Drag GAN 论文浅读
此论文为研究论文,入选 SIGGRAPH 2023(SIGGRAPH是计算机图像界最顶级会议)。
一作:潘新刚 现马克斯・普朗克计算机科学研究所博士后
论文:[2305.10973] Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (arxiv.org)代码(据说6月开源):https://github.com/XingangPan/DragGAN
效果图:

相比于更易掌控的扩散模型,GAN通过单个向前传递生成图像,因此是更高效的。
为提高更加准确、灵活、通用的交互式图像处理工具,本文提出Drag GAN(高效交互、实时编辑、多次改变图像,不依赖于额外网络),其有两部分组成:
1)一种基于特征的运动监督,它驱动图像中的操纵点向目标位置移动。(运动监督:通过生成器特征图上的偏移补丁实现,每个优化步骤都会导致操纵点向目标点移动,生成器中间特征有很强的鉴别能力,因此一个简单的损失足以监督运动。)
2)一种新的点跟踪方法,它利用判别型GAN来操纵点的位置。(点跟踪)
通过DragGAN,任何人都可以通过精确控制像素的位置来变形图像。
其中图像变形这些操作是在GAN学习的生成图像流上执行的,倾向于遵从底层的目标结构,并非简单的应用扭曲(不是“挤压像素”,而是“重新生成物体”)因此即使对于具有挑战性的场景,如遮挡内容也可以产生逼真的输出。该方法能生成不可见的内容,如狮子嘴里的牙齿,还可以按照物体的刚性变形,如马腿弯曲。
论文结构:
1.介绍
为了满足这些不同的用户需求,一种理想的可控图像合成方法应该具有以下特性:1)灵活性:它应该能够控制生成的物体或动物的不同空间属性,包括位置、姿势、形状、表情和布局;2) 精度:应能对空间属性进行高精度控制;3) 一般性:应适用于不同的对象类别,但不限于某一类别。虽然以前的工作只满足其中的一个或两个性质,但我们的目标是在这项工作中实现所有这些性质。其中3D模型等方法无法推广到别的类别,文本引导在编辑空间属性方面缺乏准确性和灵活性。
本文研究问题的两个挑战:
1)我们考虑多个点的控制,而其他的方法不能很好地处理这一点。2) 我们要求操纵点精确地到达目标点,而其他的方法没有。正如我们在实验中展示的那样,通过精确的位置控制处理多个点以达到用户想要的图像。并且,DragGAN还允许用户选择性地绘制感兴趣的区域,以执行特定于区域的编辑。在不同的数据集上进行操作,均实现了不错的效果。
2.相关工作
2.1创建交互式生成模型
2.2点跟踪
在这项工作中,我们表明,可以在不使用任何上述方法(2.2提到的方法)或额外的神经网络的情况下对GAN生成的图像进行点跟踪。我们揭示了GANs的特征空间具有足够的判别性,使得可以简单地通过特征匹配来实现跟踪。们率先将基于点的编辑问题与判别GAN特征联系起来,并设计了一种具体的方法。去掉额外的跟踪模型可以使我们的方法更有效地运行,以支持交互式编辑。尽管我们的方法简单,但在我们的实验中,我们表明它优于最先进的点跟踪方法,包括RAFT和PIP。
3.方法
本文研究基于StyleGAN2架构。
StyleGAN2架构简述: 在StyleGAN2体系结构中,512维的潜在代码![]() 通过映射网络空间w被映射到中间潜在代码
通过映射网络空间w被映射到中间潜在代码![]() w然后发送到生成器G 以产生输出图像I=G (w). 在该过程中,w被复制多次并发送到生成器的不同层G以控制不同级别的属性.................
w然后发送到生成器G 以产生输出图像I=G (w). 在该过程中,w被复制多次并发送到生成器的不同层G以控制不同级别的属性.................
3.1基于交互式点操纵

