Oracle
Oracle
1、创建表空间
create tablespace spaceName"表空间名称"
datafile 'C:\文件名'"表空间所对应的文件保存路径,包括文件名"
size 100m '指定文件默认大小,如:100m'
autoextend on :"该值为自动扩展,如果说size值满了,则扩充容量,扩充多少容量有next决定"
next 10m "每次扩容10兆"
-- 新增数据文件
alter database datafile '[数据文件位置]' size [1024m] autoextend on next [100M] MAXSIZE/unlimited [20480M];
2、创建用户
create user username'用户名'
identified by pwd"用户名密码或者口令"
default tablespace spaceName"每个用户必须归属一个表空间,一个表空间可以建多个用户"
temporary tablespace 【临时表空间】
3、用户授权
grant dba to username"用户名"
grant connect,resource to username;
# 当用户无法插入数据,报错为 --> USERS
grant unlimited tablespace to username;
4、查询表空间
-- 强制删除表空间
drop tablespace CUX including contents and datafiles;
-- 查询用户对应的表空间
select default_tablespace from dba_users where username='Albert';
-- 查询默认表空间所有用户
select a.property_name, a.property_value from database_properties a where a.property_name like '%DEFAULT%';
-- 查询所有用户临时表空间
select username,temporary_tablespace from dba_users;
5、失效对象
# 查询失效对象
select OBJECT_NAME,OWNER FROM dba_objects WHERE status = 'INVALID';
SELECT * FROM dba_invalid_objects;
--编译失效对象
BEGIN
dbms_utility.compile_schema('schema_name', false);
END;
--查询编译报错信息
SELECT * FROM dba_errors WHERE owner = 'schema_name';
6、用户表查询
# 查询当前用户下的所有表名
select table_name from user_tables
# 查询某个用户下存在的所有表的表名
select table_name from all_tables where owner = upper('[用户名]');
7、创建临时表空间
create temporary tablespace 【表空间名称】
tempfile '表空间所对应的文件保存路径,包括文件名'
size 50m
autoextend on
next 50m maxsize 20480m
extent management local;
8、修改表空间
-- 修改默认系统表空间
alter database default tablespace 【表空间名】;
-- 修改用户默认表空间
alter user 【用户名】default tablespace 【表空间名】;
-- 修改用户临时表空间
alter user 【用户名】TEMPORARY TABLESPACE 【临时表空间名】;
安装Oracle
1、在linux中安装一个windows操作系统
2、将oracle安装包直接拖入即可安装
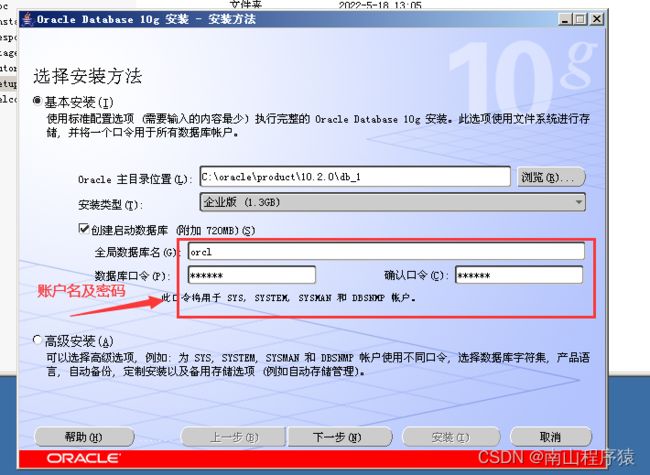
1)安装完成之后,在Linux中安装的Windows操作系统使用终端连接sqlplus
sqlplus system/idcast #sqlplus:指的是操作软件 system:指的是操作用户 idcast:指的是口令
2)将instantclient_12_1配置文件拷贝到某一个目录下,使用docs进入该目录然后远程连接
sqlplus system/idcast@192.168.60.135:1521/rocl
#192.168.60.135:IP指的是Oracle服务器存放的IP地址 1521指的是Oracle的端口号,rocl指的是全局数据库名称
3)安装PLSQL操作界面
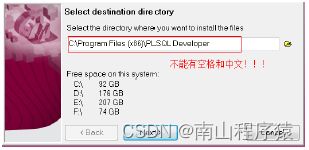
注意:Oracle中不允许有中文或者空格在路径中
4)进入到Oracle操作界面
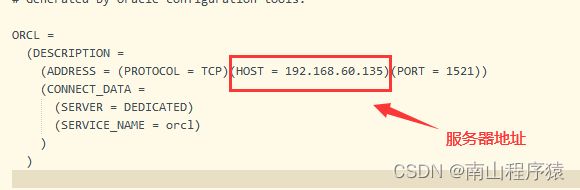
5)在Linux中安装Oracle服务器的文件中找到tnsnames.ora拷贝到本地电脑的任意目录下,使用编辑器打开,修改其中的Oracle服务器地址即可
6)配置环境变量
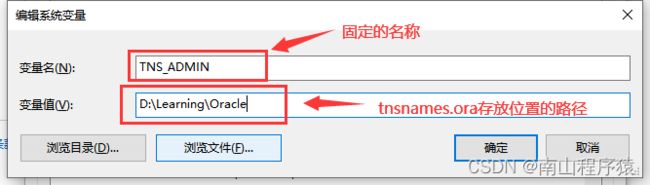
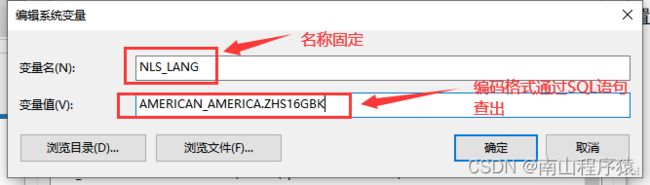
7)修改Oracle图形界面的编码格式,同样需要配置环境变量,目的是:为了输入中文时,与Oracle服务器的编码格式不一致,导致乱码问题
select userenv('language') from dual #查询服务器的编码格式语句
3、用户名和密码
username:orcl pwd:idcast
4、SQL语句
select * from tabs; #查询出数据库中的所有表
quit #退出Oracle终端操作界面
Oracle使用
1、表的增、删、改、查
--创建业主表
create table T_OWNERS(
ID NUMBER PRIMARY KEY,
NAME VARCHAR2(30),
ADDRESSID NUMBER,
HOUSENUMBER VARCHAR2(30),
WATERMETER VARCHAR2(30),
ADDDATE DATE,
OWNERTYPEID NUMBER
);
-- 增加表字段
alter table T_OWNERS ADD (
NETWORKING varchar2(10),
GRADE varchar2(10),
AGE NUMBER
)
-- 修改表字段类型
alter table T_OWNERS modify(
NETWORKING number
)
-- 修改字段名称
alter table T_OWNERS rename column NETWORKING to NETWORKINGs
-- 删除一个字段
alter table T_OWNERS drop column NETWORKINGs
-- 删除多个字段
alter table T_OWNERS drop(NETWORKING,GRADE,AGE)
-- 删除表
DROP TABLE T_OWNERS
-------------------------------------------------------------
-- 插入数据
insert into T_OWNERS values
(1,'张无忌',2,'武当山一号','太极',sysdate,1);
-- 通过commit直接提交,就不用再点击
commit;
-- 修改语句
update T_OWNERS set adddate=adddate-3 where id=1;
commit;
--------------------------------------------------------------
-- 删除表
delete from T_OWNERS where id = 1;
commit;
-- 删除表 truncate table 表名,使用truncate删除语句,直接将整个表删除,然后重建一个空的表空间
truncate table T_OWNERS
2、函数
1、字符控制函数
1、concat;拼串 substr:截取,从第几位开始,截取几个字符 length:判断字符串长度
select concat('hello','world'),substr('helloworld',2,4),length('helloworld') from dual;
2、instr:判断某一个字母在字符串中首次出现的位置,如果没有则输出0,Java中输出-1
select instr('helloworld','l') from dual;
3、lpad:查询哪一个字段,查询多少个字符,不够则使用“*”补上,在左边(lpad),而rpad指右边,俩者都可以使用空格进行补全
select employee_id,last_name,lpad(salary,10,'*') ,rpad(salary,10,' ')from employees;
4、trim:截取字符,但仅限于首尾,位于中间的需要截取的字符不进行截取
select trim('h' from 'helloworlhdh') from dual;
5、replace:替换字符,输入一串字符,输入需要替换的字符,再输入被替换的字符
select replace('abcfdfefg','f','k') from dual;
6、rtrim:去除最右侧空格,ltrim:去除最左侧空格,字符串中间存在空格,当前语法无法去除
select rtrim('dsada ')/ltrim(' dsasd') from dual;
7、LAPD和RAPD(左、右追加)
-- LAPD(String,length,[context]):在左边追加length-string的字符个数值,【context】参数为可选,不写context参数,可以充当截取字符串用
