过使用快速路径访问方法快速定位数据,减少了磁盘的I/O 与表独立存放,但不能独立存在,必须属于某个表 由数据库自动维护,表被删除时,该表上的索引自动被删除。 索引的作用类似于书的目录,几乎没有一本书没有目录,因此几乎没有一张表没有索引。
2.2索引的优缺点
优点:
(1)通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
(2)可以大大加快数据的查询速度,这也是创建索引的主要原因。
(3)在实现数据的参考完整性方面,可以加速表和表之间的连接。
(4)在使用分组和排序子句进行数据查询时,也可以显著减少查询中 分组和排序的时间。
缺点:
(1)创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费 的时间也会增加。
(2)索引需要占磁盘空间,除了数据表占数据空间之外,每一个索引 还要占一定的物理空间,如果有大量的索引,索引文件可能比数据文件更快 达到最大文件尺寸。
(3)当对表中的数据进行增加、删除和修改的时候,索引也要动态地 维护,这样就降低了数据的维护速度。
2.3索引的分类
索引分为聚簇索引和非聚簇索引两种,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引不一样;聚簇索引能够提高多行检索的速度,非聚簇索引对于单行的检索很快;
MySQL的索引分为以下几条:
1.普通索引和唯一索引
普通索引是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值。
唯一索引要求索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须是唯一的。主键索引是一种特殊的唯一索引,它不允许为空。
2.单列索引和组合索引
单列索引也就是一个索引只包含一列,一个表可以有多个单列索引。
所谓组合索引就是指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合。
3.全文索引
全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在char,varchar或者text类型的列上创建。MySQL中只有MyISAM存储引擎支持全文索引。
4.空间索引
空间索引是空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY,POINT,LINESTRING和POLYGON。MySQL中使用SPATAL关键字进行扩展,使得能够用创建正规索引类似的语法创建空间索引。创建空间索引的列,必须将其声明为not null,空间索引只能在存储引擎为MyISAM的表中创建。
2.4索引的设计原则
1.选择唯一性索引;
2.为经常需要排序。分组和联合操作的字段建立索引;
3.为常作为查询条件的字段建立索引;
4.限制索引的数目;
5.尽量使用数据量较少的索引;
6.尽量使用前缀来索引;
7.删除不再使用或者使用很少的索引;
8.索引并非越多越好,一个表中若存在大量的索引,不仅会占用磁盘空间,还会影响增删改查的性能,因为在数据更新时,索引也会进行调整和更新。
2.5索引的创建
2.5.1.创建普通索引
CREATE INDEX stu_index ON student(Sname(10));
#通过下面语句查看表的索引;
SHOW INDEX FROM student;

#也可以在创建表的时候创建索引,代码如下:
create table index_name(
Id int,
Name varcahr(40),
Sex boolean,
index(Id);
#修改表结构的时候添加索引
alter table table_name ADD INDEX index_name (column_name(length));
ALTER TABLE course ADD INDEX index_name (TId(10));
#查询索引
show index from course;

# 删除索引 DROP INDEX index_name ON table
drop index index_name on course;
2.5.2创建唯一索引
Create table index2( Id int unique, Name varchar(20), Unique index index2_id(Id asc) );
2.5.3创建全文索引
2.5.4创建单列索引
create table index4(
id int,
subject varchar(40),
index index4_name(subject(10))
);
2.5.5创建多列索引
create table index5(
id int,
name varchar(40),
sex char(2),
index index5_name(name,sex)
);
2.5.6创建空间索引
create table index6(
id int,
sapce geometry not null,
Spatial index index_sp(space)
)engine=myisam;
2.6MySQL使用场景
(1).快速查找符合where条件的记录;
(2).快速确定候选集,如果where字句使用了多个索引字段,则MySQL会优先使用能使候选集记录规模最小的那个索引,便于尽快淘汰不符合条件的记录;
(3) 如果表中存在几个字段构成的联合索引,则查找记录时,这个联合索引的最左前缀匹配字段也会被自动作 为索引来加速查找。
(4)多表做join操作时会使用索引(如果参与join的字段在这些表中均建立了索引的话)。
(5)若某字段已建立索引,求该字段的min()或max()时,MySQL会使用索引
(6)对建立了索引的字段做sort或group操作时,MySQL会使用索引
2.7SQL如何使用索引
- B-Tree可被用于sql中对列做比较的表达式,如=, >, >=, <, <=及between操作
- 若like语句的条件是不以通配符开头的常量串,MySQL也会使用索引。 比如,SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%'或SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%'可以利用索引,而SELECT * FROM tbl_name WHERE key_col LIKE ‘%Patrick%’(以通配符开头)和SELECT * FROM tbl_name WHERE key_col LIKE other_col(like条件不是常量串)无法利用索引。 对于形如LIKE '%string%'的sql语句,若通配符后面的string长度大于3,则MySQL会利用Turbo Boyer-Moore algorithm算法进行查找.
- 若已对名为col_name的列建了索引,则形如"col_name is null"的SQL会用到索引。
- 对于联合索引,sql条件中的最左前缀匹配字段会用到索引。
- 若sql语句中的where条件不只1个条件,则MySQL会进行Index Merge优化来缩小候选集范围
2.8聚簇索引和非聚簇索引
。。。。