使用 Apache Hudi、Kafka、Hive 和 Debezium 构建开放数据湖
总览
在接下来的文章中,我们将学习如何使用开源软件 (OSS) 在 AWS 上构建数据湖,包括 Red Hat 的 Debezium、Apache Kafka、Kafka Connect、Apache Hive、Apache Spark、Apache Hudi 和 Hudi DeltaStreamer。 我们将使用完全托管的 AWS 服务来托管数据源、数据湖和开源工具。 这些服务包括 Amazon RDS、MKS、EKS、EMR 和 S3。

工作流程
如上面的架构图所示,这些是演示工作流程中的高级步骤:
- 对数据源(在 Amazon RDS 上运行的 PostgreSQL 数据库)进行更改(插入、更新和删除);
- Kafka Connect Source Connector,利用 Debezium 并在 Amazon EKS (Kubernetes) 上运行,使用 Debezium 从 PostgreSQL WAL 连续读取数据;
- 源连接器以 Avro 格式在 Apicurio Registry 中创建和存储消息架构,同样在 Amazon EKS 上运行;
- Source Connector 将 Apache Avro 格式的数据转换并写入在 Amazon MSK 上运行的 Apache Kafka;
- Kafka Connect Sink Connector,使用 Confluent S3 Sink Connector,使用来自 Apicurio Registry 的模式读取来自 Kafka 主题的消息;
- Sink Connector 以 Apache Avro 格式将数据写入 Amazon S3;
- Apache Spark 使用 Hudi DeltaStreamer 并在 Amazon EMR 上运行,从 Apicurio Registry 读取消息模式;
- DeltaStreamer 从 Amazon S3 读取原始 Avro 格式数据;
- DeltaStreamer 将数据作为写入时复制 (CoW) 和读取时合并 (MoR) 表类型写入 Amazon S3;
- DeltaStreamer 将 Hudi 表和分区同步到在 Amazon EMR 上运行的 Apache Hive;
- 针对 Apache Hive Metastore查询或使用 Apache Spark 直接针对 Hudi 表进行查询,数据从 Amazon S3 中的 Hudi 表返回;
上述工作流实际上包含两个同时运行的独立进程。 步骤 2-6 代表第一个过程,即变更数据捕获 (CDC) 过程。 Kafka Connect 用于不断地将更改从数据库移动到 Amazon S3。 步骤 7-10 代表第二个过程,即数据湖摄取过程。 Hudi 的 DeltaStreamer 从 Amazon S3 读取原始 CDC 数据,并将数据以 Apache Hudi 表格式写回 S3(数据湖)中的另一个位置。 当结合起来时,这些过程可以让我们接近实时的增量数据摄取从数据源到 Hudi 管理的数据湖的变化。
可选
该演示的工作流程只是实现类似结果的众多可能工作流程之一。 替代方案包括:
- 将自行管理的 Kafka Connect 替换为完全托管的 Amazon MSK Connect 服务。
- 将 Amazon EMR 用于 AWS Glue 作业或 AWS Glue Studio 以及用于 Apache Hudi 的自定义 AWS Glue 连接器,以将数据摄取到 Hudi 表中。
- 将 Apache Hive 替换为 AWS Glue 数据目录,这是一种完全托管的 Hive 兼容元存储。
- 将 Apcurio Registry 替换为 Confluent Schema Registry 或 AWS Glue Schema Registry。
- 将 Confluent S3 Sink Connector 更换为 Kafka Connect Sink for Hudi,这可以大大简化工作流程。
- 将 HoodieMultiTableDeltaStreamer 替换为 HoodieDeltaStreamer 实用程序,以快速将多个表引入 Hudi。
- 将 Hudi 的 AvroDFSSource 替换为 AvroKafkaSource 以直接从 Kafka 读取而不是 Amazon S3,或者将 Hudi 的 JdbcSource 替换为直接从 PostgreSQL 数据库读取。 Hudi 有几个可用的数据源阅读器。了解身份验证/授权兼容性/限制。
- 根据您的工作负载要求,选择 Hudi 的写入时复制 (CoW) 和读取时合并 (MoR) 表类型中的一种或两种。
源码
这篇文章和本系列之前的文章的所有源代码都是开源的,位于 GitHub 上。 本文使用的具体资源可在 GitHub 存储库的 debezium_hudi_demo 目录中找到。 还有两份来自 Kaggle 的现代艺术博物馆 (MoMA) 收藏数据集,专门为这篇文章准备,位于 moma_data 目录中。 一份是几乎完整的数据集,另一份是较小的、具有成本效益的开发/测试版本。
https://github.com/garystafford/kafka-connect-msk-demo
Kafka Connect
在此演示中,Kafka Connect 在 Kubernetes 上运行,托管在完全托管的 Amazon Elastic Kubernetes Service (Amazon EKS) 上。 Kafka Connect 运行 Source 和 Sink 连接器。
Source Connector
Kafka Connect 源连接器 source_connector_moma_postgres_kafka.json 用于工作流程的步骤 2-4,它利用 Debezium 持续读取对 Amazon RDS for PostgreSQL 数据库的更改。 PostgreSQL 数据库在两个表中托管 MoMA数据集:艺术家和艺术品。
{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "",
"database.port": "5432",
"database.user": "",
"database.password": "",
"database.dbname": "moma",
"database.server.name": "moma",
"table.include.list": "public.artists,public.artworks",
"plugin.name": "pgoutput",
"key.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"key.converter.apicurio.registry.url": "http://localhost:8080/apis/registry/v2",
"key.converter.apicurio.registry.auto-register": "true",
"key.converter.apicurio.registry.find-latest": "true",
"value.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"value.converter.apicurio.registry.url": "http://localhost:8080/apis/registry/v2",
"value.converter.apicurio.registry.auto-register": "true",
"value.converter.apicurio.registry.find-latest": "true",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.unwrap.delete.handling.mode": "rewrite",
"transforms.unwrap.add.fields": "op,db,table,schema,lsn,source.ts_ms"
} PostgreSQL 的 Debezium 连接器从 PostgreSQL 的预写日志 (WAL) 中读取记录级插入、更新和删除条目。 根据 PostgreSQL 文档,只有在描述更改的日志记录被刷新到永久存储后才能写入对数据文件的更改,因此名称为 write-ahead log。 然后,源连接器创建 Apache Avro 消息架构并将其存储在同样在 Amazon EKS 上运行的 Apicurio Registry 中。
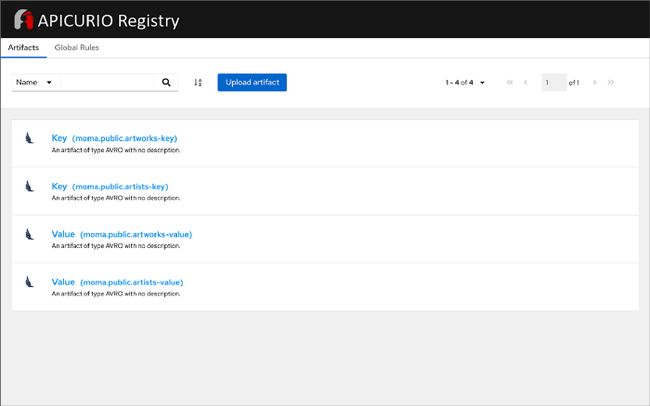