-- RPAD(String,length,[context]):在右边追加,方法和左边追加一样
select lpad('',6,'#') from dual;
select rpad('abcde',5) from dual;
8、initcap:只针对于字符串(字母类型的),用法单一。将一串字母中无论其中是否存在大小写形式,只把第一个字母大写,其余字母全部小写。
select initcap('djiqASDds') from dual;
2、数字函数
# 1、round(1),代表着只保留一位小数,后面如果不写保留几位小数的话,默认是不保留小数,只取整,如果后面填写为负数,舍弃小数,负数为几,则整数位上的数从后往前由0代替,直到满足负数个数之后,剩下的值则为原来的值,如果整数位上的位数不够负数位数,直接取0
select round(123.123,1),round(123.12),round(123.12,-2) from dual;
#2、trunc:称为截取,和round的功能一样
select trunc(123.123,1),trunc(123.12),trunc(126.12,-2) from dual;
#3、mod:称为取余,前一位除以后一位,得到的余数进行输出
select mod(1100,300) from dual;
3、转换函数
############# DATE型==>CHARACTER型 #############
1、to_char:转换成字符型格式,第一个位置输入所需要的日期列名,第二个位置输入想要的格式,然后等于某一个格式
select employee_id,last_name,hire_date from employees where to_char(hire_date,'yyyy-mm-dd')='1994-06-07';
# 注意:to_char函数中的IW、WW区别
1.1 ww的算法为每年1月1日第一周开始,date+6为每一周结尾
# 其中date只是声明单引号中的时间为日期型时间,后转换方式为年+ww的算法
select to_char(date'2022-8-22'+6,'yyyyww')from dual;
1.2、iw的算法为自然周,即星期一到星期五,且每年的第一个星期天为第一周,同样如果去年剩下的几天达不到一周的时间,那么将再今年的日期上添加几天到去年的周期上,然后再开启今年的新的周期年
# 如2022-1-3才是2022年新的一周的开始
select to_char(date'2022-1-3','yyyyiw') from dual;
# 而2022-1-2任然是2021年的第52周的结束
select to_char(date'2022-1-2','yyyyiw') from dual;
############# CHARACTER型==>DATE型 #############
2、to_date:字符型转换成日期型,将第一个位置和等于号后边的位置进行调换即可
select employee_id,last_name,hire_date from employees where to_date('1994-06-07','yyyy-mm-dd')=hire_date;
3、想要输出中文格式的日期,必须在查询列名出声明
select employee_id,last_name,to_char(hire_date,'yyyy"年"mm"月"dd"日"') from employees where to_char(hire_date,'yyyy"年"mm"月"dd"日"')='1994年06月07日';
############# NUMBER型==>CHARACTER型 ###########
4、to_char:number型进行转换,第一个位置输入number型数据,第二个位置输入需要转换成字符型的格式,9:代表一个数字,‘,’:代表分隔符,‘.’:代表小数点,0:代表着零,如果第一位上面不够三位数,则在前面补全,L:代表本地货币符号,$:代表美元符号
select to_char(1213454.43,'999,999,999.99') from dual;
select to_char(1213454.43,'L000,000,000.99') from dual;
5、to_number:char型转换成NUMBER型,首先输入char型字符串,然后输入格式进行转换,还可以进行‘加、减、乘、除’操作
select to_number('$001,213,454.43','L000,000,000.99') from dual;
select to_number('$001,213,454.43','L000,000,000.99')*2 from dual;
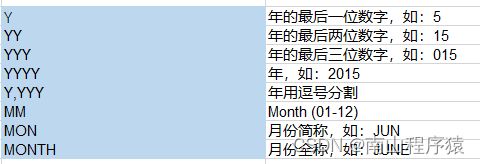
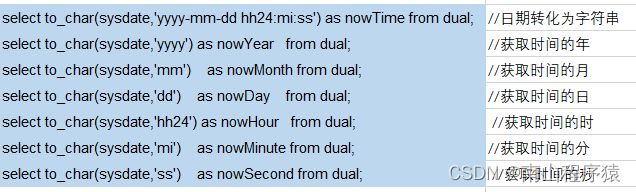
日期相关格式:


4、通用函数
# 1、通用函数nvl(expert1,expert2):代表着当expert1不为空时,则使用expert1,为空时使用expert2代替,也就是当部门ID为空时,使用后面的‘没有部门代替’,如果不为空时,则使用它自己的部门ID即可
select last_name,nvl(to_char(department_id,'99999'),'没有部门') from employees;
#2、nvl2(expr1,expr2,expr3):代表着当expr1不为空时,返回expr2,为空时,返回expr3。相当于commission_pct不为空时,则使用commission_pct+0.015,为空时,则使用,0.015
select last_name,commission_pct,nvl2(commission_pct,commission_pct+0.015,0.015) from employees;
# 3、nullif(expr1,expr2):如果俩个表达式相等(无论表达式中是何种形式,就算是计算、中文还是字母,只要相等就返回 null),返回 null 值。否则返回第一个表达式。
重点:俩个表达式的数据类型要保持一致,不能混着使用,否则报错
注意:expr2 可以放 null 值,expr1 不可以放,否则报错
select nullif(100,100) from dual; -- null
select nullif('sad','sad') from dual; -- null
select nullif('我怕','我怕') from dual; -- null
select nullif('我','我怕') from dual; -- 我
select nullif('我',null) from dual; -- 我
select nullif(12/12,12/12) from dual; -- null
SELECT NULLIF (100, 'A') FROM DUAL; -- 不可以这样
# 4、COALESCE(expr1,expr2.....exprn):当前表达式中只要存在非 null 值,那么就会返回该值,否则就会返回 null 值
重点:数据类型不能混用,但是可以和 null 一起用
SELECT COALESCE('我', NULL, 100) FROM DUAL; -- 错误
SELECT COALESCE('我', NULL, '我') FROM DUAL; -- 我
SELECT COALESCE( NULL,12, NULL,18) FROM DUAL; -- 12
SELECT COALESCE( NULL,NULL) FROM DUAL; -- null
5、条件表达式
# 1、case when then else,当部门为10时,则薪资乘以1.1,当部门为20时,则薪资乘以1.2,接下来即可使用else来代替whe then,因为其剩下最后一个
select employee_id,last_name,department_id,case department_id when 10 then salary * 1.1 when 20 then salary * 1.2 else salary * 1.3 end new_sal from employees where department_id in (10,20,30);
#2、decode:使用其,则可以将整个部门作为条件进行查询,中间使用逗号隔开
select employee_id,last_name,department_id,decode(department_id,10,salary * 1.1,20,salary *1.2,salary) new_sal from employees where department_id in (10,20,30);
6、字符、字节截取、计算函数
-- length查询的是字符长度
select length('广东省珠海市唐家湾镇') as test_length from dual;
-- lengthb查询的是字节长度
select lengthb('广东省珠海市唐家湾镇') as test_length from dual;
-- substrb(string,a,b):其中a、b俩值都是通过字节来计算范围,并不会通过字符来决定范围
select substrb('刘德华abc',-6,3) from dual;
-- substr(string,a,b)
-- 截取字符:当|a| <= b时,取a的个数
-- 当 |a| ≥ b时,才取b的个数,负数:代表着从后往前取
select substr('HelloWorld',-1,3) value from dual;
-- 截取三个字符,从前往后
select substr('HelloWorld',3) value from dual;
7、translate函数
1、整体替换:将第二个参数中的值整体替换为O?
