1、首先在官网下载graphviz
下载网址:https://www.graphviz.org/download/
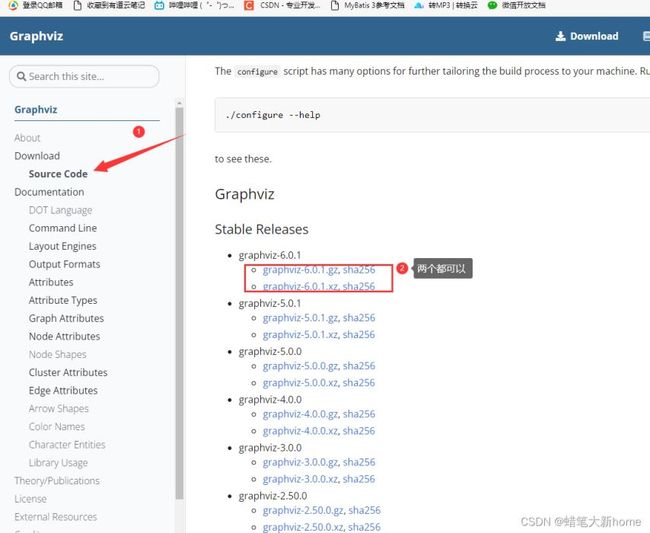
2、安装。
打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz
接着一直点下一步,即可安装完成。
3、配置环境变量
右键点击“我的电脑“”–>选择“属性”–>高级系统设置(滑到最下面)
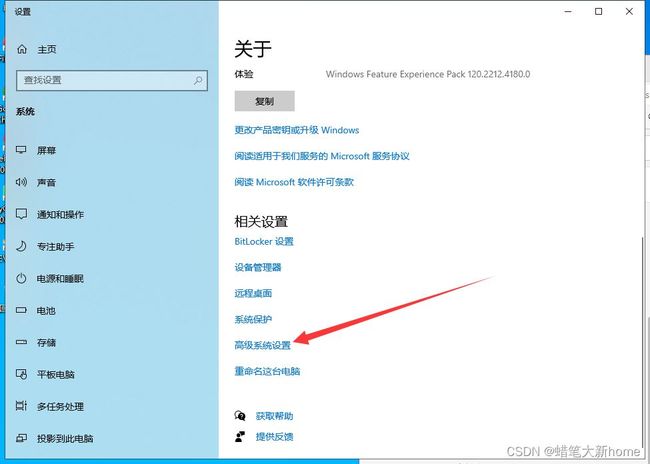
–>环境变量–>系统变量中的path(双击)
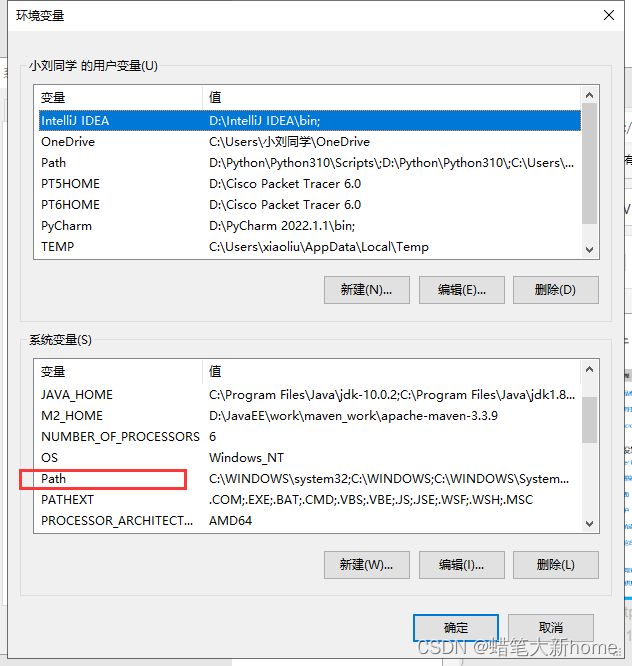
–>将graphviz的安装路径下的bin文件添加进去。如果你前面安装的路径是跟我一样,直接复制这个路径即可D:\graphviz\bin
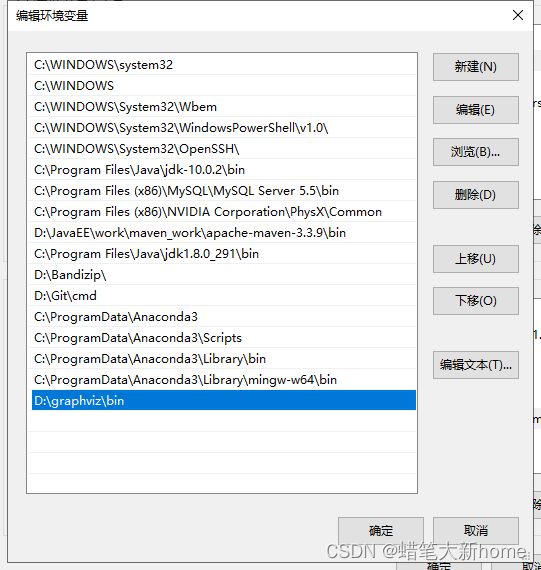
–>多次点击确定,完成环境变量配置,
4、测试
点击左下角搜索,输入“cmd”,或者 win+R键。
输入 dot -version (注意dot后面后一个空格)。
若出现dot不是内部或外部命令,则表示安装失败。
5、再次配置
接下来打开你安装路径下bin文件夹下面的config6(选择打开方式为记事本打开)
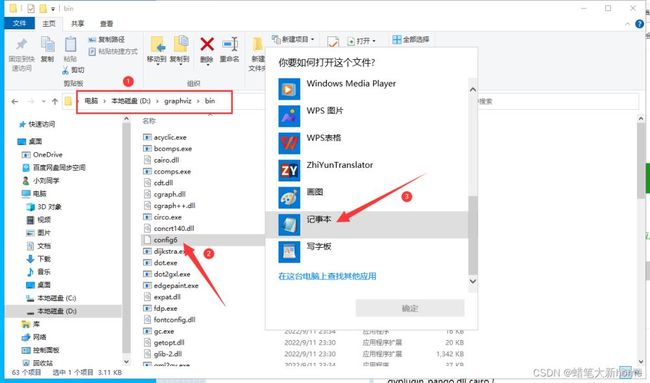
将里面内容删除,复制下面这段代码,保存即可。
import operator
import math
class DecisionTree:
def __init__(self):
pass
# 加载数据集
def loadData(self):
# 天气晴(2),阴(1),雨(0);温度炎热(2),适中(1),寒冷(0);湿度高(1),正常(0)
# 风速强(1),弱(0);进行活动(yes),不进行活动(no)
# 创建数据集
data = [
[2, 2, 1, 0, "yes"],
[2, 2, 1, 1, "no"],
[1, 2, 1, 0, "yes"],
[0, 0, 0, 0, "yes"],
[0, 0, 0, 1, "no"],
[1, 0, 0, 1, "yes"],
[2, 1, 1, 0, "no"],
[2, 0, 0, 0, "yes"],
[0, 1, 0, 0, "yes"],
[2, 1, 0, 1, "yes"],
[1, 2, 0, 0, "no"],
[0, 1, 1, 1, "no"],
]
# 分类属性
features = ["天气", "温度", "湿度", "风速"]
return data, features
# 计算给定数据集的香农熵
def ShannonEnt(self, data):
numData = len(data) # 求长度
labelCounts = {}
for feature in data:
oneLabel = feature[-1] # 获得标签
# 如果标签不在新定义的字典里创建该标签值
labelCounts.setdefault(oneLabel, 0)
# 该类标签下含有数据的个数
labelCounts[oneLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
# 同类标签出现的概率
prob = float(labelCounts[key]) / numData
# 以2为底求对数
shannonEnt -= prob * math.log2(prob)
