文字识别方法全面整理

来源:https://zhuanlan.zhihu.com/p/65707543
作者:白裳
本文来自知乎专栏,仅供学习参考使用,著作权归作者所有。如有侵权,请私信删除。
文字识别也是目前CV的主要研究方向之一。本文主要总结目前文字识别方向相关内容,包括单独文字识别以及结合文字检测和文字识别的端到端的文字识别。希望这篇文章能够帮助各位。
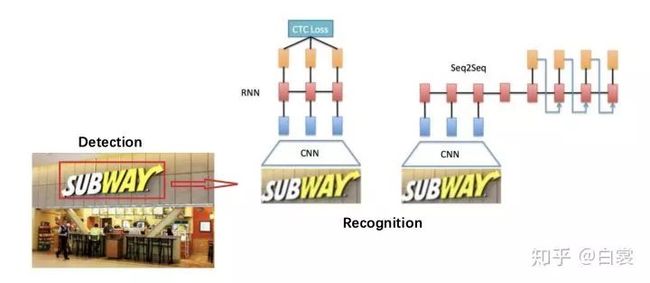
图0 文字检测Detection与文字识别Recognition
对于文字识别,实际中一般首先需要通过文字检测定位文字在图像中的区域,然后提取区域的序列特征,在此基础上进行专门的字符识别。但是随着CV发展,也出现很多端到端的End2End OCR。
文字检测(Text Detection)
文字检测定位图片中的文本区域,而Detection定位精度直接影响后续Recognition结果。

图1.1
如图1.1中,红框代表“LAN”字符ground truth(GT),绿色框代表detection box。在GT与detection box有相同IoU的情况下,识别结果差异巨大。所以Detection对后续Recognition影响非常大!
目前已经有很多文字检测方法,包括:
EAST/CTPN/SegLink/PixelLink/TextBoxes/TextBoxes++/TextSnake/MSR/...
其中CTPN方法的介绍如下:
场景文字检测—CTPN原理与实现:https://zhuanlan.zhihu.com/p/34757009
文字识别(Text Recognition)
识别水平文本行,一般用CRNN或Seq2Seq两种方法(欢迎移步本专栏相关文章):
CRNN:CNN+RNN+CTC
一文读懂CRNN+CTC文字识别:https://zhuanlan.zhihu.com/p/43534801
CNN+Seq2Seq+Attention
Seq2Seq+Attention原理介绍:https://zhuanlan.zhihu.com/p/51383402
对应OCR代码如下(不支持提问,没有任何support,谢谢)
https://github.com/bai-shang/crnn_seq2seq_ocr_pytorch
对于特定的弯曲文本行识别,早在CVPR2016就已经有了相关paper:
Robust Scene Text Recognition with Automatic Rectification. CVPR2016.
arxiv.org/abs/1603.03915
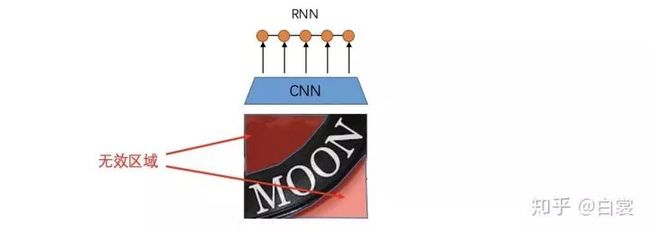
图2.1
对于弯曲不规则文本,如果按照之前的识别方法,直接将整个文本区域图像强行送入CNN+RNN,由于有大量的无效区域会导致识别效果很差。所以这篇文章提出一种通过STN网络学习变换参数,将Rectified Image对应的特征送入后续RNN中识别。
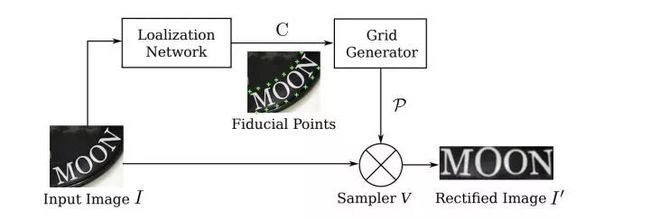
图2.2
其中Spatial Transformer Network(STN)指:
arxiv.org/abs/1506.02025
核心就是将传统二维图像变换(如旋转/缩放/仿射等)End2End融入到网络中。具体二维图像变换知识请翻阅:
Homograph单应性从传统算法到深度学习:
https://zhuanlan.zhihu.com/p/74597564
Scene Text Recognition from Two-Dimensional Perspective. AAAI2018.
该篇文章于MEGVII 2019年提出。首先在文字识别网络中加入语义分割分支,获取每个字符的相对位置。
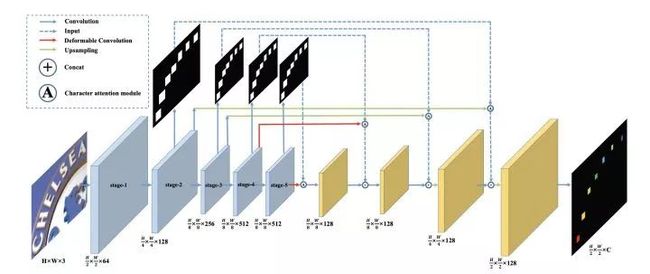
图2.4
其次,在获取每个字符位置后对字符进行分类,获得文字识别信息。该方法采用分类解决识别问题,并没有像传统方法那样使用RNN。