select replace('i love you','oi','O') from dual;
2、一一对应替换,如果替换的目标位置不够,默认替换为空(截断该替换的字符)
select replace('i love you','oeu','*2') from dual;
3、能否做数字格式验证
translate
8、内置函数(least or greatest)
注意:当进行多个值比较时,其中第一个值被确定当前函数优先返回值的类型,然后再进行隐式转换进行比较
# 1、获取列表数据的最小值
select least(17,23,44,56,7) from dual; -->7
# 2、获取列表最大值
select greatest(1,2,8)from dual;
9、日期计算
-
add_months(date,n)–date:指代需要的时间节点,n:指代几个月前或者几个月后(需要数字前面加负号,才能指代月前)
# 函数:计算某一个时间节点距离几个月前或者之后的时间 select * from emp where creation_date>to_date('20190101','yyyymmdd') and creation_date < add_months(to_date('20221011','yyyymmdd'),2) select sysdate,add_months(sysdate,-1*8) from dual; -
last_day函数:计算当前时间的月份最后一天是多少号,并且还可以用于计算当前时间距离最后一天的时间间隔多少天
select last_day(to_date('20220927','yyyyMMdd')),(last_day(sysdate) - sysdate) shen from dual; -
months_between:返回俩日期之间日期差。
重点:计算方式
-
如果俩日期一样
- 先比较年份,年份大的在expr1,就以正数形式返回俩日期之间的差值
- 且年份一样,就比较月份,月份大的在expr1,就以正数形式返回俩日期之间的差值
- 年份一样,且月份也一样,号数大的在expr1,就以正数形式返回俩日期之间的差值
-
如果俩日期不一样
- 先比较年份,年份小的在expr1,就以负数形式返回俩日期之间的差值
-
如果俩日期一摸一样,就返回 0
select months_between(to_date('20190802','yyyyMMdd'),to_date('20190421','yyyyMMdd')) from dual; select months_between(to_date('20190321','yyyyMMdd'),to_date('20190301','yyyyMMdd')) from dual; select months_between(to_date('20190321','yyyyMMdd'),to_date('20190321','yyyyMMdd')) from dual; # 以负数形式返回 <== 过去的时间排在前面 select months_between(to_date('20190201','yyyyMMdd'),to_date('20190301','yyyyMMdd')) from dual;
-
count(*) and count(1);根据分组统计出 group by 中都相同的和不相同的数据分别有多少条
select count(*),emp_name,emp_salary from emp group by emp_name,emp_salary; -
函数幂次方
select power(2,4) from dual; <-- 2的4次方
3、组函数
1、组函数类型:组函数会自动忽略空值,如想要其不忽略空值,使用单行函数中的NVL函数即可
AVG、COUNT、MAX、MIN、STDDEV(样本标准差,可用于聚集和分析函数)、SUM、DISTINCT
-----------------------------------------------
# 1、max\min任何数据类型都可以使用
select max(last_name),min(last_name),max(hire_date),min(hire_date) from employees;
# 2、avg\sum只能针对数值型数据
select avg(last_name),sum(hire_date) from employees
ORA-00932: inconsistent datatypes: expected NUMBER got DATE
# 3、count支持任何数据类型,但是其只支持计算非空的数据,会自动忽略掉空的数据,同样avg和sum一样
select count(employee_id),count(last_name),count(hire_date) from employees;
# 4、avg()函数等于sum()/count函数之和
select avg(salary),sum(salary)/count(salary) from employees;
AVG(SALARY) SUM(SALARY)/COUNT(SALARY)
----------- -------------------------
6461.682242 6461.68224299065
1 row selected
# 5、distinct去重函数,返回非空且不重复的记录总数
SELECT COUNT(DISTINCT(DEPARTMENT_ID)) FROM EMPLOYEES;
2、使用Group By进行分组查询:在使用分组函数查询时,除了包含在组函数的列,其余列都应该包含在GROUP BY 子句中
# 1、求出员工表中各个工种、各个部门的平均工资
select department_id,job_id,avg(salary) from employees group by department_id,job_id
# 2、不能在where子句只用组函数,可以在HAVING子句中使用组函数--->如:求出各个部门平均工资大于6000的部门,及其平均工资
select department_id,avg(salary)
from employees
where avg(salary)>6000
# having avg(salary)>6000
group by department_id
order by avg(salary) asc
ORA-00934: group function is not allowed here
3、分析函数
-- rank():基于排序字段,如出现相同值,其排序值一样(1 1 3),当出现另一个不同值时,就会出现跳跃(不连续)排序
select e.emp_id,e.dept_id,e.emp_name,e.emp_salary,rank() over(order by emp_salary) as ones from emp e
-- dense_rank():基于排序字段,如出现相同值,其排序值是相同的,当出现不同值时,其排序值会顺位而下进行排序,不会出现跳跃式排序
select e.emp_id,e.dept_id,e.emp_name,e.emp_salary,dense_rank() over(order by emp_salary) as ones from emp e
-- row_number():不管排序的值是否存在一样的数据,按顺序一直排(1 2 3 4...)
