SpringBoot使用EasyExcel批量导出500万数据
SpringBoot使用EasyExcel批量导出500万数据
- 说明
- excel版本比较
- EasyExcel介绍
- 项目目录
- mysql对应表建表语句
- pom.xml
- application.yml配置类
- 启动类代码
- OrderInfo 实体类
- OrderInfoExcel excel模版标题类(EasyExcel需要使用这个)
- TestController控制层
- 接口层TestService
- TestServiceImpl实现层
- TestDao数据接口层
- dao层对应mapper.xml自定义sql语句
- 测试结果如下
说明
记录下学习SpringBoot使用EasyExcel批量导出百万数据。留着以后备用。
本地环境mysql安装的5.7版本,项目使用jdk1.8版本,项目使用的mysql驱动版本为8.0版本。
这一篇博客内容代码基于我的这篇博客:
SpringBoot使用mybatis批量新增500万数据到mysql数据库Demo,在自己这篇博客的代码上做改动写批量导出功能。
excel版本比较
03版excel:HSSFWorkbook为2003之前的版本,扩展名为.xls。每个sheet页最多65536行,最大列数是256列。当应用场景数据小于65536行数据时,可以使用03版excel来导出,导出性能很高。
07版excel:XSSFWorkbook为2007之后的版本,扩展名为.xlsx。每个sheet页最多1048576行,超过这个行数,导出的时候后端程序就会抛异常。
当数据量超过65536行进行大数据量导出时可以用07版excel,当用POI进行百万数据导出时,会很占用内存,很有可能导致程序出现OOM(内存溢出),而且为了让XSSFWorkbook效率提升,用了Workbook第三个实现类SXSSFWorkbook。SXSSFWorkbook用来处理大数据量以及超大数据量的导出,只是 SXSSFWorkbook只支持.xlsx格式,不支持.xls格式。
EasyExcel介绍
EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。
它能让你在不用考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
EasyExcel官方文档:https://easyexcel.opensource.alibaba.com/
项目目录

mysql对应表建表语句
CREATE TABLE `order_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`period` int(11) NOT NULL COMMENT '账期月份',
`amount` decimal(20,2) NOT NULL COMMENT '金额',
`user_name` varchar(20) NOT NULL COMMENT '下单人',
`phone` varchar(11) NOT NULL COMMENT '手机号',
`created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`creator` varchar(20) NOT NULL COMMENT '创建人',
`modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`modifier` varchar(20) NOT NULL COMMENT '修改人',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_period` (`period`),
KEY `idx_modified` (`modified`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='订单信息表';
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>batching</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>batching</name>
<description>batching</description>
<properties>
<java.version>1.8</java.version>
<!--下列版本都是2022/04/16最新版本,都是父项目的基本依赖,用来子项目继承父项目依赖-->
<pagehelper-starter.version>1.4.2</pagehelper-starter.version>
<mybatis.version>3.5.9</mybatis.version>
<mysql-connector.version>8.0.28</mysql-connector.version>
<druid.version>1.2.9</druid.version>
<lombok.version>1.18.22</lombok.version>
<easyexcel.version>3.2.1</easyexcel.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--MyBatis分页插件1.4.2版本才支持spring-boot2.6.6-->
<!--pagehelper分页官网:https://mvnrepository.com/artifact/com.github.pagehelper/pagehelper-spring-boot-starter/-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>${pagehelper-starter.version}</version>