return shannonEnt
# 划分数据集,三个参数为带划分的数据集,划分数据集的特征,特征的返回值
def splitData(self, data, axis, value):
retData = []
for feature in data:
if feature[axis] == value:
# 将相同数据集特征的抽取出来
reducedFeature = feature[:axis]
reducedFeature.extend(feature[axis + 1 :])
retData.append(reducedFeature)
return retData # 返回一个列表
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(self, data):
numFeature = len(data[0]) - 1
baseEntropy = self.ShannonEnt(data)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeature):
# 获取第i个特征所有的可能取值
featureList = [result[i] for result in data]
# 从列表中创建集合,得到不重复的所有可能取值
uniqueFeatureList = set(featureList)
newEntropy = 0.0
for value in uniqueFeatureList:
# 以i为数据集特征,value为返回值,划分数据集
splitDataSet = self.splitData( data, i, value )
# 数据集特征为i的所占的比例
prob = len(splitDataSet) / float(len(data))
# 计算每种数据集的信息熵
newEntropy += prob * self.ShannonEnt(splitDataSet)
infoGain = baseEntropy - newEntropy
# 计算最好的信息增益,增益越大说明所占决策权越大
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# 递归构建决策树
def majorityCnt(self, labelsList):
labelsCount = {}
for vote in labelsList:
if vote not in labelsCount.keys():
labelsCount[vote] = 0
labelsCount[vote] += 1
sortedLabelsCount = sorted(
labelsCount.iteritems(), key=operator.itemgetter(1), reverse=True
) # 排序,True升序
# 返回出现次数最多的
print(sortedLabelsCount)
return sortedLabelsCount[0][0]
# 创建决策树
def createTree(self, data, features):
# 使用"="产生的新变量,实际上两者是一样的,避免后面del()函数对原变量值产生影响
features = list(features)
labelsList = [line[-1] for line in data]
# 类别完全相同则停止划分
if labelsList.count(labelsList[0]) == len(labelsList):
return labelsList[0]
