TTS | 文本转语音中的声码器(Vocoder)
在这篇文章中,我想详细说明 语音合成(TTS) 中的 Vocoder 部分。
目录
1.声码器(Vocoder)的作用
2.经典的声码器
2.1.WaveNet
2.2.WaveGlow
2.3.MelGAN
2.4.VocGAN
2.5.HiFi-GAN
参考文献
Reference
1.声码器(Vocoder)的作用
神经语音合成主要分为:
- 从文本中预测低分辨率表示,例如梅尔谱图或语言特征
- 从低分辨率表示中预测原始波形音频
一些常见的Deep Voice,Tacotron,Fastspeech的语音合成(TTS)模型是输入文本生成语音的过程,而声码器(Vocoder)是为了从原本的音频(.wav)转换为梅尔频谱图(mel-spectrogram)
为了在频域分析音频,可以执行短时傅里叶变换(STFT)来提取与频率分量相对应的特征点。其中,梅尔谱图可以通过使用与幅度分量对应的幅度值应用梅尔滤波器组并转换为梅尔尺度来获得。事实上,如果频率分量的幅度和相位值已知,STFT变换可以进行逆变换,因此可以在不丢失信息的情况下恢复原始语音。然而,对于通常预测和学习梅尔谱图的TTS模型来说,只能找到频率分量的幅度信息,要预测原始语音,必须预测相位信息,并且必须预测原始语音基于此。声码器执行此功能。
2.经典的声码器
神经声码器算法:使用深度学习的 Vocoder。目前主要使用的模型可以分为以下几种(有的论文分为3种,有的分为5种,本文根据【4】论文分类):
- 基于自回归的(auto-regressive):WaveNet, WaveRNN
- 基于流的(flows):WaveGlow, Parallel WaveNet
- 基于生成对抗网络模型(GAN)的:MelGAN, Parallel WaveGAN
- 基于VAE的
- 基于扩散(diffusion)的:WaveGrid,DiffWave
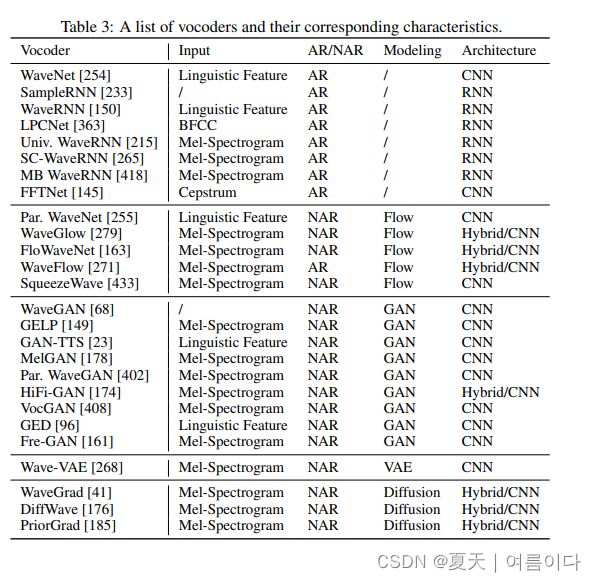
本文主要讲解一些经典的声码器(红色是务必知道的):

2.1.WaveNet
自回归生成模型 - WaveNet
WaveNet 利用 PixelCNN 这种自回归生成模型,在语音领域合成的语音质量比现有的串联和参数模型学习到的语音质量要好得多。然而,由于AR模型的性质,存在一个缺点,即需要花费太多时间进行学习和推理,并且已经进行了研究来弥补这一点。
2.2.WaveGlow
基于流的生成模型
随着基于流的模型(例如 Parallel WaveNet [6] 和 WaveGlow [7])的出现,合成语音的质量和速度被捕获。然而,WaveGlow 的一个缺点是模型需要太多参数。
2.3.MelGAN
生成对抗网络模型(GAN)
为了改善上述模型的缺点,合成语音的质量可能会有所下降,但可以有效提高速度和参数数量的 GAN 模型的研究。
2.4.VocGAN
生成对抗网络模型(GAN)
在声码器Melgan基础上提出的多刻度的声码器VocGan,解决了Melgan合成音质不高的问题。可以保持melgan合成速度的前提下提高音质,其中Loss的设计可以借鉴到其它声码器中,比如multiband系列声码器。
2.5.HiFi-GAN
生成对抗网络模型(GAN)
HiFi-GAN改善了之前的基于GAN的工作中语音质量较差的缺点,兼具了高计算效率和语音质量,
参考文献
【1】[정리] Neural Vocoder에 대해 알아보자
【2】딥러닝을 활용한 음성합성(TTS) 훑어보기(Vocoder) (tistory.com)
【3】Text To Speech — Foundational Knowledge (Part 2) | by Aaron Brown | Towards Data Science
【4】A Survey on Neural Speech Synthesis:2106.15561.pdf (arxiv.org)
【5】好用的语音合成声码器,你知道吗?(一)-云社区-华为云 (huaweicloud.com)
Reference
[1] Kong, Jungil, Jaehyeon Kim, and Jaekyoung Bae. "HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis." arXiv preprint arXiv:2010.05646 (2020).
[2] Ping, Wei, et al. "Deep voice 3: Scaling text-to-speech with convolutional sequence learning." arXiv preprint arXiv:1710.07654 (2017).
[3] Shen, Jonathan, et al. "Natural tts synthesis by conditioning wavenet on mel spectrogram predictions." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
[4] librosa.org/doc/main/generated/librosa.griffinlim.html
[5] Oord, Aaron van den, et al. "Wavenet: A generative model for raw audio." arXiv preprint arXiv:1609.03499 (2016).
[6] Oord, Aaron, et al. "Parallel wavenet: Fast high-fidelity speech synthesis." International conference on machine learning. PMLR, 2018.
[7] Prenger, Ryan, Rafael Valle, and Bryan Catanzaro. "Waveglow: A flow-based generative network for speech synthesis." ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.
[8] Kumar, Kundan, et al. "Melgan: Generative adversarial networks for conditional waveform synthesis." arXiv preprint arXiv:1910.06711 (2019).
[9] Bińkowski, Mikołaj, et al. "High fidelity speech synthesis with adversarial networks." arXiv preprint arXiv:1909.11646 (2019).
[10] Yang, Jinhyeok, et al. "VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network." arXiv preprint arXiv:2007.15256 (2020).