最后,源连接器将 Avro 格式的消息转换并写入在完全托管的 Amazon Managed Streaming for Apache Kafka (Amazon MSK) 上运行的 Apache Kafka。 假设 Kafka 的 topic.creation.enable 属性设置为 true,Kafka Connect 将创建任何必要的 Kafka 主题,每个数据库表一个。
下面,我们看到一个 Kafka 消息的示例,该消息表示在 MoMA数据库的艺术家表中插入一条艺术家 ID 为 1 的记录。 使用 PostgreSQL 的 Debezium 连接器从 PostgreSQL WAL 读取记录、转换并写入相应的 Kafka 主题。 第一个版本代表在被 Debezium 转换之前的原始数据。 请注意,操作类型 (_op) 表示读取 (r)。 可能的值包括 c 代表创建(或插入),u 代表更新,d 代表删除,r 代表读取(适用于快照)。
{
"payload": {
"before": null,
"after": {
"artist_id": 1,
"name": "Robert Arneson",
"nationality": "American",
"gender": "Male",
"birth_year": 1930,
"death_year": 1992
},
"source": {
"version": "1.7.0.Final",
"connector": "postgresql",
"name": "moma",
"ts_ms": 1640703877051,
"snapshot": "true",
"db": "moma",
"sequence": "[null,\"3668170506336\"]",
"schema": "public",
"table": "artists",
"txId": 217094,
"lsn": 3668170506336,
"xmin": null
},
"op": "r",
"ts_ms": 1640703877051,
"transaction": null
}
}下一个版本在 Debezium 使用事件扁平化单消息转换(展开 SMT)转换后表示相同的记录。 最终的消息结构表示存储在 Apicurio Registry 中的模式。 消息结构与接收器连接器写入 Amazon S3 的数据结构相同。
{
"payload": {
"artist_id": 1,
"name": "Robert Arneson",
"nationality": "American",
"gender": "Male",
"birth_year": 1930,
"death_year": 1992,
"__op": "r",
"__db": "moma",
"__table": "artists",
"__schema": "public",
"__lsn": 3668438941792,
"__source_ts_ms": 1640705109121,
"__deleted": "false"
}
}Sink Connector
Kafka Connect Sink 连接器 sink_connector_moma_kafka_s3.json 用于工作流的第 5-6 步,实现了 Confluent S3 Sink 连接器。 Sink 连接器使用存储在 Apicurio Registry 中的模式从 Kafka 读取 Avro 格式的消息。 然后,它基于相同的架构将数据以 Apache Avro 格式写入 Amazon S3。
{
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"tasks.max": 1,
"topics.regex": "moma.public.(.*)",
"table.name.format": "${topic}",
"s3.region": "us-east-1",
"s3.bucket.name": "",
"s3.part.size": 5242880,
"flush.size": 10000,
"rotate.schedule.interval.ms": 60000,
"timezone": "UTC",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"format.class": "io.confluent.connect.s3.format.avro.AvroFormat",
"schema.generator.class": "io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"schema.compatibility": "NONE",
"behavior.on.null.values": "ignore",
"key.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"key.converter.apicurio.registry.url": "http://localhost:8080/apis/registry/v2",
"key.converter.apicurio.registry.auto-register": "true",
"key.converter.apicurio.registry.find-latest": "true",
"value.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"value.converter.apicurio.registry.url": "http://localhost:8080/apis/registry/v2",
"value.converter.apicurio.registry.auto-register": "true",
"value.converter.apicurio.registry.find-latest": "true"
} Running Kafka Connect
我们首先在后台启动 Kafka Connect 作为 CDC 进程。
bin/connect-distributed.sh \
config/connect-distributed.properties \
> /dev/null 2>&1 &
tail -f logs/connect.log然后,使用 Kafka Connect 的 RESTful API 部署 Kafka Connect 源和接收器连接器。 使用 API,我们还可以确认连接器的状态。
curl -s -d @"config/source_connector_moma_postgres_kafka.json" \
-H "Content-Type: application/json" \
-X PUT http://localhost:8083/connectors/source_connector_moma_postgres_kafka/config | jq
curl -s -d @"config/sink_connector_moma_kafka_s3.json" \
-H "Content-Type: application/json" \
-X PUT http://localhost:8083/connectors/sink_connector_moma_kafka_s3/config | jq
curl -s -X GET http://localhost:8083/connectors | jq
curl -s -H "Content-Type: application/json" \
-X GET http://localhost:8083/connectors/source_connector_moma_postgres_kafka/status | jq
curl -s -H "Content-Type: application/json" \
-X GET http://localhost:8083/connectors/sink_connector_moma_kafka_s3/status | jq要确认创建了两个 Kafka 主题 moma.public.artists 和 moma.public.artworks 并包含 Avro 消息,我们可以使用 Kafka 的命令行工具。
# list kafka topics
bin/kafka-topics.sh --list \
--bootstrap-server $BBROKERS \
--command-config config/client-iam.properties
# read first 5 avro-format (binary) messages from topic
bin/kafka-console-consumer.sh \
--topic moma.public.artists \
--from-beginning \
--max-messages 5 \
