Python语言
文章目录
- Python基础
-
- 1. 计算机组成原理和Python基础
-
- 1.1 计算机组成原理
- 1.2 编程语言和Python
- 1.3 注释
- 1.4 PEP 8 规范
- 1.5 变量以及类型
-
- 1.5.1 变量定义
- 1.5.2 变量类型
- 1.6 标识符和关键字
-
- 1.6.1 命名规则
- 1.6.2 命名规范
- 1.6.3 关键字
- 1.7 输出
-
- 1.7.1 格式化输出
- 1.7.2 print 函数
- 1.8 输入
- 1.9 数据类型的转换
- 1.10 运算符
-
- 1.10.1 算数运算符
- 1.10.2 赋值运算符
- 1.10.3 复合赋值运算符
- 1.10.4 比较运算符
- 1.10.5 逻辑运算符
- 2.条件语句
-
- 2.1 if 判断的基本格式
- 2.2 if 嵌套
- 2.3 Debug 调试
- 2.4 猜拳游戏(随机数)
- 2.5 三目运算
- 3.循环语句
-
- 3.1 while 循环
- 3.2 for 循环
-
- 3.2.1 for 遍历字符串
- 3.2.2 for 遍历数字序列
- 3.2.3 for 循环嵌套
- 3.3 循环遍历的应用
-
- 3.3.1 打印正方形
- 3.3.2 打印直角三角形
- 3.3.3 其它案例
- 3.4 break & continue
- 3.5 循环 else 结构
- 4. 容器:字符串、列表、元组、字典
-
- 4.1 字符串 str
-
- 4.1.1 字符串的定义
- 4.1.2 字符串的下标和切片
- 4.1.3 字符串的查找-(find, index, count)
- 4.1.4 字符串的替换-replace
- 4.1.5 字符串的分割-split
- 4.1.6 字符串的连接-join
- 4.2 列表 list
-
- 4.2.1 列表的定义
- 4.2.2 列表的长度计算
- 4.2.3 列表的下标+切片操作
- 4.2.4 列表的遍历
- 4.2.5 列表的增加-(append, insert, extend)
- 4.2.6 列表的删除-(del, pop, remove)
- 4.2.7 列表的修改
- 4.2.8 列表的查询
- 4.2.9 列表的排序
- 4.2.10 列表的嵌套
- 4.2.11 列表的set去重法
- 4.2.12 列表的应用
- 4.3 元组 tuple
-
- 4.3.1 原组的定义
- 4.3.2 元组的取值
- 4.3.3 如何鉴定函数返回值
- 4.4 字典 dict
-
- 4.4.1 字典的定义
- 4.4.2 字典的 get 方法
- 4.4.3 字典的添加和修改
- 4.4.4 字典的删除
- 4.4.5 字典的遍历
- 4.5 enumerate()
- 4.6 公共方法总结
- 4.7 集合 set
- 5.函数
-
- 5.1 函数的定义
- 5.2 函数的debug
- 5.3 函数书写文档说明
- 5.4 局部/全局变量
- 5.5 函数的返回值
- 5.6 函数的多个返回值
- 5.7 函数传参的两种形式
- 5.8 缺省参数
- 5.9 不定长参数
- 5.10 函数形参的完整格式
- 5.11 print 函数
- 5.12 组包和拆包
- 5.13 应用:交换两个变量值
- 5.14 引用&内存
- 5.15 类型的可变与不可变
- 5.16 递归函数
- 5.17 匿名函数
- 5.18 匿名函数的使用场景
-
- 5.18.1 四则运算
- 5.18.2 列表元素排序
- 5.19 列表元素快速生成
- 6.文件
-
- 6.1 文本操作
- 6.2 文本模式
- 6.3 文本拷贝
- 6.4 文件操作
- 7.面向对象
-
- 7.1 基本概念
- 7.2 类的属性
- 7.3 魔法方法
-
- 7.3.1 `__init__()`
- 7.3.2 `__str__()`
- 7.3.3 `__del__()`
- 8.继承
-
- 8.1 继承的基本语法
- 8.2 多层继承
- 8.3 重写
- 8.4 子类调用父类的方法
- 8.5 重写父类的`__init__`方法
- 8.6 多继承
- 8.7 私有权限
- 8.8 实例属性 & 类属性
- 8.9 实例方法 & 类方法
- 8.9 静态方法
- 9.多态
- 10.异常
-
- 10.1 捕获异常
- 10.2 打印异常信息
- 10.3 捕获所有类型的异常
- 10.4 异常的完整结构
- 10.5 自定义异常类
- 11.模块
-
- 11.1 模块的导入
- 11.2 设置 Sources Root
- 11.3 模块中的变量`__all__`
- 11.4 模块中的变量`__name__`
- 11.5 注意事项
- 12.包
- 问题总结
-
- 文件路径 \User 报错
Python基础
1. 计算机组成原理和Python基础
1.1 计算机组成原理
-
计算机有哪些部分组成?
- 硬件系统
- 主机部分
- CPU中央处理器
- 内存(4G, 8G, 16G, 32G, 64G)
- 外设部分
- 输入/输出设备
- 显示设备
- 外存储器
- 硬盘(固态/机械硬盘)
- 优盘
- 主机部分
- 软件系统
- 系统软件
- 操作系统:控制硬件运行,支持其它软件运行
- Windos
- Mac
- Linux
- Android
- IOS
- 驱动程序
- 操作系统:控制硬件运行,支持其它软件运行
- 应用软件
- 游戏
- 音乐
- 视频
- 系统软件
- 硬件系统
-
计算机如何处理程序的
计算机想要运行程序,需要将软件加载到内存中,
CPU只能和内存进行交互!
1.2 编程语言和Python
编程语言:计算机与人类沟通交流的语言
python:python解释器,将python解释成计算机认识的语言
pycharm:IDE(集成开发环境),写代码的软件
1.3 注释
# 井号:单行注释
'''
单引号:多行注释【不推荐使用】
'''
"""
双引号:多行注释
"""
1.4 PEP 8 规范
单行注释:#后必须添加空格
绿色下划线:不是单词
W292 no newline at end of file:最后一行+回车【Ctrl+Enter】
行内注释:2空格+#+1空格+comments
函数:前后空两行
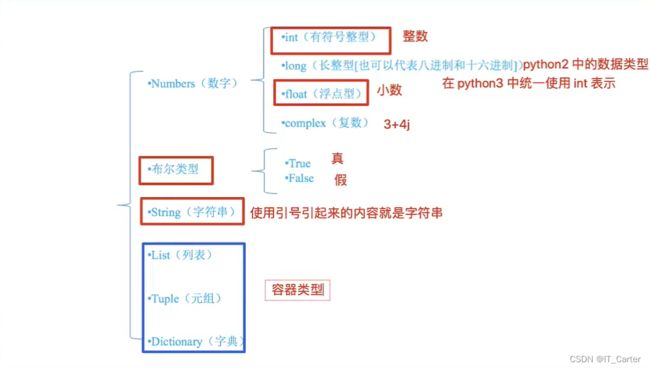
1.5 变量以及类型
1.5.1 变量定义
# 变量的定义
# 变量名 = 数据值 【变量名遵循标识符定义规则】
num1 = 100
num2 = 10
num3 = num1 + num2
print('num3=', num3) # Ctrl+enter在下方插入一个空行
# 变量的类型
num = 10
name = 'carter'
flag = True
print(type(num)) # 1.5.2 变量类型
1.6 标识符和关键字
1.6.1 命名规则
- 标识符由
字母、下划线、数字组成,不能以数字开头
1.6.2 命名规范
- 见名知意
- 驼峰命名法
- 小驼峰:userName
- 大驼峰:FirstName
- 下划线:last_name【
python默认】 - 不能使用系统的关键字
1.6.3 关键字
系统定义好的标识符,具有特殊作用!
import keyword # 导包
print(keyword.kwlist) # 打印python中所有关键字
1.7 输出
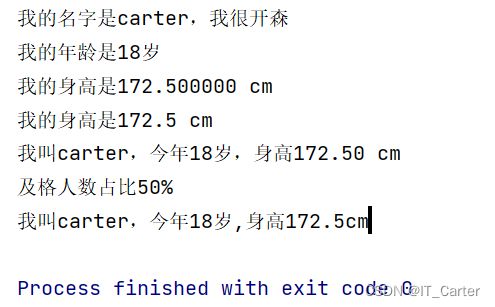
1.7.1 格式化输出

# 需求:输出 我的名字是xxx,我很开森
name = 'carter'
print("我的名字是%s,我很开森" % name)
# 需求:输出 我的年龄是18岁
age = 18
print('我的年龄是%d岁' % age)
# 需求:输出 我的身高是xxx cm
height = 172.5
print('我的身高是%f cm' % height)
print('我的身高是%.1f cm' % height)
# 需求:输出 我叫xxx,今年xx岁,身高xxx cm
print('我叫%s,今年%d岁,身高%.2f cm' % (name, age, height))
# 需求:输出 及格人数占比50%
print('及格人数占比%d%%' % 50)
# python3.6开始支持f-string,占位统一使用{}去占位,填充的数据直接写在{}内
# f-string的方式
print(f'我叫{name},今年{age}岁,身高{height}cm')
1.7.2 print 函数
修改print()函数结尾处的默认字符!!!
