python pytorch 纯算法实现前馈神经网络训练(数据集随机生成)-续
python pytorch 纯算法实现前馈神经网络训练(数据集随机生成)-续
上一次的代码博主看了,有两个小问题其实,一个是,SGD优化的时候,那个梯度应该初始化为0,还一个是我并没有用到随机生成batch。
博主修改了代码,并且加入了accuracy图像绘制的代码。代码如下:
#coding=gbk
import torch
from torch.autograd import Variable
from torch.utils import data
import matplotlib.pyplot as plt
dim=5
batch=32
neuron_num=10
def generate_data():
torch.manual_seed(3)
X1=torch.randint(0,4,(1000,dim))
X2=torch.randint(6,10,(1000,dim))
Y1=torch.randint(0,1,(1000,))
Y2=torch.randint(1,2,(1000,))
print(X1)
print(X2)
print(Y1)
print(Y2)
X_data=torch.cat([X1,X2],0)
Y_label=torch.cat([Y1,Y2],0)
print(X_data)
print(Y_label)
return X_data,Y_label
def sampling(X_data,Y_label,batch):
data_size=Y_label.size()
#print(data_size)
index_sequense=torch.randperm(data_size[0])
return index_sequense
def loss_function_crossEntropy(Y_predict,Y_real):
if Y_real==1:
return -torch.log(Y_predict)
else:
return -torch.log(1-Y_predict)
X_data,Y_label=generate_data()
index_sequense=sampling(X_data,Y_label,batch)
def test():
l=loss_function_crossEntropy(torch.tensor([0.1]),torch.tensor([1]))
print(l)
def neuron_net(X,W,b):
result=torch.matmul(X.type(dtype=torch.float32),W)+b
result=torch.relu(result).reshape(1,result.size(0))
#print(result)
#print(result.size())
return result
def grad(X,W,b,y_predict,y_real,W2,b2):
g1=y_real/y_predict+(y_real-1)/(1-y_predict)
result=torch.matmul(X.type(dtype=torch.float32),W)+b
result=torch.relu(result).reshape(1,result.size(0))
g2=y_predict*(1-y_predict)
g3=neuron_net(X,W,b)
g4=W2
C=torch.matmul(X.type(dtype=torch.float32),W)+b
a=[]
for i in C:
if i<=0:
a.append(0)
else:
a.append(1)
g5=torch.tensor(a)
g6=X
grad_w=g1*g2*g3
grad_b=g1*g2
#print("grad_w",grad_w)
#print(grad_b)
grad_w2=g1*g2*g4
grad_w2=grad_w2.reshape(1,10)
grad_w2=grad_w2*g5
# print(grad_w2.size())
grad_w2=grad_w2.reshape(10,1)
g6=g6.reshape(1,5)
grad_b2=grad_w2
grad_w2=torch.matmul(grad_w2.type(dtype=torch.float32),g6.type(dtype=torch.float32))
# print(grad_b2.size())
return grad_w,grad_b,grad_w2,grad_b2
#print(g1,g2,g3,g4,g5,g6)
#print(grad_w2)
#print(grad_b2)
def flat_dense(X,W,b):
return torch.sigmoid(torch.matmul(X.type(dtype=torch.float32),W)+b)