</dependency>
<!-- MyBatis就是用来创建数据库连接进行增删改查等操作,提供了原生JDBC,如Connection,Statement,ResultSet这些底层-->
<!-- MyBatis官网:https://mybatis.org/mybatis-3/zh/dependency-info.html-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>${mybatis.version}</version>
</dependency>
<!--Mysql数据库驱动-->
<!--Mysql驱动官网:https://mvnrepository.com/artifact/mysql/mysql-connector-java/-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector.version}</version>
</dependency>
<!--集成druid连接池-->
<!--druid版本官网:https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--lombok-->
<!--lombok官网:https://mvnrepository.com/artifact/org.projectlombok/lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
<!--集成阿里巴巴EasyExcel用于大批量数据导出-->
<!--官网地址:https://easyexcel.opensource.alibaba.com/-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>${easyexcel.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
application.yml配置类
server:
port: 8080
mybatis:
mapper-locations:
- classpath:mapper/*.xml #找到mybatis位置,自定义sql语句
#当查询语句中resultType="java.util.HashMap"时,如果返回的字段值为null时,设置如下参数为true,让它返回
configuration:
call-setters-on-nulls: true
#打印sql语句
logging:
level:
com.example.batching.dao: debug
spring:
datasource:
#mysql批量新增需要在url后面添加rewriteBatchedStatements=true才能生效
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
driverClassName: com.mysql.cj.jdbc.Driver #mysql8.0驱动,mysql5.7驱动是com.mysql.jdbc.Driver
username: 你自己的数据库用户名
password: 你自己的数据库密码
druid:
initial-size: 3 #连接池初始大小
min-idle: 5 #最小空闲连接数
max-active: 20 #最大空闲连接数
web-stat-filter:
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" #不统计这些请求数据
stat-view-servlet: #访问监控网页的用户名和密码
#默认为true,内置监控页面首页/druid/index.html
enabled: true
login-username: druid
login-password: druid
启动类代码
package com.example.batching;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BatchingApplication {
public static void main(String[] args) {
SpringApplication.run(BatchingApplication.class, args);
}
}
OrderInfo 实体类
package com.example.batching.entity;
import lombok.Data;
import java.math.BigDecimal;
@Data
public class OrderInfo {
private int id;
private int period;//账期月份
private BigDecimal amount;//金额
private String userName;//下单人
private String phone;//手机号
private String created;//创建时间
private String creator;//创建人
private String modified;//修改时间
private String modifier;//修改人
private int pageNum;//页数
private int pageSize;//每页所返回行数
}
OrderInfoExcel excel模版标题类(EasyExcel需要使用这个)
package com.example.batching.excelmode;
import com.alibaba.excel.annotation.ExcelIgnore;
