目标检测 | Anchor free之CenterNet深度解析
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
1 前言
本文接着上一讲对CornerNet的网络结构和损失函数的解析,链接如下
https://zhuanlan.zhihu.com/p/188587434https://zhuanlan.zhihu.com/p/195517472
本文来聊一聊Anchor-Free领域耳熟能详的CenterNet。
原论文名为《Objects as Points》,有没有觉得这种简单的名字特别霸气,比什么"基于xxxx的xxxx的xxxx论文"帅气多了哈。
虽然这名字够短,但是内容却非常充实。将物体看成点进行检测,那么应用主要有以下三点
(1)物体检测
(2)3D定位
(3)人体姿态估计
本文的代码看的是基于keras版本的。链接如下
https://github.com/see--/keras-centernet
2.网络结构
顾名思义,CornerNet以检测框的两个角点为基础进行物体的检测,而CenterNet以检测框的中心为基础进行物体位置的检测.
CenterNet和CornerNet的网络结构类似,如下为CornerNet的网络结构。
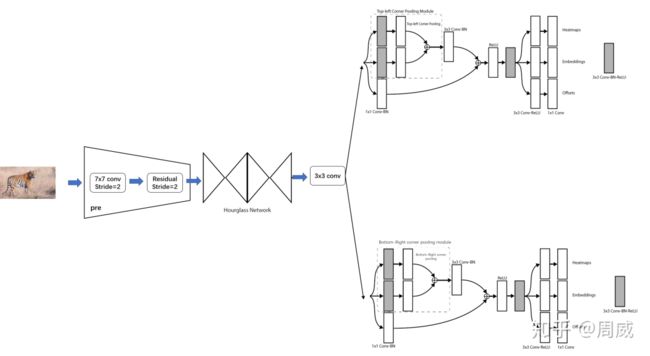 图1
图1
由于CornerNet需要进行两个关键点检测(左上角点和右下角点)来判断物体的位置,所以共有两个大分支(每个大分支中又包含了三个小分支)。
而 CenterNet只需要进行一个关键点的检测(中心点的检测)来判断物体的位置,所以只有一个大的分支,该分支包含了三个小分支(虽然这三个小分支和CornerNet的还是有区别的)。基于Hourglass backbone的CenterNet结构如下图所示
 图2
图2
该网络要比CornerNet更简单,而且细心的小伙伴们应该也发现了和CornerNet分支输出存在一定的异同之处,该网络输出分支分别为
(1)HeatMap,大小为(W/4,H/4,80),输出不同类别(80个类别)物体中心点的位置
(2) Offset,大小为(W/4,H/4,2),对HeatMap的输出进行精炼,提高定位准确度
(3) Height&Width,大小为(W/4,H/4,2),预测以关键点为中心的检测框的宽高
显然,(1)(2)在CornerNet中也出现过,但是Corner的另一个分支是输出每个被检测角点的embedding,即左上点的embedding和右上点的embedding距离足够近,则被认定为同一检测框的角点对。
另外在CornerNet中还有一个创新点,为Corner Pooling的提出,在CenterNet中被剔除了。
那么结合CenterNet的结构图
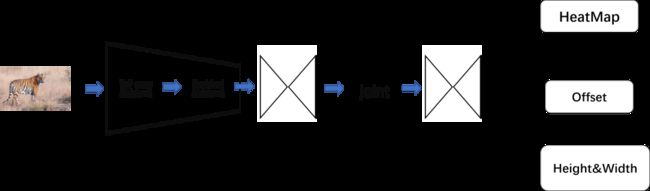 图2
图2
可以将其分为以下几个部分
(1)pre,通过一个步长为2的7x7卷积和步长为2的残差单元,将图片宽高压缩为原来的1/4
(2)Hourglass Module 1,第一个沙漏型的卷积神经网络模块
(3)joint,连接Hourglass Module 2和Hourglass Module 2
(4)Hourglass Module 2,第二个沙漏型的卷积神经网络模块
(5)Head,输出三个分支输出
具体代码实现为
def HourglassNetwork(heads, num_stacks, cnv_dim=256, inres=(512, 512), weights='ctdet_coco',
dims=[256, 384, 384, 384, 512]):
"""Instantiates the Hourglass architecture.
Optionally loads weights pre-trained on COCO.
Note that the data format convention used by the model is
the one specified in your Keras config at `~/.keras/keras.json`.
# Arguments
num_stacks: number of hourglass modules.
cnv_dim: number of filters after the resolution is decreased.
inres: network input shape, should be a multiple of 128.
weights: one of `None` (random initialization),
'ctdet_coco' (pre-training on COCO for 2D object detection),
'hpdet_coco' (pre-training on COCO for human pose detection),
or the path to the weights file to be loaded.
dims: numbers of channels in the hourglass blocks.
# Returns
A Keras model instance.
# Raises
ValueError: in case of invalid argument for `weights`,
or invalid input shape.