代码
# print()函数
print('hello', end=' ') # 修改print()函数结尾处字符,end=空格
print('world') # print()函数,默认end='\n'
print('hello', end='_*_')
print('world')
输出
hello world
hello_*_world
1.8 输入
代码
# 输入:从键盘获取输入的内容,存入计算机程序中
# input()函数
# input('提示信息'),遇到【回车】结束,得到的值都是字符串类型
password = input('请输入密码:')
print('密码:%s \n类型是:%s' % (password, type(password)))
结果
请输入密码:1122
密码:1122
类型是:
1.9 数据类型的转换
代码
# 需求:从键盘中输入苹果的价格、重量,输出苹果单价9.00元/斤,购买5.00斤,需要支付45.00元
# 单价
apple_price = float(input('输入的价格:'))
# 斤数
apple_weight = float(input('输入的重量:'))
# 总价
result = apple_price * apple_weight
print('苹果单价%.2f元/斤,购买%.2f斤,需要支付%.2f元' % (apple_price, apple_weight, result))
print(f'苹果单价{apple_price}元/斤,购买{apple_weight}斤,需要支付{result}元')
# 一、类型转换,将原始数据转换成我们需要的类型转换
# 1.不会改变原始数据
# 2.生成一个新的数据
number = 10
string_num = str(number)
print('%-5s %s' % (string_num, type(string_num)))
# eval() 还原原来的数据类型,去掉字符串的引号
num_int = eval('100')
print('%-5d %s' % (num_int, type(num_int)))
num_float = eval('99.9')
print('%-5.1f %s' % (num_float, type(num_float)))
num_01 = eval('num_int') # num_int是已经定义好的【变量】,可以使用不会报错
print('%-5d %s' % (num_01, type(num_01)))
结果
输入的价格:9
输入的重量:5
苹果单价9.00元/斤,购买5.00斤,需要支付45.00元
苹果单价9.0元/斤,购买5.0斤,需要支付45.0元
10
100
99.9
100
1.10 运算符
1.10.1 算数运算符
| / | 除 | 9/2=4.5 8/2=4.0 |
|---|---|---|
| // | 取整 | 9//2=4 8//2 = 4 |
| % | 取余 | 9%2=1 8%2=0 |
| ** | 指数 | 2**3=8 |
1.10.2 赋值运算符
=
1.10.3 复合赋值运算符
a -= c
a += c
…
1.10.4 比较运算符
== != >
比较运算符的结果是bool类型,即True, False
1.10.5 逻辑运算符
and 逻辑与 两个条件都为True 结果为True 一假为假 【短路现象:第一个为False,结果直接为False】
or 逻辑或 两个条件都为False 结果为False 一真为真 【短路现象:第一个为True,结果直接为True】
not 逻辑非 取反,原来True,变为False; 原来False,变为True
2.条件语句
2.1 if 判断的基本格式
- 严格的缩进关系
if 判断条件1:
判断条件1为 True, 会执行的代码01
判断条件1为 True, 会执行的代码02 # 缩进内,属于同一代码块
...
elif 判断条件2:
判断条件1不成立,判断条件2成立,执行此代码
else:
判断条件1、2都不成立,执行此代码
顶格书写的代码,代表和 if 判断没有关系
在 python 使用严格的缩进关系,代替代码的层级关系, 在 if 语句的缩进内,属于 if 语句的代码块
if 判断条件:
pass # 占位,空代码,防止报错
else:
pass
while condition:
pass
案例
age = int(input('请输入年龄:'))
if 0 < age < 18:
print('你还是个孩子,不可以涩涩哦!')
elif 18 <= age <= 100:
print('你已经是成年人了')
print('可以进入网吧为所欲为')
else:
print('输入年龄不正确')
# if...elif 只要一个条件成立,后续条件不会进行判断!!!
score = eval(input('学生成绩:'))
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 60:
print('及格')
else:
print('不及格')
2.2 if 嵌套
if 判断条件1:
判断条件1成立,执行此代码
if 判断条件2:
判断条件1、2都成立,执行此代码
else:
判断条件1成立、2不成立,执行此代码
else:
判断条件1不成立,执行此代码
代码
# 需求:有钱:可上车 没钱:不能上车
# 有座位:可坐 无座位:站着
money = eval(input('拥有的零钱:'))
if money >= 2:
print('可以上车')
seats = int(input('车上剩余座位个数:'))
if seats > 0:
print('可以坐下')
else:
print('没有座位,站着')
else:
print('没有钱,不能上车')
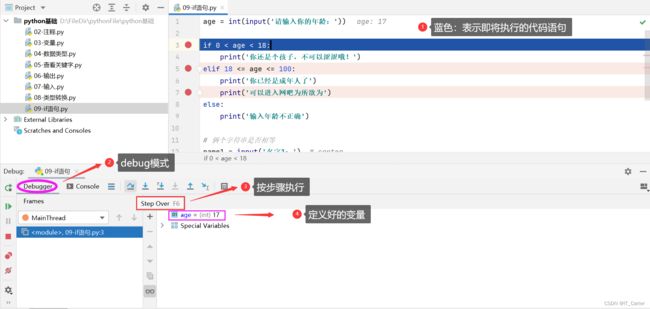
2.3 Debug 调试
- 可以查看代码执行过程
- 排查错误
步骤:
- 打断点
- 右键debug运行代码
- 点击下一步,查看代码执行过程
2.4 猜拳游戏(随机数)
需求
- 从控制台输入要出的拳头 – 石头(1) / 剪刀(2) / 布(3)
- 电脑随机出拳 – 先假设电脑只会出石头,完成完整代码功能
- 比较胜负
import random
# 产生[a, b]之间的随机数,包含a, b
num = random.randint(a, b)
代码
# 1:石头 2:剪刀 3:布
import random
while True:
# 1.自己出拳
user_fist = eval(input('请输入要出的拳:1(石头) 2(剪刀) 3(布) 0(exit):'))
if user_fist == 0:
break
# 2.电脑随机出拳
computer_fist = random.randint(1, 3) # 1-3之间的随机数
if computer_fist == 1:
print('电脑出了1(石头)')
elif computer_fist == 2:
print('电脑出了2(剪刀)')
else:
print('电脑出了3(布)')
# 3.判断胜负
result = user_fist - computer_fist
if result == 0:
print('平局')
elif result == 1 or result == -2:
print('电脑获胜...')
else:
print('用户获胜...')
请输入要出的拳:1(石头) 2(剪刀) 3(布):2
电脑出了3(布)
用户获胜...
2.5 三目运算
变量 = 表达式1 if 判断条件 else 表达式2 # 推荐使用扁平化代码
a = int(input('输入第一个数字:'))
b = int(input('输入第二个数字:'))
# 三目运算的使用
result = a - b if a >= b else b - a
print(result)
3.循环语句
3.1 while 循环
能够进行无限循环
while condition:
statementx1
statementx2
...
num = int(input('请输入循环次数:'))
i = 0
while i < num:
print(f'老婆我错了x{i+1}')
i += 1
3.2 for 循环
不能进行无限循环
基本格式
for 临时变量 in 字符串:
代码块
for 循环又称 for 遍历
3.2.1 for 遍历字符串
for i in 'hello':
# i 一次循环是字符串中的一个字符
if i != 'o':
print(i, end=', ')
else:
print(i) # 输出:h, e, l, l, o
3.2.2 for 遍历数字序列
# range(n) 会生成[0-n)的数据列,不包含n
for i in range(5):
if i < 5 - 1:
print(i, end=', ')
else:
print(i)
# range(a, b) 会生成[a, b)的整数数列,不包含b
for i in range(1, 10): # ==> for i in range(1, 10, 1)
if i < 10 - 1:
print(i, end=', ')
else:
print(i)
# range(a, b, step) 会生成[a, b)的整数序列,但每个数字之间间隔(步长)是 step
for i in range(1, 10, 3):
if i < 10-3:
print(i, end=', ')
else:
print(i)
结果
0, 1, 2, 3, 4
1, 2, 3, 4, 5, 6, 7, 8, 9
1, 4, 7
3.2.3 for 循环嵌套
操场跑圈案例
# 操场跑5圈,每圈3个俯卧撑
for i in range(1, 6, 1):
print(f'操场跑圈---{i}')
for j in range(1, 4, 1): # [1,4) 步长是1
print('俯卧撑x%d' % j)
结果
操场跑圈---1
俯卧撑x1
俯卧撑x2
俯卧撑x3
操场跑圈---2
俯卧撑x1
俯卧撑x2
俯卧撑x3
......
3.3 循环遍历的应用
3.3.1 打印正方形
要求:打印如下图形:
* * * * *
* * * * *
* * * * *
* * * * *
* * * * *
参考代码:
whlie 循环
# 循环嵌套的使用,打印正方形
n = int(input('矩形边长:'))
i = 0
while i < n:
j = 0
while j < n:
print('*', end=' ') # 打印一行的时候不能换行
j += 1
print() # 换行
i += 1
for 循环
n = int(input('矩阵边长:'))
for _ in range(n): # _表示占位符号
for _ in range(0, n, 1):
print('*', end=' ') # 打印一行
print() # 打印完一行就换行
3.3.2 打印直角三角形
*
* *
* * *
* * * *
while 循环
n = int(input('直角三角形的高:'))
current_lines = 1 # 当前处于第几行
while current_lines <= n:
i = 0
while i < current_lines: # 本行需要打印的 * 的个数
print('*', end=' ')
i += 1
print()
current_lines += 1
for 循环
n = int(input('直角三角形的高:'))
for current_lines in range(n):
for i in range(current_lines+1):
print('*', end=' ')
print()
3.3.3 其它案例
import random
"""
电脑产生1-100之间的随机数,用户来猜测
"""
# 电脑产生随机数
number = random.randint(1, 100)
while True:
i = int(input('用户猜测数字(1-100):'))
if i == number:
print('电脑产生的number=%d' % number)
break
elif i < number:
print('比电脑数字小')
else:
print('比电脑数字大')
"""
设计“过7游戏”程序,即在1-99之间,如果包含数字7或者是7的倍数,则输出"过...",否则输出具体的数字。
"""
i = 1
while i < 100:
if (i % 7 == 0) or (i % 10 == 7) or (i // 10 == 7):
print(f'{i}过...')