--property print.value=true \
--property print.offset=true \
--bootstrap-server $BBROKERS \
--consumer.config config/client-iam.propertiesSink 连接器以 10k 条消息的批次或每 60 秒(一分钟间隔)将数据写入 Amazon S3。 这些设置是可配置的,并且高度依赖于您的要求,包括消息量、消息速度、实时分析要求和可用计算资源。

由于我们不会直接在 Amazon S3 中查询此原始 Avro 格式的 CDC 数据,因此无需在 Apache Hive 或 AWS Glue 数据目录(一个完全托管的 Hive 兼容元存储)中对这些数据进行编目。
Apache Hudi
根据概述,Apache Hudi(发音为“hoodie”)是下一代流数据湖平台。 Apache Hudi 为数据湖带来了核心仓库和数据库功能。 Hudi 提供表、事务、高效的 upsert 和删除、高级索引、流式摄取服务、数据集群、压缩优化和并发,同时将数据保持为开源文件格式。
如果没有 Hudi 或等效的开源数据湖表格式,例如 Apache Iceberg 或 Databrick 的 Delta Lake,大多数数据湖只是一堆非托管的平面文件。 Amazon S3 无法原生维护数据的最新视图,这让许多更熟悉 OLTP 风格的数据库或 OLAP 风格的数据仓库的人感到惊讶。
DeltaStreamer
DeltaStreamer,又名 HoodieDeltaStreamer 实用程序(hudi-utilities-bundle 的一部分),用于工作流的第 7-10 步,提供了从分布式文件系统 (DFS) 和 Apache Kafka 等不同来源执行流式摄取数据的方法.
或者,HoodieMultiTableDeltaStreamer 是 HoodieDeltaStreamer 之上的包装器,可将单个 Spark 作业中的多个表摄取到 Hudi 数据集中。目前,它仅支持对要摄取的表进行顺序处理和 Copy on Write 表类型。
我们使用 HoodieDeltaStreamer 写入读取时合并 (MoR) 和写入时复制 (CoW) 表类型,仅用于演示目的。 MoR 表类型是 CoW 表类型的超集,它使用基于列(例如,Apache Parquet)和基于行(例如,Apache Avro)的文件格式的组合来存储数据。更新被记录到增量文件中,然后被压缩以同步或异步生成新版本的列文件。同样,表类型的选择取决于您的要求。

Amazon EMR
在此演示中,我使用了最近发布的 Amazon EMR 版本 6.5.0,并配置了 Apache Spark 3.1.2 和 Apache Hive 3.1.2。 EMR 6.5.0 运行 Scala 版本 2.12.10、Python 3.7.10 和 OpenJDK Corretto-8.312。 我在 GitHub 上包含了用于创建 EMR 集群的 AWS CloudFormation 模板和参数文件。
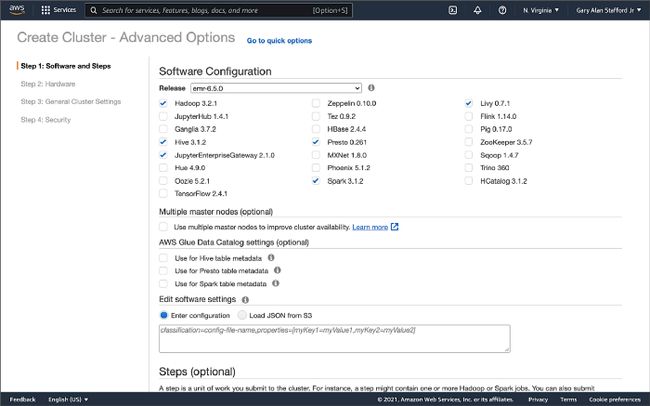
在 EMR 6.5.0 上选择 Apache Spark、Apache Hive 或 Presto 时,会自动安装 Apache Hudi 版本 0.9.0。

DeltaStreamer Configuration
下面,我们看到 DeltaStreamer 属性文件 deltastreamer_artists_apicurio_mor.properties。 此属性文件由运行 DeltaStreamer 的 Spark 作业引用,如下所示。 该文件包含与数据源、数据接收器和 Apache Hive 相关的属性。 DeltaStreamer 的数据源是写入 Amazon S3 的 CDC 数据。 在这种情况下,数据源是位于 /topics/moma.public.artworks/partition=0/ S3 对象前缀中的对象。 数据接收器是 Amazon S3 中的 Hudi MoR 表类型。 DeltaStreamer 会将 Parquet 数据(按艺术家的国籍划分)写入 /moma_mor/artists/ S3 对象前缀。 最后,DeltaStreamer 会将所有表和表分区同步到 Apache Hive,包括创建 Hive 数据库和表(如果它们不存在)。
# Built for demo of Apache Hudi 0.9.0 (EMR 6.5.0) with Apache Hive and SchemaRegistryProvider
include=base.properties
hoodie.datasource.hive_sync.assume_date_partitioning=false
hoodie.datasource.hive_sync.database=moma_mor
hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor
hoodie.datasource.hive_sync.partition_fields=nationality
hoodie.datasource.hive_sync.table=artists
hoodie.datasource.write.drop.partition.columns=true
hoodie.datasource.write.hive_style_partitioning=true
hoodie.datasource.write.partitionpath.field=nationality
hoodie.datasource.write.recordkey.field=artist_id
hoodie.deltastreamer.schemaprovider.registry.url=http:///apis/ccompat/v6/subjects/moma.public.artists-value/versions/latest
hoodie.deltastreamer.source.dfs.root=s3:///topics/moma.public.artists/partition=0/
# 1,024 * 1,024 * 128 = 134,217,728 (128 MB)
hoodie.parquet.small.file.limit=134217728
# https://dacort.dev/posts/updating-partition-values-with-apache-hudi/
# This is required if we want to ensure we upsert a record, even if the partition changes
hoodie.index.type=GLOBAL_BLOOM
# This is required to write the data into the new partition
# defaults to false in Apache Hudi 0.8.0 (EMR 6.4.0), true in Hudi 0.9.0 (EMR 6.5.0)
# hoodie.bloom.index.update.partition.path=true 下面,我们看到了 MoMA 艺术作品的等效 DeltaStreamer 属性文件,deltastreamer_artworks_apicurio_mor.properties。 GitHub 上的 Hudi CoW 表也有类似的 DeltaStreamer 属性文件。
# Built for demo of Apache Hudi 0.9.0 (EMR 6.5.0) with Apache Hive and SchemaRegistryProvider
include=base.properties
hoodie.datasource.hive_sync.assume_date_partitioning=false
hoodie.datasource.hive_sync.database=moma_mor
hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor
hoodie.datasource.hive_sync.partition_fields=classification
hoodie.datasource.hive_sync.table=artworks
hoodie.datasource.write.drop.partition.columns=true
hoodie.datasource.write.hive_style_partitioning=true
hoodie.datasource.write.partitionpath.field=classification
hoodie.datasource.write.recordkey.field=artwork_id