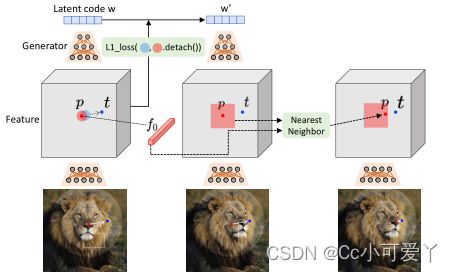
给定GAN生成的图像,用户只需要设置几个操纵点(红点)、目标点(蓝点),以及可选的表示编辑期间可移动区域的遮罩(较亮区域)。我们的方法迭代执行运动监督(第3.2节)和点跟踪(第3.3节)。运动监督步骤驱动操纵点(红点)向目标点(蓝点)移动,点跟踪步骤更新操纵点以跟踪图像中的对象。这个过程一直持续到控制点到达它们对应的目标点。
如上图所示,每个优化步骤由两个子步骤组成,包括1)运动监督和2)点跟踪。在运动监督中,强制操纵点向目标点移动的损失用于优化潜在代码w. 经过一个优化步骤后,我们得到了一个新的潜在代码w' 以及一个新的图像I′。更新会导致图像中的对象发生轻微移动。请注意,运动监督步骤仅将每个操纵点朝其目标移动一小步,但该步骤的确切长度尚不清楚,因为它受到复杂的优化动力学的影响,因此对于不同的物体和部位会有所不同。在我们的实验中通常需要30-200次迭代。
3.2运动监督
运动监督是通过生成器的特征图上的偏移补丁损失来实现的。我们通过最近邻搜索在相同的特征空间上执行点跟踪(GAN模型的判别特征可以很好的捕捉密集对应关系)。
运动监督损失:

3.3点跟踪
GANs的判别特征很好地捕捉了密集的对应关系,因此可以通过特征块中的最近邻搜索来有效地执行跟踪。
3.4实施细则
Adam优化器 pytorch基础 当所有操纵点不超过d像素远离其对应的目标点,其中对于d不超过5个操纵点,设置为1,否则设置为2。我们还开发了一个GUI来支持交互式图像操作。用户每次编辑只需等待几秒钟,就可以继续编辑,直到满意为止。
4.实验
数据集:FFHQ (512)........
4.1定性评价
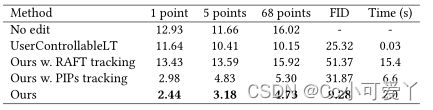
与UserControllableLT、PIPs 、RAFT做对比。

将真实图像嵌入StyleGAN的潜在空间中的GAN反演技术,我们还可以将我们的方法应用于操纵真实图像。可以编辑姿势、头发、形状、表情等。
 4.2定量评价
4.2定量评价
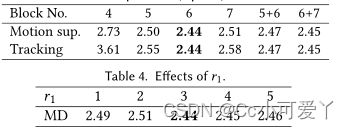
如FID分数所示,我们的方法保留了更好的图像质量。 得益于更好的跟踪能力,我们还实现了比RAFT和PIP更准确的操纵。不准确的跟踪也会导致过度的操作,这会降低图像质量,如FID分数所示。尽管UserControllableLT更快,但我们的方法在很大程度上突破了这项任务的上限,实现了更忠实的操作,同时为用户保持了舒适的运行时间。在运动监督和点跟踪中,StyleGAN的第6个块之后的特征图表现最好,显示了分辨率和判别力之间的最佳平衡。
4.3讨论
遮罩效果
只有遮罩部分改变,当在狗的头上进行遮罩时,其他区域几乎是固定的,只有头部在移动。在没有面具的情况下,操纵会移动整个狗的身体。这也表明,基于点的操作通常具有多种可能的解决方案,并且GAN将倾向于在从训练数据学习的图像流形中找到最接近的解决方案。掩码函数可以帮助减少歧义并保持某些区域的固定。

分布外泛化
我们的方法具有一定的外推能力,可以在训练图像分布之外创建图像,例如,一个张开的嘴和一个大轮子。在某些情况下,用户可能希望始终将图像保持在训练分布中,并防止其达到这种分布外操作。实现这一点的一种潜在方法是向潜在代码添加额外的正则化w

局限性
人体姿势导致伪影和无纹理区域导致漂移
社会影响
5.结论
我们介绍了DragGAN,这是一种用于直观的基于点的图像编辑的交互式方法。我们的方法利用预先训练的GAN来合成图像,这些图像不仅精确地遵循用户输入,而且保持在逼真图像的流上。与之前的许多方法相比,我们提出了一个通用框架,不依赖于特定领域的建模或辅助网络。这是使用两种新的部分来实现的:一种是潜在代码的优化,它将多个操纵点向其目标位置递增地移动,另一种是点跟踪程序,它忠实地跟踪操纵点的轨迹。这两部分都利用GAN的中间特征图的判别质量来产生像素精确的图像变形和交互性能。我们已经证明,我们的方法在基于GAN的操作方面优于现有技术,并为使用生成先验的强大图像编辑开辟了新的方向。关于未来的工作,我们计划将基于点的编辑扩展到3D生成模型。