java 正则 线程安全_Java 学习 - 正则表达式
Java 学习 - 正则表达式
一.设计正则表达式的目的
正则表达式使用单个字符串来描述,匹配一系列匹配某个句法规则的字符串.在很多文本编辑器里,正则表达式通常被用来检索,替换那些匹配某个模式的文本. 许多程序设计语言都支持利用正则表达式进行字符串操作.与其说正则表达式是一个Java的库,倒不如说正则表达式是一个针对于字符串处理的语言.
二.正则表达式基本语法
在介绍正则表达式在Java中的使用方法之前,我们先介绍正则表达式的匹配方式. 毕竟,正则表达式并非Java所特有,应该更加注重正则表达式的功能,而非在Java中具体的实现方法.
模式串与文本串的概念
正则表达式用于判定文本串是否与给定的模式串匹配.文本串和模式串的概念为:
模式串是一个遵循某种规则的泛化的字符串, 其某些字符,字符串的长度可能不尽相同,一个模式串可能能够表示多种不同的文本串.
文本串是一个固定的字符串,文本串的每一个字符都是确定的.
模式串的格式
1.单个字符是一个模式串

2.一个字符集是一个模式串
字符集的作用是检验由单个字符所构成的文本串是否与字符集中的字符满足一定关系
- 属于(simple classes)
[abc] // 可以匹配的文本串: "a","b","c"
- 不属于(negation)
[^abc] // 可以匹配的文本串: 除了"a","b","c"的任意单个字符
- 属于某一范围(range)
[a-zA-Z] // 可以匹配的文本串: "a" ~ "z" ,"A"~"Z" 任意单个字符
- 属于并集(union)
[a-d[m-p]] // 可以匹配的文本串: "a"~"d" ,"m" ~ "p" 任意单个字符
这里我有一点疑虑: union和range的区别是什么? 等后期更加理解后补充进来.
- 属于交集(intersection)
[a-z&&[def]] // 可以匹配的字符串: [a-z] 和 [def] 取交集是[def],因此能够匹配 "d","e","f"
- 属于差集(subtraction)
[a-z&&[^m-p]] // 可以匹配的字符串: [a-z] 和 [^m-p]取交集是 [a-l][q-z],因此能够匹配"a"~"l","q"~"z"

此外,Java中还提供一些被预定义好的字符集


还有一些预定义字符集看起来不太常用,这里不再介绍.
3.包含边界匹配器的模式串
所谓边界匹配器,其实是对一个模式串增添一些附加条件,例如"出现在文本串的开头","出现在文本串的结尾"
明确一个观念对于理解边界匹配器有很大的帮助
边界匹配器的宽度为0,不影响模式串的长度;或者说,包含边界匹配器的模式串长度与剔除边界匹配器的模式串长度应当一致
常见的边界匹配器:

