某网站JS加密、OB混淆与CSS反爬实战分析
1. 写在前面
最近一段时间接触了一些小说网站的业务。发现很多的小说网站,甚至一些小站它们的安全防护措施做的都很到位!例如上次说到的的五秒盾也是存在于一个小说小站。今天要讲的这个网站它集JS加密、ob混淆、CSS反爬于一体
目标站点:
aHR0cHM6Ly93d3cuaG9uZ3NodS5jb20vY29udGVudC8xMTM3NzIvMjA1NDI1LTE0NTU1NzIuaHRtbA==
2. 分析
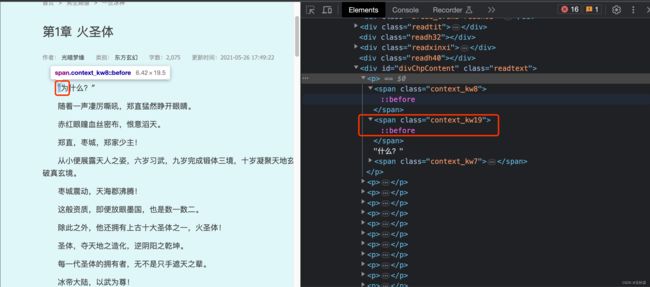
这次主要说的就是小说内容这块,打开这个网站的你会发现内容是不允许复制的。其次页面呈现的内容里面有一部分数据是隐藏的,虽然在页面你看它显示都正常,但在原代码中是没有的,而是由类似span标签代替的
这种反爬虫的手段主要先限制我们对页面的一些操作,然后将某些内容进行加密,最后在网页加载的时候通过解密算法进行解密从而渲染加载到网页
首先,碰到这种情况,我们可以先假设它这个页面的内容是经过二次请求,从接口拿到数据在进行渲染的
所以,我们可以先刷新页面看看XHR下的请求,简单的分析一波

可以看到某个请求的响应中有一个content字段,一看就知道它是经过加密处理的。这个字段的字面意思倒是可以让我们怀疑它是网页需要呈现的内容数据
在JS逆向中,可以记住大致的主流程,当然主流程里面涉及到的各种技巧与手法又可以开枝散叶,本文不做过多的描述。以后慢慢覆盖讲解:

3. 定位
这里我们其实已经知道content字段很有可能是经过加密后的小说内容。所以到这一步我们还是有比较多的方法进行定位,可以直接点击Initiator跟一下请求的调用栈
同样根据你的经验进行一些预判!如全局搜索一下可疑的关键字。这里我们可以看上面的加密肯定与base64有关,加密的数据也必然会走解密decrypt逻辑,这些可疑的关键词对象都可以是我们入手的点