图2.5
除此之外,在文章中还是使用了Deformable Convolution可变形卷积。相比传统3x3卷积,可变形卷积可以提取文字区域不同形状的特征。

图2.6
SqueezedText: A Real-time Scene Text Recognition by Binary Convolutional Encoderdecoder Network. AAAI2018.
https://ren-fengbo.lab.asu.edu/sites/default/files/16354-77074-1-pb.pdf
该文章引入二值层(-1 or +1)部分替换CRNN中的float浮点卷积,核心是使用很小的网络进行识别。
Handwriting Recognition in Low-resource Scripts using Adversarial Learning. CVPR2019.
arxiv.org/pdf/1811.01396.pdfESIR: End-to-end Scene Text Recognition via Iterative Image Rectification. CVPR2019.
http:openaccess.thecvf.com/content_CVPR_2019/papers/Zhan_ESIR_End-To-End_Scene_Text_Recognition_via_Iterative_Image_Rectification_CVPR_2019_paper.pdf
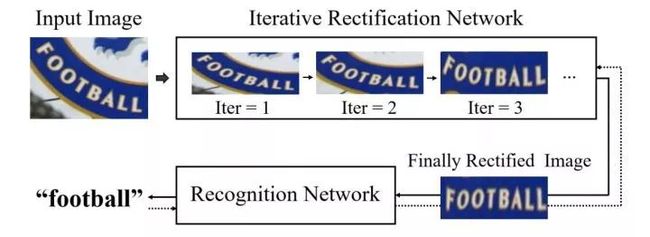
图2.7
ESIR采用cascade R-CNN级联思路,通过3次变换将弯曲字符变换为水平,再经过LSTM识别。具体变换思路请查阅论文。
End2End OCR (Detection+ Recognition)
由于End2End OCR同时涉及文字检测+文字识别两个方向,对于不熟悉的读者建议首先阅读上述CTPN/CRNN/Seq2Seq三篇文章了解相关内容(当然求点赞喽)。在之前介绍的算法中,文字检测和文字识别是分为两个网络分别完成的,所以一直有研究希望将OCR中的Detection+ Recognition合并成一个End2End网络。目前End2End OCR相关研究如下:
Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks. ICCV2017.
http:openaccess.thecvf.com/content_ICCV_2017/papers/Li_Towards_End-To-End_Text_ICCV_2017_paper.pdf
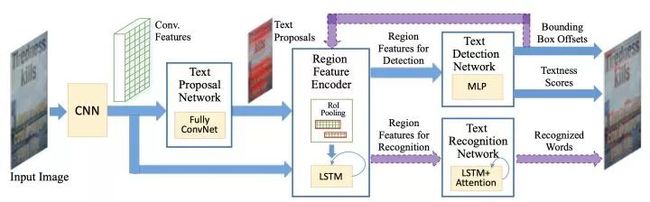
图3.1
该篇文章采用Faster R-CNN的Two-stage结构:首先Text Proposal Network(即RPN)生成对应的文本区域Text Proposal,后续通过Bounding Box regression和Box Classification进一步精修文本位置。但是不同的是,在RoI Pooling后接入一个LSTM+Attention的文字识别分支中,如图3.2。由于识别与之前介绍的文字识别方法大同小异,后续不再重复介绍。
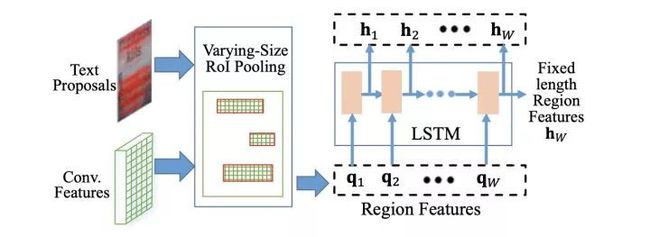
图3.2
但是这样的结构存在问题。举例说明:Faster R-CNN的RPN只是初步产生Proposal,后续还需要再经过一次Bounding Box regression才能获取准确的检测框,该问题在CTPN论文(arxiv.org/abs/1609.03605)中有说明,如图3.3:

图3.3 CTPN文章中提及RPN生成Proposal不准的问题
所以Text Proposal不一定很准会对后续识别分支产生巨大影响,导致该算法在复杂数据集上其实并不是很work。
Deep TextSpotter: An End-to-End Trainable Scene Text Localization and Recognition Framework. ICCV2017.
http:openaccess.thecvf.com/content_ICCV_2017/papers/Busta_Deep_TextSpotter_An_ICCV_2017_paper.pdf
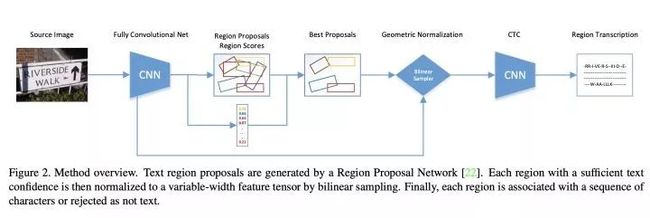
图3.4 Deep TextSpotter
在与Faster R-CNN不同,Deep TextSpotter生成的Region Proposal包含6个数值: 其中 代表Proposal box在图像中的位置, 代表Proposal box与水平方向的夹角, 代表置信度confidence。 对于Region Proposal所在的特征 ,通过双线性插值可以获得 固定高度的变换后的特征 , 其中 代表双线性采样核,本质就是传统的图像旋转+缩放插值变换。