else:
print(i)
i += 1
for i in range(1, 100, 1):
if (i % 7 == 0) or (i % 10 == 7) or (i // 10 == 7):
print('过')
else:
print(i)
import math
"""
输入一个数字,判断其是否是素数
1-n之间的素数
"""
n = int(input('输入一个数字:'))
num = 2 # 需要进行判断的数字
while num <= n:
i = 2
while i <= int(math.sqrt(num)):
if num % i == 0: # 出现一个数字能被整除,不是素数
# print(f'{n}不是素数,它能被{i}整除')
break
i += 1
else:
print(f'{num}是素数')
num += 1
3.4 break & continue
break 和 continue 只能用于循环中
break 终止循环的执行
continue 提前结束本次循环,直接进入下一次循环
案例
# 有5个苹果
# 1.吃了三个苹果之后,吃饱了,后续的苹果不吃了
# 2.吃了三个苹果之后,再吃第四个苹果,发现虫子,这个苹果就不吃了,继续吃剩下的苹果
for i in range(1, 6):
if i == 4:
print('吃饱了,不吃了...')
break
print('正在吃标号为%d的' % i)
for i in range(1, 6):
if i == 4:
print('有虫子,吃不了...')
continue
print('正在吃标号为%d的' % i)
3.5 循环 else 结构
for x in xxx:
if xxx:
xxx # if 判断条件成立,执行
else:
xxx # if 判断条件不成立,执行
else:
xxx # for 循环代码运行结束,且不是被 break 终止的时候才会执行此段代码
需求:
有一个字符串 'hello python', 判断这个字符串中有没有包含 p
如果有则输出:包含p
没有则输出:不包含p
letter = 'p'
for c in 'hello carter':
if c == letter:
print('包含%c' % letter)
break
else:
print('不包含%c' % letter) # for没有被break,表示不包含letter
4. 容器:字符串、列表、元组、字典
4.1 字符串 str
4.1.1 字符串的定义
string01 = 'gg*'*3 # 单引号+字符串的乘法
string02 = 'GG' # 双引号
string03 = """hello
world
""" # 三引号
string04 = '''HELLO
WORLD'''
string05 = 'my name is \'carter\'' # 使用转义符
string06 = "my name is 'carter'" # 遇单用双
string07 = 'my name is "carter"' # 遇双用单
print(string01)
print(string02)
print(string03)
print(string04)
print(string05)
print(string06)
print(string07)
结果
gg*gg*gg*
GG
hello
world
HELLO
WORLD
my name is 'carter'
my name is 'carter'
my name is "carter"
4.1.2 字符串的下标和切片
python中的下标
- 正数下标:从0开始
- 负数下标: -1表示最后一个字符

my_str = 'hello' # 字符串下标
print('my_str[0]=', my_str[0])
print('my_str[-1]=', my_str[-1])
length = len(my_str) # 字符串长度
print('字符串长度=', length)
切片:指对操作的对象截取其中一部分的操作,会得到一个新的字符串。
字符串、列表、元组都支持切片操作!
切片语法:变量【起始:结束:步长】
注意:选取位置从”起始“位置开始,到”结束“位的前一个结束(不包含结束位本身),步长表示选取间隔
获取 hello 字符串中的 he 字符串?
"""
切片:可以截取一段数据,多个数据
切片语法:变量[start:end:step]
start:开始位置的下标,可省略
end:结束位置的下标,不包含 end 对应的下标,可省略
step:步长,下标之间的间隔,默认是1,可省略
"""
my_str = 'hello'
my_str01 = my_str[2:4] # step是1,可以写,截取[2,4)
print(my_str01)
my_str02 = my_str[0::2] # end不写,表示是len(),截取[0,5)字符间隔为 2
print(my_str02)
my_str03 = my_str[::] # start省略,表示0,截取[0,5)
print(my_str03)
my_str04 = my_str[:] # :符号至少一个,截取[0,5)
print(my_str04)
my_str05 = my_str[-len(my_str): -1] # 字符串的负数下标, 截取[-5,-1)
print(my_str05)
my_str06 = my_str[len(my_str):0:-1] # 步长为负数,开始位置在结束位置的后面
print(my_str06)
my_str07 = my_str[::-1] # 字符串的逆置,难以理解???
print('my_str07 =', my_str07)
输出
ll
hlo
hello
hello
hell
olle
my_str07 = olleh
4.1.3 字符串的查找-(find, index, count)
my_str[:] # 得到和原来一样的字符串
my_str[::-1] # 字符串的逆置
字符串的查找
find(sub_str, start, end)
- sub_str:需要查找的内容
- start:开始位置,默认为0
- end:结束位置,默认是len()
- 函数返回值
- 找到:返回索引下标
- 找不到:-1
代码
my_str = 'hello world carter and lsx_carter'
index = my_str.find('carter', 0, len(my_str))
print('carter对应的下标:', index) # 输出字符串首字符c的下标
index = my_str.rfind('carter', 0, len(my_str)) # 从右往左查找
print('从右往左查找carter:', index)
输出
carter对应的下标: 12
从右往左查找carter: 27
index(sub_str, start, end)
- sub_str:需要查找的内容
- start:开始位置,默认为0
- end:结束位置,默认是len()
- 函数返回值
- 找到:返回索引下标
- 没找到:报错
print(my_str.index('hello', 0, len(my_str))) # 从左往右
print(my_str.rindex('hello', 0, len(my_str))) # 从右往左
count(sub_str, start, end)
- sub_str:需要查找的内容
- start:开始位置,默认为0
- end:结束位置,默认是len()
- 函数返回值
- 找到的次数
- 没有:0
4.1.4 字符串的替换-replace
replace(old_str, new_str, count)
- old_str:需被替换的字符串
- new_str:用这个字符串替换
- count:指定替换的次数,默认替换所有
- 返回值:得到一个新的字符串
Code
my_str = 'hello world carter and lsx_carter'
print(my_str)
new_my_str = my_str.replace('carter', 'Aristo', 1) # 替换1次
print(new_my_str)
new_my_str = my_str.replace('carter', 'Aristo') # 默认全部替换
print(new_my_str)
Output

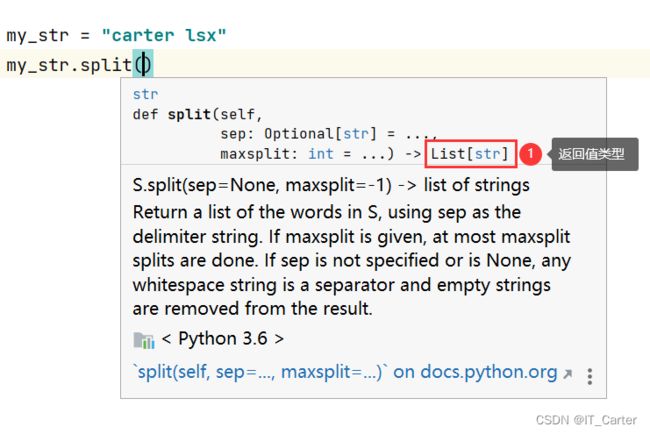
4.1.5 字符串的分割-split
split(sub_str, count)
- sub_str:按照指定字符进行切割,把肉割掉(本身被切除)
- count:指定切割次数,默认全部切割
- 返回值:
列表[]
代码
my_str = 'hello world carter and lsx_carter'
result = my_str.split(' ') # 默认全部切割
print(result)
result = my_str.split(' ', 2) # 指定切割次数
print(result)
result = my_str.rsplit(' ', 2) # 从右往左切割2刀
print(result)
输出
['hello', 'world', 'carter', 'and', 'lsx_carter']
['hello', 'world', 'carter and lsx_carter']
['hello world carter', 'and', 'lsx_carter']
4.1.6 字符串的连接-join
将 my_str 插入到 str 中每个元素之间,构造一个新的字符串,不改变原来的字符串
my_str.join(可迭代对象:字符串 or 列表-必须是字符串类型 or 元组)
join():将my_str 这个字符串添加到可迭代对象的每两个元素之间
返回值:一个新的字符串,不改变原字符串的值
代码
my_str = '-'.join('carter')
print(my_str) # 每两个字符间添加-字符
my_list = ['hello', 'world', 'my', "name's", 'carter'] # 列表
print(' '.join(my_list)) # 每两个元素间添加空格
输出
c-a-r-t-e-r
hello world my name's carter
| 关键字 | 功能 | 使用 |
|---|---|---|
| capitalize | 把字符串的第一个字符大写 | my_str.capitalize() |
| title | 把字符串中每一个单词的首字母变成大写 | my_str.title() |
| upper | 所有字母大写 | my_str.upper() |
| lower | 所有字母小写 | my_str.lower() |
| islower | 判断是否全小写 | my_str.islower() |
| isupper | 判断是否全大写 | my_str.isupper() |
| startswith | 检查字符串是否以xxx开头 | my_str.startswith(‘xxx’) |
| endswith | 检查字符串是否以xxx结尾 | my_str.endswith(‘xxx’) |
| ljust | 左对齐 | my_str.left(width) |
| rjust | 右对齐 | my_str.rjust(width) |
| center | 居中显示 | my_str.center(width) |
| lstrip | 去除字符串左边空格 | |
| rstrip | 去除字符串右边空格 | |
| strip | 去除左右空格 | |
| partition | 把字符串切割成 str前 str str后 三部分 | my_str.partition(str) |
| rpartition | 从右边开始的 | |