select e.emp_id,e.dept_id,e.emp_name,e.emp_salary,row_number() over(order by emp_salary) as ones from emp e
-- partition by(排名分区):若选择的排名中存在相同值,那么相同的值进行顺位排序,不同的值则用 1 表示,
-- 注意:partition by的排名分区是基于某一个字段进行排序,把相同的字段值汇总到一起,相同的字段值按照顺位排序,不同的值则用 1 表示
-- rank()
select e.emp_id,e.dept_id,e.emp_name,e.emp_salary,rank() over(partition by dept_id order by emp_salary) as ones from emp e
-- dense_rank()
select e.emp_id,e.dept_id,e.emp_name,e.emp_salary,dense_rank() over(partition by dept_id order by emp_salary) as ones from emp e
-- row_number
select e.emp_id,e.dept_id,e.emp_name,e.emp_salary,row_number() over(partition by dept_id order by emp_salary) as ones from emp e
3.1 计算偏移量
- LAG、LEAD(expression,,):LAG函数可以访问当前行的上一行,而LEAD函数可以访问当前行的下一行
- experssion:表达式,:为正整数,其可以选择从哪里开始输出当前行和上一行,输出的当前行和上一行都必须从第一行开始,依次往后推,:表示可以选择用什么值代替默认的null
- 注意:俩函数必须使用order by排序
SELECT emp_name, dept_id, emp_salary asl, LAG (emp_salary) OVER (ORDER BY emp_salary) LAG,
LEAD (emp_salary) OVER (ORDER BY emp_salary) LEAD
FROM emp
3.2 报表分析函数(RATIO_TO_REPORT)
- RATIO_TO_REPORT 报表分析函数,其中RATIO_TO_REPORT (emp_salary)中的参数表示,当前emp_salary占总emp_salary的百分比并且,再当前开窗函数中禁止使用order by 排序查询,可以在from或者where子句后使用,不能循环使用
SELECT emp_name, emp_salary, dept_id, RATIO_TO_REPORT (emp_salary) OVER () AS RR
FROM EMP
-- WHERE dept_id = 10149
order by emp_name, emp_salary desc, dept_id;
-------------------------------------------------------------------------------
SELECT emp_name, dept_id, emp_salary,
MIN (emp_salary)KEEP (DENSE_RANK FIRST ORDER BY dept_id) OVER (PARTITION BY dept_id) "Worst"/*,
MAX (emp_salary)KEEP (DENSE_RANK LAST ORDER BY dept_id) OVER (PARTITION BY dept_id) "Best"*/
FROM EMP
--group by emp_name, dept_id, emp_salary;
4、UNION和UNION ALL和intersect
-- 寻找交集 关键字-->intersect 可查询出删除或者更新的数据,前提是具有备份
select emp_id,dept_id,emp_name,emp_salary from emp
intersect
select emp_id,dept_id,emp_name,emp_salary from emp order by emp_salary
select emp_id from emp order by emp_id
-- minus:求第一个结果集中的数据不存在第二个结果集中的数据,且第二个结果集中的数据不在总结果集中显示
select emp_id from emp where emp_id < 10 minus select emp_id from emp where emp_id between 4 and 10;
-- union all:求俩个结果集中的所有数据,并且都显示出来
-- union:求俩个结果集中的数据,并且合并起来还带有去重效果
5、查看表空间文件所在位置
select file_name from dba_data_files where tablespace_name = 'CUX';
4、子查询
特点:‘< >’为不等于,any:比较子查询中的返回的某一个值进行比较,all:和子查询中返回的所有值进行比较,in:等于列表(查询列)中的任意一个
having关键字:针对查询的结果进行操作
-- 查询:返回其它部门中比job_id为‘IT_PROG’部门所有工资都低
-- 的员工的员工号、姓名、job_id以及salary
select employee_id,last_name,job_id,salary
from employees
where job_id <> 'IT_PROG'
and salary < all ( any
select salary
from employees
where job_id = 'IT_PROG'
)
-- 查询:最低工资大于50号部门最低工资的部门id和最低薪资
select department_id,min(salary)
from employees
group by department_id
having min(salary) > (
select min(salary)
from employees
where department_id = 50
)
5、高级子查询(未完2)
# 1、多列子查询
-- 查询与141号或174号员工的manager_id和department_id
-- 相同的其他员工的employee_id,manager_id,department_id
select employee_id,manager_id,department_id
from employees
where (manager_id,department_id) in(
# in:代表着manager_id,department_id在该子查询的范围内
select manager_id,department_id
from employees
where employee_id in (141,174)
)
# 并且查询出来的employee_id不包含141和174号员工
and employee_id not in(141,174)
# 2、from子句子查询,select可创建临时表进行比较,group by 代表着以哪个列为分组条件,然后该列相同的值放一起
-- 在from子句中使用子查询
-- 返回比本部门平均工资高的员工的last_name,department_id,salary
-- 及平均工资
select last_name,e1.department_id,salary,e2.avg_salary
from employees e1,
(select department_id,avg(salary) avg_salary from employees
group by department_id) e2
where e1.department_id = e2.department_id
# 3、order by子句中使用单列子查询
-- 查询员工的employee_id,last_name
-- 要求按照员工的department_name排序,默认为ASC
select employee_id,last_name
from employees e1
order by (select department_name from departments d
where e1.department_id = d.department_id) asc
# 4、条件表达式中使用子查询
-- 显示员工的employee_id,last_name和location
-- 其中,若员工department_id与location_id为1800的department_id相等
-- 则location为‘Canda’,否则为‘USA’
select employee_id,last_name,
(case department_id when
(select department_id from departments where location_id = 1800)
then 'Canda' else 'USA' end
) location
from employees
# 5、相关子查询
-- 若employees表中employee_id与job_history表中employee_id相同的数目
-- 不小于2,则输出相同employee_id,last_name,job_id
select employee_id,last_name,job_id
from employees e1
where 2 <= (select count(*) from job_history
where e1.employee_id = employee_id)
# 6、
6、视图
1、简单视图
# 1、创建视图
# one 是视图名称,对于视图的修改可以影响到整个基表,视图的创建有利于权限控制,不让所有得人都能够看到整张表的数据,而是看到某些特定的数据
create view one as
select employee_id,last_name,salary
from employees
where department_id = 80
# 2、修改视图
-- 对视图进行修改关键字: or replace,如果在原来的基础上进行修改,不改变视图名称
-- 那么修改后的视图将对原来的视图进行覆盖
-- 任何人对表都没有增、删、改操作,只有查询,可以在视图最后加上with read only(仅读)
create or replace view one as
select employee_id,last_name,salary,department_id
from employees
where department_id = 80
# 3、-- 对视图中的数据进行删除
delete from one where employee_id = 166
2、复杂视图
何为复杂:是否存在函数、分组
# 1、创建复杂视图
-- 视图中包含组函数和分组
create or replace view two as
select last_name,avg(salary) avg_salary,department_name
