hadoop集群搭建教程
目录
集群规划
所需软件包地址
开始安装
linux篇
添加用户与用户组
hadoop用户添加sudo权限
配置hostname名称
编辑hosts
配置免密
安装jdk1.8
hadoop集群篇
安装zookeeper
安装hadoop
hbase安装
hive安装
hue安装
集群规划
| ip | 主机名 | hadoop | journalnode | zookeeper | hbase |
| 192.168.1.130 | hd.m1 | namenode | journalnode | zookeeper | Hmaster |
| 192.168.1.131 | hd.m2 | namenode | journalnode | zookeeper | Hmaster |
| 192.168.1.132 | hd.n1 | datanode | journalnode | zookeeper | HRegionServer |
| 192.168.1.133 | hd.n2 | datanode | journalnode | zookeeper | HRegionServer |
| 192.168.1.134 | hd.n3 | datanode | journalnode | zookeeper | HRegionServer |
| 192.168.1.135 | hd.n4 | datanode | HRegionServer |
所需软件包地址
链接:百度网盘 请输入提取码提取码:mhur 复制这段内容后打开百度网盘手机App,操作更方便哦
开始安装
linux篇
6台主机每台都需要设置,以下在root用户下,如不在root用户下,命令前需要加sudo
-
添加用户与用户组
1)添加用户组:groupadd hadoop
2)添加用户:useradd -m -g hadoop hadoop
3)设置用户密码:passwd hadoop
-
hadoop用户添加sudo权限
1)编辑visudo文件,添加hadoop用户sudo权限
在root ALL=(ALL) ALL 下添加
hadoop ALL=(ALL) NOPASSWD:ALL
-
配置hostname名称
sudo vi /etc/sysconfig/network
添加
NETWORKING=yes
HOSTNAME=hd.m1
其中hd.m1 根据规划的ip地址设置。
设置完成后 使用hostname命令查看
-
编辑hosts
sudo vi /etc/hosts
192.168.1.130 hd.m1
192.168.1.131 hd.m2
192.168.1.132 hd.n1
192.168.1.133 hd.n2
192.168.1.134 hd.n3
192.168.1.135 hd.n4
其他几台机器配置一样,可以用使用scp 分发到其他机器
-
配置免密
每台机器上上执行
ssh-keygen -t rsa
cd ~/.ssh/
cat id_rsa.pub >>authorized_keys
然后cat 其他几台机器 id_rsa.pub 内容 到hd.m1,authorized_keys,authorized_keys文件每台机器保持一致,分发到其他几台机器
-
安装jdk1.8
先java -version查看机器上的版本

机器自带的有些问题,卸载掉,安装oracle 官网jdk
卸载步骤:rpm -qa |grep java

卸载:
sudo yum -y remove javapackages-tools-3.4.1-11.el7.noarch
卸载后
![]()
安装jdk ,准备安装包到/opt/servers/下
sudo tar -zxvf jdk-8u141-linux-x64.tar.gz
目录用户权限可以不改
cd /usr
sudo ln -s /opt/servers/jdk1.8.0_141 java 建立软连接
在配置文件中建java.sh,目录路径:/etc/profile.d/
#!/bin/sh
JAVA_HOME=/usr/java
PATH=JAVAHOME/bin:/opt/mysql/bin:JAVA_HOME/bin:/opt/mysql/bin:JAVAHOME/bin:/opt/mysql/bin:PATH
export CLASSPATH=.:$JAVA_HOME/lib
export PATH JAVA_HOME
hadoop集群篇
-
安装zookeeper
cd zookeeper/conf
编辑zoo.cfg 文件
tickTime=6000
initLimit=20
syncLimit=10
dataDir=/home/hadoop/data/zk_data
dataLogDir=/home/hadoop/data/zk_log
maxClientCnxns=10000
clientPort=2181
minSessionTimeout=10000
maxSessionTimeout=1200000
zookeeper.client.sasl=false
server.1=hd.m1:2888:3888
server.2=hd.m2:2888:3888
server.3=hd.n1:2888:3888
server.4=hd.n2:2888:3888
server.5=hd.n3:2888:3888在/home/hadoop/data/zk_data 中vi myid
1
每台设置不同值;可以按顺序配置1~5.
cd ../bin
./zkServer.sh start
[hadoop@hd conf]$ jps
22218 Jps
21803 QuorumPeerMain
有QuorumPeerMain表示zookeeper 启动成功
-
安装hadoop
一、配置
配置详见百度云盘 etc.tar.gz 文件,只需要修改
1)excludes 设置为空
2)hadoop-env.sh

3)yarn-site.xml ,根据自己机器内存配置设置
4)hdfs-site.xml ,数据节点的目录路径,设置空间最大的盘
例如:
dfs.data.dir
/home/hadoop/data/hdfs/dn
[hadoop@hd software]$ df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs 3.8G 0 3.8G 0% /dev/shm
tmpfs 3.8G 9.4M 3.8G 1% /run
tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
/dev/sda4 50G 4.0G 47G 8% /
/dev/sda2 1014M 137M 878M 14% /boot
/dev/sda5 873G 3.2G 869G 1% /home
/dev/sda1 200M 12M 189M 6% /boot/efi
tmpfs 773M 0 773M 0% /run/user/1000
5)slavers:
hd.n1
hd.n2
hd.n3
hd.n46)其他设置同etc.tar.gz
7)配置hadoop环境变量
在/etc/profile.d/下建hadoop.sh文件
set hadoop path
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=PATH:PATH:PATH:HADOOP_HOME/bin
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
set hbase path
export HBASE_HOME=/home/hadoop/hbase
export PATH=PATH:PATH:PATH:HBASE_HOME/bin
set hive path
export HIVE_HOME=/home/hadoop/hive
export PATH=PATH:PATH:PATH:HIVE_HOME/bin
#set sqoop path
export SQOOP_HOME=/home/hadoop/sqoop1
export PATH=PATH:PATH:PATH:SQOOP_HOME/bin
export SBIN_HOME=/home/hadoop/hadoop/sbin
export PATH=PATH:PATH:PATH:SBIN_HOME
set mahout path
export MAHOUT_HOME=/home/hadoop/mahout
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=MAHOUTHOME/conf:MAHOUT_HOME/conf:MAHOUTHOME/conf:MAHOUT_HOME/bin:$PATH
set maven path
#export M2_HOME=/home/hadoop/maven
#export PATH=M2HOME/bin:M2_HOME/bin:M2HOME/bin:PATH
set kylin path
export KYLIN_HOME=/home/hadoop/kylin
export PATH=KYLINHOME/bin:KYLIN_HOME/bin:KYLINHOME/bin:PATH
#set java
#export PATH=JAVAHOME/bin:JAVA_HOME/bin:JAVAHOME/bin:JRE_HOME/bin:$PATH
set history time
export HISTTIMEFORMAT="%F %T whoami "保存后,source /etc/profile.d/hadoop.sh 生效
二、启动顺序:重要
1、启动journalnode
我设置的是hd.m1,hd.m2,hd.n1,hd.n2,hd.n3,
在这几台机器上分别启动
./hadoop-daemon.sh start journalnode
启动成功会查看进程:
[hadoop@hd sbin]$ jps 16288 JournalNode
2、格式化namenode
在hd.m1节点上执行
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置的目录下生成个hdfs初始化文件,
使用:hdfs namenode -bootstrapStandby 同步初始化文件到hd.m2
此处注意:如果没有启动journalnode,格式化会失败
3、格式化zkfc
hdfs zkfc -formatZK
4、启动HDFS(在hd.m1上执行)
./start-dfs.sh
5、启动YARN
start-yarn.sh
还需要手动在standby即hd.m2上手动启动的 resourcemanager
yarn-daemon.sh start resourcemanager
6、验证配置
hadoop配置完毕,可以浏览器访问:
http://192.168.1.130:50070
NameNode 'hd.m1:9000' (active)
http://192.168.1.131:50070
NameNode 'hd.m2:9000' (standby)
7、遇到问题
hd.m1 namenode resourcemanager 都存在
但是查看hd.m1的50070页面 显示节点都是dead状态
查看日志,提示全网namenode的ClusterID和datanode的ClusterID之间不一致的问题解决办法
先停止namenode resourcemanager
./hadoop-daemon.sh stop namenode
./yarn-daemon.sh stop resourcemanager
同步hd.m2 的/home/hadoop/data/hdfs/nn/current/version 文件到hd.m1
scp /home/hadoop/data/hdfs/nn/current/version [email protected]$PWD
再重新启动:注意顺序,先resourcemanager,再启动namenode
./yarn-daemon.sh start resourcemanager
./hadoop-daemon.sh start namenode
再次查192.168.1.130:50070
显示正常。
至此 hadoop 安装完毕
-
hbase安装
比较简单
解压后,配置regionservers
hd.n1
hd.n2
hd.n3
hd.n4在hd.m1上启动
start-hbase.sh
然后再hd.m2 上启动
/hbase-daemon.sh start master
查看 192.168.1.130:60010
192.168.1.131:60010 界面查看hbase管理页面
至此完成hbase 安装
后记:查看nn1 nn2状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
在hdfs-site.xml中配置了为true
dfs.ha.automatic-failover.enabled
hdfs haadmin -failover -forcefence -forceactive nn2 nn1 会提示
forcefence and forceactive flags not supported with auto-failover enabled.
