python获取职教云信息
⭐作者介绍:大二本科网络工程专业在读,持续学习Java,努力输出优质文章
⭐作者主页:@逐梦苍穹
⭐所属专栏:项目。
目录
- 1、需求
-
- 1.1、推荐课程
- 1.2、课程详情
- 2、思路分析
-
- 2.1、推荐课程
-
- 完整代码
- 2.2、课程详情
-
- 找到JSON数据
- 最终思路
- 新的问题
- 完整代码
1、需求
1.1、推荐课程

1.2、课程详情
对于上面每个课程,点击图片能跳转到对应课程页面,爬取中上面每个课程页面中的如下红色线划出的信息并保存为“课程详细列表.csv”。各栏目依次为:课程名称,所属专业,学时安排,课程进度,学时数,累计选课人数,本期选课人数,学员所属单位数,本期学员所属单位数,累计互动次数,本期互动次数,累计日志总数。

2、思路分析
爬虫代码通用的部分,也是最重要的部分:请求头和资源访问路径。
请求头是模拟普通用户通过浏览器访问的行为,以此初步跳过爬虫检测机制

这里的推荐课程和课程详情的爬取,均使用解析JSON格式的数据的方式!
2.1、推荐课程
首先我们知道,对于前后端交互数据,需要使用Ajax。所以对浏览器请求抓包可以得到:
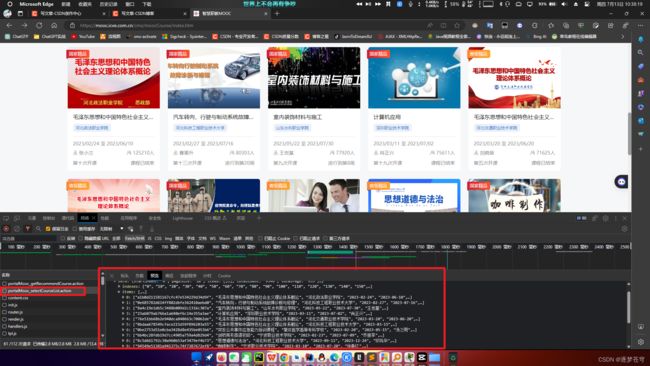
在这里可以看到,这个JSON响应的数据里面包含了一整页的数据,这些数据在portalMooc_selectCourseList.action里面,所以先定位这个资源的路径是什么:

可以看到,资源路径是:https://mooc.icve.com.cn/patch/zhzj/portalMooc_selectCourseList.action
但是如果去访问这个路径,会发现无法请求。
查看请求头,发现是POST:

使用python代码去访问,也是失败。

POST请求的资源,需要传入请求数据data,如下便是可以成功访问资源的代码:

那么这个data是怎么来的呢?
查看负载:
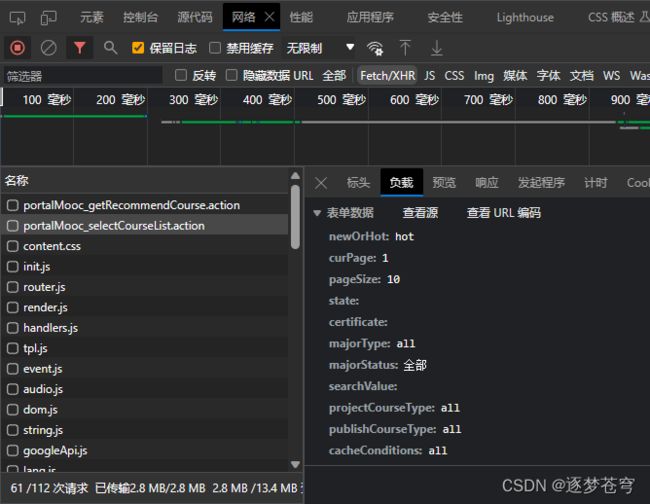
至此,关于推荐课程单页的获取,就结束了。接下来爬取多页,无非就是加循环。解析数据无非就是把json的键值对进行提取,不再赘述了。请看全部的代码,代码即注释:
完整代码
import csv
import json
import requests
from datetime import datetime
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
url = 'https://mooc.icve.com.cn/patch/zhzj/portalMooc_selectCourseList.action'
file = open('919页推荐课程.csv', mode='a', newline="",encoding='utf-8')
writer = csv.writer(file)
writer.writerow(['课程名称', '开课学校', '开始时间', '结束时间', '授课教师', '学习人数', '开课次数', '开课周次'])
for i in range(801, 920):
data = {
'newOrHot': 'hot',
'curPage': i,
'pageSize': '10',
'state': '',
'certificate': '',
'majorType': 'all',
'majorStatus': '全部',
'searchValue': '',
'projectCourseType': 'all',
'publishCourseType': 'all',
'cacheConditions': 'all'
}
response = requests.post(url, headers=headers, data=data)
# 检查响应状态码是否为200,表示请求成功
if response.status_code == 200:
try:
current_time = datetime.now()
classesStartWeekly = ""
dct = json.loads(response.text)['data']['items'] ##json字符串转换成python对象
# print(dct)
for data in dct:
className = data[1]
schoolName = data[2]
startTime = data[3]
endTime = data[4]
teacher = data[5]
learningNum = data[11]
numberOfClass = data[9]
time_diff = datetime.strptime(endTime + ' 23:59', '%Y-%m-%d %H:%M') - datetime.strptime(startTime + ' 0:00', '%Y-%m-%d %H:%M')
if current_time > datetime.strptime(endTime, '%Y-%m-%d'):
current_weeks = (time_diff.seconds // 3600) // 7
classesStartWeekly = "课程已结束"
elif(current_time < datetime.strptime(startTime, '%Y-%m-%d')):
classesStartWeekly = "课程未开始"
else:
current_time_diff = current_time - datetime.strptime(startTime + ' 0:00', '%Y-%m-%d %H:%M')
current_weeks = current_time_diff.days // 7
if current_time_diff.days % 7 > 0:
current_weeks += 1
classesStartWeekly = current_weeks
writer.writerow([className, schoolName, startTime, endTime, teacher,learningNum, numberOfClass, classesStartWeekly])
print(className, schoolName, startTime, endTime, teacher, learningNum, numberOfClass, classesStartWeekly)
except:
pass
else:
print('请求失败')
2.2、课程详情
课程详情和推荐课程类似,即是抓包获取JSON数据。但是发现获取到的数据只包含部分。所以通过抓包,看到了前端的JS文件,通过对JS文件的分析,找到了所有的数据。
找到JSON数据
第一步我们需要先找到JSON的数据,这个地方和上面的推荐课程略有不同,这里需要间接获取。
可以看到我们"需要的所有数据"都在这里,这是第三个请求路径:(实际上数据不全,但是我们能获取到的只有这部分,后面再细说)

那么我们通过上面的推荐课程爬取,可以知道这部分的数据请求都是POST,需要传入data去请求,此时我们查看负载:
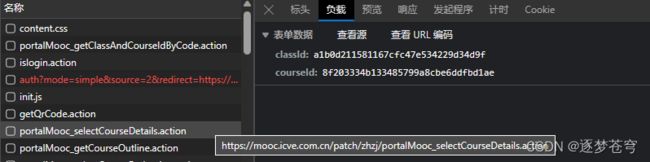
发现如果想要请求这个JSON资源,还需要传入两个Id:classId和courseId。
很明显这个Id加密过,没有办法得出规律,那么就需要利用其他渠道获取。
此时猜想,这个Id的数据肯定也是利用Ajax响应到前端的JSON资源。尝试寻找:

可以发现两个Id在这里,这是第二个请求路径。此时查看负载,发现还缺少classCode:

