用python代码实现输入基金代码爬取季度报告并获取季报特定模块内容制作动态词云图
本文涉及爬虫、pdf文件转txt文件、提取指定内容和生成词云图四个部分。
文章目录
前言
一、引入库
二、爬取网页上的基金季报
三、pdf转txt文件
四、提取指定内容
五、删除页眉页脚
六、制作词云图
总结
前言
本文将介绍如何爬取网站上的pdf文件并提取文件中的指定段落计算关键词出现次数并制作动态词云图,以爬取基金季报为例。
提示:以下是本篇文章正文内容
一、引入库
import pandas
import time
import random
import requests
import os
import re
import jieba
import os.path
import pandas as pd
import matplotlib.pyplot as plt
from PyPDF2 import PdfFileReader, PdfFileWriter
from pdf2docx import Converter
from selenium import webdriver
from bs4 import BeautifulSoup
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
from selenium.webdriver.common.by import By
from wordcloud import WordCloud
from collections import Counter
from pyecharts.charts import WordCloud二、爬取网页上的基金季报
定义get_report()函数,输入基金代码,可以爬取对应基金的最新一期季度报告。
代码如下:
def get_report(code):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path= "D:\Downloads\chromedriver_win32\chromedriver.exe")
#运行之前需要手动改一下自己的 chromedriver.exe 的本地路径
url = 'http://fundf10.eastmoney.com/jjgg_{0}_3.html'.format(code)
driver.get(url)
content = driver.page_source
soup = BeautifulSoup(content, 'html.parser')
# 获取页码数
soup_pages = soup.find_all('div', class_='pagebtns')[0].find_all('label')
page_size = len(soup_pages)-2
list_result = []
"""获取内容"""
soup_tbody = soup.find_all('table', class_='w782 comm jjgg')[0].find_all('tbody')[0]
for soup_tr in soup_tbody.find_all('tr'):
soup_a = soup_tr.find_all('td')[0].find_all('a')
title = soup_a[0].get_text()
# 文件下载链接为空的处理
if len(soup_a) == 2:
link = soup_a[1].get('href')
else:
link = None
date_str = soup_tr.find_all('td')[2].get_text()
if title.endswith("报告"):
list_result.append([title, link, date_str])
df_result = pandas.DataFrame(list_result, columns=['报告标题', '报告pdf链接', '公告日期'])
# 点击下一页按钮
driver.find_element(By.XPATH,"//div[@class='pagebtns']/label["+str(+2)+"]").click()
time.sleep(random.randint(5, 10))
# 下载文件
res = requests.get(df_result['报告pdf链接'][0])
#设置下载路径,
file_path = os.path.join('E:/changjiangsecurity/report//',df_result['报告标题'][0] + '.pdf')
with open(file_path, 'wb') as f:
f.write(res.content)
接下来介绍部分步骤:
1.要实现打开网址这项操作,首先要下载对应的chromedriver版本,方法如下:
1)首先,打开谷歌浏览器,找到目前你谷歌浏览器的版本。(打开设置,点击关于谷歌就能看到,如下图)

2)chromedriver的版本一定要与Chrome的版本一致,有两个下载地址:
①CNPM Binaries Mirror
②http://chromedriver.storage.googleapis.com/index.html
点进去之后点击对应的版本,比如我的谷歌版本是100.0.4896.75,我下载对应的chromedriver的版本可以是100.0.4896.60,点进去之后选择相应的系统,如果是windows系统就选win32即可。
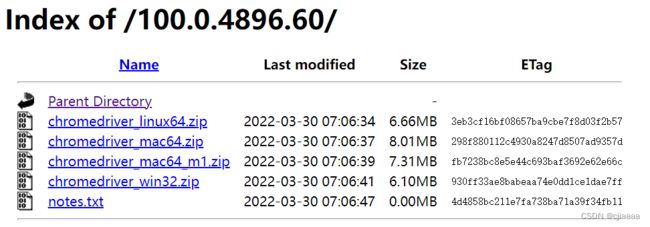
2.设置网址
打开天天基金网-基金公告-定期报告,可以得到目标网址
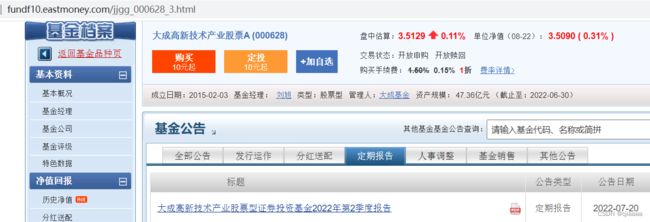
则: url = 'http://fundf10.eastmoney.com/jjgg_{0}_3.html'.format(code)
三、pdf转txt文件
将pdf文件转为txt文件,txt文件方便定位关键词和提取关键段落。
代码如下:
def changePdfToText(filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
pdfStr = pdfStr + x.get_text() + '\n'
fileNames = os.path.splitext(filePath)
file2 = open(fileNames[0] + '.txt','wb')#保存这些内容
file2.write(pdfStr.encode())
file2.close()
file.close()
四、提取指定内容
本次案例以提取“4.4投资策略和运作分析”和“4.5 报告期”之间的内容为例,对于每一份报告,我们都提取这一部分的内容。
代码如下:
data = open(r'E:\changjiangsecurity\result\opnion.txt',"w+")
#txt定位
for file in os.listdir(file_path):
# 获取文件后缀
suff_name = os.path.splitext(file)[1]