不能切换
-
hive安装
从hive.apache.org 下载1.2.2
进入conf 配置
hive-env.sh
if [ "$SERVICE" = "cli" ]; then
if [ -z "$DEBUG" ]; then
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms10m -Xmx4096m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:+UseParNewGC -XX:-UseGCOverheadLimit"
else
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xms10m -Xmx4096m -XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:-UseGCOverheadLimit"
fi
fi
# The heap size of the jvm stared by hive shell script can be controlled via:
#
# export HADOOP_HEAPSIZE=4096
#
# Larger heap size may be required when running queries over large number of files or partitions.
# By default hive shell scripts use a heap size of 256 (MB). Larger heap size would also be
# appropriate for hive server (hwi etc).
# Set HADOOP_HOME to point to a specific hadoop install directory
export JAVA_HOME=/usr/java/jdk1.7.0_71
export HADOOP_HOME=/home/hadoop/hadoop
export HIVE_HOME=/home/hadoop/hive
export HADOOP_CLASSPATH=/home/hadoop/hbase/lib/*
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=$HIVE_HOME/conf
# Folder containing extra ibraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/home/hadoop/atlas/hook/hive
hive-site.xml mysql 的配置
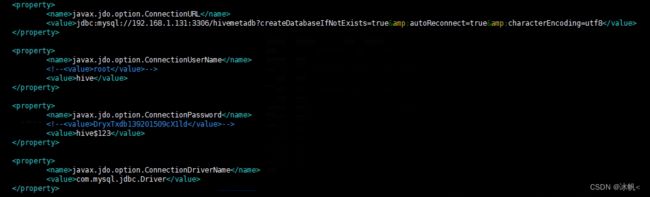
创建mysql hive 用户,创建hivemetadb数据库,并赋予hive 用户数据库访问权限
给hive用户权限
GRANT ALL PRIVILEGES ON hivemetadb.* TO 'hive'@'%' IDENTIFIED BY 'hive$123';
FLUSH PRIVILEGES;hue安装
安装linux 包:
sudo yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel安装python3.8
1、依赖包安装
sudo yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel2、下载包:Index of /ftp/python/3.8.0/wget https://www.python.org/ftp/python/3.8.0/Python-3.8.0a1.tgz
3、解压:tar -zvf Python-3.8.0.tgz
4、安装:cd Python-3.8.0
./configure --prefix=/usr/local/python3
make && make install
5、建立软连接
ln -s /usr/local/python3/bin/python3.8 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3.8 /usr/bin/pip3
配置环境变量
下载hue,解压
make apps
如果使用python2.7 找不到python.h文件
可以参考这个,比较详细
安装hue-3.12.0_python-
yum -y install git gcc-c++ asciidoc cyrus-sasl-devel cyrus-sasl-gssapi krb5-devel libxml2-devel el python-devel sqlite-devel openssl-devel gmp-devel openldap-devel mysql-server mysql mysql-devel libxslt-devel libffi libffi-develrpm -qa | grep python-2.7.5-76.el7.x86_64 |xargs rpm -e --nodeps
yum install mysql-devel yum install openldap-devel安装node
wget https://npm.taobao.org/mirrors/node/v10.14.1/node-v10.14.1-linux-x64.tar.gz
tar -xvf node-v10.14.1-linux-x64.tar.gz mv node-v10.14.1-linux-x64 node
环境变量
export NODE_HOME=/usr/local/nodeexport
PATH=NODEHOME/bin:NODE_HOME/bin:NODEHOME/bin:PATH
npm —version
ln -s /home/hadoop/node/bin/npx /usr/local/bin/npx
ln -s /home/hadoop/node/bin/npm /usr/local/bin/npm
ln -s /home/hadoop/node/bin/node /usr/local/bin/node
下载hue-release-4.9.0.tar.gz版本
配置:/home/hadoop/hue-release-4.9.0/desktop/conf/pseudo-distributed.ini
# Hue configuration file
# ===================================
#
# For complete documentation about the contents of this file, run
# $ /build/env/bin/hue config_help
#
# All .ini files under the current directory are treated equally. Their
# contents are merged to form the Hue configuration, which can
# can be viewed on the Hue at
# http://:/dump_config
###########################################################################
# General configuration for core Desktop features (authentication, etc)
###########################################################################
[desktop]
# Set this to a random string, the longer the better.
# This is used for secure hashing in the session store.
#secret_key=jFE93j;2maomaosi22943d['d;/.q[eIW^y#e=+Iei*@
secret_key=
# Execute this script to produce the Django secret key. This will be used when
# 'secret_key' is not set.
## secret_key_script=
# Webserver listens on this address and port
http_host=0.0.0.0
http_port=8888
# A comma-separated list of available Hue load balancers
## hue_load_balancer=
# Time zone name
time_zone=Asia/Shanghai
# Enable or disable debug mode.
django_debug_mode=false
# Enable development mode, where notably static files are not cached.
## dev=false
# Enable or disable database debug mode.
## database_logging=false
# Whether to send debug messages from JavaScript to the server logs.
## send_dbug_messages=false
# Enable or disable backtrace for server error
http_500_debug_mode=false
# Enable or disable instrumentation. If django_debug_mode is True, this is automatically enabled
## instrumentation=false
# Server email for internal error messages
## django_server_email='[email protected]'
# Email backend
## django_email_backend=django.core.mail.backends.smtp.EmailBackend
# Set to true to use CherryPy as the webserver, set to false
# to use Gunicorn as the webserver. Defaults to CherryPy if
# key is not specified.
## use_cherrypy_server=true
# Gunicorn work class: gevent or evenlet, gthread or sync.
## gunicorn_work_class=eventlet
# The number of Gunicorn worker processes. If not specified, it uses: (number of CPU * 2) + 1.
## gunicorn_number_of_workers=None
# Webserver runs as this user
server_user=hadoop
server_group=hadoop
# This should be the Hue admin and proxy user
default_user=hue
# This should be the hadoop cluster admin
default_hdfs_superuser=hadoop
# If set to false, runcpserver will not actually start the web server.
# Used if Apache is being used as a WSGI container.
## enable_server=yes
# Number of threads used by the CherryPy web server
## cherrypy_server_threads=50
# This property specifies the maximum size of the receive buffer in bytes in thrift sasl communication,
# default value is 2097152 (2 MB), which equals to (2 * 1024 * 1024)
## sasl_max_buffer=2097152
# Hue will try to get the actual host of the Service, even if it resides behind a load balancer.
# This will enable an automatic configuration of the service without requiring custom configuration of the service load balancer.
# This is available for the Impala service only currently. It is highly recommended to only point to a series of coordinator-only nodes only.
# enable_smart_thrift_pool=false
# Filename of SSL Certificate
## ssl_certificate=
# Filename of SSL RSA Private Key
## ssl_private_key=
# Filename of SSL Certificate Chain
## ssl_certificate_chain=
# SSL certificate password
## ssl_password=
# Execute this script to produce the SSL password. This will be used when 'ssl_password' is not set.
## ssl_password_script=
# Disable all renegotiation in TLSv1.2 and earlier. Do not send HelloRequest messages, and ignore renegotiation requests via ClientHello. This option is only available with OpenSSL 1.1.0h and later and python 3.7
## ssl_no_renegotiation=python.version >= 3.7
# X-Content-Type-Options: nosniff This is a HTTP response header feature that helps prevent attacks based on MIME-type confusion.
## secure_content_type_nosniff=true
# X-Xss-Protection: \"1; mode=block\" This is a HTTP response header feature to force XSS protection.
## secure_browser_xss_filter=true
# X-Content-Type-Options: nosniff This is a HTTP response header feature that helps prevent attacks based on MIME-type confusion.
## secure_content_security_policy="script-src 'self' 'unsafe-inline' 'unsafe-eval' *.google-analytics.com *.doubleclick.net data:;img-src 'self' *.google-analytics.com *.doubleclick.net http://*.tile.osm.org *.tile.osm.org *.gstatic.com data:;style-src 'self' 'unsafe-inline' fonts.googleapis.com;connect-src 'self';frame-src *;child-src 'self' data: *.vimeo.com;object-src 'none'"
# Strict-Transport-Security HTTP Strict Transport Security(HSTS) is a policy which is communicated by the server to the user agent via HTTP response header field name "Strict-Transport-Security". HSTS policy specifies a period of time during which the user agent(browser) should only access the server in a secure fashion(https).
## secure_ssl_redirect=False
## secure_redirect_host=0.0.0.0
## secure_redirect_exempt=[]
## secure_hsts_seconds=31536000
## secure_hsts_include_subdomains=true
# List of allowed and disallowed ciphers in cipher list format.
# See http://www.openssl.org/docs/apps/ciphers.html for more information on
# cipher list format. This list is from
# https://wiki.mozilla.org/Security/Server_Side_TLS v3.7 intermediate
# recommendation, which should be compatible with Firefox 1, Chrome 1, IE 7,
# Opera 5 and Safari 1.
## ssl_cipher_list=ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA
# Path to default Certificate Authority certificates.
## ssl_cacerts=/etc/hue/cacerts.pem
# Choose whether Hue should validate certificates received from the server.
## ssl_validate=true
# Default LDAP/PAM/.. username and password of the hue user used for authentications with other services.
# Inactive if password is empty.
# e.g. LDAP pass-through authentication for HiveServer2 or Impala. Apps can override them individually.
## auth_username=hue
## auth_password=
# Default encoding for site data
## default_site_encoding=utf-8
# Help improve Hue with anonymous usage analytics.
# Use Google Analytics to see how many times an application or specific section of an application is used, nothing more.
## collect_usage=true
# Tile layer server URL for the Leaflet map charts
# Read more on http://leafletjs.com/reference.html#tilelayer
# Make sure you add the tile domain to the img-src section of the 'secure_content_security_policy' configuration parameter as well.