继续寻找,发现找不到了。这个地方的"类代码"应该是某一个唯一标识,一门课程对应一门。所以这个数据,应该是在一开始的"推荐课程"那里传递的:
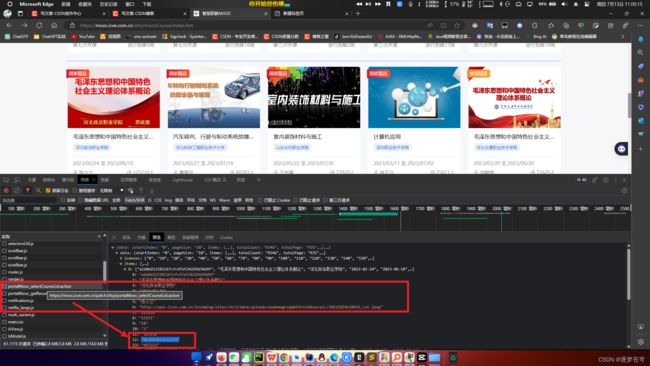
此处,这是第一个请求路径。
最终思路
那么此时思路就明确了:
先通过第一个请求路径,得到classCode,
再把这个classCode作为data传递请求第二个请求路径的资源,获取到classId和courseId,
再把这两个Id作为data传递请求第三个请求路径的资源,获取到我们需要的课程详情的JSON数据。
| URL |
|---|
| 第一个:https://mooc.icve.com.cn/patch/zhzj/portalMooc_selectCourseList.action |
| 第二个:https://mooc.icve.com.cn/patch/zhzj/portalMooc_getClassAndCourseIdByCode.action |
| 第三个:https://mooc.icve.com.cn/patch/zhzj/portalMooc_selectCourseDetails.action |
新的问题
此时获取到数据之后,发现了新的问题:有些数据是没有通过JSON格式传递的!
那么这些数据是怎么展现到前端页面的呢?毫无疑问是后端传递上来的JSON数据里面的某些数据,拿上来放在前端计算了。所以我们应该尝试找到前端计算的代码,我们可以去寻找JS文件:
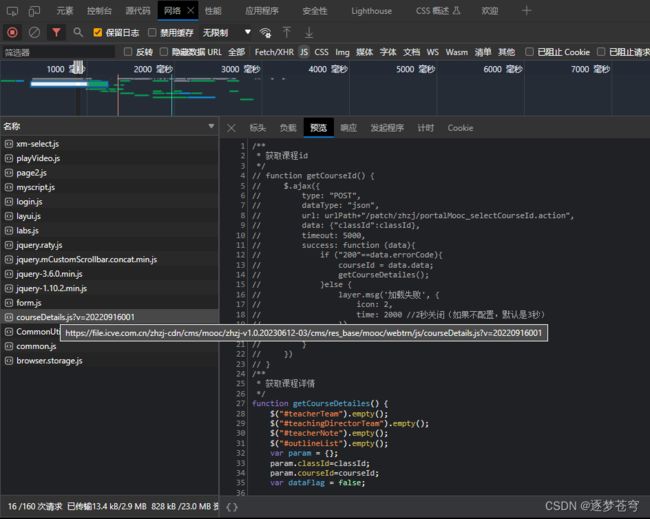
可以看到,应该就是它了,但是我们不是要把它抓下来,而是要看它是如何计算的,然后照葫芦画瓢在python代码中计算。下面举个简单例子说明:(本期互动)
①定位前端元素

②JSON查找disCount

传的是0
③那就只能去JS里面查找

找到了这段逻辑,可以看到里面的num1和num2就是我们要的数据。剩下的数据以此类推,然后转为python代码,如:

完整代码
# -*- coding: utf-8 -*-
# @Author:︶ㄣ释然
# @Time: 2023/6/20 14:29
import csv
import json
import requests
from datetime import datetime
from termcolor import colored
file1 = open('919页课程详细列表.csv', mode='a', newline="", encoding='utf-8')
writer1 = csv.writer(file1)
writer1.writerow(['课程名称', '所属专业', '学时安排', '课程进度', '学时数', '累计选课人数', '本期选课人数', '学员所属单位数', '本期学员所属单位数', '累计互动次数', '本期互动次数', '累计日志总数','开课学校','学校类别','开始时间','结束时间'])
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
# list_classCode = []
# list_classId_and_courseId = []
'''每一次循环爬一页热门推荐页,一页十条'''
def getClassCode(url_getClassCode):
file2 = open('919页热门推荐页ClassCode.csv', mode='a', newline="", encoding='utf-8')
writer2 = csv.writer(file2)
for i in range(801, 920):
data_getClassCode = {
'newOrHot': 'hot',
'curPage': i,
'pageSize': '10',
'state': '',
'certificate': '',
'majorType': 'all',
'majorStatus': '全部',
'searchValue': '',
'projectCourseType': 'all',
'publishCourseType': 'all',
'cacheConditions': 'all'
}
try:
response = requests.post(url_getClassCode, headers=headers, data=data_getClassCode)
# 检查响应状态码是否为200,表示请求成功
if response.status_code == 200:
dct = json.loads(response.text)['data']['items']
for data_getClassCode in dct:
# list_classCode.append(data_getClassCode[12])
writer2.writerow([data_getClassCode[12]])
print("成功获取热门推荐页第%s页" % i)
else:
print('请求失败')
except:
pass
'''查每一条的classId和courseId,上面for一次,这里就可以for10次'''
def getClassId_and_CourseId(url_getClassId_and_CourseId):
file3 = open('919页classId_and_courseId.csv', mode='a', newline="", encoding='utf-8')
writer3 = csv.writer(file3)
csvfile = open('919页热门推荐页ClassCode.csv', newline='')
reader = csv.reader(csvfile)
listReader = list(reader)
for i in range(6001, 9167):
data_getClassId_and_CourseId = {
'classCode': listReader[i][0]
}
try:
response = requests.post(url_getClassId_and_CourseId, headers=headers, data=data_getClassId_and_CourseId)
if response.status_code == 200:
dct = json.loads(response.text)['data']
# list_classId_and_courseId.append(dct)
writer3.writerow([dct])
print("成功获取第%s门课程的classId和courseId" % i)
else:
print('请求失败')
except:
pass
'''根据上面查到的两个Id,开始获取详情页JSON数据'''
def details(url_details):
csvfile = open('919页classId_and_courseId.csv', newline='')
reader = csv.reader(csvfile)
listReader = list(reader)
for i in range(1, 9154):
current_time = datetime.now()
json_str = str(listReader[i - 1][0])
json_str = json_str.replace("'", "\"")
dictionary = json.loads(json_str)
data_details = {
'classId': dictionary['classId'],
'courseId': dictionary['courseId']
}
response = requests.post(url_details, headers=headers, data=data_details)
if response.status_code == 200:
try:
dct = json.loads(response.text)
className = dct['data']['className']
majorName = dct['data']['majorName']
learningPlan = round(float(dct['data']['learningTime']) / int(dct['data']['weekNum']), 2)
weekDate = 0
learningTime = dct['data']['learningTime']
allClassPeople = int(dct['courseMoocData'][0][3]) + int(dct['classSpocList'][0][0])
classPeople = dct['data']['classPeople']
allSchoolCount = dct['courseMoocData'][0][0]
schoolCount = dct['data']['schoolCount']
allDisCount = int(dct['courseMoocData'][0][1]) + int(dct['classSpocList'][0][1])
disCount = 0
allLogCount = int(dct['courseMoocData'][0][2]) + int(dct['classSpocList'][0][3])
schoolName = dct['data']['schoolName']
schoolCategory = dct['data']['category']
startTime = dct['data']['startTime']
endTime = dct['data']['endTime']
time = (current_time - datetime.strptime(dct['data']['startTime'], '%Y-%m-%d %H:%M:%S.%f'))
time = time.days // 7
weekDate = time
if current_time < datetime.strptime(dct['data']['endTime'], '%Y-%m-%d %H:%M:%S.%f'):
if time % 7 > 0:
weekDate += 1
else:
weekDate = int(dct['data']['weekNum'])
questionNum = dct['data']['questionNum']
noteNum = dct['data']['noteNum']
allQuestionNum = dct['courseMoocData'][0][4]
allNoteNum = dct['courseMoocData'][0][5]
disCount = dct['data']['disCount']
# print(questionNum,noteNum,allNoteNum,allQuestionNum)
if disCount == '' or disCount is None:
disCount = 0
if questionNum == '' or questionNum is None:
questionNum = 0
if noteNum == '' or noteNum is None:
noteNum = 0
if allQuestionNum == '' or allQuestionNum is None:
allQuestionNum = 0
if allNoteNum == '' or allNoteNum is None:
allNoteNum = 0
# 累计互动
if (dct['postData']['data']['totalCount'] == None or 0 == dct['postData']['data']['totalCount'] or "0" == dct['postData']['data']['totalCount']):
allDisCount = int(allDisCount) + int(allQuestionNum) + int(allNoteNum)
else:
allDisCount = int(allDisCount) + int(dct['postData']['data']['totalCount']) + int(allQuestionNum) + int(
allNoteNum)
# 本期互动
if (dct['postData']['data']['nowCount'] == None or 0 == dct['postData']['data']['nowCount'] or "0" == dct['postData']['data'][
'nowCount']):
disCount = int(disCount) + int(questionNum) + int(noteNum)
else:
disCount = int(disCount) + int(dct['postData']['data']['nowCount']) + int(questionNum) + int(noteNum)
writer1.writerow([className, majorName, learningPlan, weekDate, learningTime, allClassPeople, classPeople, allSchoolCount, schoolCount, allDisCount,
disCount, allLogCount,schoolName,schoolCategory,startTime,endTime])
print(className, majorName, learningPlan, weekDate, learningTime, allClassPeople, classPeople, allSchoolCount, schoolCount, allDisCount,
disCount, allLogCount,schoolName,schoolCategory,startTime,endTime)
except Exception as e:
print(colored(str(e), 'red'))
else:
print('请求失败')
if __name__ == '__main__':
url_getClassCode = 'https://mooc.icve.com.cn/patch/zhzj/portalMooc_selectCourseList.action'
url_getClassId_and_CourseId = 'https://mooc.icve.com.cn/patch/zhzj/portalMooc_getClassAndCourseIdByCode.action'
url_details = 'https://mooc.icve.com.cn/patch/zhzj/portalMooc_selectCourseDetails.action'
getClassCode(url_getClassCode)
getClassId_and_CourseId(url_getClassId_and_CourseId)
details(url_details)