# 遍历完所有特征值时返回出现次数最多的
if len(data[0]) == 1:
return self.majorityCnt(labelsList)
# 选择最好的数据集划分方式
bestFeature = self.chooseBestFeatureToSplit(data)
bestFeatLabel = features[bestFeature] # 得到对应的标签值
myTree = {bestFeatLabel: {}}
# 清空features[bestFeat],在下一次使用时清零
del (features[bestFeature])
featureValues = [example[bestFeature] for example in data]
uniqueFeatureValues = set(featureValues)
for value in uniqueFeatureValues:
subFeatures = features[:]
# 递归调用创建决策树函数
myTree[bestFeatLabel][value] = self.createTree(
self.splitData(data, bestFeature, value), subFeatures
)
return myTree
# 预测新数据特征下是否进行活动
def predict(self, tree, features, x):
for key1 in tree.keys():
secondDict = tree[key1]
# key是根节点代表的特征,featIndex是取根节点特征在特征列表的索引,方便后面对输入样本逐变量判断
featIndex = features.index(key1)
# 这里每一个key值对应的是根节点特征的不同取值
for key2 in secondDict.keys():
# 找到输入样本在决策树中的由根节点往下走的路径
if x[featIndex] == key2:
# 该分支产生了一个内部节点,则在决策树中继续同样的操作查找路径
if type(secondDict[key2]).__name__ == "dict":
classLabel = self.predict(secondDict[key2], features, x)
# 该分支产生是叶节点,直接取值就得到类别
else:
classLabel = secondDict[key2]
return classLabel
if __name__ == "__main__":
dtree = DecisionTree()
data, features = dtree.loadData()
myTree = dtree.createTree(data, features)
print(myTree)
label = dtree.predict(myTree, features, [1, 1, 1, 0])
print("新数据[1,1,1,0]对应的是否要进行活动为:{}".format(label))
最后再次通过cmd测试是否安装成功。命令:dot -version (同样注意dot后有一个空格)
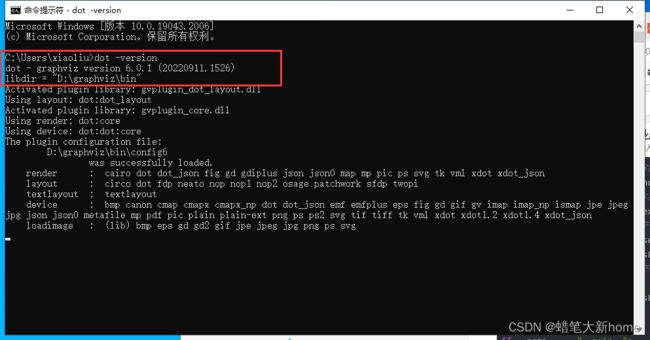
出现这段文字。显示dot版本和路径,恭喜你安装成功。
到此这篇关于graphviz 2022最新安装教程适用初学者的文章就介绍到这了,更多相关graphviz 安装教程内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!