## leaflet_tile_layer=http://{s}.tile.osm.org/{z}/{x}/{y}.png
# The copyright message for the specified Leaflet maps Tile Layer
## leaflet_tile_layer_attribution='© OpenStreetMap contributors'
# All the map options accordingly to http://leafletjs.com/reference-0.7.7.html#map-options
# To change CRS, just use the name, ie. "EPSG4326"
## leaflet_map_options='{}'
# All the tile layer options, accordingly to http://leafletjs.com/reference-0.7.7.html#tilelayer
## leaflet_tile_layer_options='{}'
# X-Frame-Options HTTP header value. Use 'DENY' to deny framing completely
## http_x_frame_options=SAMEORIGIN
# Enable X-Forwarded-Host header if the load balancer requires it.
## use_x_forwarded_host=true
# Support for HTTPS termination at the load-balancer level with SECURE_PROXY_SSL_HEADER.
## secure_proxy_ssl_header=false
# Comma-separated list of Django middleware classes to use.
# See https://docs.djangoproject.com/en/1.4/ref/middleware/ for more details on middlewares in Django.
## middleware=desktop.auth.backend.LdapSynchronizationBackend
# Comma-separated list of regular expressions, which match the redirect URL.
# For example, to restrict to your local domain and FQDN, the following value can be used:
# ^\/.*$,^http:\/\/www.mydomain.com\/.*$
## redirect_whitelist=^(\/[a-zA-Z0-9]+.*|\/)$
# Comma separated list of apps to not load at server startup.
# e.g.: pig,zookeeper
## app_blacklist=
# Id of the cluster where Hue is located.
## cluster_id='default'
# Choose whether to show the new SQL editor.
## use_new_editor=true
# Global setting to allow or disable end user downloads in all Hue.
# e.g. Query result in Editors and Dashboards, file in File Browser...
## enable_download=true
# Global setting to enable or disable document sharing.
# Note that this does not affect currently shared documents.
## enable_sharing=true
# Choose whether to enable SQL syntax check or not
## enable_sql_syntax_check=true
# Choose whether to show the improved assist panel and the right context panel
## use_new_side_panels=false
# Choose whether to use new charting library across the whole Hue.
## use_new_charts=false
# Choose whether to allow multi tenancy or not.
## enable_organizations=false
# Editor autocomplete timeout (ms) when fetching columns, fields, tables etc.
# To disable this type of autocompletion set the value to 0.
## editor_autocomplete_timeout=30000
# Enable saved default configurations for Hive, Impala, Spark, and Oozie.
## use_default_configuration=false
# The directory where to store the auditing logs. Auditing is disable if the value is empty.
# e.g. /var/log/hue/audit.log
## audit_event_log_dir=
# Size in KB/MB/GB for audit log to rollover.
## audit_log_max_file_size=100MB
# Timeout in seconds for REST calls.
## rest_conn_timeout=120
# A json file containing a list of log redaction rules for cleaning sensitive data
# from log files. It is defined as:
#
# {
# "version": 1,
# "rules": [
# {
# "description": "This is the first rule",
# "trigger": "triggerstring 1",
# "search": "regex 1",
# "replace": "replace 1"
# },
# {
# "description": "This is the second rule",
# "trigger": "triggerstring 2",
# "search": "regex 2",
# "replace": "replace 2"
# }
# ]
# }
#
# Redaction works by searching a string for the [TRIGGER] string. If found,
# the [REGEX] is used to replace sensitive information with the
# [REDACTION_MASK]. If specified with 'log_redaction_string', the
# 'log_redaction_string' rules will be executed after the
# 'log_redaction_file' rules.
#
# For example, here is a file that would redact passwords and social security numbers:
# {
# "version": 1,
# "rules": [
# {
# "description": "Redact passwords",
# "trigger": "password",
# "search": "password=\".*\"",
# "replace": "password=\"???\""
# },
# {
# "description": "Redact social security numbers",
# "trigger": "",
# "search": "\d{3}-\d{2}-\d{4}",
# "replace": "XXX-XX-XXXX"
# }
# ]
# }
## log_redaction_file=
# Comma separated list of strings representing the host/domain names that the Hue server can serve.
# e.g.: localhost,domain1,*
## allowed_hosts="*"
# Allow use django debug tool with Chrome browser for debugging issue, django_debug_mode must be true also
## enable_django_debug_tool=false
# Comma separated list of users' username that allow to use django debug tool. If it is empty, all users are allowed.
## django_debug_tool_users=
# Number of characters in rest api reponse calls to dump to the logs when debug is enabled. Set to -1 for entire response.
## rest_response_size=2000
# Turn on Prometheus metrics end point /metrics.
## enable_prometheus=false
# Turn on the Gist snippet sharing.
## enable_gist=true
# Add public description so that the link can be unfurled in a preview by websites like Slack.
# Only enabled automatically in private setups.
## enable_gist_preview=true
# Turn on the direct link sharing of saved document.
## enable_link_sharing=true
# Hue uses Localstorage to keep the users settings and database preferences.
# Please make this value true in case local storage should not be used
# default value is false
## disable_local_storage = false
# Administrators
# ----------------
[[django_admins]]
## [[[admin1]]]
## name=john
## [email protected]
# UI customizations
# -------------------
[[custom]]
# Top banner HTML code
# e.g. Test Lab A2 Hue Services
## banner_top_html='This is Hue 4 Beta! - Please feel free to email any feedback / questions to [email protected] or @gethue.'
# Login splash HTML code
# e.g. WARNING: You are required to have authorization before you proceed
## login_splash_html=GetHue.com
WARNING: You have accessed a computer managed by GetHue. You are required to have authorization from GetHue before you proceed.
# Cache timeout in milliseconds for the assist, autocomplete, etc.
# defaults to 10 days, set to 0 to disable caching
## cacheable_ttl=864000000
# SVG code to replace the default Hue logo in the top bar and sign in screen
# e.g. for the parameter
# For use when using LdapBackend for Hue authentication
## ldap_username_pattern="uid=,ou=People,dc=mycompany,dc=com"
# Create users in Hue when they try to login with their LDAP credentials
# For use when using LdapBackend for Hue authentication
## create_users_on_login = true
# Synchronize a users groups when they login
## sync_groups_on_login=true
# A comma-separated list of Ldap groups with users that can login
## login_groups=
# Ignore the case of usernames when searching for existing users in Hue.
## ignore_username_case=true
# Force usernames to lowercase when creating new users from LDAP.
# Takes precedence over force_username_uppercase
## force_username_lowercase=true
# Force usernames to uppercase, cannot be combined with force_username_lowercase
## force_username_uppercase=false
# Use search bind authentication.
## search_bind_authentication=true
# Choose which kind of subgrouping to use: nested or suboordinate (deprecated).
## subgroups=suboordinate
# Define the number of levels to search for nested members.
## nested_members_search_depth=10
# Whether or not to follow referrals
## follow_referrals=false
# Enable python-ldap debugging.
## debug=false
# Sets the debug level within the underlying LDAP C lib.
## debug_level=255
# Possible values for trace_level are 0 for no logging, 1 for only logging the method calls with arguments,
# 2 for logging the method calls with arguments and the complete results and 9 for also logging the traceback of method calls.
## trace_level=0
[[[users]]]
# Base filter for searching for users
## user_filter="objectclass=*"
# The username attribute in the LDAP schema
## user_name_attr=sAMAccountName
[[[groups]]]
# Base filter for searching for groups
## group_filter="objectclass=*"
# The group name attribute in the LDAP schema
## group_name_attr=cn
# The attribute of the group object which identifies the members of the group
## group_member_attr=members
[[[ldap_servers]]]
## [[[[mycompany]]]]
# The search base for finding users and groups
## base_dn="DC=mycompany,DC=com"
# URL of the LDAP server
## ldap_url=ldap://auth.mycompany.com
# The NT domain used for LDAP authentication
## nt_domain=mycompany.com
# A PEM-format file containing certificates for the CA's that
# Hue will trust for authentication over TLS.
# The certificate for the CA that signed the
# LDAP server certificate must be included among these certificates.
# See more here http://www.openldap.org/doc/admin24/tls.html.
## ldap_cert=
## use_start_tls=true
# Distinguished name of the user to bind as -- not necessary if the LDAP server
# supports anonymous searches
## bind_dn="CN=ServiceAccount,DC=mycompany,DC=com"
# Password of the bind user -- not necessary if the LDAP server supports
# anonymous searches
## bind_password=
# Execute this script to produce the bind user password. This will be used
# when 'bind_password' is not set.
## bind_password_script=
# Pattern for searching for usernames -- Use for the parameter
# For use when using LdapBackend for Hue authentication
## ldap_username_pattern="uid=,ou=People,dc=mycompany,dc=com"
## Use search bind authentication.
## search_bind_authentication=true
# Whether or not to follow referrals
## follow_referrals=false
# Enable python-ldap debugging.
## debug=false
# Sets the debug level within the underlying LDAP C lib.
## debug_level=255
# Possible values for trace_level are 0 for no logging, 1 for only logging the method calls with arguments,
# 2 for logging the method calls with arguments and the complete results and 9 for also logging the traceback of method calls.