import com.alibaba.excel.annotation.ExcelProperty;
import java.math.BigDecimal;
public class OrderInfoExcel {
@ExcelProperty(value="id")
private int id;
@ExcelProperty(value="账期月份")
private int period;//账期月份
@ExcelProperty(value="金额")
private BigDecimal amount;//金额
@ExcelProperty(value="下单人")
private String userName;//下单人
@ExcelProperty(value="手机号")
private String phone;//手机号
@ExcelProperty(value="创建时间")
private String created;//创建时间
@ExcelProperty(value="创建人")
private String creator;//创建人
@ExcelProperty(value="修改时间")
private String modified;//修改时间
@ExcelProperty(value="修改人")
private String modifier;//修改人
@ExcelIgnore
private int pageNum;//页数
@ExcelIgnore
private int pageSize;//每页所返回行数
}
TestController控制层
批量导出方法看batchExport方法。
package com.example.batching.controller;
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.ExcelWriter;
import com.alibaba.excel.write.metadata.WriteSheet;
import com.example.batching.entity.OrderInfo;
import com.example.batching.excelmode.OrderInfoExcel;
import com.example.batching.service.TestService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletResponse;
import java.io.OutputStream;
import java.math.BigDecimal;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
@RestController
@RequestMapping(value = "/order")
public class TestController {
@Autowired
private TestService testService;
//批量新增数据处理
@PostMapping(value = "/batchSave")
public String batchSave() {
//随机生成电话号码
String[] start = {"130", "131", "132", "133", "134", "150", "151", "155", "158", "166", "180", "181", "184", "185", "188"};
List<OrderInfo> orderInfoList=new ArrayList<>();
//生成500万数据批量新增到mysql数据库里面
for(int i=1;i<=5000000;i++){
OrderInfo orderInfo=new OrderInfo();
orderInfo.setPeriod(202206);
orderInfo.setAmount(new BigDecimal(i));
orderInfo.setUserName("用户"+i);
orderInfo.setPhone(start[(int) (Math.random() * start.length)]+(10000000+(int)(Math.random()*(99999999-10000000+1))));
orderInfo.setCreator("用户"+i);
orderInfo.setModifier("用户"+i);
orderInfoList.add(orderInfo);
//每一万条数据进行批量新增
if(i%10000==0){
testService.batchSave(orderInfoList);
//新增完成后清空list集合防止内存溢出
orderInfoList.clear();
System.out.println("当前已新增完数据:"+i+"行");
}
}
return "成功";
}
//批量导出数据到excel
@GetMapping(value = "/batchExport")
public void batchExport(HttpServletResponse response) {
try{
OutputStream outputStream =response.getOutputStream();
//查询出总数据量大小,这里为500万
int count=testService.batchExportCount();
System.out.println("count="+count);
//根据总数得到总页数
int totalPage=(count-1)/100000+1;//总页数,每页10万行数据
System.out.println("totalPage="+totalPage);