hoodie.deltastreamer.schemaprovider.registry.url=http:///apis/ccompat/v6/subjects/moma.public.artworks-value/versions/latest
hoodie.deltastreamer.source.dfs.root=s3:///topics/moma.public.artworks/partition=0/
# 1,024 * 1,024 * 128 = 134,217,728 (128 MB)
hoodie.parquet.small.file.limit=134217728
# https://dacort.dev/posts/updating-partition-values-with-apache-hudi/
# This is required if we want to ensure we upsert a record, even if the partition changes
hoodie.index.type=GLOBAL_BLOOM
# This is required to write the data into the new partition
# defaults to false in Apache Hudi 0.8.0 (EMR 6.4.0), true in Hudi 0.9.0 (EMR 6.5.0)
# hoodie.bloom.index.update.partition.path=true 所有 DeltaStreamer 属性文件都参考 Apicurio Registry 以获取 Avro 模式的位置。 Kafka Avro 格式消息和 CDC 在 Amazon S3 中创建的 Avro 格式文件都使用这些模式。 由于 DeltaStreamer 与 Confluent Schema Registry 的耦合,相对于其他注册表,我们必须使用 Apicurio Registry 的 Confluent Schema Registry API(版本 6)兼容性 API 端点(例如,/apis/ccompat/v6/subjects/moma.public.artists-value /versions/latest) 将 org.apache.hudi.utilities.schema.SchemaRegistryProvider 数据源选项与 DeltaStreamer 一起使用时。 据 Apicurio 介绍,为了提供与 Confluent SerDes(Serializer/Deserializer)和其他客户端的兼容性,Apicurio Registry 实现了 Confluent Schema Registry 定义的 API。
Running DeltaStreamer
属性文件由调用 DeltaStreamer 库的 Spark 作业使用 spark-submit 加载。 下面,我们看到一个调用 DeltaStreamer 类的示例 Spark 作业。 DeltaStreamer 从 S3 读取原始 Avro 格式的 CDC 数据,并使用 Hudi MoR 表类型将数据写入 /moma_mor/artists/ S3 对象前缀。 在这个 Spark 特定的工作中,我们使用了连续选项。 DeltaStreamer 使用此选项以连续模式运行,在循环中运行 source-fetch、transform 和 write。 我们也在使用 UPSERT 写操作 (op)。 操作选项包括 UPSERT、INSERT 和 BULK_INSERT。 这组选项非常适合将 CDC 数据的持续更改插入到 Hudi 表中。 您可以在 EMR 的主节点上的前台或后台运行作业,或者从 Amazon EMR 控制台作为 EMR 步骤运行。
export DATA_LAKE_BUCKET=""
# artists data, MoR table type, continuous upserts
spark-submit \
--jars /usr/lib/spark/jars/spark-avro.jar,/usr/lib/hudi/hudi-utilities-bundle.jar \
--conf spark.sql.catalogImplementation=hive \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /usr/lib/hudi/hudi-utilities-bundle.jar \
--table-type MERGE_ON_READ \
--source-ordering-field __source_ts_ms \
--props "s3://${DATA_LAKE_BUCKET}/hudi/deltastreamer_artists_apicurio_mor.properties" \
--source-class org.apache.hudi.utilities.sources.AvroDFSSource \
--target-base-path "s3://${DATA_LAKE_BUCKET}/moma/artists_mor/" \
--target-table moma_mor.artists \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--enable-sync \
--continuous \
--op UPSERT 下面,我们看到另一个示例 DeltaStreamer Spark 作业,它从 S3 读取原始 Avro 格式的 CDC 数据,并使用 MoR 表类型将数据写入 /moma_mor/artworks/ S3 对象前缀。 此示例使用 BULK_INSERT 写入操作 (op) 和 filter-dupes 选项。 filter-dupes 选项确保在 INSERT 或 BULK_INSERT 之前删除/过滤掉来自源的重复记录。 这组选项非常适合将现有数据初始批量插入到 Hudi 表中。 该作业运行一次并完成,与前面连续运行的示例不同。
export DATA_LAKE_BUCKET=""
# artworks data, MoR table type, 1x bulk insert
spark-submit \
--jars /usr/lib/spark/jars/spark-avro.jar,/usr/lib/hudi/hudi-utilities-bundle.jar \
--conf spark.sql.catalogImplementation=hive \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /usr/lib/hudi/hudi-utilities-bundle.jar \
--table-type MERGE_ON_READ \
--source-ordering-field __source_ts_ms \
--props "s3://${DATA_LAKE_BUCKET}/hudi/deltastreamer_artworks_apicurio_mor.properties" \
--source-class org.apache.hudi.utilities.sources.AvroDFSSource \
--target-base-path "s3://${DATA_LAKE_BUCKET}/moma/artworks_mor/" \
--target-table moma_mor.artworks \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--enable-sync \
--op BULK_INSERT \
--filter-dupes 同步到Hive
以下纯视频剪辑演示了 Hudi CoW 和 MoR 表类型在 Apache Hive 方面的差异。 在视频中,我们运行 GitHub 上包含的 deltastreamer_jobs_bulk_bkgd.sh 脚本。 该脚本运行四个不同的 Apache Spark 作业,使用 Hudi DeltaStreamer 将来自 Amazon S3 的所有艺术家和艺术品 CDC 数据批量摄取到 Hudi CoW 和 MoR 表类型中。 完成四个 Spark 作业后,脚本会查询 Apache Hive 并显示由 DeltaStreamer 创建的新 Hive 数据库和数据库表。
在上面的视频和下面的终端屏幕截图中,请注意在两个 Hive 数据库中创建的表的差异,即 Hudi CoW 表类型 (moma_cow) 和 MoR 表类型 (moma_mor)。 MoR 表类型为每个数据源(例如,artist_ro 和 Artist_rt)创建一个读取优化表 (_ro) 和一个实时表 (_rt)。