## trace_level=0
## [[[[[users]]]]]
# Base filter for searching for users
## user_filter="objectclass=Person"
# The username attribute in the LDAP schema
## user_name_attr=sAMAccountName
## [[[[[groups]]]]]
# Base filter for searching for groups
## group_filter="objectclass=groupOfNames"
# The username attribute in the LDAP schema
## group_name_attr=cn
# Configuration options for specifying the Source Version Control.
# ----------------------------------------------------------------
[[vcs]]
## [[[git-read-only]]]
## Base URL to Remote Server
# remote_url=https://github.com/cloudera/hue/tree/master
## Base URL to Version Control API
# api_url=https://api.github.com
## [[[github]]]
## Base URL to Remote Server
# remote_url=https://github.com/cloudera/hue/tree/master
## Base URL to Version Control API
# api_url=https://api.github.com
# These will be necessary when you want to write back to the repository.
## Client ID for Authorized Application
# client_id=
## Client Secret for Authorized Application
# client_secret=
## [[[svn]]
## Base URL to Remote Server
# remote_url=https://github.com/cloudera/hue/tree/master
## Base URL to Version Control API
# api_url=https://api.github.com
# These will be necessary when you want to write back to the repository.
## Client ID for Authorized Application
# client_id=
## Client Secret for Authorized Application
# client_secret=
# Configuration options for specifying the Desktop Database. For more info,
# see http://docs.djangoproject.com/en/1.11/ref/settings/#database-engine
# ------------------------------------------------------------------------
[[database]]
# Database engine is typically one of:
# postgresql_psycopg2, mysql, sqlite3 or oracle.
#
# Note that for sqlite3, 'name', below is a path to the filename. For other backends, it is the database name
# Note for Oracle, options={"threaded":true} must be set in order to avoid crashes.
# Note for Oracle, you can use the Oracle Service Name by setting "host=" and "port=" and then "name=:/".
# Note for MariaDB use the 'mysql' engine.
engine=mysql
host=127.0.0.1
port=3306
user=root
password=******
# conn_max_age option to make database connection persistent value in seconds
# https://docs.djangoproject.com/en/1.11/ref/databases/#persistent-connections
## conn_max_age=0
# Execute this script to produce the database password. This will be used when 'password' is not set.
## password_script=/path/script
## name=desktop/desktop.db
name=hue
## options={}
# Database schema, to be used only when public schema is revoked in postgres
## schema=public
# Configuration options for specifying the Desktop session.
# For more info, see https://docs.djangoproject.com/en/1.4/topics/http/sessions/
# ------------------------------------------------------------------------
[[session]]
# The name of the cookie to use for sessions.
# This can have any value that is not used by the other cookie names in your application.
## cookie_name=sessionid
# The cookie containing the users' session ID will expire after this amount of time in seconds.
# Default is 2 weeks.
## ttl=1209600
# The cookie containing the users' session ID and csrf cookie will be secure.
# Should only be enabled with HTTPS.
## secure=false
# The cookie containing the users' session ID and csrf cookie will use the HTTP only flag.
## http_only=true
# Use session-length cookies. Logs out the user when she closes the browser window.
## expire_at_browser_close=false
# If set, limits the number of concurrent user sessions. 1 represents 1 browser session per user. Default: 0 (unlimited sessions per user)
## concurrent_user_session_limit=0
# A list of hosts which are trusted origins for unsafe requests. See django's CSRF_TRUSTED_ORIGINS for more information
## trusted_origins=.cloudera.com
# Configuration options for connecting to an external SMTP server
# ------------------------------------------------------------------------
[[smtp]]
# The SMTP server information for email notification delivery
host=smtp.163.com
port=25
[email protected]
password=*****
# Whether to use a TLS (secure) connection when talking to the SMTP server
tls=no
# Default email address to use for various automated notification from Hue
## default_from_email=hue@localhost
# Configuration options for KNOX integration for secured CDPD cluster
# ------------------------------------------------------------------------
[[knox]]
# This is a list of hosts that knox proxy requests can come from
## knox_proxyhosts=server1.domain.com,server2.domain.com
# List of Kerberos principal name which is allowed to impersonate others
## knox_principal=knox1,knox2
# Comma separated list of strings representing the ports that the Hue server can trust as knox port.
## knox_ports=80,8443
# Configuration options for Kerberos integration for secured Hadoop clusters
# ------------------------------------------------------------------------
[[kerberos]]
# Path to Hue's Kerberos keytab file
## hue_keytab=
# Kerberos principal name for Hue
## hue_principal=hue/hostname.foo.com
# Frequency in seconds with which Hue will renew its keytab
## REINIT_FREQUENCY=3600
# Path to keep Kerberos credentials cached
## ccache_path=/var/run/hue/hue_krb5_ccache
# Path to kinit
## kinit_path=/path/to/kinit
# Set to false if renew_lifetime in krb5.conf is set to 0m
## krb5_renewlifetime_enabled=true
# Mutual authentication from the server, attaches HTTP GSSAPI/Kerberos Authentication to the given Request object
## mutual_authentication="OPTIONAL" or "REQUIRED" or "DISABLED"
# Configuration options for using OAuthBackend (Core) login
# ------------------------------------------------------------------------
[[oauth]]
# The Consumer key of the application
## consumer_key=XXXXXXXXXXXXXXXXXXXXX
# The Consumer secret of the application
## consumer_secret=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
# The Request token URL
## request_token_url=https://api.twitter.com/oauth/request_token
# The Access token URL
## access_token_url=https://api.twitter.com/oauth/access_token
# The Authorize URL
## authenticate_url=https://api.twitter.com/oauth/authorize
# Configuration options for using OIDCBackend (Core) login for SSO
# ------------------------------------------------------------------------
[[oidc]]
# The client ID as relay party set in OpenID provider
## oidc_rp_client_id=XXXXXXXXXXXXXXXXXXXXX
# The client secret as relay party set in OpenID provider
## oidc_rp_client_secret=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
# The OpenID provider authoriation endpoint
## oidc_op_authorization_endpoint=https://keycloak.example.com/auth/realms/Cloudera/protocol/openid-connect/auth
# The OpenID provider token endpoint
## oidc_op_token_endpoint=https://keycloak.example.com/auth/realms/cloudera/protocol/openid-connect/token
# The OpenID provider user info endpoint
## oidc_op_user_endpoint=https://keycloak.example.com/auth/realms/cloudera/protocol/openid-connect/userinfo
# The OpenID provider signing key in PEM or DER format
## oidc_rp_idp_sign_key=/path/to/key_file
# The OpenID provider authoriation endpoint
## oidc_op_jwks_endpoint=https://keycloak.example.com/auth/realms/Cloudera/protocol/openid-connect/certs
# Whether Hue as OpenID Connect client verify SSL cert
## oidc_verify_ssl=true
# As relay party Hue URL path to redirect to after login
## login_redirect_url=https://localhost:8888/oidc/callback/
# The OpenID provider URL path to redirect to after logout
## logout_redirect_url=https://keycloak.example.com/auth/realms/cloudera/protocol/openid-connect/logout
# As relay party Hue URL path to redirect to after login
## login_redirect_url_failure=https://localhost:8888/hue/oidc_failed/
# Create a new user from OpenID Connect on login if it doesn't exist
## create_users_on_login=true
# When creating a new user, which 'claims' attribute from the OIDC provider to be used for creating the username.
# Default to 'preferred_username'. Possible values include: 'email'
## oidc_username_attribute=preferred_username
# The group of users will be created and updated as superuser. To use this feature, setup in Keycloak:
# 1. add the name of the group here
# 2. in Keycloak, go to your_realm --> your_clients --> Mappers, add a mapper
# Mapper Type: Group Membership (this is predefined mapper type)
# Token Claim Name: group_membership (required exact string)
## superuser_group=hue_superusers
# Configuration options for Metrics
# ------------------------------------------------------------------------
[[metrics]]
# Enable the metrics URL "/desktop/metrics"
## enable_web_metrics=True
# If specified, Hue will write metrics to this file.
## location=/var/log/hue/metrics.json
# Time in milliseconds on how frequently to collect metrics
## collection_interval=30000
# Configuration options for the request Tracing
# ------------------------------------------------------------------------
[[tracing]]
## If tracing is enabled.
# enabled=false
## Trace all the requests instead of a few specific ones like the SQL Editor. Much noisiers.
# trace_all=false
# Configuration options for the Task Server
# ------------------------------------------------------------------------
[[task_server]]
# If resource intensive or blocking can be delegated to an already running task server.
## enabled=False
# Switch on the integration with the Task Scheduler.
## beat_enabled=False
# Number of query results rows to fetch into the result storage.
## fetch_result_limit=2000
# Django file storage class to use to temporarily store query results
## result_storage='{"backend": "django.core.files.storage.FileSystemStorage", "properties": {"location": "./logs"}}'
# How the task server and tasks communicate.
## broker_url=amqp://guest:guest@localhost//
# Where to store task results. Defaults to local file system path. Celery comes with a several other backends.
## celery_result_backend=file:///$HUE_ROOT/logs
# Default options provided to the task server at startup.
## celeryd_opts='--time-limit=300'
# Django cache to use to store temporarily used data during query execution. This is in addition to result_file_storage and result_backend.