图3.5
在获得 后,显然可以后接RNN+CTC进行识别。可以看到Deep TextSpotter通过学习角度 ,将proposal通过双线性插值变换为固定高度的水平特征,然后再进行识别,达到一种End2End的效果。与同时期的上一个方法类似,同样存在RPN生成Proposal不准导致识别率低的问题,所以在复杂数据集实际效果可能并不是太好。
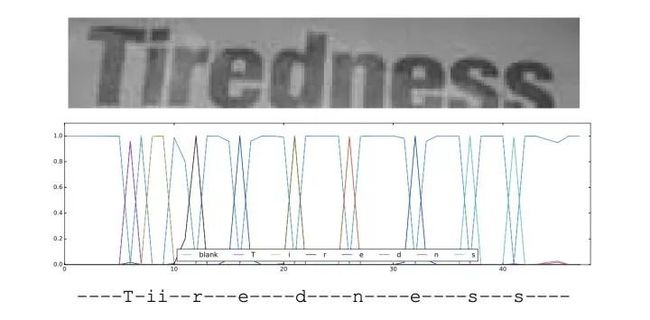
图3.6 Deep TextSpotter对应的CTC识别
Attention-based Extraction of Structured Information from Street View Imagery. ICDAR2017.
arxiv.org/abs/1704.03549
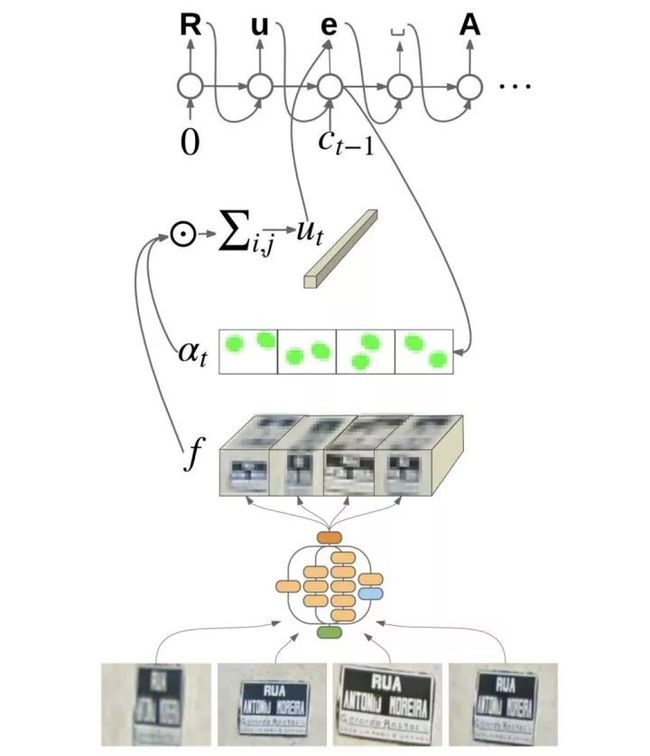
图3.7 spatial attention ocr
该文章由Google在2017年提出,主要针对多视角的街景采集数据进行OCR,其关键点为:
利用CNN提取不同视角的图片的特征,并将特征concat为一个大的特征矩阵
计算图片中文的spatial attention , 越大该区域为文字区域的概率越大
通过 抽取 中文字区域特征 ,并送入后续RNN进行识别
该方法利用spatial attention(arxiv.org/pdf/1502.03044v3.pdf)进行端到端OCR,相比检测+检测方法更加新颖。
Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes. ECCV2018.
arxiv.org/abs/1807.02242
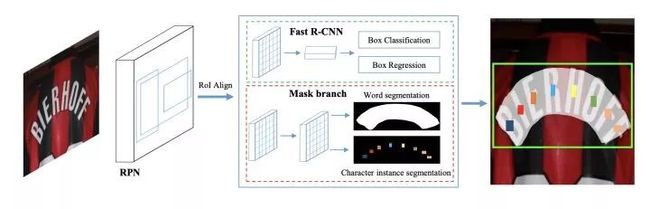
图3.8 Mask TextSpotter
该方法由旷视科技 (www.zhihu.com/people/c26b4202ed6af1379f52a967235d94b2) 在2018年提出,主要用于解决不规则弯曲字符End2End的识别问题。相比倾斜字符,处理弯曲不规则字符更难,无法简单通过Proposal角度 对特征进行变换。Mask TextSpotter借鉴了Mask RCNN,首先由RPN网络生成Proposal,再由Faster R-CNN分支对Proposal做进一步分类和位置回归,同时通过Mask分支分割出文本所在区域Global word map和每个字符所在中心Background map。这样不仅可以获得整个文本word区域,还可以获得每个字符character区域。
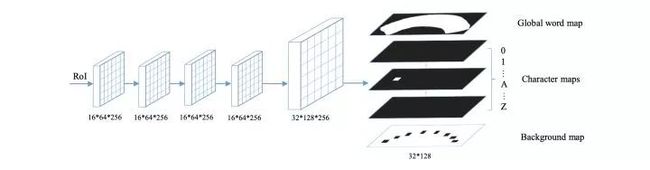
图3.9 Mask TextSpotter进行文字识别
在文字识别方面Mask TextSpotter设计0~1和A~Z共计36个“one-hot”形式的Character map进行分类,即没有使用RNN直接强行分类。如果用Mask TextSpotter识别汉字,则需要设计4000+ Character map,这显然是不科学的。另外该方法在识别过程中也没有用到文字的序列信息(总体来说该方法与之前的Scene Text Recognition from Two-Dimensional Perspective思路类似)。
Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline. ECCV2018.
http:openaccess.thecvf.com/content_ECCV_2018/papers/Zhenbo_Xu_Towards_End-to-End_License_ECCV_2018_paper.pdf
在该文章中提出一个包含250k图的中国车牌数据集CCPD,每个标注包含1个box+4个定位点+识别文字GT:

图3.10 车牌数据集CCPD
在网络方面该文章提出一种PRNet:
利用Box Regression layer层预测车牌位置 ;
检测出来 确定位置后,采集对应不同尺度的特征图进行ROI Pooling;
把不同尺度特征拼接在一起,进行识别。
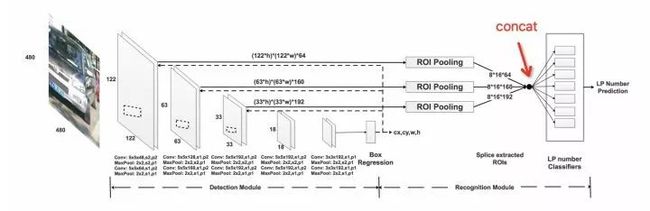
图3.11 PRNet
该文章核心内容就是推出了一个车牌OCR数据集CCPD,并在这个数据集上提出一种BaseLine方法。该方向研究人员可以尝试使用该数据集。
在这里特别感谢一下所有开放数据集的研究人员!数据才是cv第一生产力!
An end-to-end TextSpotter with Explicit Alignment and Attention. CVPR2018.
http:openaccess.thecvf.com/content_cvpr_2018/papers/He_An_End-to-End_TextSpotter_CVPR_2018_paper.pdf

图3.12
改文章与Deep TextSpotter比较类似,首先生成带有角度 的倾斜Text Proposal,然后通过类似于RoI Pooling的Text-alignment提取固定长度的feature sequence,再送入RNN+Seq2Seq+Attention结构进行识别。

图3.13
与Deep TextSpotter不同的是,Text-alignment在通过双线性插值提取到整个Proposal特征后,再通过一组Inception卷积获取feature sequence送入RNN,而不是直接把双线性插值结果送入RNN。

图3.15
FOTS: Fast Oriented Text Spotting with a Unified Network. CVPR2018.
arxiv.org/abs/1801.01671
FOTS采用Single-Shot结构结合(arxiv.org/abs/1612.03144)直接检测文字区域,输出带角度 的Bounding Box;之后利用双线性插值RoIRotate获取固定大小的特征,送入双向LSTM进行识别。

图3.16 FOTS Architecture

图3.17 FPN

图3.18 RoIRotate
由于使用Single-Shot结构,所以应该是相对“Fast”一点。
SEE: Towards Semi-Supervised End-to-End Scene Text Recognition. AAAI2018.
arxiv.org/abs/1712.05404

图3.19

图3.20
另外SEE作者2017年在arXiv上放出STN-OCR的论文,应该是没有中任何会议。考虑到完整性也挂在这里。
arxiv.org/abs/1707.08831
—— END ——
![]()

“哪吒头”—玩转小潮流