神经网络之VGG
目录
1.VGG的简单介绍
1.2结构图
3.参考代码
VGGNet-16 架构:完整指南 |卡格尔 (kaggle.com)
1.VGG的简单介绍
经典卷积神经网络的基本组成部分是下面的这个序列:
-
带填充以保持分辨率的卷积层;
-
非线性激活函数,如ReLU;
-
汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的VGG论文中 (Simonyan and Zisserman, 2014),作者使用了带有3×3卷积核、填充为1(保持高度和宽度)的卷积层,和带有2×2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。
VGG的全称是视觉几何小组,隶属于牛津大学科学与工程系。它发布了一系列从VGG开始的卷积网络模型,可以应用于人脸识别和图像分类,从VGG16到VGG19。VGG研究卷积网络深度的初衷是了解卷积网络的深度如何影响大规模图像分类和识别的准确性和准确性-Deep-16CNN),为了加深网络层数并避免参数过多,在所有层中都使用了一个小的3x3卷积核。
1.2结构图
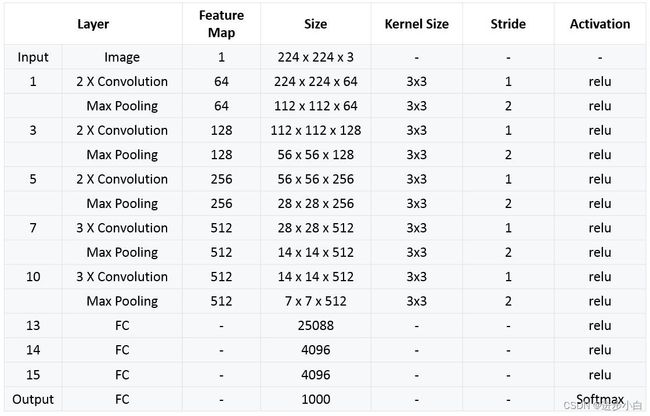
VGG的输入被设置为大小为224x244的RGB图像。为训练集图像上的所有图像计算平均RGB值,然后将该图像作为输入输入到VGG卷积网络。使用3x3或1x1滤波器,并且卷积步骤是固定的。有3个VGG全连接层,根据卷积层+全连接层的总数,可以从VGG11到VGG19变化。最小VGG11具有8个卷积层和3个完全连接层。最大VGG19具有16个卷积层+3个完全连接的层。此外,VGG网络后面没有每个卷积层后面的池化层,也没有分布在不同卷积层下的总共5个池化层。下图为VGG结构图:

关于架构图:

VGG16包含16层,VGG19包含19层。在最后三个完全连接的层中,一系列VGG完全相同。整体结构包括5组卷积层,后面是一个MaxPool。不同之处在于,在五组卷积层中包括了越来越多的级联卷积层。
3.参考代码
VGGNet-16 架构:完整指南 |卡格尔 (kaggle.com)
在这里讲述了一个比较完整的代码记录,本文参考李沐老师所写
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)#将构建一个高度和宽度为224的单通道数据样本,以观察每个层输出的形状。
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)
为了减少训练时间 将原参数量缩小到原来的1\16.
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())