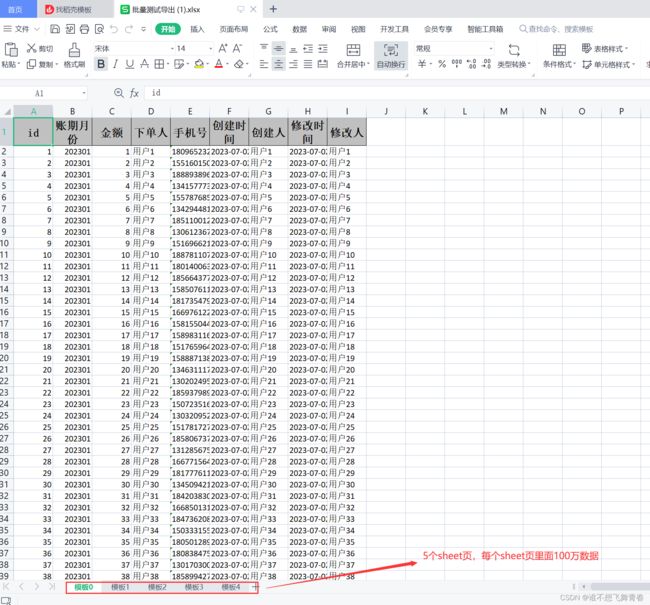
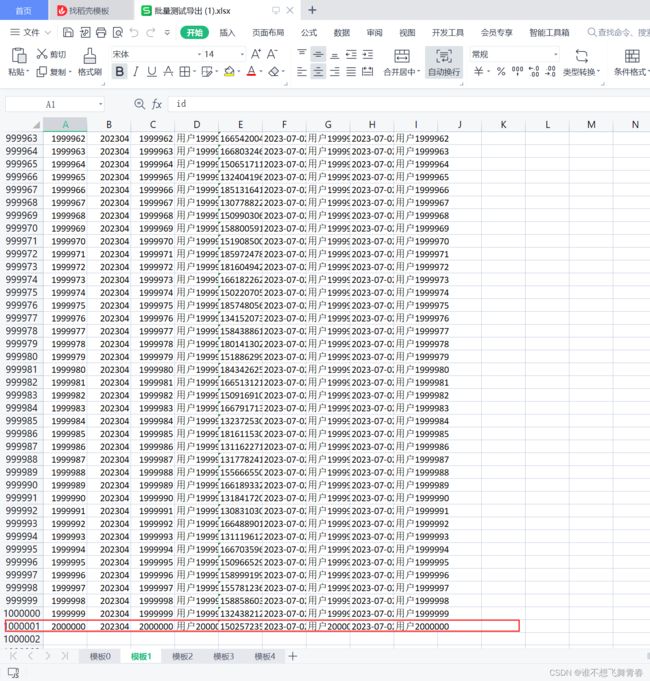
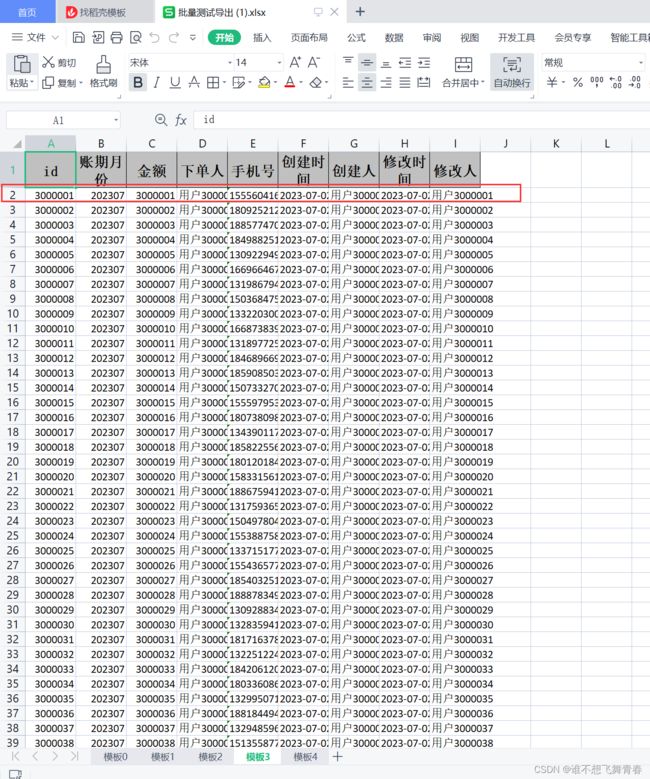
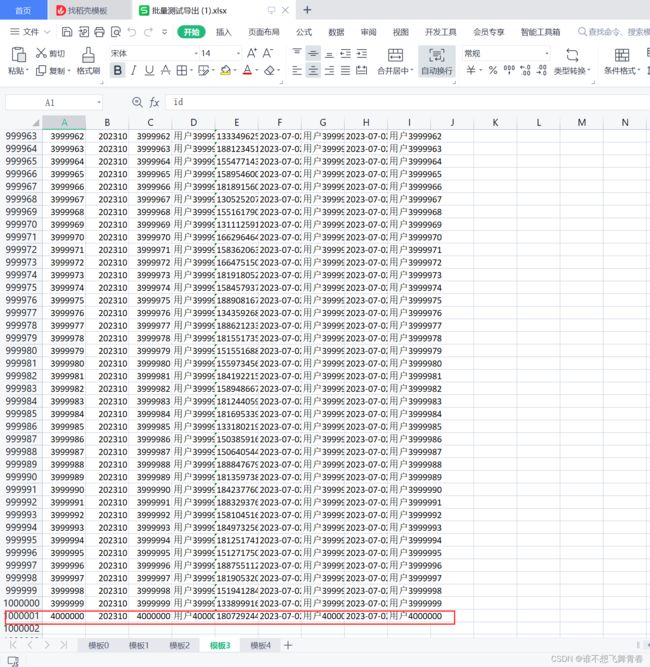
//xlsx每个sheet页最大数据行为1048576,超过这个数值就会报错,所以这里将500万数据分5个导出到5个sheet页
//根据总数得到每页sheet应该分几个sheet,每个sheet导入100万数据,500万就是5个sheet
int totalSheet=(count-1)/1000000+1;//总sheet页数,每个sheet100万行数据
System.out.println("totalSheet="+totalSheet);
//设置初始页数
OrderInfo orderInfo=new OrderInfo();
orderInfo.setPageNum(0);//初始页,从0开始
orderInfo.setPageSize(100000);//每页返回数据
//文件名
String fileName="批量测试导出.xlsx";
//使用EasyExcel进行导出
ExcelWriter excelWriter = EasyExcel.write(outputStream, OrderInfoExcel.class).build();
//这里最终会写到5个sheet里面
for (int i = 0; i < totalSheet; i++) {
//writerSheet第一个参数表示往几个sheet开始写数据,从0开始表示第一个
WriteSheet writeSheet = EasyExcel.writerSheet(i, "模板" + i).build();
//分页去数据库查询数据
for(int j = orderInfo.getPageNum(); j < totalPage; j++){
//页数,对应后端数据库来说是索引
int pageNum=j*100000;
//每页要查询的行数
int pageSize=orderInfo.getPageSize();
//根据分页参数去查询每页数据
List<OrderInfo> data = testService.batchExport(pageNum,pageSize);
excelWriter.write(data, writeSheet);
System.out.println("已导出数据:"+(pageNum+100000));
if((pageNum+100000)%1000000==0){
//记录当前页数j并加1,并跳出这个for循环,往下一个sheet页写入数据
orderInfo.setPageNum(j+1);
break;
}
}
}
//下载
response.reset();
response.setContentType("application/octet-stream; charset=utf-8");//以流的形式对文件进行下载
response.setHeader("Content-Disposition", "attachment; filename=" + URLEncoder.encode(fileName, "UTF-8"));//对文件名编码,防止文件名乱码
excelWriter.finish();
outputStream.flush();
outputStream.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
接口层TestService
package com.example.batching.service;
import com.example.batching.entity.OrderInfo;
import java.util.List;
public interface TestService {
void batchSave(List<OrderInfo> orderInfoList);
int batchExportCount();
List<OrderInfo> batchExport(int pageNum, int pageSize);
}
TestServiceImpl实现层
package com.example.batching.service.impl;
import com.example.batching.dao.TestDao;
import com.example.batching.entity.OrderInfo;
import com.example.batching.service.TestService;
import com.github.pagehelper.PageHelper;
import org.apache.ibatis.session.ExecutorType;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.List;
@Service
public class TestServiceImpl implements TestService {
@Resource
private TestDao testDao;
@Resource
private SqlSessionFactory sqlSessionFactory;
@Override
public void batchSave(List<OrderInfo> orderInfoList) {
//批量新增处理,需要在jdbc连接那里添加rewriteBatchedStatements=true属性,批量新增才能生效
// ExecutorType.SIMPLE: 这个执行器类型不做特殊的事情。它为每个语句的执行创建一个新的预处理语句。自动提交不关闭的前提下,默认设置是这个