| splitlines | 按照行分割 | |
| isalpha | 字符是否都是字母 | |
| isdigit | 字符是否都是数字 | |
| isalnum | 字符串是否由 数字 和 字母 组成 | |
| isspace | 是否是空格字符串 |
4.2 列表 list
python中的一种数据类型,可以存放多个数据,数据类型可以是任意的
4.2.1 列表的定义
# 空列表的定义
my_list = []
print(my_list, type(my_list))
my_list01 = list()
print(my_list01, type(my_list01))
# 定义带数据的列表,每个数据元素之间使用逗号隔开
my_list02 = [1, 3.14, True, 'carter']
print(my_list02, type(my_list02))
4.2.2 列表的长度计算
print(len(my_list))
4.2.3 列表的下标+切片操作
my_list02 = [1, 3.14, True, 'carter']
print(my_list02[3]) # carter
print(my_list02[1:3:1]) # [3.14, True]
注意:字符串不能使用下标修改数据,但是列表 list 中可以
列表
my_list02[3] = 'lsx'
print(my_list02) # [1, 3.14, True, 'lsx']
字符串
my_str = 'hello'
my_str[0] = 'l'
print(my_str)
# TypeError: 'str' object does not support item assignment 字符串不可以进行分配
4.2.4 列表的遍历
my_list03 = [1, 3.14, True, 'carter']
# list 列表遍历
for value in my_list03:
print(value)
print('*'*30) # 字符串的乘法操作
i = 0
while i < len(my_list03):
print(my_list03[i])
i += 1
输出
1
3.14
True
carter
******************************
1
3.14
True
carter
4.2.5 列表的增加-(append, insert, extend)
三者都是直接在原列表中进行的添加操作,不会返回新列表
append:拼接,尾插法
insert:插入,头插法
extend:可插入多个元素组合成的列表
代码
my_list = [1, 3.14, True, 'carter']
print('原始数据:', my_list)
my_list.append(-1) # 尾插法
print('尾插法:', my_list)
my_list.insert(0, '零') # 头插法
print('头插法:', my_list)
my_list.extend([1, 2, 3]) # 合并列表
print('插入列表:', my_list)
my_list01 = [1, 2, 3, 4]
my_list02 = [1, 2, 3, 4]
my_list03 = my_list01 + my_list02 # 列表不去重复
for i in my_list01: # 列表去重操作
if i in my_list02:
continue
else:
my_list02.append(i)
my_list02.sort(reverse=False) # False升序 True降序
输出
原始数据: [1, 3.14, True, 'carter']
尾插法: [1, 3.14, True, 'carter', -1]
头插法: ['零', 1, 3.14, True, 'carter', -1]
插入列表: ['零', 1, 3.14, True, 'carter', -1, 1, 2, 3]
4.2.6 列表的删除-(del, pop, remove)
- del my_list[index]:删除指定下标元素
- my_list.pop(index):尾删法 or 指定下标删除,并返回删除的元素
- remove(xxx):删除存在的元素xxx
my_list = [1, 2, 3, 4]
print(my_list)
my_list.remove(3) # 删除存在的数据
print(my_list)
num = my_list.pop() # 默认删除最后一个
print('我删除了', num)
print(my_list)
num = my_list.pop(my_list.index(1)) # 删除指定下标(元素1的下标)
print('我删除了', num)
print(my_list)
print('我将删除:my_list[0]=%d' % my_list[0])
del my_list[0]
print(my_list)
4.2.7 列表的修改
索引修改
my_list02[3] = 'lsx'
print(my_list02) # [1, 3.14, True, 'lsx']
4.2.8 列表的查询
- index(xxx):寻找 list 中的xxx元素的下标
- 存在:返回首字符下标
- 不存在:报错
- count(xxx):xxx 在 list 中出现的次数
- in: xxx in list 列表中是否存在xxx
- not in:xxx not in list 元素xxx是否不存在于列表中
my_list = [1, 3.14, False, 'carter', 1]
num = my_list.index(3.14) # 获取元素3.14在列表中的下标
print(num)
num = my_list.count(1) # 统计元素1在列表中的个数,True也会被程序看成1
print(num)
flag = 3.14 in my_list # 判断元素 3.14是否存在
print(flag)
flag = 3.14 not in my_list
print(flag)
4.2.9 列表的排序
列表数据的数据类型一致才能排序
sort:原列表中进行排序的,默认从小到大排序
sorted:不会在原列表中进行排序,会得到一个新的列表
数字列表排序
my_list = [1, 4, 3, 2, -1]
my_list.sort() # 默认从小到大
my_list.sort(reverse=False) # 效果同上
my_list.sort(reverse=True) # 从大到小
my_list01 = sorted(my_list, reverse=False) # 默认升序
my_list01 = sorted(my_list, reverse=True) # 默认降序
字符串列表逆置
my_list02 = ['a', 'b', 'c', 'd']
# 方法1
my_list03 = my_list02[::-1]
print(my_list03)
# 方法2
my_list02.reverse()
print(my_list02)
4.2.10 列表的嵌套
my_list = [
['北京大学', '清华大学', '浙江大学'],
['武汉大学', '华中科技大学', '北京邮电大学'],
['南京邮电大学', '重庆邮电大学', '西安邮电大学']
]
print(my_list[1])
print(my_list[1][1])
print(my_list[1][1][1])
for school_names in my_list:
print(type(school_names)) # list 类型
for school_name in school_names:
print(school_name)
4.2.11 列表的set去重法
my_list = [1, 1, 1, 2, 3, 3, 2, 2, 3]
my_list = list(set(my_list))
print(f'my_list={my_list}') # my_list=[1, 2, 3]
4.2.12 列表的应用
随机办公室进行分配
import random
"""
一个学校,有3个办公室,现在有9位老师等待工位分配,请编写程序,完成随机分配
"""
# 资源
teacher_office = [[], [], []]
teachers = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'j']
# 每个办公室的最大容量
max_size = len(teachers) // len(teacher_office) + (1 if len(teachers) % len(teacher_office) > 0 else 0)
print(f'max_size={max_size}')
for teacher in teachers:
i = random.randint(0, 2) # 对办公室进行随机+可以对老师名字进行随机
while len(teacher_office[i]) == max_size: # 该办公室满了,缺点没有负载均衡
i = random.randint(0, 2)
teacher_office[i].append(teacher)
print(teacher_office)
随机老师进行分配
# 2.随机老师:轮询分配到每个办公室
length_teacher = len(teachers) # 老师数量
length_teacher_office = len(teacher_office) # 办公室数量
office_index = 0 # 轮询的办公室
while length_teacher > 0:
# 生成随机下标,长度和未分配的老师数量相关
i = random.randint(0, length_teacher-1)
# 删除 list 指定的下标元素
teacher = teachers.pop(i) # pop 方法会返回删除的元素
# 老师数目发生改变
length_teacher -= 1
# 使用 轮询方法 分配至办公室
teacher_office[office_index].append(teacher)
# 轮询改变 办公室索引
office_index = (office_index + 1) % length_teacher_office
sequ = 1
for office in teacher_office:
print(f'{sequ}号办公室分配的老师是:')
for teacher_name in office:
print(teacher_name, end=" ")
print()
sequ += 1
4.3 元组 tuple
元组中元素不能修改,没有修改操作,仅有查询操作
- 支持下标、切片操作
4.3.1 原组的定义
空元组
my_list = [] # 列表
my_tuple = () # 元组,不可更改
my_tuple01 = tuple() # 没有意义
一个元素的元组
my_tuple = (1) # 元组切片操作
my_tuple = (1, 2, 3)
print(my_tuple[::-1]) # 切片操作--->(3, 2, 1)
4.3.2 元组的取值
my_tuple[index]
4.3.3 如何鉴定函数返回值
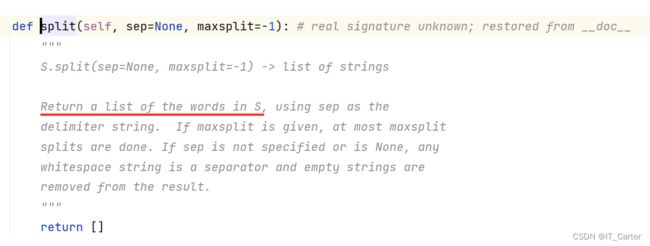
4.4 字典 dict
4.4.1 字典的定义
- key:字符串 or 数字【不可变类型】
- value:可以是任意类型
- 注意:key 值的 int 1 和 float 1.0 代表同一个 key 值
代码
# 字典 dictionary 定义使用{}
my_dict = {"name": "carter", 'age': 18, 'hobby': ['学习', '看书', '摘录'], 1: [1, 2, 3]}
