Linux 调试进阶(多场景覆盖)
1. 背景
最近在小米项目中分析较多crash问题,结合之前在《程序员的自我修养——链接,状态与库》书中学到的一点皮毛。感触颇深,总结了一些经验,相信对大家分析相关问题有一定的帮助。因为本文的知识点偏于底层,大部分思路都是基于《程序员的自我修养》,对于没有相关知识储备的朋友,可能会有一定难度。不过还是建议过一遍,图一乐呵,万一哪天遇到,能够为您提供解决思路,我也会觉得很欣慰。
本文核心目的是结合常见案例场景进行分析,提供解决思路。因此不再介绍基础,比如gdb 调试方式,coredump 的生成,backtrace 的等。
2. 能量补给站
案例分析前,需要介绍两个知识点,后续的很多思路,都是依靠这两点。
2.1 addr2line
addr2line命令来自英文词组“address to line”的缩写,其功能是将函数地址解析成文件名或行号的工具。给出一个可执行文件中的地址或一个可重定位对象中的偏移部分的地址,使用调试信息来找出与之相关的文件名和行号。【这个地址指的是可执行文件或动态库的代码段地址】
2.2 帧指针和栈指针
我们知道每一个线程都有自己独立的线程栈,而函数调用操作都是基于栈实现的。那么栈的内容包括哪些呢?比如:函数的返回地址,函数入参,局部变量,寄存器值等等。【而这些信息,对于我们分析问题有极大的帮助】。
困难在于如何分析出有用信息,那就需要先了解栈帧结构,可参考下图:
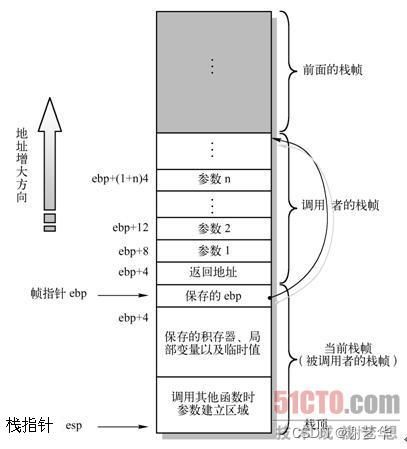
图一
如上图:
栈指针esp: 一直指向线程栈的栈顶。感觉作用不大。
帧指针ebp:函数执行过程中对大部分数据的访问都基于帧指针ebp进行。并且通过ebp 指针的上下文,我们可以清楚的知道函数调用关系。【ebp 保存调用者的 帧指针, ebp+4 保存调用者的返回地址】这句话,会在案例中演示分析。
3. 案例分析
3.1 基于backtrace 的日志分析
3.1.1 设计与实施
在一些程序中,会采用linux 提供的backtrace 和 backtrace_symbols 接口,将对应的堆栈信息打印。大致思路:
1. 在程序初始化时,对一些异常信号的注册,比如SIGSEGV, SIGABRT,SIGPIPE等
2. 当线程触发信号时,会在信号处理函数中,通过backtrace 和 backtrace_symbols 将当前线程的堆栈信息进行打印。
3. 退出当前进程,exit(-1);
如下图所示:

图二
之后通过addr2line 命令即可定位到指定的源码文件以及代码行数。
3.1.2 符号被strip或没有加-g 编译选项
上述的分析方法比较依赖理想的环境,如果存在以下情况,则会不太适用。
可执行文件/动态库被strip 或 编译过程没有增加-g 选项
我们知道linux 设备中磁盘资源有限,宿主机往往会对集成方 SDK的大小做要求。因此,大部分场景下,在量产发行版本中,会对可执行文件以及动态库进行strip, 达到减少SDK大小的目的。若进行了strip,那么backstrace 得到的信息有两种情况:
1. 如图二一致。
2. 没有符号+偏移地址【可能因为glibc版本不同】,仅有程序的虚拟地址。即如下:

图三
对于情景一:
我们的分析思路类似,只不过若文件已经被strip 那么你是无法通过nm 查看符号地址+偏移 得到代码段地址。也无法通过addr2line 从文件中得到代码行数。解决方式:
1. 确定文件的版本号,比如通过 git commit Id。
2. 重现编译程序或动态库。增加 -g 编译选项 且不 strip。
3. 再通过nm查看符号+偏移,得到代码段地址。
4. addr2line 得到代码行数
上述的核心思想:同样的代码,通过增加编译选项-g,是不会改变代码段内容的。【-O优化选项会改变】
因此,大部分SDK 提供方,编译过程中,会生成两份SDK,一份是不加-g编译选项且strip 过的,一份是增加-g 选项,不strip的。
对于情景二:
从日志中我们仅能得到虚拟地址的调用栈,而虚拟地址在可执行程序每一次运行时,可能是不一样的。【可执行程序的代码段对应的虚拟地址应该不会变化。但是动态库的代码段会随着加载地址的不同,发生变化】
因此,我们要做的就是,在这一次的crash中,通过虚拟地址计算出对应的代码段偏移,可以从当前进程的maps中计算。我写了一个简单的示例。main.c, func1.c , func2.c , func3.c。
| main.c |
| func1.c |
| func2.c |
| func3.c |
做如下编译流程:
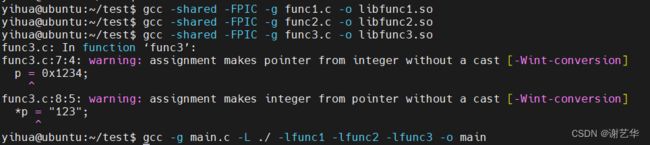
即模拟调用栈main->func1->func2->func3, 且func3 产生crash。分析流程如下:
1. 通过gdb 调试,当出现crash 出现后,我们关注调用栈的虚拟地址。(忽略其它提示信息)
2. 查看程序的进程号,查看maps
3. 通过虚拟地址计算出代码段偏移地址
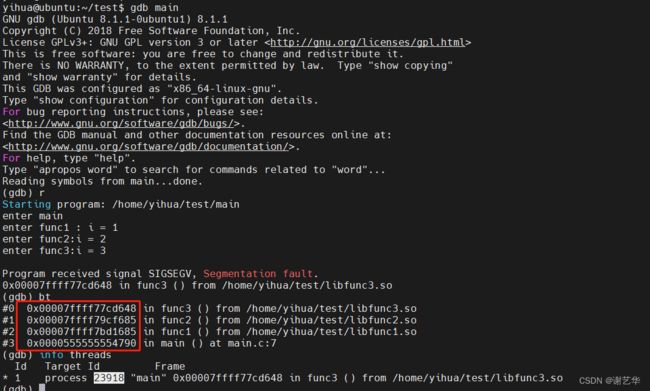
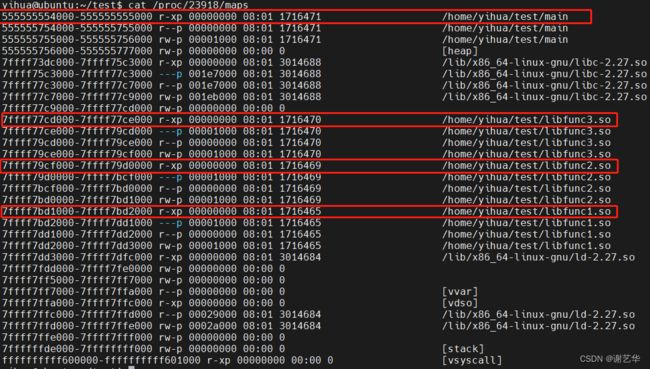
计算过程:
1. 从调用栈中,我们知道虚拟地址的调用顺序分别为:0x0000555555554790 > 0x00007ffff7bd1685 > 0x00007ffff79cf685 > 0x00007ffff77cd648
2. 从maps 中可以看到,这些虚拟地址分别映射在main,libfunc1.so,libfunc2.so ,libfunc3.so的代码段中。因此通过计算,既可得到对应的代码段的偏移。如下:
| 0x0000555555554790 - 0x555555554000 = 0x790 |

