单机 T 级流量转发吞吐提升 5 倍,可编程负载均衡网关 1.0 上线
一、背景
负载均衡网关是云计算网络的一个关键基础设施,为云计算各应用业务提供高性能的转发功能。
目前云计算网关普遍是基于 X86 CPU + DPDK 通用服务器平台的形态实现。百度智能云自研的 BGW(BaiduGateWay)四层负载均衡网关 2012 年开始使用,从最初的单机 10Gbps 吞吐演进到目前单机 200Gbps,是一种云计算网络中用量最多的网关。
随着百度智能云业务的发展,对负载均衡网关提出了新的需求与挑战:
-
单核计算能力受限。为了防止报文乱序,需要同一条业务流调度到同一个网关的同一个 CPU 核上处理。由于 CPU 单核能力已基本停止提升,因此单流的极限吞吐能力发展缓慢。如今,即使采用最新的 CPU,单流的实际吞吐能力也仅能做到 10-20Gbps,而这一数据也只是理想情况下的最优结果。
如果两个或更多的大流量被同时调度到同一个 CPU 核上,由于处理能力的限制,那么会因争抢 CPU 引起相互影响而降低业务整体吞吐量;更坏情况下,该 CPU 核上处理的其他流量也会受到影响,可能导致概率性的丢包。
-
时延不稳定。使用 CPU 软件处理相对于硬件转发而言,通常有较高的时延。在软件网关上,一个报文的处理流程要经过以下步骤:从网卡接收开始,经过 PCIe 送到 CPU 上的 DPDK 驱动,然后网关软件再做业务逻辑处理,之后提交给 DPDK 驱动,最后经过 PCIe 下发到网卡上再发送出去。
从实测结果来看,当前百度智能云的软件网关在一般负载水平下的报文平均处理时延通常在 30-50us,转发负载较高时 100us 以上的长尾时延也很常见,极端情况甚至会出现 ms 级的时延。另外时延波动和 CPU 缓存的实际命中情况密切相关,难以预期。较大时延波动尺度对于跨机房或跨地域的通信一般没什么实质影响,但是对于强依赖同机房内低时延的业务来说访问的影响却较大。
-
大带宽场景的 TCO(Total Cost of Ownership)较高。尽管 CPU 的核数在不断提升,但是在网关这种重 I/O 吞吐的业务上,软件处理报文的能力并不能随着 CPU 核数线性提升。例如,使用 64 物理核的 AMD Milan 服务器上运行 BGW,当 32 核以上增加 CPU 核数,对整体吞吐则没有明显的增加。这一现象和当前 CPU 的微架构(尤其是 L3 缓存)强相关。
实际上当前软件网关通常可承诺的带宽规格大致上是 100-200G(如果只考虑大包也能做到 400G)。如果需要一个网关的集群支撑 10T 带宽,那么即使在不考虑冗余的情况下,也需要部署 50-100 台服务器。
综上所述,基于 X86 CPU 通用服务器的软件网关,随业务量的增加和深度使用单网关性能将无法进一步满足需求,吞吐性能提升困难,同时无法解决高负载时延时大幅增加、易抖动,大流量时打满 CPU 造成丢包等问题。
二、解决方案
为了应对不断发展的业务需求,百度智能云打造了第三代可编程网关平台 – UNP(Universal Networking Platform)。UNP 平台将 X86 CPU、可编程交换芯片、FPGA 加速卡融合在一起,形成一个可扩展的异构融合网关平台。相比 X86 软件网关平台该 UNP 具备如下优势:
-
可编程交换芯片可提供 T 级别的带宽吞吐能力;
-
通过硬件网络芯片 + X86 CPU 同时支持硬件网关和传统软件网关的运行,提供强大的灵活性和超融合能力;
-
通过扩展插槽提供更多硬件加速扩展能力。
通过引入 UNP 平台可充分发挥软硬一体化的技术优势,百度智能云在 2023 年 1 月推出了可编程负载均衡 UNP-BGW 网关 1.0,有效解决了负载均衡网关中的大带宽、大象流、低延迟等问题需求,为负载均衡网关带来如下收益:
-
通过软硬结合、session 表硬件 offload 卸载提升网关吞吐的性能,可以提供单网关 T 级大带宽,同时大幅降低网关用量成本。
-
降低网关产品的网络延迟、解决高负载场景下网关丢包和抖动问题。
可编程负载均衡 UNP-BGW 网关 1.0 主要分两部分,X86 网关部分和可编程交换芯片部分。
X86 部分依然使用 DPDK 的方案处理管控配置、路由转发控制、session 管理和非 offload 的报文负载均衡功能转发,单独从这个角度来看,类似部署了一台双 NUMA 的 X86-BGW。
路由的外围控制原理如下图所示,两个 NIC 网卡以标准网卡的形式出现在用户空间,它的另外一端直连可编程交换芯片。图中 Vnic0 ~ VnicN 是使用可编程交换芯片提供的驱动生成的虚拟网络设备,这些设备的主要作用有两个:收发路由报文和抓包诊断:
-
发送和接收 BGP 路由协议相关的数据包,与交换机形成路由关系,将流量引入这台设备;
-
在需要进行抓包时,把端口进入的流量镜像一份,送给 X86 用户空间虚拟网络设备,可以抓包排查问题。