# 通过 key 进行访问,如果key不存在===>报错!!!
print(my_dict[1])
print(my_dict['hobby'][2])
# 使用 get 方法进行访问
print(my_dict.get('hobby')[2])
# for 循环进行遍历
for key in my_dict:
print(my_dict[key], end=" ")
输出
[1, 2, 3]
摘录
摘录
carter 18 ['学习', '看书', '摘录'] [1, 2, 3]
4.4.2 字典的 get 方法
- my_dict.get(key):字典中有返回该值,没有返回 None
- my_dict.get(key, value):存在返回固定数据,不存在返回自定义的默认值 value
代码
print(my_dict.get('hobbys'))
print(my_dict.get('hobbys', '自定义默认'))
# 输出:None 自定义默认
4.4.3 字典的添加和修改
- 字典[key] = 数据值
- key 值存在,修改数据
- key 值不存在,添加数据
4.4.4 字典的删除
- del
del 字典名:直接将 字典变量抹除del 字典明[key]:根据key来删除字典中的元素
- pop:通过 key 来删除指定元素,返回值告知删除了 who
- key 不存在,上述方式都报错
- 字典.clear():删除所有键值对
代码
del my_dict[1] # 字典的删除
delete_value = my_dict.pop('hobby')
print(f'我删除了{delete_value}')
my_dict.clear() # 清空字典
print(my_dict)
del my_dict # 删除字典变量,除非再次定义
4.4.5 字典的遍历
for 遍历
for key in my_dict:
print(my_dict[key], end=" ")
print()
keys 方法
- 获取所有的 key 值
- 可以使用 list() 进行类型转换
# 获取所有的 key 值
dict_keys = my_dict.keys()
print(dict_keys, type(dict_keys)) # dict_keys(['name', 'age', 'hobby', 1]) values 方法
- 获取所有 value 值
- 可以使用 list() 进行类型转换
dict_values = my_dict.values()
print(dict_values, type(dict_values)) # dict_values(['carter', 18]) items 方法
-
获取所有键值对,元组类型
-
可以使用 list() 进行类型转换
dict_items = my_dict.items()
print(dict_items, type(dict_items))
# dict_items([('name', 'carter'), ('age', 18)]) 4.5 enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列
同时列出数据的数据下标,一般用在for循环当中。
代码
my_list = ['a', 'b', 'c', 'd']
for i in my_list:
print(my_list.index(i), i) # 获取 index 和 value
for i in enumerate(my_list): # 合并成元组
print(i, type(i), i[0], i[1])
输出
0 a
1 b
2 c
3 d
(0, 'a') <class 'tuple'> 0 a
(1, 'b') <class 'tuple'> 1 b
(2, 'c') <class 'tuple'> 2 c
(3, 'd') <class 'tuple'> 3 d
4.6 公共方法总结
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3 ,4] | 合并 | 字符串、列表[]、元组() |
| * | [‘Hi’]*4 | [‘Hi’, ‘Hi’, ‘Hi’, ‘Hi’] | 复制 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否在 | 字符串、列表、元组、字典(key 值) |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典(key 值) |
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | len(item) | 计算容器中元素个数 |
| 2 | max(item) | 返回容器中元素最大值,字典比较 key 值大小 |
| 3 | min(item) | 返回容器中元素最小值 |
| 4 | del(item) | 删除容器变量 |

4.7 集合 set
set的定义,使用 {数据1,数据2,…}
- 集合中的数据必须是不可变类型
- 集合本身是可变类型
- 集合是无序的(添加和输出顺序并不一致)
- 没有重复数据
- 不支持下标操作
代码
# 集合 set 定义使用{数据1, 数据2, ...} 不是键值对
# 键值对:字典
# 去重
my_set = {1, False, 'hello', (1, 2)}
print(my_set) # 无序输出
# 增加
my_set.add(100)
print(my_set)
# 删除
my_set.remove(False)
print(my_set)
# 修改
my_set.remove(1)
my_set.add(2)
print(my_set)
# 亲空
my_set.clear()
print(my_set)
输出
{False, 1, 'hello', (1, 2)}
{False, 1, (1, 2), 100, 'hello'}
{1, (1, 2), 100, 'hello'}
{(1, 2), 2, 100, 'hello'}
set()
5.函数
5.1 函数的定义
def 函数名():
代码
- 减少代码的冗余
- 函数名遵循标识符的规则
- PEP8规范,function 前后都需要空两行
print('函数第定义前...')
# 函数的定义
def sum_number(a, b):
return a + b
print('函数第定义后...')
# 函数调用
print('函数使用前...')
print(sum_number(1, 1))
print('函数使用后...')
5.2 函数的debug

5.3 函数书写文档说明
- 函数注释有特定位置
- 函数的参数
- 实参:函数调用时的参数【实参传给形参】
- 形参:函数定义时的参数
代码
print('函数第定义前...')
# 函数的定义
def sum_number(a, b):
"""
:param a: int 类型
:param b: int 类型
:return: 两数之和
"""
return a + b
print('函数第定义后...')
# 函数调用
print('函数使用前...')
print(sum_number(1, 1))
print('函数使用后...')
help(sum_number) # 查看文档注释
输出
函数第定义前...
函数第定义后...
函数使用前...
2
函数使用后...
Help on function sum_number in module __main__:
sum_number(a, b)
:param a: int 类型
:param b: int 类型
:return: 两数之和
5.4 局部/全局变量
-
局部变量:函数内部定义的变量,只能在函数内部使用
-
生存周期
- 函数调用时被创建
- 函数结束时被销毁
-
全局变量:函数外部定义的变量
Q:能否在函数内部修改全局变量?
- 使用 global 关键字
代码
num = 100
def func01():
print(num)
def func02():
num = 200 # 定义了一个和【全局变量】名字相同的【局部变量】而已
def func03():
global num # 【全局变量】:函数内部,正确修改全局变量
num = 200
func01() # 100
func02() # 定义一个局部变量num=200
func01() # 100
func03() # global 关键字,修改全局变量
func01() # 200【改变】
5.5 函数的返回值
在函数内部定义的局部变量,或者通过计算得到的局部变量,想要在函数外部访问和使用
此时可以使用 return 关键字
return
- 将 return 后的数据值进行返回
- 程序遇到 return ,会终止(结束)执行,不会执行之后的代码
def add(a, b):
return a + b
result = add(int(input('输入第1个数字:')), int(input('输入第2个数字:')))
print(f'函数返回结果:{result}')
5.6 函数的多个返回值
import math
def add(a=1, b=1): # 如果调用时,不传入参数,函数启动本身默认的值 a=1,b=1
c = a + b
d = int(math.fabs(a-b))
# return c, d
return [c, d] # 列表
# return (c, d) # 元组
# return {0: c, 1:d} # 字典
a = int(input('输入第1个数字:'))
b = int(input('输入第2个数字:'))
# result01, result02 = add(a, b)
# print(f'函数返回结果:result01={result01}, result02={result02}')
result = add(a, b)
print(f'函数返回结果:result01={result[0]}, result02={result[1]}')
1.return 后面可以不写数据值,默认返回None
def func():
xxx
return # 返回 None,终止函数的运行
2.函数可以不写 return ,返回默认值 None
def func():
xxx
pass
5.7 函数传参的两种形式
def func(a, b, c):
print(f'a:{a}')
print(f'b:{b}')
print(f'c:{c}')
# 1、位置传参:按照参数的位置顺序进行传参
func(1, 2, 3)
# 2、关键字使用:指定实参传给哪个形参
func(a=10, c=20, b=30)
# 3、混合使用:先位置传参,后参数传参
func(300, c=3, b=30)
代码报错
# 位置实参必须在关键字实参之前
func(a=300, 3, 30)
# SyntaxError: positional argument follows keyword argument,
# a形参匹配多个实参,300给了a 3也给了a
func(300, a=3, c=30)
# TypeError: func() got multiple values for argument 'a'
5.8 缺省参数
def func(a, b=10):
print(f'a={a}', end=' ')
print(f'b={b}')
# 特点:函数调用的时候,如果给缺省参数传递实参值那它使用传递的值,否则就使用默认值
func(1) # 不给b传实参
func(1, 2)
5.9 不定长参数
print 函数是典型的不定长元组形参类型
- 不定长元组形参
- 不定长字典形参
def func(*args, **kwargs):
"""
:param args:一个*号,不定长元组形参,可以接收所有【位置实参】,类型是元组
:param kwargs:两个*号,不定长字典形参,可以接收所有的【关键字实参】,类型是字典
:return:None
"""
for i in args:
print(i, end=' ')
print()
for k, v in kwargs.items():
print(f'kwargs[{k}]={v}')
func(1, 2, 4, a='a', b='b')
5.10 函数形参的完整格式
4种参数类型
- 普通参数
- 不定长元组参数
- 缺省参数
- 不定长字典藏书
def func(a, *c, b=1, **d):
pass
5.11 print 函数
def print(self, *args, sep=' ', end='\n', file=None): # known special case of print
"""
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
sep: 输出多个参数,中间的字符,默认空格
"""
pass
# 案例演示
print(1, 2, 3, 4, sep="->") # 1->2->3->4
5.12 组包和拆包
组包:将多个数据值,组成元组,给到一个变量
拆包:将容器中的数据分别给到多个变量,注意:数据的个数和变量的个数要保持一致
代码
# 组包:将多个变量,组成元组,给到一个变量
a = 1, 2, 3
print(a, type(a)) # (1, 2, 3) 结果
(1, 2, 3)
1->2->3->1->3
10 20
name age
5.13 应用:交换两个变量值
代码
a = 1
b = 2
print('交换前:', a, b)
# 方式1:临时变量
temp = a
a = b
b = temp
print('方式1:', a, b)
# 方式2:数学方式
a = a + b
b = a - b
a = a - b
print('方式2:', a, b)
# 方式3: 组包--->拆包
b, a = a, b
print('方式3:', a, b)
输出
交换前: 1 2
方式1: 2 1
方式2: 1 2
方式3: 2 1
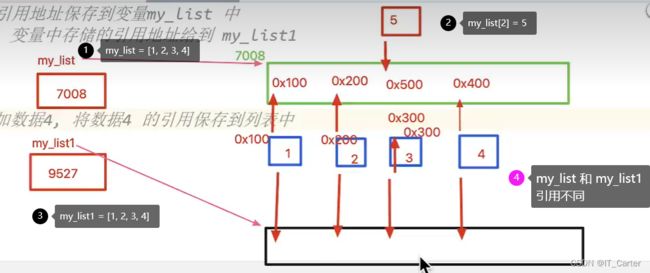
5.14 引用&内存
在 python 中,值是靠引用来传递的
我们可以用 id() 来判断两个变量是否为同一个值的引用。我们将 id 理解为那块内存标识
赋值运算符可以改变变量的引用
- a = 1:常量1 分配内存空间,将存储地址赋值给变量 a
- b = a:将 a 保存的存储地址复制给 b
- a = 2:开辟存储常量2的内存空间,将这块内存空间的地址赋值给a

列表
my_a = [1, 2, 3]
my_b = my_a
my_a.append(4) # 修改 my_a 列表,改变了列表中元素的地址值,如果 list 的容量到了max,是否需要进行扩容?