3.1.3 总结
因此,为了兼容更多的场景,backtrace一般会和maps 一起使用。所以信号处理函数的实现如下:
| static void backtrace_signal_handler(int32_t signal) |
3.2 基于Coredump的日志分析
Coredump叫做核心转储,它是进程运行时在突然崩溃的那一刻的一个内存快照。操作系统在程序发生异常而异常在进程内部又没有被捕获的情况下,会把进程此刻内存、寄存器状态、运行堆栈等信息转储保存在一个文件里。【理论上基于coredump ,你可以得到进程中任何一个变量的值,以及预测程序的运行状态】
正常情况下,通过Coredump 可以定位到大部分问题。但是有些情况下,也会遇到头疼的问题。常见的如下:
1. 变量被优化或没有-g 编译选项,导致无法查看变量内容
2. 栈被破坏,无法查看调用栈
3.2.1 变量被优化或没有-g 编译选项,导致无法查看变量内容
编译流程如下:
环境复现:
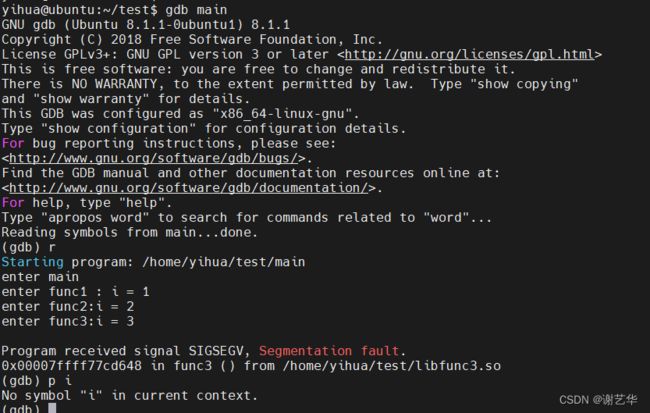
如图所示,当通过gdb 查看到 crash 点在 func3 内部中时,我们若想知道传入参数i的值,通过 gdb 是无法进行打印的。(忽略程序中的printf打印),因为libfunc3.so 编译时,没有增加-g 选项。
若这个异常很难复现,我们该如何进一步分析呢?
分析:
1. 通过汇编语言进行解析,分析入参的传递过程
2. 确定入参的地址
3. 进行打印
通过objdump -d libfunc3.so > symbol3 ,objdump -d libfunc2.so > symbol2对libfunc3.so 和libfunc2.so进行反汇编。如图所示:
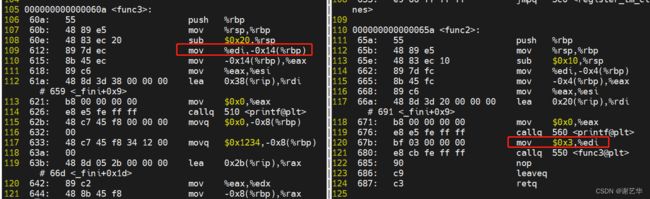
由此可知,func2调用func3时,先将入参保存至 %edi 寄存器中,而func3 内部将 edi 寄存器的值保存至 (%rbp-0x14)的地址。因此,我们仅需要查看该内存地址的值即可。

由此可知当前的值传入的值为3。
3.2.2 栈被破坏,无法查看调用栈
这种情况比较特殊,因为堆栈被破坏了。导致无法直接查看有用的信息。如图:

这种情况一般是因为你的线程栈被越界访问,导致函数的返回地址被破坏。堆栈信息打印不出来。可参考这篇博客,较为详细的描述了堆栈被破坏的原理。https://blog.csdn.net/minghe_uestc/article/details/7977997
遇到该类问题,我一般会将栈顶指针$sp尽可能多的栈空间内容打印。从内容中得到关键内容。【为什么打印$sp指针,而不是$bp指针?,因为栈的顺序是从高地址向低地址增加,而$sp指针作为栈顶指针,肯定是线程栈内的最低地址,而程序访问,赋值的操作是向上增加,因此$sp指针大部分情况不会被破坏,$bp指针,可能会被破坏】
1. 从栈空间中,过滤去特定的数据,从而缩小排查范围。如上面的博客。
2. 从栈空间中,过滤出可能的$bp 指针。从而缩小排查范围。如下图:
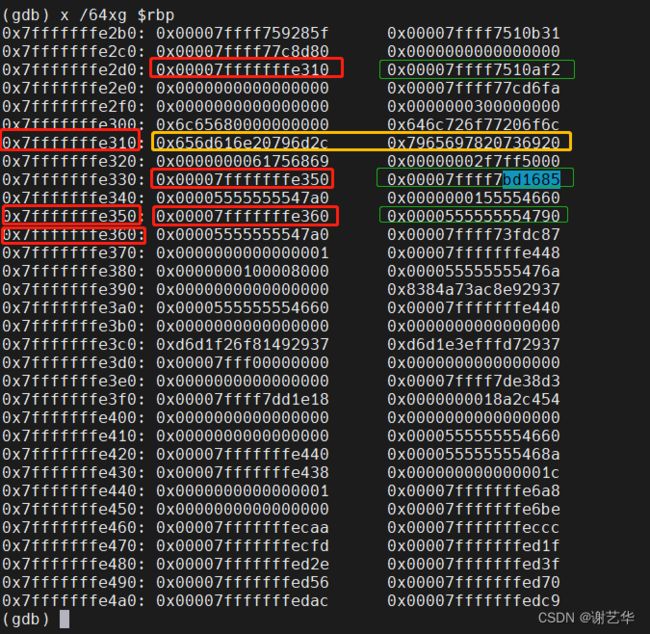
如图所示:
红色框内是栈帧的bp。
黄色框内很明显是错误的old bp 以及错误的函数返回地址。通过打印,可以知道是被字符串覆盖了。

绿色框内,则是函数的返回地址。之后通过maps进行计算,则可以定位到接口。
总结
crash 问题是我们linux 开发无法避免的一个难题。很多时候,异常出现后,因为无法获取更多的分析信息。我们需要花费大量的人力去测试复现。
因此在第一现场,利用仅有的资源分析出更多的有用信息,就显得十分重要。希望本篇能够给相关同事,提供分析思路。