**示例**
^ 匹配文本串的开头
模式串
"^HelloWorld" // 所匹配的文本串: "HelloWorld"的部分,且必须满足"HelloWorld"在整个串的开头
匹配示例
#case1: "HelloWorld" // 匹配出 "HelloWorld"
#case2: "HeheHelloWorld" // 无匹配
#case3: "HelloWorldHehe" // 匹配出 "HelloWorld"
一个无意义的匹配:
"HelloWorld^" // 由于^匹配出文本串的开头位置,而"HelloWorld"永远不可能在开头位置之前,因此这个模式串永远不可能匹配成功
$ 匹配文本串的结尾
模式串
"HelloWorld$" // 所匹配的文本串
匹配示例
#case1: "HeheHelloWorld" // 匹配出 "HelloWorld"
#case2: "HelloWorldHehe" // 无匹配
#case3: "HelloWorld" // 匹配出"HelloWorld"
一个无意义的匹配:
"$HelloWorld" // 由于$匹配出文本串的开头位置,而"HelloWorld"永远不可能在结尾位置之后,因此这个模式串永远不可能匹配成功
\b 匹配单词边界
单词边界的意义是: 一侧为单词字符,另一侧为非单词字符. 其中单词字符包括[字母,数字,下划线,汉字],非单词字符还包括空字符.
模式串
\bapple
匹配示例
#case1: "apple" // 匹配出apple,因为a是一个单词字符,而a左边是一个空字符,\b的两侧满足一个为非单词字符,一个为单词字符
#case2: "bapple" // 无匹配,因为 \b的两侧为'b'和'a',均为非单词字符
#case3: " apple" // 匹配出"apple",因为\b的两侧分别为' '和'a'
#case4: "apple123456"
// 匹配出apple,因为a是一个单词字符,而a左边是一个空字符,\b的两侧满足一个为非单词字符,一个为单词字符,而后续的"123456"不影响结果
#case5: " app" // 无匹配,虽然\b的两侧为' '和'a',但后续的"apple"无匹配
两个无意义的匹配
" \b apple" // 因为\b两侧已经指定了必须为' '和' ',而它们都是非单词字符,不满足\b的条件,因此永远无法匹配成功
"a\bapple" // 因为\b两侧已经指定了必须为'a'和'a',而它们都是单词字符,不满足\b的条件,因此永远无法匹配成功
4.包含贪婪量词的模式串(有回溯贪婪量词)
贪婪量词的"贪婪"意义: 尽可能地多匹配字符;如果一个字符串满足要求,继续向后检测,是否仍然符合要求,如果仍符合要求则继续匹配
应当注意的是,"满足要求"并非指仅仅满足X部分的要求,而是使得全局满足要求
贪婪量词的使用十分广泛,先看贪婪量词的常见类型
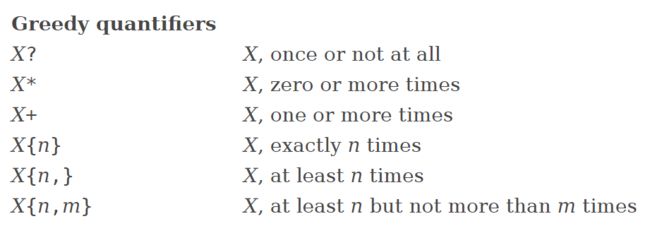
X? 表达可选择
模式串
"\d(.\d)?"
匹配示例
#case1: "1" // 匹配出"1"
#case2: "1.5" // 匹配出"1.5"
#case3: "1.25" // 匹配出"1.2"和"5"
#case4: "13.2" // 匹配出"1"和"3.2"
#case4: ".25" // 匹配出"2"和"5"
X* 表达任意次
关于X*的用法,千万不要看网上大多数中文的翻译"零次或多次",这容易造成误解"一次不出现或出现次数至少为2". 官方文档给的定义是"zero or more times",表示的是可以出现任意次.
模式串
"xo*"
匹配示例
#case1: "x" // 匹配"x"
#case2: "xo" // 匹配"xo"
#case3: "xooo" // 匹配"xooo"
X+ 表达至少出现一次
这个用法比较浅显易懂,不再举例
X{n}
出现次数恰好为n
X{n,}
出现次数至少为n
X{n,m}
出现次数至少为n,至多为m
模式串
"xo{1,3}"
文本串
#case1: "x" // 无匹配
#case2: "xo" // 匹配出"xo"
#case3: "xoo" // 匹配出"xoo"
#case4: "xooo" // 匹配出"xooo"
#case5: "xoooo" // 匹配出"xooo"
5.包含节制量词的模式串
节制量词的"节制"意义: 尽可能地少匹配字符;如果一个字符串满足要求,立刻返回匹配的串,即使后续有更长的字符串,也不再匹配.
应当注意的是,"满足要求"并非指仅仅满足X部分的要求,而是使得全局满足要求
例如
模式串
""
匹配
#case1: "" // 匹配出""而非"". 表面上,这是因为""本身并非文本串""的连续子串;而如果从节制量词的实现方式来考虑,节制量词要求满足""的全局要求,而非".*"的局部要求.
在贪婪量词的后面加'?'表达节制含义
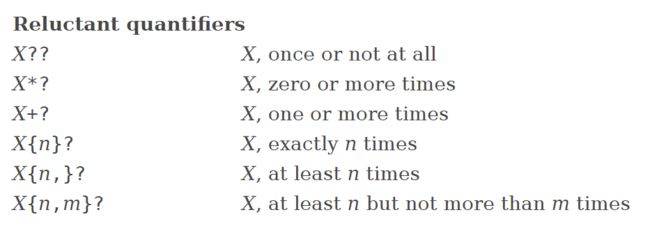
6.包含占有量词的模式串(无回溯贪婪量词)
这个量词相对用的比较少,而且我上网查一些在线的正则测试工具,似乎并不支持占有量词
对于占有量词,应该结合其与贪婪量词的区别来理解.
模式串
"" // 贪婪量词
"" // 占有量词
匹配示例
#case1: "" // 贪婪量词匹配出"",占有量词无匹配
贪婪量词
非贪婪量词
占有量词
匹配
X?
X??
X?+
匹配X 0次或1次
X*
X*?
X*+
匹配X 0次或无数次
X+
X+?
X++
匹配X 1次或无数次
X{n}
X{n}?
X{n}+
匹配X n次
X{n,}
X{n,}?
X{n,}+
匹配X 至少n次
X{n,m}
X{n,m}?
X{n,m}+
匹配X 至少n次至多m次
7.包含捕获组的模式串
组和捕获
捕获组可以通过从左到右计算其开括号来编号,在表达式 ((A)(B(C))) 中,可以理解为bfs的过程
$1 =((A)(B(C)))
$2 = (A)
$3 =(B(C))
$4 =(C)