## execution_storage='{"BACKEND": "django.core.cache.backends.locmem.LocMemCache", "LOCATION": "celery-hue"}'
# Path to a file containing a list of beat schedules.
# beat_schedules_file=/etc/hue/conf/schedules.py
# e.g.
# periodic_tasks = [{
# 'add-every-monday-morning': {
# 'task': 'desktop.celery.debug_task',
# 'schedule': crontab(minute='*'),
# },
# },
# {
# 'customer_count_query': {
# 'task': 'notebook.tasks.run_sync_query',
# 'schedule': crontab(minute='*'),
# 'args': (None, None),
# },
# }
# ]
# Settings for the Google Cloud lib
# ------------------------------------------------------------------------
[[gc_accounts]]
[[[default]]]
# The JSON credentials to authenticate to Google Cloud e.g. '{ "type": "service_account", "project_id": .... }'
# json_credentials=None
###########################################################################
# Settings to configure the snippets available in the Notebook
###########################################################################
[notebook]
## Show the notebook menu or not
# show_notebooks=true
## Flag to enable the selection of queries from files, saved queries into the editor or as snippet.
# enable_external_statements=false
## Flag to enable the bulk submission of queries as a background task through Oozie.
# enable_batch_execute=true
## Flag to turn on the SQL indexer.
# enable_sql_indexer=false
## Flag to turn on the Presentation mode of the editor.
# enable_presentation=true
## Flag to enable the SQL query builder of the table assist (deprecated).
# enable_query_builder=false
## Flag to enable the creation of a coordinator for the current SQL query.
# enable_query_scheduling=false
## Main flag to override the automatic starting of the DBProxy server.
# enable_dbproxy_server=true
## Classpath to be appended to the default DBProxy server classpath.
# dbproxy_extra_classpath=
## Comma separated list of interpreters that should be shown on the wheel. This list takes precedence over the
## order in which the interpreter entries appear. Only the first 5 interpreters will appear on the wheel.
# interpreters_shown_on_wheel=
## Default limit to use in SELECT statements if not present. Set to 0 to disable.
# default_limit=5000
# One entry for each type of snippet.
[[interpreters]]
# Define the name and how to connect and execute the language.
# https://docs.gethue.com/administrator/configuration/editor/
[[[mysql]]]
name = MySQL
interface=sqlalchemy
# ## https://docs.sqlalchemy.org/en/latest/dialects/mysql.html
# options='{"url": "mysql://root:secret@database:3306/hue"}'
options='{"url": "mysql://root:[email protected]:3306/hue"}'
[[[hive]]]
name=Hive
interface=hiveserver2
# [[[llap]]]
# name=LLAP
# interface=hiveserver2
[[[impala]]]
name=Impala
interface=hiveserver2
# [[[postgresql]]]
# name = postgresql
# interface=sqlalchemy
# options='{"url": "postgresql://hue:hue@host:5432/hue"}'
# [[[druid]]]
# name = Druid
# interface=sqlalchemy
# options='{"url": "druid://host:8082/druid/v2/sql/"}'
[[[sql]]]
name=SparkSql
interface=livy
[[[spark]]]
name=Scala
interface=livy
[[[pyspark]]]
name=PySpark
interface=livy
[[[r]]]
name=R
interface=livy
# [[jar]]]
# name=Spark Submit Jar
# interface=livy-batch
[[[py]]]
name=Spark Submit Python
interface=livy-batch
[[[text]]]
name=Text
interface=text
[[[markdown]]]
name=Markdown
interface=text
[[[sqlite]]]
name = SQLite
interface=rdbms
[[[oracle]]]
name = Oracle
interface=rdbms
[[[solr]]]
name = Solr SQL
interface=solr
## Name of the collection handler
options='{"collection": "default"}'
[[[pig]]]
name=Pig
interface=oozie
[[[java]]]
name=Java
interface=oozie
[[[spark2]]]
name=Spark
interface=oozie
[[[mapreduce]]]
name=MapReduce
interface=oozie
[[[sqoop1]]]
name=Sqoop1
interface=oozie
[[[distcp]]]
name=Distcp
interface=oozie
[[[shell]]]
name=Shell
interface=oozie
# [[[presto]]]
# name=Presto SQL
# interface=sqlalchemy
# ## Specific options for connecting to the Presto server.
# ## The JDBC driver presto-jdbc.jar need to be in the CLASSPATH environment variable.
# ## If 'user' and 'password' are omitted, they will be prompted in the UI.
# options='{"url": "jdbc:presto://localhost:8080/catalog/schema", "driver": "io.prestosql.jdbc.PrestoDriver", "user": "root", "password": "root"}'
# ## Impersonation on.
# options='{"url": "presto://hd.m1:8080/hive/default", "has_impersonation": true}'
# ## Kerberos.
# # options='{"url": "presto://localhost:8080/hive/default?KerberosKeytabPath=/path/to/keytab&KerberosPrincipal=principal&KerberosRemoteServiceName=service&protocol=https"'
# ## LDAPS enabled over HTTPS.
# # options='{"url": "presto://username:password@localhost:8443/tpch/default","connect_args":"{\"protocol\": \"https\"}"}'
# ## Presto Session properties along with HTTPS.
# # options='{"url": "presto://username:password@localhost:8443/tpch/default","connect_args":"{\"protocol\": \"https\", \"session_props\": {\"query_max_run_time\": \"1m\"}}"}'
# ## Presto Session properties when HTTPS is not enabled.
# # options='{"url": "presto://username:password@localhost:8080/tpch/default","connect_args":"{\"session_props\": {\"query_max_run_time\": \"1m\"}}"}'
# [[[dasksql]]]
# name=Dask-SQL
# interface=sqlalchemy
# ## Specific options for connecting to the dask-sql server.
# ## Please note, that dask-sql uses the presto protocol.
# # options='{"url": "presto://localhost:8080/catalog/default"}'
[[[clickhouse]]]
name=ClickHouse
interface=jdbc
# ## Specific options for connecting to the ClickHouse server.
# ## The JDBC driver clickhouse-jdbc.jar and its related jars need to be in the CLASSPATH environment variable.
options='{"url": "jdbc:clickhouse://hd.n2:8123", "driver": "ru.yandex.clickhouse.ClickHouseDriver", "user": "default", "password": ""}'
# [[[vertica]]]
# name=Vertica
# interface=jdbc
# ## Specific options for connecting to a Vertica server.
# ## The JDBC driver vertica-jdbc-*.jar and its related jars need to be in the CLASSPATH environment variable.
# ## If 'user' and 'password' are omitted, they will be prompted in the UI.
# options='{"url": "jdbc:vertica://localhost:5434", "driver": "com.vertica.jdbc.Driver"}'
## Define which query and table examples can be automatically setup for the available dialects.
# [[examples]]
## If installing the examples automatically at startup.
# auto_load=false
## If automatically loading the dialect example at Editor opening.
# auto_open=false
## Names of the saved queries to install. All if empty.
# queries=
## Names of the tables to install. All if empty.
# tables=
###########################################################################
# Settings to configure your Analytics Dashboards
###########################################################################
[dashboard]
# Activate the Dashboard link in the menu.
## is_enabled=true
# Activate the SQL Dashboard (beta).
## has_sql_enabled=false
# Activate the Query Builder (beta).
## has_query_builder_enabled=false
# Activate the static report layout (beta).
## has_report_enabled=false
# Activate the new grid layout system.
## use_gridster=true
# Activate the widget filter and comparison (beta).
## has_widget_filter=false
# Activate the tree widget (to drill down fields as dimensions, alpha).
## has_tree_widget=false
[[engines]]
# [[[solr]]]
# Requires Solr 6+
## analytics=true
## nesting=false
# [[[sql]]]
## analytics=true
## nesting=false
###########################################################################
# Settings to configure your Hadoop cluster.
###########################################################################
[hadoop]
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
# HA support by using HttpFs
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://hdfs-nn
# NameNode logical name.
logical_name=hadoop
# Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is 14000 for HttpFs.
webhdfs_url=http://hd.m1:14000/webhdfs/v1
# Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false
# In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True
# Directory of the Hadoop configuration
## hadoop_conf_dir=$HADOOP_CONF_DIR when set or '/etc/hadoop/conf'
hadoop_conf_dir=/home/hadoop/hadoop/conf
# Whether Hue should list this HDFS cluster. For historical reason there is no way to disable HDFS.
## is_enabled=true
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]]
[[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=hd.m1
# The port where the ResourceManager IPC listens on
resourcemanager_port=8032
# Whether to submit jobs to this cluster
submit_to=True
# Resource Manager logical name (required for HA)
## logical_name=
# Change this if your YARN cluster is Kerberos-secured
## security_enabled=false
# URL of the ResourceManager API
resourcemanager_api_url=http://hd.m1:8088
# URL of the ProxyServer API
proxy_api_url=http://hd.m1:8088
# URL of the HistoryServer API
history_server_api_url=http://hd.m1:19888
# URL of the Spark History Server
spark_history_server_url=http://hd.m1:18088
# Change this if your Spark History Server is Kerberos-secured
## spark_history_server_security_enabled=false
# In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True
# HA support by specifying multiple clusters.
# Redefine different properties there.
# e.g.
# [[[ha]]]
# Resource Manager logical name (required for HA)
## logical_name=my-rm-name
# Un-comment to enable
## submit_to=True
# URL of the ResourceManager API
## resourcemanager_api_url=http://localhost:8088
# ...
###########################################################################
# Settings to configure Beeswax with Hive
###########################################################################
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=hd.m1
# Binary thrift port for HiveServer2.
## hive_server_port=10000
# Http thrift port for HiveServer2.
## hive_server_http_port=10001
# Host where LLAP is running
## llap_server_host = localhost
# LLAP binary thrift port
## llap_server_port = 10500
# LLAP HTTP Thrift port
## llap_server_thrift_port = 10501
# Alternatively, use Service Discovery for LLAP (Hive Server Interactive) and/or Hiveserver2, this will override server and thrift port