from employees e,departments d
where e.department_id = d.department_id
group by department_name,last_name
# 2、不能对复杂函数进行DML操作
-- 修改复杂视图中的内容
update two set department_name = 'tan' where last_name = 'Dilly'
ORA-01732: data manipulation operation not legal on this view
3、删除视图
drop view '视图名称';
4、(Top-N)分析伪列
注意:对 ROWNUM 只能使用 < 或 <=, 而用 =, >, >= 都将不能返回任何数据。如果需要让它可以使用 =, >, >= ,那么需要将ROWNUM 变成真实存在的数据
select rownum,employee_id,last_name,salary
from (
select employee_id,last_name,salary
from employees
order by salary desc
)
where rownum > 40 and rownum <=50
将rownum变成真实列,将rownum作为子查询的结果,然后再使用其别名作为开始查询的条件,这样即可在Rownum原有基础符号(< 或 <=)上使用其它的 =, >, >= 符号
select a.*,a.rn from (select emp_name,emp_salary,rownum rn from emp) a where rn >= 20
7、数据处理
0、拷贝表
# 复制一个表,可以选择复制几列,同样也可全部复制,并且复制其约束
create table emp1
as
select employee_id,last_name,hire_date,salary from employees
where 1=2
# 全部复制一个表中的任何数据
create table employees1
as
select * from employees
1、insert
# 1、插入值,当插入的日期需要转换时
insert into emp1 values
(1002,'BB',to_date('1991_09_01','yyyy-mm-dd'),20000)
# 2、复制表中的数据到新的空表中
insert into emp1
select employee_id,last_name,hire_date,salary
from employees
where department_id = 80
2、update、delete
# 1、更新144号员工的工作和薪资使其与205号员工相同
update employees1
set job_id = (select job_id from employees1 where employee_id = 205)
,
salary = (select salary from employees1 where employee_id = 205)
where employee_id = 144
###############################################
select job_id,salary <--查询144和205号员工
from employees1
where employee_id in (144,205)
###############################################
# 2、从employees1表中删除department名称中含有Public字符的部门id
delete from employees1
where department_id = (select department_id from departments
where department_name like '%Public%')
3、事务
commit、rollback、savepoint(保存点),如果对表中的数据操作过后,通过commit提交之后,使用rollback也不能回滚到最初的数据,同理设置savepoint(保存点)也一样,设置savepoint(保存点)之后,不能提交操作过后的语句,这样savepoint(保存点)就失去意义
4、行转列
某个表中存在一个部门号对应多个员工,现将每个部门所对应的员工进行分组,并且分俩列查询出来 -->listagg() within group
listagg() :就是将有员工名称汇集起来,通过逗号隔开,然后再order by,最后用id进行分组即可
select department_id, listagg(employee_name, ',') within group (order by employee_name) as name
from cux_oaf_test_employee group by department_id;
8、序列
重点:序列的初始值只有在初次使用时,才会存在,后续使用的值都是上一个表使用序列插入值的下一位值。如果想重新使用序列的初始值,只有通过删除序列进行重建才能使用初始值
1、创建、修改序列
注意:
当使用循环后:
① 如果插入数据的值到达了序列的 maxvalue 或者 序列默认的最大值时,只要序列中开启了循环模式,就代表着序列可以重新开始取值插入到表中,就意味着会存在重复值
② 如果序列中没有开启使用重复值,那么当序列插入的数据到达 maxvalue 或者 序列默认最大值时,如果还想继续插入数据,就会报错
cache 参数使用规则:
开启 cache:
① cache 参数默认是预存20个序列值到内存中,当数据开始插入时,每增加一个数,cache 往内存中追加一位数,保证内存中存在 20 序列值。 <=== 在大量数据插入时,有利于提高性能,
关闭 cache:
在大量数据插入时不可取,会降低 CPU 性能,许多数据处于等待状态。如下:
大量语句发生请求,申请序列时,为了避免序列在运用层实现序列而引起的性能瓶颈。Oracle序列允许将序列提前生成 cache x个先存入内存,在发生大量申请序列语句时,可直接到运行最快的内存中去得到序列。但cache个数也不能设置太大,因为在数据库重启时,会清空内存信息,预存在内存中的序列会丢失,当数据库再次启动后,序列从上次内存中最大的序列号+1 开始存入cache x个。这种情况也能会在数据库关闭时也会导致序号不连续。
-- 1、创建序列
create sequence empseq
-- 每次增长10间隔数是10
increment by 10
-- 从第10个数开始,进来每增长一次就加上increment by定义的值
start with 10
-- 提供的最大值:也就是序列增长到哪停止增长
默认最大值是
maxvalue 100
-- 最小值:序列最小值从哪位数开始
minvalue 0
-- 是否需要循环 no cycle代表不循环
cycle -- 循环
-- 不需要缓存 cache需要缓存
-- cache值会被提前缓存到内存中,默认是 20 个值
nocache / cache [值]
################################################
-- 2、修改序列,将需要修改的列列出来修改值即可
alter sequence empseq
increment by 1
nocycle
-- 3、查看当前用户下的序列
select * from user_sequences
select * from USER_OBJECTS
-- 4、解析表
min_value:默认初始值 1
max_value:默认是 10^28 次方
NOMAX_VALUE:并不代表着可以无限制的使用,默认是10^27次方
cache:默认是预存 20 个值到内存中。
nocycle:序列默认不循环

2、注意
- 对序列的任何操作,都会影响到序列的自增,如:
- (删、改序列值)
- 系统异常
- 多个表同时使用同一序列
- 以上的所有操作都会是序列在一定程度上产生间隙
3、查询、删除序列
# 1、查询序列
select sequence_name,min_value,max_value,increment_by,last_number from user_sequences
# 2、删除序列
drop sequence empseq
9、索引
重点:索引字段上如果存在空值,经过默认排序时,NULL值的行都会被排在最后
1、创建索引
# 1、索引名称一般为:表_列
create index emp2_id_ix
on emp2(employee_id)
# 2、删除索引
drop index '索引名称'
2、什么时候创建索引
- 以下情况创建索引
- 列中数据分布范围广
- 经常在where子句或连接条件中出现
- 表经常被访问且数据量较大
- 以下情况不创建索引
- 表小
- 列不经常作为连接条件或者出现在where子句中
- 数据较少
- 经常更新
九、锁
单表–引用表(主外键)—未解决
原则:
- 只有被修改时,行才会被锁定
- 当一条语句修改了一条记录,只有这条记录上被锁定
- 当某行被修改时,它将阻塞其它用户对它的修改
- 当一个事务修改一行时,将该行上加上行锁(TX),用于阻止其它事务对该行的修改
- 读永远不会阻止写,写也永远不会阻止读,唯一读会阻塞:select … for update
- 当一行被修改后,Oracle通过回滚段提供给数据的一致性读
- 锁阻塞:当多个会话竞争同一资源时,那么先执行的会话如不提交或回滚事务,那么后续的会话一直处于阻塞或等待状态 ----执行需要提交事务语句
insert和update锁机制区别
引用表:对主表进行DML操作时
TM锁(表锁)
-
排它锁(lock table emp in exclusive mode;):任何事务都不能进行DML语句操作。何时会触发该锁:Alter table、drop table、drop index、truncate table。释放锁只需要—>commit;
-
共享锁(lock table BOOS in share mode;): 若同时有多个会话对某一条语句做dml操作,session都加上S锁,那么各个session之间都必须等待对方释放锁 -->commit;释放
-
行级共享锁(lock table BOOS in row share mode; ): 当操作某一条数据时,使用RS锁,该条数据只能再当前事务中操作,别的事务不能对当前数据进行操作,如果对当前数据进行update操作,默认会自动加上行级排它锁
-
行级排它锁(lock table BOOS in row exclusive mode; ):只要事务不对同一行数据进行操作,那么不同的事务之间均可做不同的操作
-
行级共享排它锁(lock table BOOS in share row exclusive mode; ): 只能有一个事务能够获得该锁,其它事务只能对当前表做查询操作(除select … for update nowait)除非释放锁–commit;
-
DML语句获得表锁的目的:首先保证自身对表的访问不受其他事务DML语句干扰,其次阻止其他事务中和自身有冲突的DDL操作执行
-