# 过滤非pdf格式文件
if suff_name == '.txt':
# 获取文件名称
file_name = os.path.splitext(file)[0]
path=os.path.join(file_path + '//' + file_name+'.txt')
with open(path,"r",encoding='utf-8') as f:
content = f.read()
re_str = r'投资策略和运作分析(.+)4.5 报告期' # 筛选定位
resp = re.findall(re_str, content, re.S)
a = ' '.join(resp)
a.split('\n')
print(a,file = data)
print('\n',file = data)
data.close()
五、删除页眉页脚
但是,上一步那样粗略识别的方式有一些问题,那就是当需要提取的段落出现跨页的情况时,页眉和页脚也会被读取进入结果中,所以增加一步删除页眉页脚的工作。
代码如下:
# 删除页眉页脚
file = open(r'E:\changjiangsecurity\result\\opnion.txt',"r")#需要打开文件的绝对地址
a = file.readlines()
b = []
for i in range(len(a)):
if "季度报告" not in a[i] and "页 共" not in a[i]: # 关键词
b.append(a[i])
file2 = open(r'E:\changjiangsecurity\result\\final.txt', 'w', encoding='utf-8') #要写入文件的地址
file2.writelines(b)
file.close()
file2.close() 六、制作词云图
提取到了指定段落后,我们开始制作由指定词构成的词云图。我们需要设定关键词,统计关键词在段落中出现的次数(词频),然后根据词频数画词云图,并显示出现的次数。
代码如下:
# 制作词云图
startWords = ['碳中和','新能源','新能源车','消费','军工','元宇宙','TMT','金融','地产','半导体','制造业','高端制造','硬科技','医药','5G','物联网','网络安全','新基建','建材','煤炭','钢铁','航运']
# 打开文本
text = open("E:/changjiangsecurity/result/final.txt", encoding="utf-8").read()
# 中文分词
text = jieba.lcut(text) # 利用jieba进行精细分词形成列表
# 统计词频
aftertext = []
i = 0
j = 0
for i in range(len(text)):
for j in range(len(startWords)):
if text[i] == startWords[j]:
aftertext.append(text[i])
j=j+1
i=i+1
dict={}
for key in aftertext:
dict[key]=dict.get(key,0)+1
print(dict)
# 画图
frequency = {}
for word in aftertext:
if word not in frequency:
frequency[word] = 1
else:
frequency[word] += 1
word_list = list(frequency.items())
word_list
mywordcloud = WordCloud()
mywordcloud.add('',word_list, shape='circle')
# 渲染图片
mywordcloud.render_notebook()全部代码如下:
import pandas
import time
import random
import requests
import os
import re
import jieba
import os.path
import pandas as pd
import matplotlib.pyplot as plt
from PyPDF2 import PdfFileReader, PdfFileWriter
from pdf2docx import Converter
from selenium import webdriver
from bs4 import BeautifulSoup
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
from selenium.webdriver.common.by import By
from wordcloud import WordCloud
from collections import Counter
from pyecharts.charts import WordCloud
def get_report(code):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path= "D:\Downloads\chromedriver_win32\chromedriver.exe")
#运行之前需要手动改一下自己的 chromedriver.exe 的本地路径
url = 'http://fundf10.eastmoney.com/jjgg_{0}_3.html'.format(code)
driver.get(url)
content = driver.page_source
soup = BeautifulSoup(content, 'html.parser')
# 获取页码数
soup_pages = soup.find_all('div', class_='pagebtns')[0].find_all('label')
page_size = len(soup_pages)-2
list_result = []
"""获取内容"""
soup_tbody = soup.find_all('table', class_='w782 comm jjgg')[0].find_all('tbody')[0]
for soup_tr in soup_tbody.find_all('tr'):
soup_a = soup_tr.find_all('td')[0].find_all('a')
title = soup_a[0].get_text()
# 文件下载链接为空的处理
if len(soup_a) == 2:
link = soup_a[1].get('href')
else:
link = None
date_str = soup_tr.find_all('td')[2].get_text()
if title.endswith("报告"):
list_result.append([title, link, date_str])