# Whether to use Service Discovery for LLAP
## hive_discovery_llap = true
# is llap (hive server interactive) running in an HA configuration (more than 1)
# important as the zookeeper structure is different
## hive_discovery_llap_ha = false
# Shortcuts to finding LLAP znode Key
# Non-HA - hiveserver-interactive-site - hive.server2.zookeeper.namespace ex hive2 = /hive2
# HA-NonKerberized - _llap ex app name llap0 = /llap0_llap
# HA-Kerberized - _llap-sasl ex app name llap0 = /llap0_llap-sasl
## hive_discovery_llap_znode = /hiveserver2-hive2
# Whether to use Service Discovery for HiveServer2
## hive_discovery_hs2 = true
# Hiveserver2 is hive-site hive.server2.zookeeper.namespace ex hiveserver2 = /hiverserver2
## hive_discovery_hiveserver2_znode = /hiveserver2
# Applicable only for LLAP HA
# To keep the load on zookeeper to a minimum
# ---- we cache the LLAP activeEndpoint for the cache_timeout period
# ---- we cache the hiveserver2 endpoint for the length of session
# configurations to set the time between zookeeper checks
## cache_timeout = 60
# Host where Hive Metastore Server (HMS) is running.
# If Kerberos security is enabled, the fully-qualified domain name (FQDN) is required.
## hive_metastore_host=localhost
# Configure the port the Hive Metastore Server runs on.
## hive_metastore_port=9083
# Hive configuration directory, where hive-site.xml is located
## hive_conf_dir=/etc/hive/conf
# Timeout in seconds for thrift calls to Hive service
server_conn_timeout=120
# Choose whether to use the old GetLog() thrift call from before Hive 0.14 to retrieve the logs.
# If false, use the FetchResults() thrift call from Hive 1.0 or more instead.
## use_get_log_api=false
# Limit the number of partitions that can be listed.
## list_partitions_limit=10000
# The maximum number of partitions that will be included in the SELECT * LIMIT sample query for partitioned tables.
## query_partitions_limit=10
# A limit to the number of rows that can be downloaded from a query before it is truncated.
# A value of -1 means there will be no limit.
## download_row_limit=100000
# A limit to the number of bytes that can be downloaded from a query before it is truncated.
# A value of -1 means there will be no limit.
## download_bytes_limit=-1
# Hue will try to close the Hive query when the user leaves the editor page.
# This will free all the query resources in HiveServer2, but also make its results inaccessible.
## close_queries=false
# Hue will use at most this many HiveServer2 sessions per user at a time.
# For Tez, increase the number to more if you need more than one query at the time, e.g. 2 or 3 (Tez has a maximum of 1 query by session).
# -1 is unlimited number of sessions.
## max_number_of_sessions=1
# When set to True, Hue will close sessions created for background queries and open new ones as needed.
# When set to False, Hue will keep sessions created for background queries opened and reuse them as needed.
# This flag is useful when max_number_of_sessions != 1
## close_sessions=max_number_of_sessions != 1
# Thrift version to use when communicating with HiveServer2.
# Version 11 comes with Hive 3.0. If issues, try 7.
thrift_version=7
# A comma-separated list of white-listed Hive configuration properties that users are authorized to set.
## config_whitelist=hive.map.aggr,hive.exec.compress.output,hive.exec.parallel,hive.execution.engine,mapreduce.job.queuename
# Override the default desktop username and password of the hue user used for authentications with other services.
# e.g. Used for LDAP/PAM pass-through authentication.
## auth_username=hue
## auth_password=
# Use SASL framework to establish connection to host.
## use_sasl=false
[[ssl]]
# Path to Certificate Authority certificates.
## cacerts=/etc/hue/cacerts.pem
# Choose whether Hue should validate certificates received from the server.
## validate=true
###########################################################################
# Settings to configure Metastore
###########################################################################
[metastore]
# Flag to turn on the new version of the create table wizard.
## enable_new_create_table=true
# Flag to force all metadata calls (e.g. list tables, table or column details...) to happen via HiveServer2 if available instead of Impala.
## force_hs2_metadata=false
# Choose whether to show the table ERD component. Default false
## show_table_erd=false
###########################################################################
# Settings to configure Impala
###########################################################################
[impala]
# Host of the Impala Server (one of the Impalad)
## server_host=localhost
# Port of the Impala Server
## server_port=21050
# Endpoint of the Impala Proxy Server, for example: '/endpoint'.
# Note that SERVER_PORT will be used when set.
## proxy_endpoint=
# URL of the Impala Coordinator Server.
## coordinator_url=localhost:25000
# Kerberos principal
## impala_principal=impala/hostname.foo.com
# Turn on/off impersonation mechanism when talking to Impala
## impersonation_enabled=False
# Number of initial rows of a result set to ask Impala to cache in order
# to support re-fetching them for downloading them.
# Set to 0 for disabling the option and backward compatibility.
## querycache_rows=50000
# Timeout in seconds for thrift calls
## server_conn_timeout=120
# Hue will try to close the Impala query when the user leaves the editor page.
# This will free all the query resources in Impala, but also make its results inaccessible.
## close_queries=true
# If > 0, the query will be timed out (i.e. cancelled) if Impala does not do any work
# (compute or send back results) for that query within QUERY_TIMEOUT_S seconds.
## query_timeout_s=300
# If > 0, the session will be timed out (i.e. cancelled) if Impala does not do any work
# (compute or send back results) for that session within SESSION_TIMEOUT_S seconds (default 15 min).
## session_timeout_s=900
# Override the desktop default username and password of the hue user used for authentications with other services.
# e.g. Used for LDAP/PAM pass-through authentication.
## auth_username=hue
## auth_password=
# Username and password for Impala Daemon Web interface for getting Impala queries in JobBrowser
## daemon_api_username=
## daemon_api_password=
# Execute this script to produce the password to avoid entering in clear text
## daemon_api_password_script=
# Set to 'digest' when webserver_htpassword_user and webserver_htpassword_password are set for Impala, or set to
# 'basic' if webserver_require_ldap is set
## daemon_api_auth_scheme=digest
# A comma-separated list of white-listed Impala configuration properties that users are authorized to set.
# config_whitelist=debug_action,explain_level,mem_limit,optimize_partition_key_scans,query_timeout_s,request_pool
# Path to the impala configuration dir which has impalad_flags file
## impala_conf_dir=${HUE_CONF_DIR}/impala-conf
# Use SASL framework to establish connection to host.
## use_sasl=true
# Use Thrift over HTTP for the transport mode.
## use_thrift_http=false
[[ssl]]
# SSL communication enabled for this server.
## enabled=false
# Path to Certificate Authority certificates.
## cacerts=/etc/hue/cacerts.pem
# Choose whether Hue should validate certificates received from the server.
## validate=true
###########################################################################
# Settings to configure the Spark application.
###########################################################################
[spark]
# The Livy Server URL.
## livy_server_url=http://localhost:8998
# Whether Livy requires client to perform Kerberos authentication.
## security_enabled=false
# Whether Livy requires client to use csrf protection.
## csrf_enabled=false
# Host of the Spark Thrift Server
# https://spark.apache.org/docs/latest/sql-distributed-sql-engine.html
## sql_server_host=localhost
# Port of the Spark Thrift Server
## sql_server_port=10000
# Choose whether Hue should validate certificates received from the server.
## ssl_cert_ca_verify=true
# Use SASL framework to establish connection to host.
## use_sasl=false
###########################################################################
# Settings to configure the Oozie app
###########################################################################
[oozie]
# Location on local FS where the examples are stored.
## local_data_dir=..../examples
# Location on local FS where the data for the examples is stored.
## sample_data_dir=...thirdparty/sample_data
# Location on HDFS where the oozie examples and workflows are stored.
# Parameters are $TIME and $USER, e.g. /user/$USER/hue/workspaces/workflow-$TIME
## remote_data_dir=/user/hue/oozie/workspaces
# Maximum of Oozie workflows or coodinators to retrieve in one API call.
## oozie_jobs_count=100
# Use Cron format for defining the frequency of a Coordinator instead of the old frequency number/unit.
## enable_cron_scheduling=true
# Flag to enable the saved Editor queries to be dragged and dropped into a workflow.
## enable_document_action=true
# Flag to enable Oozie backend filtering instead of doing it at the page level in Javascript. Requires Oozie 4.3+.
## enable_oozie_backend_filtering=true
# Flag to enable the Impala action.
## enable_impala_action=false
# Flag to enable the Altus action.
## enable_altus_action=false
###########################################################################
# Settings to configure the Filebrowser app
###########################################################################
[filebrowser]
# Location on local filesystem where the uploaded archives are temporary stored.
## archive_upload_tempdir=/tmp
# Show Download Button for HDFS file browser.
## show_download_button=true
# Show Upload Button for HDFS file browser.
## show_upload_button=true
# Flag to enable the extraction of a uploaded archive in HDFS.
## enable_extract_uploaded_archive=true
# Redirect client to WebHdfs or S3 for file download. Note: Turning this on will override notebook/redirect_whitelist for user selected file downloads on WebHdfs & S3.
## redirect_download=false
# Optionally set this if you want a different home directory path. e.g. s3a://gethue.
## remote_storage_home=s3a://gethue
###########################################################################
# Settings to configure Pig
###########################################################################
[pig]
# Path to directory with piggybank.jar on local filesystem.
## local_sample_dir=/usr/share/hue/apps/pig/examples
# Location piggybank.jar will be copied to in HDFS.
## remote_data_dir=/user/hue/pig/examples
###########################################################################
# Settings to configure Sqoop2
###########################################################################
[sqoop]
# If the Sqoop2 app is enabled. Sqoop2 project is deprecated. Sqoop1 is recommended.
## is_enabled=false
# Sqoop server URL
## server_url=http://localhost:12000/sqoop
# Path to configuration directory
## sqoop_conf_dir=/etc/sqoop2/conf
# Choose whether Hue should validate certificates received from the server.
## ssl_cert_ca_verify=true
# For autocompletion, fill out the librdbms section.
###########################################################################
# Settings to configure Proxy
###########################################################################
[proxy]
# Comma-separated list of regular expressions,
# which match 'host:port' of requested proxy target.
## whitelist=(localhost|127\.0\.0\.1):(50030|50070|50060|50075)
# Comma-separated list of regular expressions,
# which match any prefix of 'host:port/path' of requested proxy target.
# This does not support matching GET parameters.
## blacklist=
###########################################################################
# Settings to configure HBase Browser
###########################################################################
[hbase]
# Comma-separated list of HBase Thrift servers for clusters in the format of '(name|host:port)'.
# Use full hostname. If hbase.thrift.ssl.enabled in hbase-site is set to true, https will be used otherwise it will use http
# If using Kerberos we assume GSSAPI SASL, not PLAIN.
hbase_clusters=(Cluster|hd.m1:9090)
# HBase configuration directory, where hbase-site.xml is located.
hbase_conf_dir=/home/hadoop/hbase/conf
# Hard limit of rows or columns per row fetched before truncating.
## truncate_limit = 500
# Should come from hbase-site.xml, do not set. 'framed' is used to chunk up responses, used with the nonblocking server in Thrift but is not supported in Hue.