数据转发处理的原理如下图所示,相对于普通 X86-BGW,UNP-BGW 转发分成两条路径:
-
Fast-Path:快速路径,命中 session 的流量由 ASIC 可编辑硬件转发,提供硬件 T 级别的转发能力和 us 级的低时延;
-
Slow-Path:慢速路径,未命中 session 的流量上送 CPU,按配置指令决策是否下发 session 走快速路径。
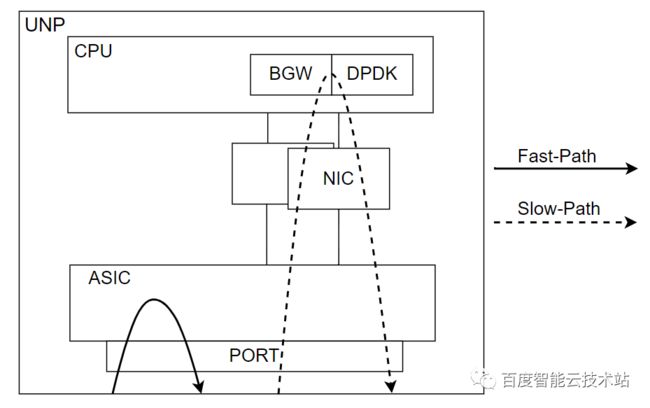
对于一条业务流的第一个建立连接的报文,UNP-BGW 接收到之后,ASIC 查询本硬件没有 session 时,会走 Slow-Path 并上送 CPU 做新建 session 处理。
BGW 定期获取 session 流量统计,当这条流转发稳态达到一定时间,且带宽 bps 或者 pps 达到指定阈值时,BGW 判定此流为大象流,并将此 session 下发到 ASIC 可编程硬件做 session offload。
当连接主动断开或者无流量导致超时,CPU 会及时老化掉 ASIC 可编程硬件的 session,以便硬件资源的合理使用。
相比传统的软件网关,UNP-BGW 1.0 具备如下产品特点:
-
容量:单机带宽吞吐扩大 5 倍以上,200Gbps 升级为大于 1Tbps 能力;
-
时延:平均转发时延降低 20 倍以上,高负载时 100us 降至稳定小于 4us 无抖动,转发更快速;
-
丢包率:十万分之一降至数亿分之一,网络更可靠;
-
成本:实现了单机转发能力的提升,承接更大规模流量时可以减少部署成本;
-
能耗:所需部署机器的减少,T 级别吞吐时整体能耗下降 50% 以上,实现碳减排。
典型案例
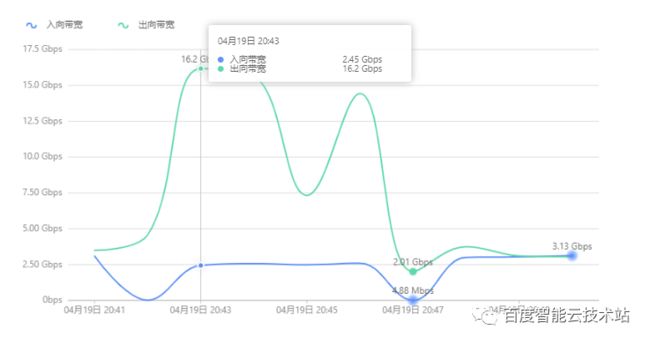
某读写存储的业务用户经常有单条大象流(带宽 15Gbps 左右)的读业务数据请求,使用 X86-BGW 软件网关集群时,导致单网关上 CPU 使用率高达 90%,影响了其他业务的转发处理。


当用户切换到 UNP-BGW 网关后,同业务读写条件下单条大象流还能提升到 16Gbps,流量 offload 后单 CPU 的使用率不到 1%。

可编程负载均衡 UNP-BGW 网关 1.0 带来了带宽、时延、丢包率等性能指标的大幅提升,该产品已经用于加速对象存储 BOS 服务,大家可以进入到百度智能云官网的服务网卡产品页面中,在创建服务网卡时选择 BOS 接入点使用。

可编程负载均衡 1.0 版本网关因 ASIC 硬件的存储空间仅几百 Mb,session 表容量有限,可以通过扩展 FPGA 加速卡提升大表项能力,进一步的提升可编程负载均衡能力。
百度智能云正在加速推出 UNP-BGW 2.0 版本,具备更高 offload 卸载能力,满足高带宽千万级 session 负载均衡需求 。
- - - - - - - - - - END - - - - - - - - - -
推荐阅读:
百度工程师移动开发避坑指南——内存泄漏篇
增强型语言模型——走向通用智能的道路?
基于公共信箱的全量消息实现
百度APP iOS端包体积50M优化实践(二) 图片优化
浅论分布式训练中的recompute机制
剖析多利熊业务如何基于分布式架构实践稳定性建设