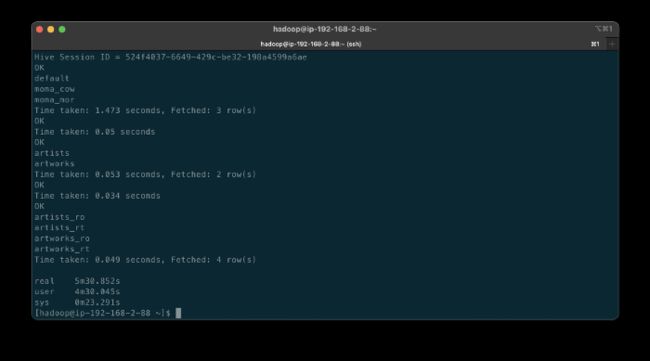
根据文档,Hudi 在 Hive 元存储中为 MoR 表类型创建了两个表。 第一个表是一个带有 _ro 的读取优化视图,第二个是一个带有 _rt 的同名表,它是一个实时视图。 根据 Hudi 的说法,读取优化视图公开了列 Parquet,而实时视图公开了列 Parquet 和/或基于行的日志; 您可以查询两个表。 CoW 表类型为每个数据源(例如艺术家)创建一个没有后缀的表。 下面,我们看到了由 DeltaStreamer 创建的 Artists_rt 表的 Hive 表结构,使用 SHOW CREATE TABLE moma_mor.artists_rt;。
CREATE EXTERNAL TABLE `moma_mor.artists_rt`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`artist_id` int,
`name` string,
`gender` string,
`birth_year` int,
`death_year` int,
`__op` string,
`__db` string,
`__table` string,
`__schema` string,
`__lsn` bigint,
`__source_ts_ms` bigint,
`__deleted` string)
PARTITIONED BY (
`nationality` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'hoodie.query.as.ro.table'='false',
'path'='s3:///moma/artists_mor')
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3:///moma/artists_mor'
TBLPROPERTIES (
'bucketing_version'='2',
'last_commit_time_sync'='20211230180429',
'spark.sql.partitionProvider'='catalog',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numPartCols'='1',
'spark.sql.sources.schema.numParts'='1',
'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"_hoodie_commit_time","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_commit_seqno","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_record_key","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_partition_path","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_file_name","type":"string","nullable":true,"metadata":{}},{"name":"artist_id","type":"integer","nullable":false,"metadata":{}},{"name":"name","type":"string","nullable":true,"metadata":{}},{"name":"gender","type":"string","nullable":true,"metadata":{}},{"name":"birth_year","type":"integer","nullable":true,"metadata":{}},{"name":"death_year","type":"integer","nullable":true,"metadata":{}},{"name":"__op","type":"string","nullable":true,"metadata":{}},{"name":"__db","type":"string","nullable":true,"metadata":{}},{"name":"__table","type":"string","nullable":true,"metadata":{}},{"name":"__schema","type":"string","nullable":true,"metadata":{}},{"name":"__lsn","type":"long","nullable":true,"metadata":{}},{"name":"__source_ts_ms","type":"long","nullable":true,"metadata":{}},{"name":"__deleted","type":"string","nullable":true,"metadata":{}},{"name":"nationality","type":"string","nullable":true,"metadata":{}}]}',
'spark.sql.sources.schema.partCol.0'='nationality',
'transient_lastDdlTime'='1640919578') 运行演示的 deltastreamer_jobs_bulk_bkgd.sh 脚本后,Amazon S3 存储桶的 Hudi 管理部分中生成的对象结构如下所示。

下面是在 /moma/artists_cow/ S3 对象前缀中创建的 Hudi 文件示例。 在使用 Hudi 等数据湖表格式时,鉴于其特殊的目录结构和大量对象,应通过 Hudi 的编程接口抽象与数据的交互。 一般来说,您不会直接与数据湖中的对象进行交互。
"moma/artists_cow/.hoodie/.aux/.bootstrap/.fileids_$folder$",
"moma/artists_cow/.hoodie/.aux/.bootstrap/.partitions_$folder$",
"moma/artists_cow/.hoodie/.aux/.bootstrap_$folder$",
"moma/artists_cow/.hoodie/.aux_$folder$",
"moma/artists_cow/.hoodie/.temp_$folder$",
"moma/artists_cow/.hoodie/20211231203737.commit",
"moma/artists_cow/.hoodie/20211231203737.commit.requested",
"moma/artists_cow/.hoodie/20211231203737.inflight",
"moma/artists_cow/.hoodie/20211231203738.rollback",
"moma/artists_cow/.hoodie/20211231203738.rollback.inflight",
"moma/artists_cow/.hoodie/archived_$folder$",
"moma/artists_cow/.hoodie/hoodie.properties",
"moma/artists_cow/.hoodie_$folder$",
"moma/artists_cow/nationality=Afghan/.hoodie_partition_metadata",
"moma/artists_cow/nationality=Afghan/4f39e019-e3d7-4a6a-a7bd-6d07eddd495a-0_0-28-3352_20211231203737.parquet",
"moma/artists_cow/nationality=Afghan_$folder$",
"moma/artists_cow/nationality=Albanian/.hoodie_partition_metadata",
"moma/artists_cow/nationality=Albanian/4f39e019-e3d7-4a6a-a7bd-6d07eddd495a-1_0-28-3352_20211231203737.parquet",
"moma/artists_cow/nationality=Albanian_$folder$",
"moma/artists_cow/nationality=Algerian/.hoodie_partition_metadata",