# 'buffered' used to be the default of the HBase Thrift Server. Default is buffered when not set in hbase-site.xml.
thrift_transport=buffered
# Choose whether Hue should validate certificates received from the server.
## ssl_cert_ca_verify=true
###########################################################################
# Settings to configure Solr Search
###########################################################################
[search]
# URL of the Solr Server
## solr_url=http://localhost:8983/solr/
# Requires FQDN in solr_url if enabled
## security_enabled=false
## Query sent when no term is entered
## empty_query=*:*
###########################################################################
# Settings to configure Solr API lib
###########################################################################
[libsolr]
# Choose whether Hue should validate certificates received from the server.
## ssl_cert_ca_verify=true
# Default path to Solr in ZooKeeper.
## solr_zk_path=/solr
###########################################################################
# Settings to configure the Data Import Wizard
###########################################################################
[indexer]
# Filesystem directory containing Solr Morphline indexing libs.
## config_indexer_libs_path=/tmp/smart_indexer_lib
# Filesystem directory containing JDBC libs.
## config_jdbc_libs_path=/user/oozie/libext/jdbc_drivers
# Filesystem directory containing jar libs.
## config_jars_libs_path=/user/oozie/libext/libs
# Flag to turn on the Solr Morphline indexer.
## enable_scalable_indexer=true
# Flag to turn on Sqoop ingest.
## enable_sqoop=true
# Flag to turn on Kafka topic ingest.
## enable_kafka=false
###########################################################################
# Settings to configure Job Designer
###########################################################################
[jobsub]
# Location on local FS where examples and template are stored.
## local_data_dir=..../data
# Location on local FS where sample data is stored
## sample_data_dir=...thirdparty/sample_data
###########################################################################
# Settings to configure Job Browser.
###########################################################################
[jobbrowser]
# Share submitted jobs information with all users. If set to false,
# submitted jobs are visible only to the owner and administrators.
## share_jobs=true
# Whether to disalbe the job kill button for all users in the jobbrowser
## disable_killing_jobs=false
# Offset in bytes where a negative offset will fetch the last N bytes for the given log file (default 1MB).
## log_offset=-1000000
# Maximum number of jobs to fetch and display when pagination is not supported for the type.
## max_job_fetch=500
# Show the version 2 of app which unifies all the past browsers into one.
## enable_v2=true
# Show the Impala query section for listing and showing more troubleshooting information.
## enable_query_browser=true
# Show the Hive section for listing the query history and providing more troubleshooting information.
## enable_hive_query_browser=false
# Show the Queries section for listing Hive/Impala query history and providing more troubleshooting information.
## enable_queries_list=false
# Use the proxy API instead of the ORM to access the query_store.
## use_proxy=true
[[query_store]]
# URL of Query Store API server.
##server_url=http://localhost:8080/
###########################################################################
# Settings to configure Sentry / Security App.
###########################################################################
[security]
# Use Sentry API V1 for Hive.
## hive_v1=true
# Use Sentry API V2 for Hive.
## hive_v2=false
# Use Sentry API V2 for Solr.
## solr_v2=true
###########################################################################
# Settings to configure the Zookeeper application.
###########################################################################
[zookeeper]
[[clusters]]
[[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:2181,localhost:2182,localhost:2183
host_ports=hd.m1:2181,hd.m2:2181,hd.n1:2181,hd.n2:2181,hd.n3:2181
# The URL of the REST contrib service (required for znode browsing).
rest_url=http://hd.m1:9998,hd.m2:9998,hd.n1:9998,hd.n2:9998,hd.n3:9998
# Name of Kerberos principal when using security.
## principal_name=zookeeper
###########################################################################
# Settings for the User Admin application
###########################################################################
[useradmin]
# Default home directory permissions
## home_dir_permissions=0755
# Disable to use umask from hdfs else new user home directory would be created with the permissions from home_dir_permissions
## use_home_dir_permissions=true
# The name of the default user group that users will be a member of
## default_user_group=default
[[password_policy]]
# Set password policy to all users. The default policy requires password to be at least 8 characters long,
# and contain both uppercase and lowercase letters, numbers, and special characters.
## is_enabled=false
## pwd_regex="^(?=.*?[A-Z])(?=(.*[a-z]){1,})(?=(.*[\d]){1,})(?=(.*[\W_]){1,}).{8,}$"
## pwd_hint="The password must be at least 8 characters long, and must contain both uppercase and lowercase letters, at least one number, and at least one special character."
## pwd_error_message="The password must be at least 8 characters long, and must contain both uppercase and lowercase letters, at least one number, and at least one special character."
###########################################################################
# Settings to configure liboozie
###########################################################################
[liboozie]
# The URL where the Oozie service runs on. This is required in order for
# users to submit jobs. Empty value disables the config check.
## oozie_url=http://localhost:11000/oozie
# Requires FQDN in oozie_url if enabled
## security_enabled=false
# Location on HDFS where the workflows/coordinator are deployed when submitted.
## remote_deployement_dir=/user/hue/oozie/deployments
###########################################################################
# Settings for the AWS lib
###########################################################################
[aws]
# Enable the detection of an IAM role providing the credentials automatically. It can take a few seconds.
## has_iam_detection=false
[[aws_accounts]]
# Default AWS account
## [[[default]]]
# AWS credentials
## access_key_id=
## secret_access_key=
## security_token=
# Execute this script to produce the AWS access key ID.
## access_key_id_script=/path/access_key_id.sh
# Execute this script to produce the AWS secret access key.
## secret_access_key_script=/path/secret_access_key.sh
# Allow to use either environment variables or
# EC2 InstanceProfile to retrieve AWS credentials.
## allow_environment_credentials=yes
# AWS region to use, if no region is specified, will attempt to connect to standard s3.amazonaws.com endpoint
## region=us-east-1
# Endpoint overrides
## host=
# Proxy address and port
## proxy_address=
## proxy_port=8080
## proxy_user=
## proxy_pass=
# Secure connections are the default, but this can be explicitly overridden:
## is_secure=true
# The default calling format uses https://.s3.amazonaws.com but
# this may not make sense if DNS is not configured in this way for custom endpoints.
# e.g. Use boto.s3.connection.OrdinaryCallingFormat for https://s3.amazonaws.com/
## calling_format=boto.s3.connection.OrdinaryCallingFormat
# The time in seconds before a delegate key is expired. Used when filebrowser/redirect_download is used. Default to 4 Hours.
## key_expiry=14400
###########################################################################
# Settings for the Azure lib
###########################################################################
[azure]
[[azure_accounts]]
# Default Azure account
[[[default]]]
# Azure credentials
## client_id=
# Execute this script to produce the ADLS client id.
## client_id_script=/path/client_id.sh
## client_secret=
# Execute this script to produce the ADLS client secret.
## client_secret_script=/path/client_secret.sh
## tenant_id=
# Execute this script to produce the ADLS tenant id.
## tenant_id_script=/path/tenant_id.sh
[[adls_clusters]]
# Default ADLS cluster
[[[default]]]
## fs_defaultfs=adl://.azuredatalakestore.net
## webhdfs_url=https://.azuredatalakestore.net/webhdfs/v1
[[abfs_clusters]]
# Default ABFS cluster
[[[default]]]
## fs_defaultfs=abfss://@.dfs.core.windows.net
## webhdfs_url=https://@.dfs.core.windows.net
###########################################################################
# Settings for the Sentry lib
###########################################################################
[libsentry]
# Hostname or IP of server.
## hostname=localhost
# Port the sentry service is running on.
## port=8038
# Sentry configuration directory, where sentry-site.xml is located.
## sentry_conf_dir=/etc/sentry/conf
# Number of seconds when the privilege list of a user is cached.
## privilege_checker_caching=300
###########################################################################
# Settings to configure the ZooKeeper Lib
###########################################################################
[libzookeeper]
# ZooKeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:2181,localhost:2182,localhost:2183
## ensemble=localhost:2181
# Name of Kerberos principal when using security.
## principal_name=zookeeper
###########################################################################
# Settings for the RDBMS application
###########################################################################
[librdbms]
# The RDBMS app can have any number of databases configured in the databases
# section. A database is known by its section name
# (IE sqlite, mysql, psql, and oracle in the list below).
[[databases]]
# sqlite configuration.
## [[[sqlite]]]
# Name to show in the UI.
## nice_name=SQLite
# For SQLite, name defines the path to the database.
## name=/tmp/sqlite.db
# Database backend to use.
## engine=sqlite
# Database options to send to the server when connecting.
# https://docs.djangoproject.com/en/1.4/ref/databases/
## options={}
# mysql, oracle, or postgresql configuration.
[[[mysql]]]
# Name to show in the UI.
nice_name="My SQL DB"
# For MySQL and PostgreSQL, name is the name of the database.
# For Oracle, Name is instance of the Oracle server. For express edition
# this is 'xe' by default.
name=hue
# Database backend to use. This can be:
# 1. mysql
# 2. postgresql
# 3. oracle
engine=mysql
# IP or hostname of the database to connect to.
host=127.0.0.1
# Port the database server is listening to. Defaults are:
# 1. MySQL: 3306
# 2. PostgreSQL: 5432
# 3. Oracle Express Edition: 1521
port=3306
# Username to authenticate with when connecting to the database.
user=root
# Password matching the username to authenticate with when
# connecting to the database.
password=*********
# Database options to send to the server when connecting.
# https://docs.djangoproject.com/en/1.4/ref/databases/
## options={}
###########################################################################
# Settings to configure SAML
###########################################################################
[libsaml]
# Xmlsec1 binary path. This program should be executable by the user running Hue.
## xmlsec_binary=/usr/local/bin/xmlsec1
# Entity ID for Hue acting as service provider.
# Can also accept a pattern where '' will be replaced with server URL base.
## entity_id="/saml2/metadata/"
# Create users from SSO on login.
## create_users_on_login=true
# Required attributes to ask for from IdP.
# This requires a comma separated list.
## required_attributes=uid
# Optional attributes to ask for from IdP.
# This requires a comma separated list.
## optional_attributes=
# IdP metadata in the form of a file. This is generally an XML file containing metadata that the Identity Provider generates.