当某一记录被锁定后,其它需要访问被锁定对象的会话会按先进先出的方式等待锁的释放,而对于select操作而言,不受锁的控制
-
S锁:
# 当前会话加上S锁,
lock table BOOS in share mode;
insert into boos(boos_id,boos_manager_id,boos_name,creation_date,last_update_date) values(3,1003,'Albert',sysdate,sysdate);
update boos set boos_name = 'Amoss' where boos_id = 3;
delete from boos where boos_id = 3;
-
系统表查看锁
-- 查询出有哪些表阻塞了--->v$lock SELECT sid, TYPE, lmode, id1, id2, request, BLOCK FROM v$lock WHERE TYPE IN ('TM', 'TX'); -- 根据 ID1 对应数字,查出对应的表--->dba_objects SELECT object_name FROM dba_objects WHERE object_id = 73557; -- 会话层面优化必看该表-->v$session_wait SELECT sid, event FROM v$session_wait WHERE sid = 160; commit; -- 查询存在等待资源的表 select object_name,machine,s.sid,s.serial# from v$locked_object l,dba_objects o ,v$session s where l.object_id = o.object_id and l.session_id=s.sid; -- 释放等待资源中的表 alter system kill session 'sid,serial$' alter system kill session '160,10714'; --------------------------------------------------------- ---------------------查看锁------------------------------- --------------------------------------------------------- select * from DBA_LOCKs; select * from DBA_LOCK; select * from V$FIXED_VIEW_DEFINITION; -- 动态性能视图查看 select * from V$LOCK; select * from V$LOCKED_OBJECT; --记录DML锁 select * from GV$CR_BLOCK_SERVER; select * from DBA_DDL_LOCKS; -- 查出所有的DDL锁 select * from DBA_DML_LOCKS; -- 查出所有的DML锁 select*from V$lock_Type;-- 查询Oracle中的锁
-- 释放等待资源中的表 alter system kill session 'sid,serial$'
alter system kill session '160,10714';
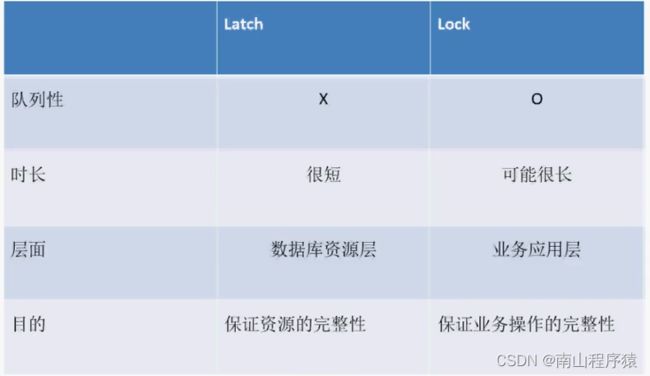
select name from v$latchname;
-- 查看表空间文件所在位置
select file_name from dba_data_files where tablespace_name = 'CUX';
Latch的获取
- wait方式–如果无法获取请求的latch,则
- spin
- 当一个会话无法获得需要的latch时,会继续使用CPU(CPU空转),达到一个间隔后再次尝试申请latch,直到达到最大的重试次数
- sleep
- 当一个会话无法获得需要的latch时,会等待一段时间(sleep),达到一个间隔后再次尝试申请latch,循环往复,直到达到最大的重试次数
- spin
- No wait方式–如果无法获取请求的latch,则
- 不会发生sleep或者spin,转而去获取其它可用的Latch
PL-SQL
1、PL-SQL块
PL-SQL程序由三块组成:即声明部分、执行部分、异常处理部分
2、如何使用
使用PL-SQL前,需要输入set serveroutput on该命令,如不输入,则不会有运行结果
3、记录类型和简单类型
- 一个PL/SQL RECORD必须包含一个或多个字段:这些字段的数据类型可以是标量类型、RECORD类型或PL/SQL表类型
- 在PL/SQL块中从表中取出一行进行处理时用PL/SQL RECORD
- SELECT语句查询的列值的数量与顺序,必须与创建记录类型变量中定义的字段数量和顺序相匹配
- 一个记录类型的变量仅仅能保存从数据库中查询出的一行记录,若查询出了多行记录。就会出现错误
################################################
-- 简单类型
declare
-- 声明变量、类型
-- 注意:声明变量的范围不能小于原本的范围,否则会造成数据插入失败
-- employees.salary%type:代表着可以动态的获取数据表的变量类型以及范围
v_sal employees.salary%type;
v_email varchar2(20);
v_hrie_date date;
begin
-- 程序执行部分(类似于Java中的main()方法)
select salary,email,hire_date into v_sal,v_email,v_hrie_date
from employees where employee_id = 100;
-- 打印
dbms_output.put_line(v_sal||','||v_email||','||v_hrie_date);
--exception
-- 针对begin块中出现的异常,提供处理机制
-- 使用 when ....then....
-- when ....then....
end;
###############################################
-- 记录类型
declare
-- 声明一个类型、
-- 注意:声明变量的范围不能小于原本的范围,否则会造成数据插入失败
-- employees.salary%type:代表着可以动态的获取数据表的变量类型以及范围
-- 记录类型
type fire is record(
v_sal employees.salary%type,
v_email varchar2(20),
v_hrie_date date
);
-- 定义一个记录类型的成员变量,名称可以随意取
v_fire fire;
begin
-- 程序执行部分(类似于Java中的main()方法)
select salary,email,hire_date into v_fire
from employees where employee_id = 100;
-- 打印,根据变量名称进行取值
dbms_output.put_line(v_fire.v_sal||','||v_fire.v_email||','||v_fire.v_hrie_date);
--exception
-- 针对begin块中出现的异常,提供处理机制
-- 使用 when ....then....
-- when ....then....
end;
4、游标
概念:用来处理多条数据
创建游标的四步骤:一、声明游标 二、打开游标 三、提取游标数据 四、关闭游标
1、使用游标查询单条数据
-- 游标
-- 打印出80号部门的所有的员工的工资:salary:xxx
declare
-- 定义变量
v_sal employees.salary%type;
-- 声明游标
cursor emp_sal_cursor is select salary from employees where department_id = 80;
begin
-- 打开游标
open emp_sal_cursor;
-- 提取游标
fetch emp_sal_cursor into v_sal;
-- 循环提取员工,while emp_sal_cursor%found:%found用来判断游标中是否
-- 还存在相关的行,然后 loop 开始循环
while emp_sal_cursor%found loop
dbms_output.put_line('salary'||v_sal);
-- 打印行之后,提取剩下的行在游标中
fetch emp_sal_cursor into v_sal;
end loop;
-- 关闭游标
close emp_sal_cursor;
end;
2、使用游标查询多条数据,通过定义记录类型
-- 游标
-- 打印出80号部门的所有的员工的工资:salary:xxx
-- 当需要输出多个属性时,这个时候声明一个记录类型,记录类型中的变量通过逗号隔开
declare
-- 声明一个记录类型
type emp_record is record(
v_sal employees.salary%type,
v_empid employees.employee_id%type,
v_hiredate employees.hire_date%type
);
-- 声明一个记录类型的变量
v_emp_record emp_record;
-- 定义游标
cursor emp_sal_cursor is select salary,employee_id,hire_date from employees where department_id = 80;
begin
-- 打开游标
open emp_sal_cursor;
-- 提取游标
fetch emp_sal_cursor into v_emp_record;
-- 循环提取员工,while emp_sal_cursor%found:%found用来判断游标中是否
-- 还存在相关的行,然后 loop 开始循环
while emp_sal_cursor%found loop
dbms_output.put_line('salary:'|| v_emp_record.v_sal
||',id:'|| v_emp_record.v_empid
||',hire_date:'|| v_emp_record.v_hiredate);
-- 打印行之后,提取剩下的行在游标中
fetch emp_sal_cursor into v_emp_record;
end loop;
-- 关闭游标
close emp_sal_cursor;
end;
3、通过使用For循环来使用游标,简化开发
-- 游标
-- 打印出80号部门的所有的员工的工资:salary:xxx
declare
-- 定义一个游标
cursor emp_sal_cursor is select salary,employee_id,hire_date
from employees where department_id = 80;
begin