print(my_a, id(my_a))
print(my_b, id(my_b))
5.15 类型的可变与不可变
在不改变变量引用的前提下,能否改变变量引用中的数据值
不可变类型:int float bool str tuple
可变类型: list dict
代码
# 不可变参数类型
num = 10 # int 类型
num = 20 # int 改变数据值的方式,但是id(num)发生了改变,原来内存地址的值仍然存储的是 10
a = 10
b = 10
print(id(a) == id(b)) # True
my_tuple = (1, 2, 3)
my_tuple1 = (1, 2, 3)
print(id(my_tuple) == id(my_tuple1)) # True
# 可变参数类型
my_list = [1, 2, 3]
my_list1 = [1, 2, 3]
print(id(my_list) == id(my_list1)) # False
my_list = [1, 2, 3, 4]
my_list.append(5) # id(my_list)不会改变,但 my_list 中的元素值发生了改变
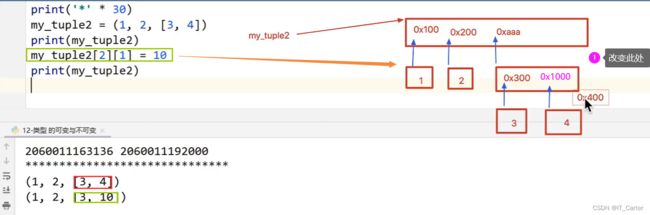
Q:元组中 List 改变是否是 tuple 改变?
A:否
可变参数的函数
def list_append(my_list, element): # 相当于my_list = list_1
my_list.append(element) # 未修改 my_list 的引用地址
list_1 = [1, 2, 3]
list_append(list_1, 4)
print(list_1)
def func(a):
a += 1 # 修改了a的引用地址
b = 10
func(b)
print(b) # 10
5.16 递归函数
求n!
def func(n):
if n == 1:
return n
return func(n-1)*n
num = int(input('输入一个数字:'))
print(F'{num}!={func(num)}')
5.17 匿名函数
使用 lambda 关键字定义的函数就是匿名函数
lambda 参数列表: 表达式
# 匿名函数的调用方法1
(lambda 参数列表: 表达式)() # 将整个函数当作函数名+()进行调用
# 匿名函数的调用方法2 [没有意义,不如def]
f = lambda 参数列表: 表达式
f()
-
无参数无返回值
def 函数名(): 函数代码 lambda:函数代码 -
无参数有返回值
def 函数名(): return 1 + 2 lambda: 1 + 2 -
有参数无返回值
def 函数名(a, b): print(a, b) lambda a, b: print(a, b) -
有参数有返回值
def 函数名(a, b): return a + b lambda a, b: a + b
5.18 匿名函数的使用场景
作为函数的参数
5.18.1 四则运算
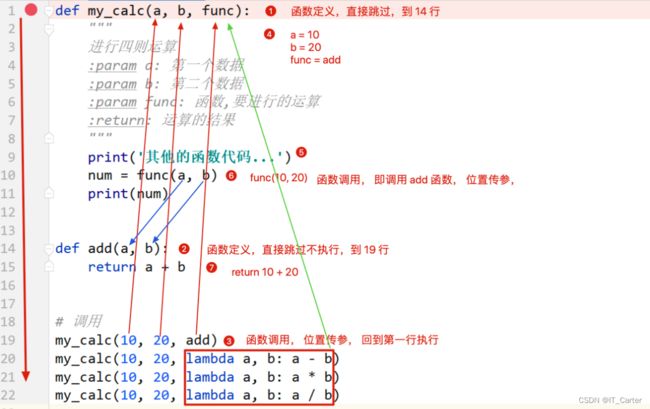
案例:四则运算
def add(a, b): # 加法运算
return a + b
def calculate(a, b, fun):
"""
:param a: 形参变量
:param b: 形参变量
:param fun: 函数
:return: 计算结果
"""
num = fun(a, b)
print(num)
return num
calculate(1, 3, add)
# 【匿名函数的应用】+3
calculate(1, 3, lambda a, b: a - b)
calculate(1, 3, lambda a, b: a * b)
calculate(1, 3, lambda a, b: a / b)
5.18.2 列表元素排序
列表的元素属于字典类型的排序应用
代码
my_list = [{'name': 'carter', 'age': 19},
{'name': 'lsx', 'age': 15},
{'name': 'lsd', 'age': 18}]
# 对列表中的字典元素 进行姓名升序排序
my_list.sort(key=lambda X: X['name'])
print(my_list)
# 年龄大小升序
my_list.sort(key=lambda my_dict: my_dict['age'], reverse=False)
print(my_list)
my_list01 = ['a' 'cf', 'safsdbmvf', 'abc',]
# 根据字符串长度进行降序排序
my_list01.sort(key=lambda my_str: len(my_str), reverse=True)
print(my_list01)
输出
[{'name': 'carter', 'age': 19}, {'name': 'lsd', 'age': 18}, {'name': 'lsx', 'age': 15}]
[{'name': 'lsx', 'age': 15}, {'name': 'lsd', 'age': 18}, {'name': 'carter', 'age': 19}]
['safsdbmvf', 'acf', 'abc']
5.19 列表元素快速生成
代码
# 1. 变量 = 【生成数据的规则 for 临时变量 in xxx】
my_list01 = [i for i in range(5)]
print(my_list01)
my_list02 = ['hello' for _ in range(5)]
print(my_list02)
my_list03 = [f'num:{i}' for i in range(5)]
print(my_list03)
# 2. 变量 = 【生成数据的规则 for 临时变量 in xxx if xxx】
# 每次循环 if 条件为True,生成一个数据
my_list04 = [i for i in range(0, 5, 1) if i % 2 == 0]
print(my_list04)
# 3. 变量 = 【生成数据的规则 for 临时变量 in xxx if xxx for 临时变量 in xxx if xxx】
# 双重for循环
my_list05 = [(i, j) for i in range(2) for j in range(1, 3)]
print(my_list05, type(my_list05[0]))
my_list06 = [[i, j] for i in range(2) for j in range(1, 3)]
print(my_list06, type(my_list06[0]))
my_list07 = [{'age': i, 'name': f"{j}号"} for i in range(18, 19) for j in range(1, 3)]
print(my_list07, type(my_list07[0]))
输出
[0, 1, 2, 3, 4]
['hello', 'hello', 'hello', 'hello', 'hello']
['num:0', 'num:1', 'num:2', 'num:3', 'num:4']
[0, 2, 4]
[(0, 1), (0, 2), (1, 1), (1, 2)] <class 'tuple'>
[[0, 1], [0, 2], [1, 1], [1, 2]] <class 'list'>
[{'age': 18, 'name': '1号'}, {'age': 18, 'name': '2号'}] <class 'dict'>
6.文件
6.1 文本操作
- open 函数打开文件,没有指定 encoding,默认 GBK
- write 函数将中文写入文件,没有指定 encoding,默认GBK
- 在 pycharm 中双击打开文件,默认编码 UTF-8
- 使用 utf-8 打开 GBK,出现乱码问题
代码
# 文件读取-r
f = open('1.txt', 'r', encoding='UTF-8') # 文件中有中文!
buff = f.read()
print(buff) # 输出文本内容
f.close() # 关闭资源
# 文件写入-w
f = open('2.txt', mode='w', encoding='utf-8')
f.write('hello carter\n')
f.write('你好 carter\n')
f.close()
# 文件追加-a
f = open(file='1.txt', mode='a', encoding='utf-8')
f.write('hello China\n')
f.write('你好,中国\n')
f.close()
6.2 文本模式
1.文本文件:txt, py, md 能够使用记事本打开的文件
# 可以使用 文本模式 or 二进制模式 打开文件
2.二进制文件:具有特殊格式的文件,mp3 mp4 rmvb avi png jpg 等
# 二进制模式 打开文件:无法指定 encoding 参数
二进制的转换
buff = '你好啊!'.encode() # 二进制编码
print(buff, type(buff)) # class 'bytes'
buff = buff.decode() # 二进制解码
print(buff, type(buff)) # class 'str'
6.3 文本拷贝
代码
def file_copy(file_name):
# 1、读取文件中的内容
f = open(file=file_name, mode='r', encoding='utf-8')
buf = f.read()
f.close()
# 2、生成新的文件名
index = file_name.rfind('.')
new_file_name = file_name[:index] + '副本' + file_name[index:]
# 3、复制文本
f = open(new_file_name, 'w', encoding='utf-8')
f.write(buf)
f.close()
print('备份成功...')