"""
if not (weights in {'ctdet_coco', 'hpdet_coco', None} or os.path.exists(weights)):
raise ValueError('The `weights` argument should be either '
'`None` (random initialization), `ctdet_coco` '
'(pre-trained on COCO), `hpdet_coco` (pre-trained on COCO) '
'or the path to the weights file to be loaded.')
input_layer = Input(shape=(inres[0], inres[1], 3), name='HGInput')
inter = pre(input_layer, cnv_dim)
prev_inter = None
outputs = []
for i in range(num_stacks):
prev_inter = inter
_heads, inter = hourglass_module(heads, inter, cnv_dim, i, dims) # return the heads that include three branchs
outputs.extend(_heads)
if i < num_stacks - 1:
# the joint between the first hourglass module and the second ones
inter_ = Conv2D(cnv_dim, 1, use_bias=False, name='inter_.%d.0' % i)(prev_inter)
inter_ = BatchNormalization(epsilon=1e-5, name='inter_.%d.1' % i)(inter_)
cnv_ = Conv2D(cnv_dim, 1, use_bias=False, name='cnv_.%d.0' % i)(inter)
cnv_ = BatchNormalization(epsilon=1e-5, name='cnv_.%d.1' % i)(cnv_)
inter = Add(name='inters.%d.inters.add' % i)([inter_, cnv_])
inter = Activation('relu', name='inters.%d.inters.relu' % i)(inter)
inter = residual(inter, cnv_dim, 'inters.%d' % i)
model = Model(inputs=input_layer, outputs=outputs)
if weights == 'ctdet_coco':
weights_path = get_file(
'%s_hg.hdf5' % weights,
CTDET_COCO_WEIGHTS_PATH,
cache_subdir='models',
file_hash='ce01e92f75b533e3ff8e396c76d55d97ff3ec27e99b1bdac1d7b0d6dcf5d90eb')
model.load_weights(weights_path)
elif weights == 'hpdet_coco':
weights_path = get_file(
'%s_hg.hdf5' % weights,
HPDET_COCO_WEIGHTS_PATH,
cache_subdir='models',
file_hash='5c562ee22dc383080629dae975f269d62de3a41da6fd0c821085fbee183d555d')
model.load_weights(weights_path)
elif weights is not None:
model.load_weights(weights)
return model有关注释都在上面了,具体定义请结合源代码进行查看。
一、介绍3.检测框获取Decode
前面我们已经知道了CenterNet网络有三个输出,分别为
(1) HeatMap,大小为(W/4,H/4,80),输出不同类别(80个类别)物体中心点的位置
(2) Offset,大小为(W/4,H/4,2),对HeatMap的输出进行精炼,提高定位准确度
(3) Height&Width,大小为(W/4,H/4,2),预测以关键点为中心的检测框的宽高
那么如何将这些输出转为直观的检测框信息呢?
在目标检测领域,通常将这一过程称为decode,就是根据网络的输出获取直观的检测框信息。
那么encode就是将检测框信息(通常为ground-truth bounding box的坐标、宽高信息)转化为形为网络输出的信息,便于网络损失函数的求解。
代码中实现decode这一过程的代码如下
def _ctdet_decode(hm, reg, wh, k=100, output_stride=4):
"""将网络的输出转换为标准的检测框信息"""
hm = K.sigmoid(hm)
hm = _nms(hm)
hm_shape = K.shape(hm)
reg_shape = K.shape(reg)
wh_shape = K.shape(wh)
# cat为通道数
batch, width, cat = hm_shape[0], hm_shape[2], hm_shape[3]
# 对输出的特征图进行铺平
hm_flat = K.reshape(hm, (batch, -1))
reg_flat = K.reshape(reg, (reg_shape[0], -1, reg_shape[-1]))
wh_flat = K.reshape(wh, (wh_shape[0], -1, wh_shape[-1]))
def _process_sample(args):
_hm, _reg, _wh = args
_scores, _inds = tf.math.top_k(_hm, k=k, sorted=True) # 寻找前k个heatmap的值
_classes = K.cast(_inds % cat, 'float32') #获取索引对应的类别
_inds = K.cast(_inds / cat, 'int32') #在某一类别中的位置(最大长度为 width*width),一维的