上述通过分析定位找到可疑的JS代码,可以看到这里大概率是一个解密函数的调用,我们埋一个断点重新刷新请求一下:
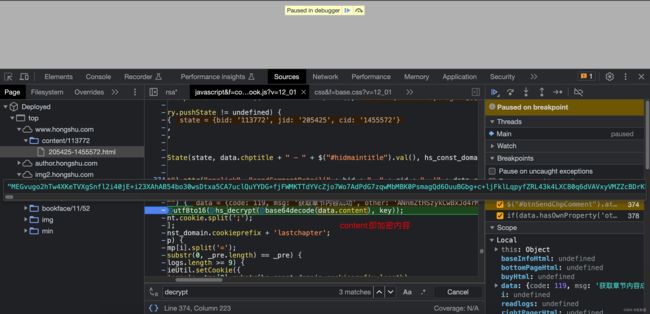
断点到此处后,我们可以看到content字段,就是一串密文,而这段密文依次调用了utf8to16、hs_decrypt、base64decode这三个函数。这里我们可以大胆的猜想它们就是解密函数
3. 扣代码
现在我们可以去印证我们最开始的猜想,content字段到底是不是解密后的小说内容,我们将上面几个函数的js代码扣出来
function base64decode(str) {
var c1, c2, c3, c4, base64DecodeChars = new Array(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,62,-1,-1,-1,63,52,53,54,55,56,57,58,59,60,61,-1,-1,-1,-1,-1,-1,-1,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,-1,-1,-1,-1,-1,-1,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,-1,-1,-1,-1,-1);
var i, len, out;
len = str.length;
i = 0;
out = "";
while (i < len) {
do {
c1 = base64DecodeChars[str.charCodeAt(i++) & 0xff];
} while (i < len && c1 == -1);if (c1 == -1)
break;
do {
c2 = base64DecodeChars[str.charCodeAt(i++) & 0xff];
} while (i < len && c2 == -1);if (c2 == -1)
break;
out += String.fromCharCode((c1 << 2) | ((c2 & 0x30) >> 4));
do {
c3 = str.charCodeAt(i++) & 0xff;
if (c3 == 61)
return out;
c3 = base64DecodeChars[c3];
} while (i < len && c3 == -1);if (c3 == -1)
break;
out += String.fromCharCode(((c2 & 0XF) << 4) | ((c3 & 0x3C) >> 2));
do {
c4 = str.charCodeAt(i++) & 0xff;
if (c4 == 61)
return out;
c4 = base64DecodeChars[c4];
} while (i < len && c4 == -1);if (c4 == -1)
break;
out += String.fromCharCode(((c3 & 0x03) << 6) | c4);
}
return out;
}
function str2long(s, w) {
var len = s.length;
var v = [];
for (var i = 0; i < len; i += 4) {
v[i >> 2] = s.charCodeAt(i) | s.charCodeAt(i + 1) << 8 | s.charCodeAt(i + 2) << 16 | s.charCodeAt(i + 3) << 24;
}
if (w) {
v[v.length] = len;
}
return v;
}
function hs_decrypt(str, key) {
if (str == "") {
return "";
}
var v = str2long(str, false);
var k = str2long(key, false);
var n = v.length - 1;
var z = v[n - 1]
, y = v[0]
, delta = 0x9E3779B9;
var mx, e, q = Math.floor(6 + 52 / (n + 1)), sum = q * delta & 0xffffffff;
while (sum != 0) {
e = sum >>> 2 & 3;
for (var p = n; p > 0; p--) {
z = v[p - 1];
mx = (z >>> 5 ^ y << 2) + (y >>> 3 ^ z << 4) ^ (sum ^ y) + (k[p & 3 ^ e] ^ z);
y = v[p] = v[p] - mx & 0xffffffff;
}
z = v[n];
mx = (z >>> 5 ^ y << 2) + (y >>> 3 ^ z << 4) ^ (sum ^ y) + (k[p & 3 ^ e] ^ z);
y = v[0] = v[0] - mx & 0xffffffff;
sum = sum - delta & 0xffffffff;
}
return long2str(v, true);
}
function long2str(v, w) {
var vl = v.length;
var sl = v[vl - 1] & 0xffffffff;
for (var i = 0; i < vl; i++) {
v[i] = String.fromCharCode(v[i] & 0xff, v[i] >>> 8 & 0xff, v[i] >>> 16 & 0xff, v[i] >>> 24 & 0xff);
}
if (w) {
return v.join('').substring(0, sl);
} else {
return v.join('');
}
}
function utf8to16(str) {
var out, i, len, c;
var char2, char3;
out = "";
len = str.length;
i = 0;
while (i < len) {
c = str.charCodeAt(i++);
switch (c >> 4) {
case 0:
case 1:
case 2:
case 3:
case 4:
case 5:
case 6:
case 7:
out += str.charAt(i - 1);
break;
case 12:
case 13:
char2 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x1F) << 6) | (char2 & 0x3F));
break;
case 14:
char2 = str.charCodeAt(i++);
char3 = str.charCodeAt(i++);
out += String.fromCharCode(((c & 0x0F) << 12) | ((char2 & 0x3F) << 6) | ((char3 & 0x3F) << 0));
break;
}
}
return out;
}
function decrypt(content,key){
return utf8to16(hs_decrypt(base64decode(content), key))
}
decrypt函数是自己定义的,为了更好的调用上面的解密函数。同时可以看到,解密函数调用的时候不光是传了content参数,还有一个key,那么我们现在需要分析key这个值是什么
回到接口请求分析那一步,之前第一次分析的时候,就把所有的请求都看了一遍,自然有发现这个key也是在XHR请求响应中的