6.4 文件操作

7.面向对象
7.1 基本概念
两种编程思想
- 面向过程:亲历亲为+自己写函数
- 面向对象:封装+继承+多态
类:大驼峰命名法
方法:在类中定义的函数
7.2 类的属性
外部操作属性
- 缺点1:只能单独的用于该操作对象来使用
- 缺点2:类内部无法使用外部添加的属性
class Dog():
def play(self):
print('二哈快乐的拆家中...')
dog01 = Dog()
# 外部添加属性
dog01.name = '二哈'
dog01.age = 4
# 修改属性
dog01.age = 3
内部操作属性
- self:指调用方法的对象本身
class Dog():
def play(self):
print(f'小狗 {self.name}快乐的拆家中...') # 没有 name 属性,调用该方法就会报错
dog = Dog()
dog.name = '二哈'
dog.play()
print('-'*30)
dog1 = Dog()
dog1.play()
# AttributeError: 'Dog' object has no attribute 'name'
7.3 魔法方法
在 python 的类中,有一类方法,这类方法以 `两个下划线开头` 和`两个下划线结尾`
在`满足某个特定条件的情况下,会自动调用`. 这类方法,称为魔法方法
如何学习魔法方法:
1. 魔法方法在什么情况下会自动调用
2. 这个魔法方法有什么作用
3. 这个魔法方法有哪些注意事项
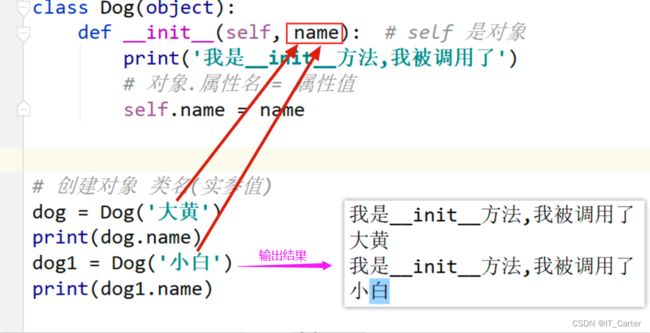
7.3.1 __init__()
- 用于初始化属性
调用时机: 在创建对象之后,会立即调用.
作用:
1. 用来给对象添加属性,给对象属性一个初始值(构造函数)
2. 代码的业务需求,每创建一个对象,都需要执行的代码可以写在 `__init__ `中
【注意点】: 如果 `__init__` 方法中,有除了 self 之外的形参,那么在创建的对象的时候,需要给额外的形参传递实参值 `类名(实参)`
唯一形参

结果

多个参数
7.3.2 __str__()
- toString():用于输出信息
调用时机:
1. `print(对象)`, 会自动调用 `__str__` 方法, 打印输出的结果是 `__str__` 方法的返回值
2. `str(对象)` 类型转换,将自定义对象转换为字符串的时候, 会自动调用
应用:
1. 打印对象的时候,输出一些属性信息
2. 需要将对象转换为字符串类型的时候
注意点:
`方法必须返回一个字符串`,只有 self 一个参数
没有__str__()方法时
代码
class Dog:
def __init__(self, name, age):
print('Dog类初始化...')
self.name = name
self.age = age
dog = Dog('大黄', 4)
print(dog) # 没有__str__方法,默认输出对象的引用地址
str_dog = str(dog)
print(str_dog) # 没有__str__方法的类型转换,默认输出对象的引用地址
输出
Dog类初始化...
<__main__.Dog object at 0x000001FE24F4B438>
<__main__.Dog object at 0x000001FE24F4B438>
有__str__()方法时
代码
class Dog:
def __init__(self, name, age):
print('Dog类初始化...')
self.name = name
self.age = age
def __str__(self):
return f'今年{self.age}岁的{self.name}被外星人抓走了!'
dog = Dog('大黄', 4)
print(dog) # 默认输出__str__()方法的返回格式
str_dog = str(dog)
print(str_dog) # 默认输出__str__()方法的返回格式
输出
Dog类初始化...
今年4岁的大黄被外星人抓走了!
今年4岁的大黄被外星人抓走了!
7.3.3 __del__()
析构函数
调用时机:
对象在内存中被销毁删除的时候(引用计数为 0)会自动调用 __del__ 方法
1. 程序代码运行结束,在程序运行过程中,创建的所有对象和变量都会被删除销毁
2. 使用 `del 变量` , 将这个对象的引用计数变为 0.会自动调用 __del__ 方法
应用场景:
对象被删除销毁的时候,要书写的代码可以写在 `__del__`中.一般很少使用
引用计数: 是 python 内存管理的一种机制, 是指一块内存,有多少个变量在引用,
1. 当一个变量,引用一块内存的时候,引用计数加 1
2. 当删除一个变量,或者这个变量不再引用这块内存.引用计数减 1
3. 当内存的引用计数变为 0 的时候,这块内存被删除,内存中的数据被销毁
my_list = [1, 2] # 1
my_list1 = my_list # 2:该存储值的内存地址被引用2次,计数器为2
del my_list # 1
del my_list1 # 0:没有人引用[1, 2]这块地址的值,自动调用__del__()方法

8.继承
8.1 继承的基本语法
继承:描述类与类之间的所属关系
基本语法:
class 类B(类A)
pass
成为B继承A
`特点:子类可以使用父类的方法和属性
优点:代码复用,重复相同的代码不用多次书写
名词:
`类A:父类 基类
`类B:子类 派生类
代码
class Animal(object):
def eat(self):
print(f'{self.name}能吃蔬菜,能吃肉')
def __init__(self):
self.name = '动物'
class Dog(Animal):
def son_func(self):
print('狗子吃屎,父亲是', self.name, sep='')
dog = Dog()
# 子类调用父类的方法和属性
dog.eat()
print(dog.name)
# 子类调用自己的方法
dog.son_func()
输出
动物能吃蔬菜,能吃肉
动物
狗子吃屎,父亲是动物
8.2 多层继承
代码
`1.祖宗
class Animal(object):
def eat(self):
print('欢乐的吃东西...')
`2.父亲
class Dog(Animal):
def play(self):
print('愉快的玩耍...')
`3.儿子
class DogSon(Dog):
pass
`DogSon-->Dog 单继承 DogSon-->Dog-->Animal 多层继承
dog_son = DogSon()
dog_son.eat() # 祖宗的方法
dog_son.play() # 父亲的方法
8.3 重写
`子类重写父类的方法
重写: 子类定义和父类名字相同的方法.
为什么重写: 父类中的方法,不能满足子类对象的需求,所以要重写.
重写之后的特点: 子类对象调用子类自己的方法,不再调用的方法,父类对象调用父类自己的方法.
class Dog(object):
def bark(self):
print('狗子汪汪叫...')
class Cat(Dog):
def bark(self):
print('小猫喵喵喵...')
dog = Dog()
dog.bark()
cat = Cat() `狗子汪汪叫...
cat.bark() `小猫喵喵喵...
8.4 子类调用父类的方法
class Dog(object):
def bark(self):
print('狗子汪汪叫...')
class Cat(Dog):
def bark(self):
print('小猫喵喵喵...')
`子类中如何调用父类的方法
def parents_func(self):
`调用方式1
Dog.bark(self)
`调用方式2
super(Cat, self).bark()
`调用方式3
super().bark()
Dog().bark()
cat = Cat()
cat.bark()
cat.parents_func()
8.5 重写父类的__init__方法
class Dog(object):
def __init__(self, name):
self.age = 0
self.name = name
def __str__(self):
return f'名字为:{self.name}, 年龄是:{self.age}'
class Cat(Dog):
# 1.子类重写父类的__init__方法
def __init__(self, name, color):
super(Cat, self).__init__(name) # 需要调用父类的__init__并将参数传过去
self.color = color
# 2。子类重写__str__方法
def __str__(self):
return f'名字为:{self.name}, 年龄是:{self.age}, 毛色为:{self.color}'
cat = Cat('二哈', '撒黑色')
print(cat)
8.6 多继承
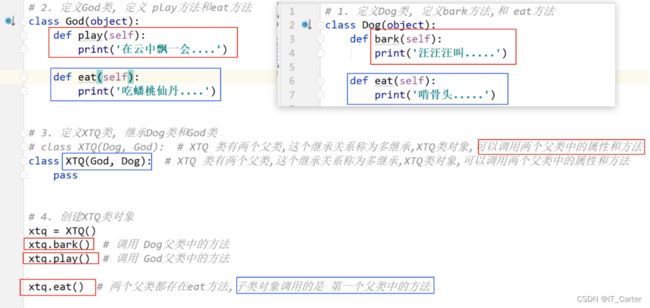
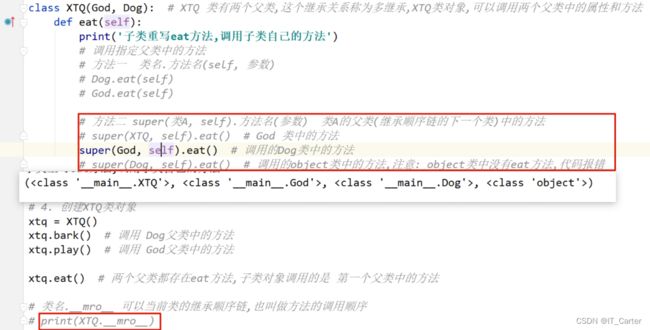
8.7 私有权限
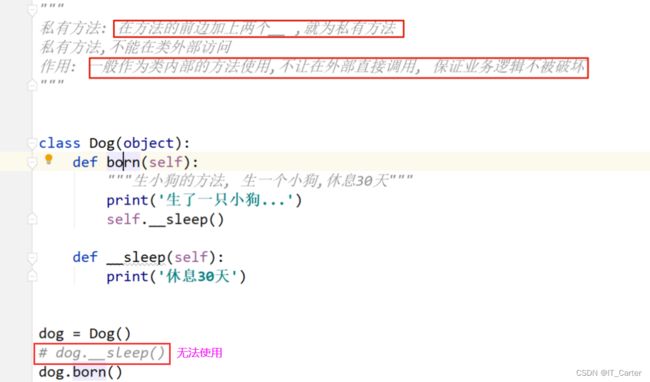
访问权限控制: 在什么地方可以使用和操作.