## metadata_file=
# Private key to encrypt metadata with.
## key_file=
# Signed certificate to send along with encrypted metadata.
## cert_file=
# If your computer and another computer that you are communicating with are not in synch regarding the computer clock, then here you can state how big a difference you are prepared to accept in milliseconds.
## accepted_time_diff=0
# Path to a file containing the password private key.
## key_file_password=/path/key
# Execute this script to produce the private key password. This will be used when 'key_file_password' is not set.
## key_file_password_script=/path/pwd.sh
# A mapping from attributes in the response from the IdP to django user attributes.
## user_attribute_mapping={'uid': ('username', )}
# Have Hue initiated authn requests be signed and provide a certificate.
## authn_requests_signed=false
# Have Hue initiated authn response be signed.
## want_response_signed=false
# Have Hue initiated authn assertions response be signed.
## want_assertions_signed=false
# Have Hue initiated logout requests be signed and provide a certificate.
## logout_requests_signed=false
# Username can be sourced from 'attributes' or 'nameid'.
## username_source=attributes
# Performs the logout or not.
## logout_enabled=true
# Comma separated list of group names which are all required to complete the authentication. e.g. admin,sales.
## required_groups=
# Name of the SAML attribute containing the list of groups the user belongs to.
## required_groups_attribute=groups
###########################################################################
# Settings to configure OAuth
###########################################################################
[liboauth]
# NOTE:
# To work, each of the active (i.e. uncommented) service must have
# applications created on the social network.
# Then the "consumer key" and "consumer secret" must be provided here.
#
# The addresses where to do so are:
# Twitter: https://dev.twitter.com/apps
# Google+ : https://cloud.google.com/
# Facebook: https://developers.facebook.com/apps
# Linkedin: https://www.linkedin.com/secure/developer
#
# Additionnaly, the following must be set in the application settings:
# Twitter: Callback URL (aka Redirect URL) must be set to http://YOUR_HUE_IP_OR_DOMAIN_NAME/oauth/social_login/oauth_authenticated
# Google+ : CONSENT SCREEN must have email address
# Facebook: Sandbox Mode must be DISABLED
# Linkedin: "In OAuth User Agreement", r_emailaddress is REQUIRED
# The Consumer key of the application
## consumer_key_twitter=
## consumer_key_google=
## consumer_key_facebook=
## consumer_key_linkedin=
# The Consumer secret of the application
## consumer_secret_twitter=
## consumer_secret_google=
## consumer_secret_facebook=
## consumer_secret_linkedin=
# The Request token URL
## request_token_url_twitter=https://api.twitter.com/oauth/request_token
## request_token_url_google=https://accounts.google.com/o/oauth2/auth
## request_token_url_linkedin=https://www.linkedin.com/uas/oauth2/authorization
## request_token_url_facebook=https://graph.facebook.com/oauth/authorize
# The Access token URL
## access_token_url_twitter=https://api.twitter.com/oauth/access_token
## access_token_url_google=https://accounts.google.com/o/oauth2/token
## access_token_url_facebook=https://graph.facebook.com/oauth/access_token
## access_token_url_linkedin=https://api.linkedin.com/uas/oauth2/accessToken
# The Authenticate URL
## authenticate_url_twitter=https://api.twitter.com/oauth/authorize
## authenticate_url_google=https://www.googleapis.com/oauth2/v1/userinfo?access_token=
## authenticate_url_facebook=https://graph.facebook.com/me?access_token=
## authenticate_url_linkedin=https://api.linkedin.com/v1/people/~:(email-address)?format=json&oauth2_access_token=
# Username Map. Json Hash format.
# Replaces username parts in order to simplify usernames obtained
# Example: {"@sub1.domain.com":"_S1", "@sub2.domain.com":"_S2"}
# converts '[email protected]' to 'email_S1'
## username_map={}
# Whitelisted domains (only applies to Google OAuth). CSV format.
## whitelisted_domains_google=
###########################################################################
# Settings to configure Kafka
###########################################################################
[kafka]
[[kafka]]
# Enable the Kafka integration.
is_enabled=true
# Base URL of Kafka Ksql API.
ksql_api_url=http://hd.m1:8088
###########################################################################
# Settings to configure Metadata
###########################################################################
[metadata]
[[manager]]
# Cloudera Manager API URL (without version suffix).
## api_url=http://localhost:7180/api
[[optimizer]]
# Mode of optimization: off, local, api.
## mode=off
# Type of Optimizer connector to use, e.g. optimizer, navopt, dummy.
## interface=navopt
# Hostname of Optimizer API service.
## hostname=navoptapi.us-west-1.optimizer.altus.cloudera.com
# The name of the key of the service.
## auth_key_id=e0819f3a-1e6f-4904-be69-5b704bacd1245
# The private part of the key associated with the auth_key.
## auth_key_secret='-----BEGIN PRIVATE KEY....'
# Execute this script to produce the auth_key secret. This will be used when `auth_key_secret` is not set.
## auth_key_secret_script=/path/to/script.sh
# The name of the workload where queries are uploaded and optimizations are calculated from. Automatically guessed from auth_key and cluster_id if not specified.
## tenant_id=
# Perform Sentry privilege filtering.
# Default to true automatically if the cluster is secure.
## apply_sentry_permissions=False
# Cache timeout in milliseconds for the Optimizer metadata used in assist, autocomplete, etc.
# Defaults to 10 days, set to 0 to disable caching.
## cacheable_ttl=864000000
# Automatically upload queries after their execution in order to improve recommendations.
## auto_upload_queries=true
# Automatically upload queried tables DDL in order to improve recommendations.
## auto_upload_ddl=true
# Automatically upload queried tables and columns stats in order to improve recommendations.
## auto_upload_stats=false
# Allow admins to upload the last N executed queries in the quick start wizard. Use 0 to disable.
## query_history_upload_limit=10000
[[catalog]]
# The type of Catalog: Apache Atlas, Cloudera Navigator...
## interface=atlas
# Catalog API URL (without version suffix).
## api_url=http://localhost:21000/atlas/v2
# Username of the CM user used for authentication.
## server_user=hue
# Password of the user used for authentication.
## server_password=
# Limits found entities to a specific cluster. When empty the entities from all clusters will be included in the
# search results.
## search_cluster=
# Set to true when authenticating via kerberos instead of username/password
## kerberos_enabled=core_site.is_kerberos_enabled()
# Directory of the configurations.
## conf_dir=HUE_CONF_DIR/hive-conf
# Deprecated by [[catalog]]
[[navigator]]
# Navigator API URL (without version suffix).
## api_url=http://localhost:7187/api
# Which authentication to use: CM or external via LDAP or SAML.
## navmetadataserver_auth_type=CMDB
# Username of the CM user used for authentication.
## navmetadataserver_cmdb_user=hue
# CM password of the user used for authentication.
## navmetadataserver_cmdb_password=
# Execute this script to produce the CM password. This will be used when the plain password is not set.
# navmetadataserver_cmdb_password_script=
# Username of the LDAP user used for authentication.
## navmetadataserver_ldap_user=hue
# LDAP password of the user used for authentication.
## navmetadataserver_ldap_ppassword=
# Execute this script to produce the LDAP password. This will be used when the plain password is not set.
## navmetadataserver_ldap_password_script=
# Username of the SAML user used for authentication.
## navmetadataserver_saml_user=hue
## SAML password of the user used for authentication.
# navmetadataserver_saml_password=
# Execute this script to produce the SAML password. This will be used when the plain password is not set.
## navmetadataserver_saml_password_script=
# Perform Sentry privilege filtering.
# Default to true automatically if the cluster is secure.
## apply_sentry_permissions=False
# Max number of items to fetch in one call in object search.
## fetch_size_search=450
# Max number of items to fetch in one call in object search autocomplete.
## fetch_size_search_interactive=450
# If metadata search is enabled, also show the search box in the left assist.
## enable_file_search=false
[[prometheus]]
# Configuration options for Prometheus API.
api_url=http://hd.m1:9090/api
安装pyhive,clickhouse
./build/env/bin/pip install pyhive
./build/env/bin/pip install sqlalchemy-clickhouse
可以配置presto 与clickhouse
启动hue:
./build/env/bin/hue runserver
在192.168.1.130:8888 登陆,畅快的体验吧。
中间写的有一些简略,如有疑问或者安装过程中有问题,可以私信或者评论区留言,谢谢。