现在,我们只需要从这两个接口当中请求拿到content与key值就能调用我们的JS解密算法进行解密
这里我们可以在Console控制台把js代码放进去再构造一下content与key即可验证,得到的结果正如我们猜想,它就是加密后的内容,如下是解密后的数据:
4. CSS反爬绕过
现在我们已经得到了页面加密的内容、解密算法。但是可以看到解密出来后的数据是不完整的,被隐藏了。现在要做的就是拿到被隐藏的那些文字内容,这样整个页面的内容才是全的
我们再回过头看之前的请求分析,这个图里面除了content字段还有一个ohter字段的值貌似也是经过加密处理的

不要考虑那么多,现在为止我们只要这么想,所有的数据在呈现到前端页面时,必定是有迹可循的。不管是后端加密还是前端加密,都是一样,我们直接用解密函数在控制台看看,如下:
很可惜这并不是所缺失的那些内容,倒像是一段JS代码,不过好像也并不是正常的JS代码,显然经过了混淆。但是好在结构还算清晰
我们不用管这里面的具体加密与解密算法是怎样的,只需要分析它的加密跟解密的逻辑最后调用即可
ob混淆里面有一个大数组:
var _0x09d1 = ['uJtRs', 'RyzMW', 'wkLRG', 'prototype', 'endWith', 'GIvaF', 'test', 'enc', '0767CD2FAAF99E58', 'window', 'location', 'href', 'Latin1', 'parse', 'D063F0602455077D', '146385F634C9CB00', 'ZeroPadding', 'toString', 'Utf8', 'split', 'createElement', 'style', 'setAttribute', 'type', 'async', 'head', 'cqrvw', 'link', 'nNyBj', 'length', 'parentNode', 'insertBefore', 'appendChild', '4|1|5|3|2|0', 'fromCharCode', 'tMLmi', 'OAWFf', 'KUtvo', 'KgGRl', 'qBUPd', 'addRule', '.context_kw', '::before', 'styleSheets', 'cssRules', 'pad', 'ZFebI', 'clamp', 'qVUkH', 'sigBytes', 'words', 'xsbdD', 'ouYQw']
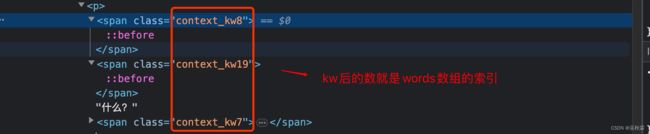
这个数组基本是明文的,很多大厂网站这个数组全是跟变量_0x09d1一样全是十六进制的,其实经过分析就能发现words就是被打散隐藏的缺失内容

到了这一步,我们第一种方案则可以根据span标签里的class的数字索引去取words数组里面的值了
5. 内容还原
当然还有另外一种还原内容的方案,这里我建议使用JS注入然后渲染
html = ''+content+''
r = HTML(html=html)
script_code = '''
var span_list = document.getElementsByTagName("span");
for (var i=0; i
r.render(script=script_code, reload=False)
print(r.find('body', first=True).text)
上面的font color=#ff0033 size=3>ohter就是我们解密出来的那段js混淆代码,也就是用来还原缺失内容的关键函数,它就是我们上面的js参数,然后content就是我们上面还原的第一阶段解密出来的content值
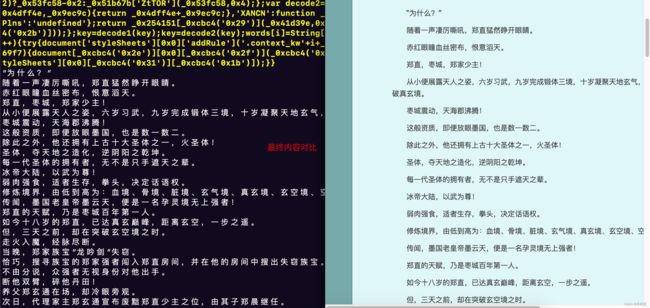
解密后的网页内容:
解密后的JS混淆代码:
注入后拿到的页面完整内容:
好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章