W=torch.randn(dim,neuron_num)
b=torch.randn(neuron_num)
W2=torch.randn(neuron_num,1)
b2=torch.randn(1)
def net(X,W,b,W2,b2):
result=neuron_net(X,W,b)
ans=flat_dense(result,W2,b2)
return ans
y_predict=net(X_data[0],W,b,W2,b2)
print(y_predict)
grad_w,grad_b,grad_w2,grad_b2=grad(X_data[0],W,b,y_predict,Y_label[0],W2,b2)
loss_list=[]
accuracy_list=[]
learn_rating=0.01
epoch=2000
def train():
index=0
global W,W2,b,b2
for i in range(epoch):
W_g=torch.zeros(dim,neuron_num)
b_g=torch.zeros(neuron_num)
W2_g=torch.zeros(neuron_num,1)
b2_g=torch.zeros(1)
loss=torch.tensor([0.0])
co=0
for j in range(32):
try:
y_predict=net(X_data[index_sequense[index]],W,b,W2,b2)
grad_w,grad_b,grad_w2,grad_b2=grad(X_data[index_sequense[index]],W,b,y_predict,Y_label[index_sequense[index]],W2,b2)
# print(grad_w2.size(),W_g.size())
grad_w2=torch.t(grad_w2)
W_g=W_g+grad_w2
grad_b2=grad_b2.reshape(10)
#print("b_g",b_g)
#print("grad_b2",grad_b2)
b_g=grad_b2+b_g
W2_g=W2_g+torch.t(grad_w)
b2_g=b2_g+torch.t(grad_b)
# print("fdafaf",grad_w,grad_b,grad_w2,grad_b2)
loss=loss+loss_function_crossEntropy(y_predict,Y_label[index_sequense[index]])
# print( Y_label[index],y_predict[0][0])
if (Y_label[index_sequense[index]]==1) &( y_predict[0][0]>0.5):
co=co+1
if (Y_label[index_sequense[index]]==0) &( y_predict[0][0]<=0.5):
co=co+1
index=index+1
except:
index=0
print("loss:",loss[0])
print("accuracy:",co/32)
loss_list.append(loss[0])
accuracy_list.append(co/32)
W_g=W_g/batch
b_g=b_g/batch
W2_g=W2_g/batch
b2_g=b2_g/batch
#print(W.size())
#print(b.size())
#print(W2.size())
#print(b2.size())
W=W+learn_rating*W_g
# print("b*********************",b,b_g)
b=b+learn_rating*(b_g)
#print(W2_g.size())
#print(b2_g.size())
W2=W2+learn_rating*W2_g
b2=b2+learn_rating*b2_g
#print(W.size())
#print(b.size())
#print(W2.size())
#print(b2.size())
train()
epoch_list=list(range(epoch))
plt.plot(epoch_list,loss_list,label='SGD')
plt.title("loss")
plt.legend()
plt.show()
epoch_list=list(range(epoch))
plt.plot(epoch_list,accuracy_list,label='SGD')
plt.title("loss")
plt.legend()
plt.show()
可一下跑出的结果:
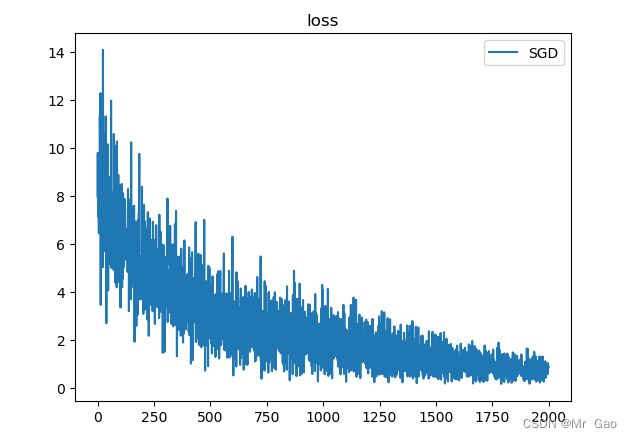
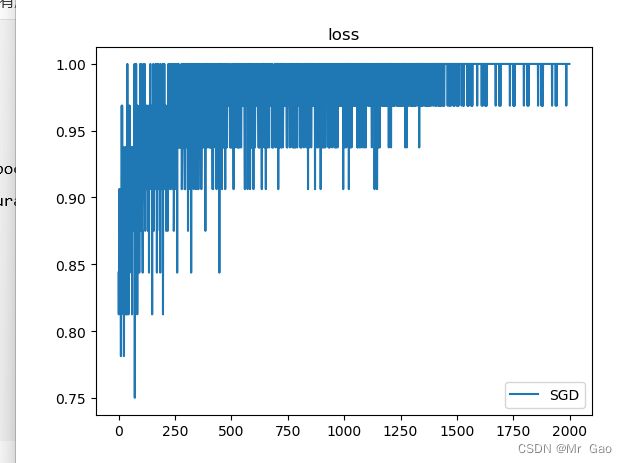
可以看到这样看下来,效果就很不错了。