// ExecutorType.REUSE: 这个执行器类型会复用预处理语句。
// ExecutorType.BATCH: 这个执行器会批量执行所有更新语句,如果 SELECT 在它们中间执行还会标定它们是 必须的,来保证一个简单并易于理解的行为。
//如果自动提交设置为true,将无法控制提交的条数,改为最后统一提交
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
try {
TestDao testMapper = sqlSession.getMapper(TestDao.class);
orderInfoList.stream().forEach(orderInfo -> testMapper.batchSave(orderInfo));
//提交数据
sqlSession.commit();
} catch (Exception e) {
sqlSession.rollback();
} finally {
sqlSession.close();
}
}
@Override
public int batchExportCount() {
return testDao.batchExportCount();
}
@Override
public List<OrderInfo> batchExport(int pageNum, int pageSize) {
return testDao.batchExport(pageNum, pageSize);
}
}
TestDao数据接口层
package com.example.batching.dao;
import com.example.batching.entity.OrderInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import java.util.List;
@Mapper
public interface TestDao {
void batchSave(OrderInfo orderInfo);
int batchExportCount();
List<OrderInfo> batchExport(@Param("pageNum") int pageNum, @Param("pageSize") int pageSize);
}
dao层对应mapper.xml自定义sql语句
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace必须指向Dao接口 -->
<mapper namespace="com.example.batching.dao.TestDao">
<insert id="batchSave" parameterType="com.example.batching.entity.OrderInfo">
INSERT INTO order_info
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="period != null">
period,
</if>
<if test="amount != null">
amount,
</if>
<if test="userName != null">
user_name,
</if>
<if test="phone != null">
phone,
</if>
<if test="creator != null">
creator,
</if>
<if test="modifier != null">
modifier,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="period != null">
#{period},
</if>
<if test="amount != null">
#{amount},
</if>
<if test="userName != null">
#{userName},
</if>
<if test="phone != null">
#{phone},
</if>
<if test="creator != null">
#{creator},
</if>
<if test="modifier != null">
#{modifier},
</if>
</trim>
</insert>
<select id="batchExportCount" resultType="java.lang.Integer">
select count(id) num from order_info
</select>
<select id="batchExport" parameterType="java.lang.Integer" resultType="com.example.batching.entity.OrderInfo">
select id,period,amount,user_name userName,phone,created,creator,modified,modifier
from order_info
order by id
limit #{pageNum},#{pageSize}
</select>
</mapper>
测试结果如下
浏览器调用接口返回如下:

后台控制台打印如下:
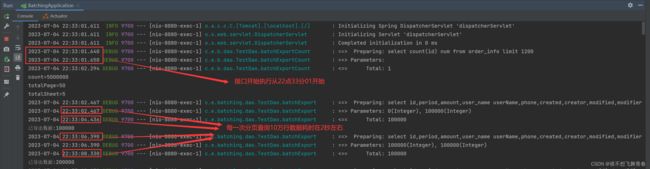
越往后进行深翻页,查询耗时越长

从22时33分01秒到22时36分52秒耗时接近4分钟才将所有数据进行导出。
所以这里的性能瓶颈在sql优化那一块,怎么才能深翻页的时候提高sql性能,让500万
数据更快导出。
excel文件结果如下:
id自增从1到5000000,每个sheet页100万数据。