Java开发 - Canal的基本用法
前言
今天给大家带来的是Canal的基本用法,Canal在Java中常被我们用来做数据的同步,当然不是MySQL与MySQL,Redis与Redis之间了,如果是他们,那就好办了,我们可以直接通过配置来完成他们之间的主从、主主,级联等的同步,为什么要用Canal呢?主要是为了完成MySQL与Redis、MySQL与ES之间的数据同步,其本质是同步的过程中降低代码的耦合度,否则我们完全可以通过代码分别往几种不同的存储方存储数据。
认识Canal
什么是Canal
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
下面这张图可以代表Canal的用途,就染我们来一起瞻仰一下:

在看到这张图后,我们要感谢开发者的付出,提供给我们这么好的工具,目前来说,很多公司做数据同步都是采用的这种方式,可以通过Canal分别向MySQL,ES里同步数据。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
基本原理
Canal的实现主要利用了MySQL主从复制的原理,细分如下:
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
也就是说,Canal将自己伪装成一个MySQL的从库,像其他的Slava一样,向Master发送dump 协议,MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ),canal 解析 binary log 对象(原始为 byte 流)。
Canal准备
第一次接触Canal的小伙伴点击下面链接下载Canal:
Releases · alibaba/canal · GitHub
不要使用太新的版本,我们就用1.1.4的版本:

下载完成之后放在一个英文路径下,我们改下文件夹的名字canal,下有四个文件夹:

MySQL配置
这里,我们不需要去配置MySQL的主从,如果你想了解,不妨去看这篇博客:
Java开发 - MySQL主从复制初体验
这里有你想要的主从配置,和对主从配置的一些心得体会。
在此处,我们只需要开启一个MySQL服务,设置一个连接的用户和密码,整体上和配置MySQL主从的步骤差不多,因为本质上也是要把Canal配置成MySQL的Slava的。
MySQL服务开启了吧?那么登陆MySQL服务,我们先来创建并授权一个用户.
创建用户:
CREATE USER 'canal'@'%' IDENTIFIED WITH 'mysql_native_password' BY '123456';
mysql8.0和5.x其中一个改动就是加密认证方式发生改变,这个在上面提到的MySQL主从复制里有提到,caching_sha2_password是8.0, mysql_native_password是5.x,canal我们这里都采用mysql_native_password的方式创建密码。
远程授权:
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' WITH GRANT OPTION;刷新权限:
FLUSH PRIVILEGES;修改my.cnf文件,这个根据自己mysql安装位置的路径去找,但似乎这个文件大多情况是不存在的,所以我们直接在etc目录下创建一个用就行,实在害怕,可以运行如下命令查看my.cnf的默认运行位置:
mysql --help | grep 'my.cnf'
所以在默认路径下:/usr/local/Cellar/mysql/版本号/ ,此处没有etc文件,自己手动创建吧,不要怂,接着:

进入etc文件,在这里运行:
vim my.cnf输入:
[mysqld]
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# 不要和canal的slaveId重复即可
server_id=1
退出并保存,然后重启mysql。
检查mysql的binlog是否开启:
show variables like 'log_bin';
已开启。
检查binlog_format:
show variables like "%binlog_format%";
显示ROW,代表我们设置生效。
检查server_id:
show variables like "%server_id%";
我们设置的1,已生效。
查看当前正在写入的binlog文件:
show master status;
我们主要看的就是这两个参数,记住,到此为止,不要再动数据库的任何东西,否则这两个数据会改变,对我们配置canal会有影响。 上面的两个参数,我们在稍后配置canal的时候需要。
额。。。。。不过,这俩参数其实可以不用设置,不设置就代表从最新的地方开始同步,博主已经试过了,没问题。
Canal配置
我们打开刚刚下载的canal文件夹,打开这个路径下的文件:conf/example/instance.properties:
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=157
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=123456
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
我们需要改的核心参数暂时不多,如下:
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=157
canal.instance.dbUsername=canal
canal.instance.dbPassword=123456其他的暂时先不用改,后续将到实际应用的时候会讲,这几个参数不用博主说大家也应该知道什么意思了吧?保存一下。
现在我们来启动canal,canal的启动很简单,打开一个命令行工具,直接把bin/startup.sh文件拖进去回车就可以了,方式不固定:
命令行输出了一大段内容,但我们不知道canal启动成功了没,我们来看下:

通过jps可以看到CanalLauncher的进程号,看来应该是没问题的。
单纯的Canal监听测试
下面我们创建一个最简单的Spring Boot工程,过程就不赘述了:
首先我们引入依赖:
com.alibaba.otter
canal.client
1.1.4
版本号要和我们使用的一致。
添加配置:
canal:
serverAddress: 127.0.0.1
serverPort: 11111
instance:
- example在CannalClient类使用Spring Bean的生命周期函数afterPropertiesSet(),切记,这里只是监听,并不是真正项目上使用,不要照搬,此处知识单传让大家看到canal监听的效果:
package com.codingfire.canal.Client;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;
import java.net.InetSocketAddress;
import java.util.List;
@Component
public class CanalClient implements InitializingBean {
private final static int BATCH_SIZE = 1000;
@Override
public void afterPropertiesSet() throws Exception {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
//打开连接
connector.connect();
//订阅数据库表,全部表
connector.subscribe(".*\\..*");
//回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();
while (true) {
// 获取指定数量的数据
Message message = connector.getWithoutAck(BATCH_SIZE);
System.out.println(message.getEntries().size());
//获取批量ID
long batchId = message.getId();
//获取批量的数量
int size = message.getEntries().size();
//如果没有数据
if (batchId == -1 || size == 0) {
try {
//线程休眠2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
System.out.println("----------------");
//如果有数据,处理数据
//遍历entries,单条解析
for (CanalEntry.Entry entry : message.getEntries()) {
//获取表名
String tableName = entry.getHeader().getTableName();
//获取类型
CanalEntry.EntryType entryType = entry.getEntryType();
//获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//判断entry类型是否为ROWDATA类型
if (CanalEntry.EntryType.ROWDATA.equals(entryType)){
//反序列化
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//获取当前事件操作类型
CanalEntry.EventType eventType = rowChange.getEventType();
//获取数据集
List rowDatasList = rowChange.getRowDatasList();
//遍历
for (CanalEntry.RowData rowData : rowDatasList) {
//改变前数据
JSONObject jsonObjectBefore = new JSONObject();
List beforeColumnsList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : beforeColumnsList) {
jsonObjectBefore.put(column.getName(),column.getValue());
}
//改变后数据
JSONObject jsonObjectAfter = new JSONObject();
List afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
jsonObjectAfter.put(column.getName(),column.getValue());
}
System.out.println("Table:"+tableName+",EventTpye:"+eventType+",Before:"+jsonObjectBefore+",After:"+jsonObjectAfter);
}
}else {
System.out.println("当前操作类型为:"+entryType);
}
}
}
//进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
}
} 下面,就到了最激动人心的时刻,请运行我们的Spring Boot工程:

看到这里,就代表启动成功了,下面,我们连接数据库:
mysql -uroot -p123456随便你是哪个用户连接的都行,没有数据库,你就创建新的数据库,如果已经有了,那么你直接操作里面的数据库表即可,博主目前有一个canal数据库,我们就用这个数据库:
use canal;博主里面有一张用户表,操作里面的表:
insert into user value(null ,'小明','123456',20,'13812345678');现在查看控制台有没有监听到数据库变化:
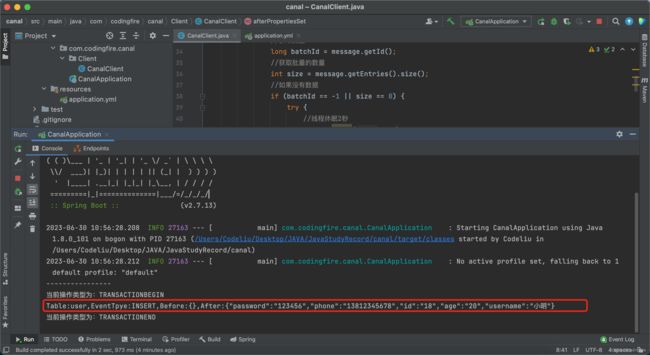
可以看到控制台已经打印出了我们刚刚操作的SQL,测试成功。
注意:这里只是监控,并不是真实使用场景,只是让大家直观看到SQL语句被监听到的场景,实际应用中,我们会结合MQ来使用,但不在这篇讲解。
结语
这篇博客只是canal 的基本配置和监听机制的讲解,旨在帮助大家了解canal的工作方式,在下一篇博客中,我们将结合MQ来做数据的同步,所以大家也不要着急,咱们慢慢来,一步一给脚印,一定要把基础知识学扎实,canal的配置相较于MySQL的主从还是很相似的,也比较简单,主要都是配置项,所以更需要我们细心,不要出错,否则一个参数的错误都是导致系统无法正常运行。好了,咱们下篇再见。