df_result = pandas.DataFrame(list_result, columns=['报告标题', '报告pdf链接', '公告日期'])
# 点击下一页按钮
driver.find_element(By.XPATH,"//div[@class='pagebtns']/label["+str(+2)+"]").click()
time.sleep(random.randint(5, 10))
# 下载文件
res = requests.get(df_result['报告pdf链接'][0])
#设置下载路径,
file_path = os.path.join('E:/changjiangsecurity/report//',df_result['报告标题'][0] + '.pdf')
with open(file_path, 'wb') as f:
f.write(res.content)
data=pd.read_excel('E:\changjiangsecurity\changjiang50.xlsx',dtype='str')###2022年长江50表格
fid=['0'*(6-len(x))+x for x in data['基金代码']]
data['基金代码']=fid#转化为str
for i in fid:
get_report(i)
def changePdfToText(filePath):
file = open(path, 'rb') # 以二进制读模式打开
#用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
praser.set_document(doc)
doc.set_parser(praser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
pdfStr = ''
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
pdfStr = pdfStr + x.get_text() + '\n'
fileNames = os.path.splitext(filePath)
file2 = open(fileNames[0] + '.txt','wb')#保存这些内容
file2.write(pdfStr.encode())
file2.close()
file.close()
file_path= 'E:/changjiangsecurity/report'
for file in os.listdir(file_path):
suff_name = os.path.splitext(file)[1]
# 过滤非pdf格式文件
if suff_name == '.pdf':
# 获取文件名称
file_name = os.path.splitext(file)[0]
path=file_path+'//'+file_name+'.pdf'
changePdfToText(path)
data = open(r'E:\changjiangsecurity\result\opnion.txt',"w+")
#txt定位
for file in os.listdir(file_path):
# 获取文件后缀
suff_name = os.path.splitext(file)[1]
# 过滤非pdf格式文件
if suff_name == '.txt':
# 获取文件名称
file_name = os.path.splitext(file)[0]
path=os.path.join(file_path + '//' + file_name+'.txt')
with open(path,"r",encoding='utf-8') as f:
content = f.read()
re_str = r'投资策略和运作分析(.+)4.5 报告期' # 筛选定位
resp = re.findall(re_str, content, re.S)
a = ' '.join(resp)
a.split('\n')
print(a,file = data)
print('\n',file = data)
data.close()
# 删除页眉页脚
file = open(r'E:\changjiangsecurity\result\\opnion.txt',"r")#需要打开文件的绝对地址
a = file.readlines()
b = []
for i in range(len(a)):
if "季度报告" not in a[i] and "页 共" not in a[i]: # 关键词
b.append(a[i])
file2 = open(r'E:\changjiangsecurity\result\\final.txt', 'w', encoding='utf-8') #要写入文件的地址
file2.writelines(b)
file.close()
file2.close()
# 制作词云图
startWords = ['碳中和','新能源','新能源车','消费','军工','元宇宙','TMT','金融','地产','半导体','制造业','高端制造','硬科技','医药','5G','物联网','网络安全','新基建','建材','煤炭','钢铁','航运']
# 打开文本
text = open("E:/changjiangsecurity/result/final.txt", encoding="utf-8").read()
# 中文分词
text = jieba.lcut(text) # 利用jieba进行精细分词形成列表
# 统计词频
aftertext = []
i = 0
j = 0
for i in range(len(text)):
for j in range(len(startWords)):
if text[i] == startWords[j]:
aftertext.append(text[i])
j=j+1
i=i+1
dict={}
for key in aftertext:
dict[key]=dict.get(key,0)+1
print(dict)
# 画图
frequency = {}
for word in aftertext:
if word not in frequency:
frequency[word] = 1
else:
frequency[word] += 1
word_list = list(frequency.items())
word_list
mywordcloud = WordCloud()
mywordcloud.add('',word_list, shape='circle')
# 渲染图片
mywordcloud.render_notebook()生成结果如下:
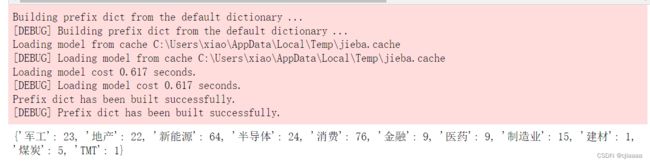
当鼠标移动到关键词处时同时也会显示其出现的次数,如图所示:

总结
以上就是今天要讲的内容,本文介绍了用python代码实现输入基金代码爬取季度报告并获取季报特定模块内容制作进阶版词云图的全部过程,希望能对读者有所帮助。