"moma/artists_cow/nationality=Algerian/4f39e019-e3d7-4a6a-a7bd-6d07eddd495a-2_0-28-3352_20211231203737.parquet",
"moma/artists_cow/nationality=Algerian_$folder$",
"moma/artists_cow/nationality=American/.hoodie_partition_metadata",
"moma/artists_cow/nationality=American/0065ed77-4a6c-4755-b133-45126310936d-0_502-28-3854_20211231203737.parquet",
"moma/artists_cow/nationality=American/011d5c57-c918-40d8-8518-c3cb56747133-0_15-28-3367_20211231203737.parquet"Hudi CLI
或者,我们可以使用 Hudi CLI (hudi-cli) 检查 Hudi 表。 CLI 提供了广泛的可用命令列表。 使用 CLI,我们可以检查 Hudi 表及其模式,并查看操作统计信息,如写入放大(1 字节传入数据写入的字节数)、提交和压缩。
> hudi-cli
help
connect --path s3:///moma/artworks_mor/
connect --path s3:///moma/artworks_cow/
desc
fetch table schema
commits show
stats wa
compactions show all 以下纯视频短片展示了如何使用在 Amazon EMR 主节点上运行的 Hudi CLI 检查 S3 中的 Hudi 表。
Hudi Data Structure
回想一下我们之前在帖子中看到的示例 Kafka 消息,该消息表示插入了一个艺术家 ID 为 1 的艺术家记录。下面,我们看到了同样的记录在被 Hudi DeltaStreamer 摄取后的样子。 请注意 Hudi 添加的带有 hoodie 前缀的五个附加字段。
{
"_hoodie_commit_time": "20211227215352",
"_hoodie_commit_seqno": "20211227215352_63_7301",
"_hoodie_record_key": "1",
"_hoodie_partition_path": "nationality=American",
"_hoodie_file_name": "0e91bb5b-aa93-42a9-933d-242f5fda1b8f-0_63-24-4710_20211227215352.parquet",
"artist_id": 1,
"name": "Robert Arneson",
"nationality": "American",
"gender": "Male",
"birth_year": 1930,
"death_year": 1992,
"__op": "r",
"__db": "moma",
"__table": "artists",
"__schema": "public",
"__lsn": 3637434647944,
"__source_ts_ms": 1640566580452,
"__deleted": "false"
}Querying Hudi-managed Data
随着初始数据摄取完成并且 CDC 和 DeltaStreamer 进程监控未来的变化,我们可以查询存储在 Hudi 表中的结果数据。 首先,我们将对 PostgreSQL MoMA Collection 数据库进行一些更改,以了解 Hudi 如何管理数据突变。 我们还可以使用 Hive、Spark 或 Presto 直接更改 Hudi 表。 但是,这会导致我们的数据源与 Hudi 表不同步,可能会否定整个 CDC 流程。 在开发数据湖时,这是一个至关重要的考虑因素——如何将更改引入 Hudi 表,尤其是在涉及 CDC 时,以及数据源和数据湖之间的数据连续性是否至关重要。
为了演示,我对 MoMA 数据库中的一件艺术品进行了一系列任意更新,Pablo Picasso 的“Picador (La Pique)”。
-- 'Picador (La Pique)', by Pablo Picasso
SELECT *
FROM artworks
WHERE artwork_id = 128447 AND classification = 'Print';
-- firts update (creation date)
UPDATE artworks
SET date = 1959
WHERE artwork_id = 128447;
-- second update (acquisition date)
UPDATE artworks
SET acquisition_date = '2009-04-15'
WHERE artwork_id = 128447;
-- third update (in vs. '')
UPDATE artworks
SET dimensions = 'composition: 20 13/16 x 25 3/16 in (52.9 x 64 cm); sheet: 24 7/16 x 29 1/2 in (62.1 x 75 cm)'
WHERE artwork_id = 128447;
-- fourth update (acquisition date)
UPDATE artworks
SET acquisition_date = '2009-04-19'
WHERE artwork_id = 128447;下面,请注意 S3 中显示的最后四个对象。 从文件名和日期来看,我们可以看到 CDC 进程使用 Kafka Connect 获取了我对数据库中的记录所做的四次更新。 源连接器首先将更改写入 Kafka。 然后 Sink 连接器读取这些 Kafka 消息并将数据以 Avro 格式写入 Amazon S3,如下所示。

再次查看 S3,我们还可以观察到 DeltaStreamer 在 Amazon S3 中提取了新的 CDC 对象并将它们写入 Hudi CoW 和 MoR 表。 请注意下面显示的文件类型。 鉴于 Hudi 的 MoR 表类型结构,Hudi 首先将更改记录到基于行的增量文件中,然后将它们压缩以生成新版本的列格式 Parquet 文件。

从Apache Hive查询数据
在 S3 中查询 Hudi 管理的数据有多种方法。 在此演示中,它们包括使用命令行中的 hive 客户端对抗 Apache Hive、使用 Spark 对抗 Hive,以及也使用 Spark 对抗 Hudi 表。 我们还可以在 EMR 上安装 Presto 以直接或通过 Hive 查询 Hudi 数据。
每次数据库更改后,查询 Hive 中的实时 artifact_rt 表,可以观察到 Hudi 中的数据反映了更新情况。 请注意,前三个更新的 _hoodie_file_name 字段的值是 Hudi 增量日志文件,而最后一次更新的值是 Parquet 文件。 Parquet 文件表示在进行第四次更新和执行 Hive 查询之间发生了压缩。 最后,请注意操作类型 (_op) 表示所有记录的更新更改 (u)。

一旦所有fours 数据库更新完成并发生压缩,我们应该从所有Hive 表中观察到相同的结果。 下面,请注意所有三个表的 _hoodie_file_name 字段都是 Parquet 文件。 从逻辑上讲,MoR 读取优化表和实时 Hive 表的 Parquet 文件是相同的。
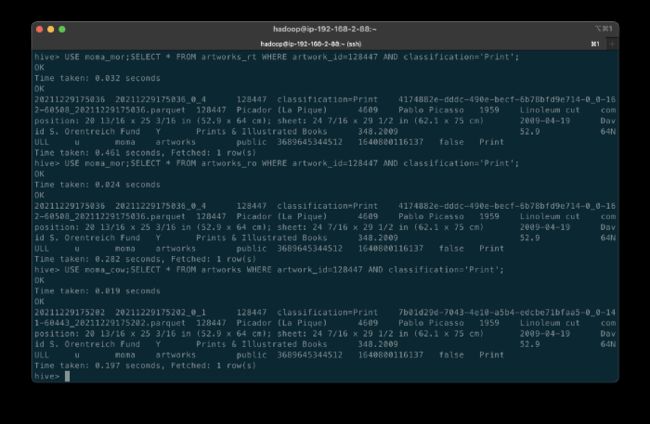
如果我们在压缩之前查询数据,结果会有所不同。 下面我们有三个查询。 我进一步更新了艺术品记录,将日期字段从 1959 年更改为 1960 年。经过读取优化的 MoR 表 artworks_ro 仍然反映了更新之前和压缩之前的原始日期值 1959。 实时表 artworks_rt 反映了日期字段 1960 的最新更新。请注意,读取优化表的 _hoodie_file_name 字段的值是 Parquet 文件,而实时表 (artworks_rt) 的值 ,第三个也是最后一个查询,是一个增量日志文件。 增量日志允许实时表显示 Hudi 中数据的最新状态。

下面是一些有用的 Hive 命令来查询 Hudi 的变化。
-- beeline or hive
-- beeline connect
!connect jdbc:hive2://localhost:10000/default
SHOW DATABASES;
DESCRIBE DATABASE moma_mor;
USE moma_cow;SHOW TABLES;
USE moma_mor;SHOW TABLES;
USE moma_mor;DESCRIBE artworks_ro;
MSCK REPAIR TABLE moma_mor.artworks_ro;