# 一维位置转二维坐标
_xs = K.cast(_inds % width, 'float32') #二维坐标中的横坐标
_ys = K.cast(K.cast(_inds / width, 'int32'), 'float32') #二维坐标的纵坐标
_wh = K.gather(_wh, _inds) #根据索引获得宽高数据
_reg = K.gather(_reg, _inds) #根据坐标获得offset
_xs = _xs + _reg[..., 0]
_ys = _ys + _reg[..., 1]
_x1 = _xs - _wh[..., 0] / 2
_y1 = _ys - _wh[..., 1] / 2
_x2 = _xs + _wh[..., 0] / 2
_y2 = _ys + _wh[..., 1] / 2
# rescale to image coordinates
_x1 = output_stride * _x1
_y1 = output_stride * _y1
_x2 = output_stride * _x2
_y2 = output_stride * _y2
_detection = K.stack([_x1, _y1, _x2, _y2, _scores, _classes], -1)
return _detection
detections = K.map_fn(_process_sample, [hm_flat, reg_flat, wh_flat], dtype=K.floatx())
return detections主要通过非极大值抑制(NMS)后在heatmap上寻找topk个最大值,即可能为物体中心的索引。然后根据这topk个中心点,寻找其对应的类别、宽高和offset信息。
这里的NMS并不像Anchor-free中的NMS(即利用检测框的IOU为距离基准求解极大值,抑制非极大值)。
而CenterNet的NMS,是寻找某点与其周围的八个点之间最大值,作为其NMS的极大值。那么该操作可以使用最简单的3x3的MaxPooling实现。
实现代码如下:
def _nms(heat, kernel=3):
hmax = K.pool2d(heat, (kernel, kernel), padding='same', pool_mode='max')
keep = K.cast(K.equal(hmax, heat), K.floatx())
return heat * keep貌似该keras代码中,并没有实现训练CenterNet的过程。所以我们没办法结合代码进行训练过程的解析,包括
(1)损失函数设定
(2)将ground-truth bounding box信息映射为类似网络输出的格式,被称为encode。
那么下面直接结合论文进行损失函数与encode的解析。
3.Encode
前面提到过Encode的过程是将ground-truth bounding box信息映射为类似网络输出的格式。这样可以加速求解损失函数的计算。
我们知道在CornerNet中将检测框的左上角点和右下角点映射到heatmap上的过程,并不是简单的一一对应关系的(也就是将原图中的某关键点映射到heatmap中的某一关键点中),而是将原图中的某关键点(在CenterNet中为检测框的中点)映射到heatmap中的某一高斯核区域内。如下图4所示,为每个检测框中心点的高斯核区域显示。
 图3 原图
图3 原图  图4 中心点映射范围
图4 中心点映射范围
又或者借用
https://zhuanlan.zhihu.com/p/66048276
中的图,为某一中心点在heatmap的映射可视化。可以直观地感受其呈现二维高斯分布。
 图5 某一中心点在heatmap的映射可视化
图5 某一中心点在heatmap的映射可视化
那么根据获得的heatmap,我们可以将ground-truth bbox的偏移信息和宽高信息按照该映射关系,等同地映射到前面提到的Offset特征图和Height&Width特征图中,实现整个encode的过程
4.损失函数的设置
实现了encode过程后,设定损失函数就变得非常简单了。
4.1 focal loss
原论文中令为网络输出的heatmap,为ground_truth信息,即heatmap的标签/监督信息。类似CornerNet使用focal loss进行损失函数设定,实现过程如下

这里的和为focal loss的超参数,N是图片中关键点的个数。
4.2 offset loss
为了弥补由于stride的原因造成的偏移误差,论文中设定了一个关于偏移的损失函数,使得训练后的网络能够有效计算offset值,从而修正检测框的位置。
不妨这里引用一下论文中的offset loss公式。
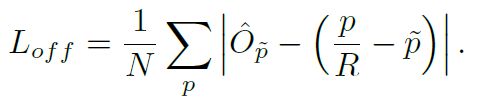 focal loss
focal loss
这里的p是检测框中心点(原图中)的真实坐标,p/R是理论上该中心点映射到特征图的准确位置区域(很可能是浮点型)。
但是我们知道在特征图中,所有的点的位置都是整型的(即不存在某一个点的位置为(1.1,2.9)的),所以实际上,原图中坐标为p的点映射到特征图后的位置应该是
是p向下取整的结果,所以这里就造成了误差了,那么这个误差就是
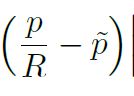
公式中的是网络的offset输出特征图。那么这个指的是关键点实际落入的区域。说明该offset loss只关注在关键点区域的offset输出。
4.3 height&width loss
用来训练物体宽高大小的损失函数就非常简单了。假设物体k的ground-truth坐标为
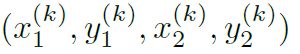
那么他的宽高为
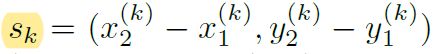
如果只考虑关键点实际落入的区域的输出特征图,也就是。该损失函数设定为
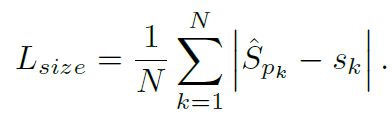
4.4 总损失
最后总损失函数为上面三个损失函数之和

5.总结
总的来说,CenterNet要比CornerNet学起来更加简单点,而且比CornerNet更实用,应用范围也更广!
该模型在Anchor-free目标检测领域和YOLO V3在Anchor-based目标检测领域的地位类似,非常推荐大家读一下原文!有关其在3D location和姿态估计等任务的应用,大家感兴趣可以自行学习。
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~