for c in emp_sal_cursor loop
dbms_output.put_line('salary:' || c.salary || 'employee_id:'||
c.employee_id || 'hire_date:'||c.hire_date);
end loop;
end;
5、存储函数
注意:函数具有返回值
1、创建存储函数
-- 1、创建存储函数
-- 函数的helloword:返回一个"helloworld"的字符串
-- hello_world(v_log varchar2):函数名括号内是形参,根据形参的类型进行返回
-- 注意:如果函数不需要参数,那么函数名后就不需要带参数,如果需要参数,则需要指明参数类型,不需要指明大小
create or replace function hello_world(v_log varchar2)
-- 返回的形参类型
return varchar2
-- is:相当于declare,里面声明变量
is
# 声明变量、记录类型、cursor
begin
# 函数执行体
return v_log;
exception
# 处理函数执行过程的异常
end;
2、调用函数
-- PLSQL型
begin
dbms_output.put_line(hello_world('atguigu'));
end;
-- SQL型
select hello_world('atguigu') from dual
3、创建带参函数及out使用
1、注意:out:是可以被改变的,所以不定义为变量
-- 获取给定部门的工资总和,要求部门号定义为参数,工资总额定义为返回值
-- 并且将公司总人数返回
create or replace function get_sal1(dept_id number,total_peo out number)
return number
is
-- 定义一个变量来接收工资总和,并且初始化为零
v_sumsal number(10) := 0;
-- 通过游标来获取某一个部门的id
cursor salary_cursor is select salary
from employees
where department_id = dept_id;
begin
-- 声明初始值为空
v_total_peo number(4) := 0;
-- 利用for循环,拿到某一个部门的id号的每一员工工资
for c in salary_cursor loop
-- 将每一笔工资加上上一笔,得到所有工资总和
v_sumsal := v_sumsal + c.salary;
v_total_peo := v_total_peo + 1;
-- 退出循环
end loop;
-- 返回总工资
return v_sumsal;
end;
2、调用
declare
--v_sum_sal number(10) := 80;
v_num number(4) := 0;
begin
dbms_output.put_line(get_sal1(80,v_num));
dbms_output.put_line(v_num);
end;
3、注意
# 1、在没有时用NOCOPY时,主函数定义的值,在调用时,都会创建一个新的变量用来接收主函数的值,其中发生的操作是-->主函数:变量值一为:a,变量值二为:b -->当调用主函数的值时,外部declare会创建一个新的变量用来接收主函数的值,其中会产生的操作 —-> 调用时,主函数变量值a := c赋值给c,完成值传递之后,c := 将值传递给a,完成输出
6、存储过程
注意:存储函数没有返回值,如果需要添加,在形参中添加,声明在begin中
1、创建存储过程
create or replace procedure add_sal(dept_id number,temp_sal out number)
is
cursor sal_cursor is select employee_id,salary,hire_date from employees
where department_id = dept_id;
v_i number(4,2) := 0;
begin
temp_sal := 0;
for c in sal_cursor loop
if to_char(c.hire_date,'yyyy') < '1995' then v_i := 0.05;
elsif to_char(c.hire_date,'yyyy') < '1998' then v_i := 0.03;
else v_i := 0.01;
end if;
-- 更新工资
update employees set salary = salary * (1 + v_i)
where employee_id = c.employee_id;
-- 付出成本
temp_sal := temp_sal + c.salary * v_i;
end loop;
dbms_output.put_line(temp_sal);
end;
2、调用存储过程
declare
v_temp number(10) := 0;
begin
add_sal(80,v_temp);
end;
3、查询存储过程及终止
-- 1、搜索是否存在某一个存储过程(浅查询)
SELECT a.sid, a.object, a.type
FROM sys.v_$access a
WHERE (a.object LIKE upper('%print_reciprocal') OR
a.object LIKE lower('%print_reciprocal'))
-- 2、查询出某一存储过程的状态(俩表关联的新查询)
SELECT a.sid, a.object, a.type, b.serial#, b.status
FROM sys.v_$access a, sys.v_$session b
WHERE a.type = 'PROCEDURE'
-- 括号中-->存储名,使用模糊查询
AND (a.object LIKE upper('%print_reciprocal') OR
a.object LIKE lower('%print_reciprocal'))
AND a.sid = b.sid
-- 其状态不是唯一的,可以更改为Inactive
AND b.status = 'ACTIVE';
-- 3、终止命令中填写对应的SID,serial#俩个编号
ALTER system kill session '33,4185';
7、触发器
create or replace trigger delete_emp2
before
delete on emp2
for each row
begin
insert into my_emp_bak
values(:old.employee_id,:old.last_name,:old.salary);
end;
8、内置程序包
1、查看数据字典保留字
-- 查看Oracle的保留字
SELECT * FROM v$reserved_words m WHERE m.RESERVED='Y' order by keyword
2、内置程序包的使用
-- 内置程序包
-- 1、生成随机数
select abs(mod(dbms_random.random,100)) from dual;
-- 生成10-20之间的任意数
select dbms_random.value(10,20) from dual;
-- 生成10-20之间的任意数,但不包括小数
select floor(dbms_random.value(10,20)) from dual;
/*
dbms_random.string(类型,长度) 生成随机文本字符串,可以指定字符串长度和类型
类型:U:代表大写字母 L:代表小写字母 A:代表大小写混写 P:代表任意字符 X:代表大写字符和数字组成
注意:不包含汉字
*/
select dbms_random.string('P',10) from dual;
-- 日期转换
/*
1、to_char
2、to_date
J:代表日期对应的内部的整数
*/
select to_char(sysdate,'yyyy-mm-dd hh:mm:ss')from dual;
-- 随机2022年的某一天
select to_char(to_date('2022-01-01','yyyy-MM-dd'),'J') from dual;
select to_date(trunc(dbms_random.value(2459581,2459800)),'J')from dual;
-- 定时任务
-- 创建一个表
create table test1001(times date);
-- 创建一个存储过程
create or replace procedure AlbertTest is
begin
insert into test1001 values(sysdate);
end;
declare
v binary_integer; -- 记录定时任务的序号
begin
AlbertTest();
dbms_job.submit(v,'AlbertTest;',sysdate,'sysdate + 1/1440');
dbms_output.put_line(v);
end;
select * from test1001;
Select * From user_jobs; -- 查看定时任务
begin
dbms_job.run(283); -- 必须运行相对应的序号
end;
begin
dbms_job.remove(283); -- 删除定时任务对应的序号,定时任务即被删除
end;
-- 读取文件
create or replace directory FILEPATH as 'd:\test'; -- 创建文件路径
drop directory FILEPATH
/*
注意:写文件 write 也可以用 w 表示
读文件 read 也可以用 r 表示
追加文件 append 也可以用 a 表示
*/
declare
v_f utl_file.file_type;
begin
v_f :=utl_file.fopen('FILEPATH','file.txt','w'); -- 打开文件
utl_file.put_line(v_f,'sdasdasda'); -- 写入文件
utl_file.fclose(v_f); -- 关闭文件
end;
2、dbms_random包
-
random:生成一个随机数,range: -power**(**231~231] 区间范围为左开右闭且为整数值
-
normal:生成一个符合正态分布的随机数,标准差为1,期望值为0
-
string:生成一个指定模式指定位数的随机字符串,其中
- u 和 U 代表大写字母
- l 和 L 代表小写字母
- a 和 A 代表大小写字母混合输出
- x 和 X 代表大写字母和数字混合输出
- p 和 P 代表任意字符输出
-
initialize :默认情况下,DBMS_RANDOM包是根据用户、时间、会话来进行初始化,INITIALIZE函数,通过设置相同的种子值,则每次生成的随机序列都将是一样的,即便是在不同的会话中,不同的用户下,随机生成的10个值都是一样的
注意:initialize只支持数值,不支持其它类型
-