SHOW PARTITIONS moma_mor.artworks_ro;
ANALYZE TABLE moma_mor.artists_rt COMPUTE STATISTICS;
DESCRIBE EXTENDED moma_mor.artists_rt;
-- test query performance without caching
set hive.query.results.cache.enabled=false;
-- 100 rows selected (1.394 seconds) <- read-optimized vs. real-time table
SELECT * FROM moma_mor.artworks_ro WHERE department='Prints & Illustrated Books' LIMIT 100;
-- 100 rows selected (2.371 seconds)
SELECT * FROM moma_mor.artworks_rt WHERE department='Prints & Illustrated Books' LIMIT 100;
-- 10 rows selected (0.719 seconds) <- read-optimized vs. real-time table, classification is partitioned
SELECT * FROM moma_mor.artworks_ro WHERE classification='Print' LIMIT 10;
-- 10 rows selected (1.482 seconds)
SELECT * FROM moma_mor.artworks_rt WHERE classification='Print' LIMIT 10;
EXPLAIN EXTENDED SELECT * FROM moma_mor.artworks_rt WHERE artwork_id=128447 AND classification='Print';
-- 1 row selected (14.126 seconds) <- read-optimized vs. real-time table
SELECT * FROM moma_mor.artworks_ro WHERE artwork_id=128447;
-- 1 row selected (32.877 seconds)
SELECT * FROM moma_mor.artworks_rt WHERE artwork_id=128447;
-- 1 row selected (1.491 seconds) <- classification is partitioned
SELECT * FROM moma_mor.artworks_rt WHERE artwork_id=128447 AND classification='Print';
-- 84 rows selected (8.618 seconds)
SELECT artworks.title AS title,
artworks.`date` AS created,
artworks.name AS artist,
artists.nationality AS nationality,
artworks.classification AS classification
FROM moma_cow.artworks artworks
JOIN moma_cow.artists artists ON (artworks.artist_id = artists.artist_id)
WHERE artworks.artist_id = 4609
AND nationality = 'Spanish'
AND classification = 'Print'
AND artworks.`date` IS NOT NULL
ORDER BY created, title;Deletes with Hudi
除了插入和更新(更新插入),Apache Hudi 还可以管理删除。 Hudi 支持对存储在 Hudi 表中的数据实现两种类型的删除:软删除和硬删除。 鉴于此演示针对 CDC 和 DeltaStreamer 的特定配置,我们将使用软删除。 软删除保留记录键并使其他字段的值无效。 硬删除,一种更强大的删除形式,从 Hudi 表中物理删除任何记录跟踪。
下面,我们看到艺术家 ID 为 441 的艺术家的 CDC 记录。基于 Debezium 的 Kafka Connect 源连接器使用的事件扁平化单消息转换 (SMT) 添加了值为 true 的 __deleted 字段,并使除 记录的密钥,artist_id,这是必需的。
{
"artist_id" : 441,
"name" : null,
"nationality" : null,
"gender" : null,
"birth_year" : null,
"death_year" : null,
"__op" : {
"string" : "d"
},
"__db" : {
"string" : "moma"
},
"__table" : {
"string" : "artists"
},
"__schema" : {
"string" : "public"
},
"__lsn" : {
"long" : 3692866569488
},
"__source_ts_ms" : {
"long" : 1640814436010
},
"__deleted" : {
"string" : "true"
}
}下面,我们在 Hudi MoR 表中看到了 Artist_id 为 441 的艺术家的相同删除记录。 所有空字段已被删除。
{
"_hoodie_commit_time": "20211229225047",
"_hoodie_commit_seqno": "20211229225047_1_1",
"_hoodie_record_key": "441",
"_hoodie_partition_path": "nationality=default",
"_hoodie_file_name": "2a98931a-6015-438e-be78-1eff80a75f83-2_1-24-15431_20211229225047.parquet",
"artist_id": 441,
"__op": "d",
"__db": "moma",
"__table": "artists",
"__schema": "public",
"__lsn": 3692866569488,
"__source_ts_ms": 1640814436010,
"__deleted": "true"
}下面,我们看到删除的记录如何出现在三个 Hive CoW 和 MoR 艺术品表中。 注意读取优化的 MoR 表的查询结果,artworks_ro,包含两条记录——原始记录 (r) 和删除的记录 (d)。 数据按国籍进行分区,由于记录被删除,因此国籍字段变为空。 在 S3 中,Hudi 将此分区表示为 nationality=default。 该记录现在存在于两个不同的 Parquet 文件中,位于两个单独的分区中,在查询读取优化的 MoR 表时需要注意这一点。

Time Travel
根据文档,Hudi 从 0.9.0 版本开始支持时间旅行查询。 通过时间旅行,您可以查询数据的先前状态。 时间旅行对于用例特别有用,包括回滚、调试和审计历史。
为了演示 Hudi 中的时间旅行查询,我们首先对源数据库进行一些额外的更改。 对于这个演示,我进行了一系列五次更新,最后在几个小时内删除了 PostgreSQL 数据库中艺术家 ID 为 299 的艺术家记录。
-- first update (birth)
UPDATE public.artists
SET birth_year = 1907
WHERE artist_id = 299;
-- second update (death)
UPDATE public.artists
SET death_year = 1989
WHERE artist_id = 299;
-- third update (middle initial)
UPDATE public.artists
SET name = 'Gerhard M. Bakker'
WHERE artist_id = 299;
-- fourth update (nationality - impacts partitions)
UPDATE public.artists
SET nationality = 'German'
WHERE artist_id = 299;
-- fifth update (birth)
UPDATE public.artists
SET birth_year = 1905
WHERE artist_id = 299;