私有权限:
定义: 在方法和属性前加上两个下划线, 就变为私有.
1. `不能在类外部通过对象直接访问和使用, 只能在类内部访问和使用
2. 不能被子类继承,
公有: 不是私有的,就是公有的.
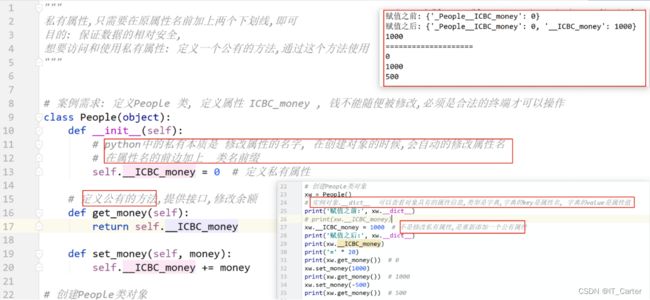
8.8 实例属性 & 类属性
- 实例属性
- 通过实例对象
self定义的属性都是实例属性 - 每一个实例对象存一份,并且值可能不一样
- 通过实例对象
- 类属性
- 在类内部,方法外定义的属性都是类属性
- 类属性,内存中只有一份
Code
class Dog():
# 类属性:类内部+方法外
class_name = '大狗狗类'
def __init__(self, name):
# 实例属性
self.name = name
# 1. the first init object
dog01 = Dog('big yellow')
print(dog01.name)
# 2. the second init object
dog02 = Dog('big white')
print(dog02.name)
# class attribute
# this result is True
print(dog01.class_name == dog02.class_name)
Output
=====实例属性=====
big yellow
big white
====类属性====
True
8.9 实例方法 & 类方法
-
实例方法:类中默认定义的方法,就是实例方法,第一个参数是
self,表示实例对象 -
类方法
- 使用
@classnethod装饰的方法,称为类方法 - 第一个参数是
cls,代表的是类对象自己 - 目的:调用类属性
- 使用
-
如果在方法中使用实例属性,那么该方法必须定义为实例方法
-
前提:不需要使用实例属性,需要使用类属性,可以将这个方法定义为类方法
代码
class Dog:
# 类属性
class_name = '亚历山大——狗王'
def __init__(self, name): # 实例方法
self.name = name # 实例属性
@classmethod
def get_class_name(cls): # 类方法
return cls.class_name # 调用类属性
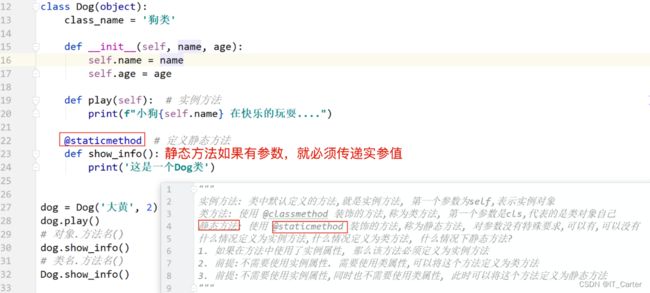
8.9 静态方法
使用 @staticmethod 修饰的方法
- 如果在方法中使用了实例属性,那么它就是实例方法a
- 前提:不需要使用实例属性,需要使用类属性,这个方法就是类方法
- 不需要使用实例属性,同时也不需要使用类属性,此时可以将这个方法定义为静态方法
9.多态
class Dog:
def __init__(self, name):
self.name = name
def play(self):
print(f'类Dog-->{self.name}愉快的玩耍')
class SonDon(Dog):
def __int__(self, name):
super().__init__(name)
def play(self):
print(f'类SonDog-->{self.name}愉快的玩耍')
# 两个类都有 play 方法
def play_with_dog(obj_dog):
obj_dog.play()
dog = Dog('二哈')
son_dog = SonDon('大王')
# 调用公共方法---多态
play_with_dog(dog)
play_with_dog(son_dog)
输出
类Dog-->二哈愉快的玩耍
类SonDog-->大王愉快的玩耍
10.异常
10.1 捕获异常
1、基本概念
异常的组成:
`异常类型`:异常具体的描述

2、异常的捕获
"""
try:
可能发生异常的代码
except (异常类型1,异常类型2,...):
发生异常执行的代码
"""
# 1.捕获单个异常
try:
print(10/0)
except ZeroDivisionError:
print('错误,被除数不能为0')
# 2.捕获多个异常
a = input('输入一个被除数:')
try:
num = int(a)
print(10/num)
except (ZeroDivisionError, ValueError):
print('您的输入有误...')
"""
try:
可能发生异常的代码
except 异常类型1:
statement+1
except 异常类型2:
statement+2
except ...
"""
a = input('输入一个被除数:')
try:
num = int(a)
print(10/num)
except ZeroDivisionError:
print('错误,被除数不能为0')
except ValueError:
print('输入有误...')
10.2 打印异常信息
"""
try:
可能异常的代码
except (异常类型1,异常类型2,...) as 变量名:
发生异常执行的代码
print(变量名)
"""
a = input('输入被除数:')
try:
num = int(a)
print(10/num)
except(ValueError, ZeroDivisionError) as error:
print('输入有误,', error, sep='')
# invalid literal for int() with base 10: 's'
# division by zero
10.3 捕获所有类型的异常
try:
可能异常的代码
except: # 缺点:不能获取异常的描述信息
发生异常执行的代码
==================================
try:
可能发生异常的代码
except Exception as e:
发生异常执行的代码
print(e)
pass
==================================
# Exception 是常见异常类的父类,
ZeroDivisionError --> ArithmeticError --> Exception --> BaseException ===> object
ValueError --> Exception --> BaseException ===> object
10.4 异常的完整结构
try:
可能发生异常的代码
except Exception as e:
发生异常执行的代码
print(e)
else:
代码没有发生异常,会执行
finally:
不管有没有发生异常,都会执行
10.5 自定义异常类
class PasswordLengthError(Exception): # 自定义密码长度异常类,继承Exception
pass
def get_password():
password = input('请输入密码:')
if len(password) >= 8:
print('密码长度合格')
else:
# 抛出异常
raise PasswordLengthError('密码长度不足8位数')
# 异常捕获
try:
get_password()
except PasswordLengthError as e:
print(e) # 密码长度不足8位数
11.模块
import random
random.randint(a, b) # 产生[a,b]的数字
python 中的一个代码文件,直接使用别人实现的功能!
11.1 模块的导入
模块就是一个 python 文件
注意:模块的名字遵循标识符的规则
# 方式一
import 模块名
模块名.功能名()
# 方式二:如果存在重名的变量名,则会被覆盖
from 模块名 import 功能名1,功能名2,...
# 方式三:可能存在覆盖【不推荐使用】
from 模块名 import * # 将模块中所有功能导入
关键字 as
作用:起别名
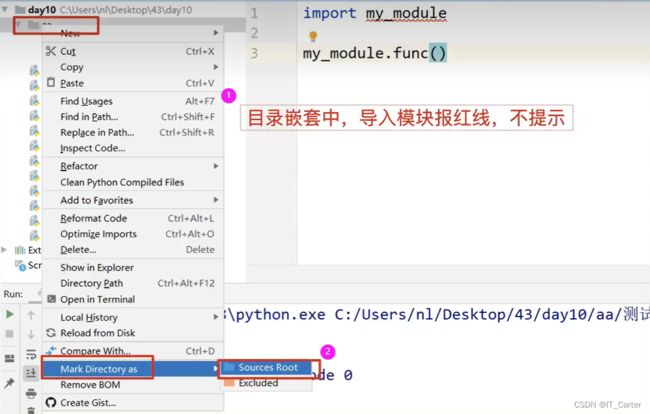
11.2 设置 Sources Root
如果出现同级目录下导模块爆红问题
11.3 模块中的变量__all__
__all__可以在每个代码文件(模块)中定义,类型是 元组、列表
作用:影响 from 模块名 import *,其它两种导入形式不受影响
- 如果没有定义
__all__变量,模块中的所有功能,都可以被导入 - 如果定义了
__all__变量,只能导入变量中定义的内容

11.4 模块中的变量__name__
相当于 Java 中的main方法,程序入口程序
测试的时候能够执行,被调用的时候不会自动执行
模块1
num = 1
print('num--->', num) # 当代码文件作为模块导入的时候也会自动执行此段代码
# 测试的时候执行
if __name__ == '__main__':
print('main-->num--->', num) # 当模块导入的时候不会自动执行
main.py
import 模块一 # 会输出:num---> 1
# 不会输出:main-->num--->1
11.5 注意事项
-
自己定义的模块不要和系统中的模块名相同
-
模块的搜索顺序
- 当前目录—>系统目录—>程序报错
12.包
包: 功能相近或者相似的模块放在一个目录中
并在目录中定义一个 `__init__.py` 文件,这个目录就是包
导入方法
1. import 包名.模块名 as 别名
2. from 包名.模块名 import 功能名
3. from 包名 import * `导入的是__init__.py`中的内容
问题总结
Q:修改 list 里的元素,改变了 list 的元素数量或元素值,如果 list 到了max存储容量, list 进行扩容时, 是否改变内存地址?
文件路径 \User 报错
代码:img = imread('C:\Users\26724\Pictures\4K壁纸\可爱比基尼美女.jpg')
错误:SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
原因:在Python中\是转义符,\u表示其后是UNICODE编码,因此\User在这里会报错,在字符串前面加个r表示就可以了
修改:img = imread(r'C:\Users\26724\Pictures\4K壁纸\可爱比基尼美女.jpg')