实际上,刚刚我们已经多次使用了捕获组,它和数学上括号的意义相同,即划分整体以及改变运算优先级
8. 包含逻辑运算符的模式串

剩下还有一些更加高级的操作,不再介绍.基本的正则表达式匹配语法介绍到此为止.
三.Java中使用正则表达式
要在Java中使用正则表达式,应当导入regex包
import java.util.regex.*;
1.Pattern 类
一个字符串所指定的正则表达式首先应当被编译成Pattern类的一个实例,这个操作对应着Pattern的一个方法"complie()".
接下来,所得到的Pattern实例可以被用于创建一个Matcher对象,Matcher对象可以用来匹配任意给定的字符串.
显式创建的一个Pattern实例,可以用于构造多个Matcher对象来进行匹配.
操作示例:
Pattern p = Pattern.complie("a*b");
Matcher m = p.matcher("aaaab");
boolean result = m.matches(); // -> result = true
隐式创建的一个Pattern实例可以更加方便地进行匹配,然而如果需要多次用到这个模式串,这么写效率较低
操作示例:
boolean result = Pattern.matches("a*b","aaaab");
Pattern实例是不可变的,这么做是为了使之多线程安全,而Matcher实例并非不可变的,因此它不是多线程安全的.
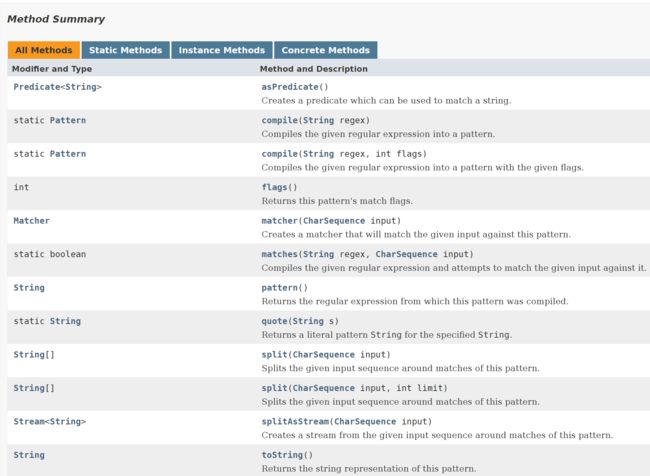
关于方法的细节,还是建议看看官方文档.