-- delete
DELETE
FROM public.artists
WHERE artist_id = 299;
一旦 CDC 和 DeltaStreamer 摄取过程完成,我们可以使用 Hudi 的时间旅行查询能力来查看 Hudi 在不同时间点(瞬间)的数据状态。 为此,我们需要向 Spark 提供一个 as.an.instant 日期/时间值(参见下面的第 21 行)。
根据我进行五次更新和删除的时间段,我选择了在那段时间内我想要检查记录状态的六个瞬间。 下面是来自 Jupyter Notebook 的 PySpark 代码示例,用于对 Hudi MoR 艺术家的表格执行六次时间旅行查询。
from datetime import timedelta
from dateutil import parser
base_path = "s3://open-data-lake-demo-us-east-1/moma/artists_mor"
instances = [ # times in EST
"2021-12-30 08:00:00", # reflects original record (r)
"2021-12-30 09:00:00", # refects updates 1 and 2 (u)
"2021-12-30 09:30:00", # refects updates 3 (u)
"2021-12-30 11:00:00", # refects updates 4 (u)
"2021-12-30 12:30:00", # refects updates 5 (u)
"2021-12-30 14:00:00", # refects delete (d)
]
for instant in instants:
as_of_instant = parser.parse(instant) + timedelta(hours=5) # adjust EST for UTC
print(f"Record state as of: {as_of_instant}")
artistsSnapshotDF = (
spark.read.format("hudi").option("as.of.instant", as_of_instant).load(base_path)
)
artistsSnapshotDF.createOrReplaceTempView("hudi_artists_snapshot")
spark.sql(
"""
SELECT _hoodie_commit_time, __op, _hoodie_partition_path, name, nationality, gender, birth_year, death_year
FROM hudi_artists_snapshot
WHERE artist_id=299;
"""
).show()下面,我们看到时间旅行查询的结果。 在每个瞬间,我们都可以观察到 Hudi MoR Artist 表中数据的变异状态,包括对现有数据快照 (r) 和删除记录 (d) 的初始批量插入。 由于在 PostgreSQL 数据库中进行的删除在 Hudi 中记录为软删除,而不是硬删除,因此我们仍然可以随时检索记录。
Record state as of: 2021-12-30 13:00:00
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
|_hoodie_commit_time|__op|_hoodie_partition_path| name|nationality|gender|birth_year|death_year|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
| 20211230034812| r| nationality=American|Gerhard H. Bakker| American| Male| 1906| 1988|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
Record state as of: 2021-12-30 14:00:00
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
|_hoodie_commit_time|__op|_hoodie_partition_path| name|nationality|gender|birth_year|death_year|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
| 20211230132628| u| nationality=American|Gerhard H. Bakker| American| Male| 1907| 1989|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
Record state as of: 2021-12-30 14:30:00
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
|_hoodie_commit_time|__op|_hoodie_partition_path| name|nationality|gender|birth_year|death_year|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
| 20211230142035| u| nationality=American|Gerhard M. Bakker| American| Male| 1907| 1989|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
Record state as of: 2021-12-30 16:00:00
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
|_hoodie_commit_time|__op|_hoodie_partition_path| name|nationality|gender|birth_year|death_year|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
| 20211230144237| u| nationality=German|Gerhard M. Bakker| German| Male| 1907| 1989|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
Record state as of: 2021-12-30 17:30:00
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
|_hoodie_commit_time|__op|_hoodie_partition_path| name|nationality|gender|birth_year|death_year|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
| 20211230171925| u| nationality=German|Gerhard M. Bakker| German| Male| 1905| 1989|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
Record state as of: 2021-12-30 19:00:00
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
|_hoodie_commit_time|__op|_hoodie_partition_path| name|nationality|gender|birth_year|death_year|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+
| 20211230180429| d| nationality=default| null| null| null| null| null|
+-------------------+----+----------------------+-----------------+-----------+------+----------+----------+除了时间旅行查询,Hudi 还提供增量查询和时间点查询。
结论
虽然这篇文章只触及了 Debezium 和 Hudi 功能的表面,但您可以看到 CDC 使用 Kafka Connect 和 Debezium 以及 Hudi 在 AWS 上构建和管理开放数据湖的强大功能。