seed:功能和initialize相似,但seed不仅支持数值型,同样也支持字符型,注意:字符型最大不能超过varchar2的最大范围
DECLARE
a NUMBER(12) := 0;
BEGIN
FOR i IN 1 .. 100 LOOP
--select dbms_random.random into A from dual;
SELECT floor(dbms_random.value(10, 20)) INTO a FROM dual;
--select dbms_random.normal numbers INTO A from dual;
dbms_output.put_line('第' || i || '次:' || a);
END LOOP;
END;
-- initialize
begin
dbms_random.initialize(-1.2);
for i in 1 .. 20 loop
dbms_output.put_line('第'||i||'次:'||dbms_random.random);
end loop;
end;
-- seed
BEGIN
--dbms_random.seed(123);
dbms_random.seed('hello');
FOR i IN 1 .. 10 LOOP
dbms_output.put_line(round(dbms_random.value * 100));
END LOOP;
END;
select * from (select * from dept order by dbms_random.random) where rownum < 4
select dbms_random.random from dual;
select dbms_random.normal from dual;
select dbms_random.string('P',10) from dual;
select floor(dbms_random.value(10,20)) from dual;
3、dbms_job包
-
dbms_job.submit:提交任务请求,其语法格式为
# dbms_job.submit(序号,'存储过程',什么时间提交,'隔多久执行一次'); dbms_job.submit(s,'Albert.test_emp;',sysdate,'sysdate + 1/1440'); -
dbms_job.run(jobno):运行定时任务,括号中填写需要运行定时任务序号
-
dbms_job.remove(jobno):删除定时任务,括号中填写需要删除的定时任务序号
-
dbms.broken(jobno, broken, nextdate):停止定时任务,填写序号以及停止时间,默认为当前时间,注意其中broken返回布尔值
-
dbms_job.interval(jobno, interval):修改间隔时间
-
dbms_job.next_date(jobno, next_date):修改下次执行时间
-
job:dbms_job.what(jobno, what):修改要执行的操作
# 1、创建存储过程
create or replace procedure test_boos3 is
begin
# 输入操作语句
end test_boos3;
# 2、调用存储过程,并且声明变量,得到定时任务的序号,提交定时任务
declare
s binary_integer; -- 记录定时任务的序号
begin
Albert.test_emp();
dbms_job.submit(s,'Albert.test_emp;',sysdate,'sysdate + 1/1440');
dbms_output.put_line(s);
end;
# 3、开始执行定时任务
begin
dbms_job.run(26);
end;
# 4、删除 or 暂停定时任务
begin
#dbms_job.remove(26);
dbms_job.broken(27,true,sysdate);
#dbms_job.next_date(27,sysdate); 下次执行任务时间
end;
9、索引表(联合数组)and嵌套表
/*
集合中的属性
1、first取集合中第一个元素的下标
2、last取集合中最后一个元素的下标
3、count取集合元素的总长度
4、limit取集合元素的最大值(注:索引表和嵌套表不限制元素个数,所以返回的是空行,可变长度数组使用才会返回最大值)
5、delete([n])删除集合中的元素,n表示下标,即删除对应下标的值
6、extend(n,[ind])扩展集合元素,n代表扩展元素个数,ind表示集合中元素的下标
7、next(ind)取当前元素的下一个元素的下标
8、prior(ind)取当前元素的上一个元素的下标
下标同样是整数且必须是正数,同样可以使用字符串,下标不一定是连续的,元素个受index范围限制(-214483647 ~~ +214483647),语法后面接表索引类型
语法:type 名称 is table of 数据类型 索引类型(pls_integer 或者 varchar2)
变量 变量类型
问题:如何取到当前元素的下一个元素的下标
*/
declare
-- 创建一个索引表
type indexTableOne is table of varchar2(10) index by pls_integer;
-- 声明变量
s indexTableOne;
v_index pls_integer;
begin
-- 存储数据
s(1) := 'Tom';
s(-1) := 'Albert';
dbms_output.put_line(s.first||' '||s(-1));
dbms_output.put_line(s.limit||'<----最大值');
--s.delete(1);
dbms_output.put_line(s.count);
dbms_output.put_line(v_index.next);
end;
declare
-- 声明一个索引表
type AlbertTwo is table of number(10) index by pls_integer;
-- 声明一个变量
v_Two AlbertTwo;
-- 声明一个第三方的下标,用来记录当前索引表的索引值
-- 注:索引表声明为什么类型,当前索引值也要同为什么类型
v_index pls_integer;
begin
v_Two(-1) := 123;
v_Two(-5) := 1233;
v_Two(9) := 1234;
v_Two(4) := 1235;
v_Two(22) := 1236;
v_Two(0) := 1237;
-- 赋值为索引表中的第一个元素的索引
v_index := v_Two.first;
loop
dbms_output.put_line(v_index||' '||v_Two(v_index));
--dbms_output.put_line(v_Two(v_index).next);
-- 当表中的最后一个元素索引等于第一个元素的索引时,退出循环
exit when v_Two.last = v_index;
-- 将元素的下一个索引赋值给v_index继续循环
v_index := v_Two.next(v_index);
end loop;
--dbms_output.put_line(v_Two(v_index).next);
end;
declare
-- 创建索引表
type t is table of trainee%rowtype index by pls_integer;
-- 创建一个变量用来存储数据
s t;
i number :=1;
begin
for a in(select * from trainee) loop
s(i) := a;
dbms_output.put_line(s(i).traineename||' ' ||s(i).sex);
i := i+1;
end loop;
end;
declare
-- 声明记录类型
type Albert is record(
Sname varchar2(10),
Sage number(10)
);
-- 声明索引表
type indexTable is table of Albert index by varchar2(4);
-- 声明下标变量
A indexTable;
-- 声明变量类型,用来存储记录类型的数据
firsts Albert;
begin
firsts.Sname := '房东';
firsts.Sage := 50;
A('1') := firsts;
dbms_output.put_line(A('1').Sname||' '||A('1').Sage);
end;
/*
嵌套表属性:
1、下标同样是整数且必须是正数,同样可以使用字符串,下标必须是连续的,语法后面不接嵌套表索引类型
2、语法:type 名称 is table of 数据类型
变量 变量类型
3、可在PLSQL中写,也同样可以存储到数据库中
问题:嵌套表中-- 初始化的括号中是做什么的
1、当嵌套表类型为varchar2时,初始化中可以写字符串,但是写单个数字?
2、当嵌套表类型为number时,初始化中可以写多个数字,但是写单个数字?
*/
--声明嵌套表
declare
type t_q is table of varchar2(10);
v_q t_q;
begin
-- 初始化嵌套表
v_q := t_q('dsa','fqww','rqw');
dbms_output.put_line(v_q(1));
end;
declare
type t_q is table of number(10);
v_q t_q;
begin
-- 初始化嵌套表
v_q := t_q(1,2);
--v_q := t_q('天上人','蓝蓝天');
-- 扩展表
--v_q.extend(3);
--v_q(1) := 12354;
--v_q(2) := 456789;
--v_q(3) := '人';
dbms_output.put_line(v_q(1));
--dbms_output.put_line(v_q(2));
--dbms_output.put_line(v_q(1)||' ' ||v_q(2));
dbms_output.put_line(v_q.count);
end;
-- 把嵌套表存储到数据库中
-- 在声明嵌套表前面添加 create
create type t_q is table of vachar2(190);
drop type t_q; -- 删除嵌套表
declare
-- 声明变量接收数据
v_q t_q;
begin
-- 初始化嵌套表
v_q := t_q('fasfas','weq','rqw');
dbms_output.put_line(v_q(1));
end;
-- 在创建表的同时创建嵌套表
create type t_q is table of vachar2(190);
create table seven(
ids varchar2(12),
myname t_q
)nested table myname store as v_name;
-- 往嵌套表中添加数据
insert into seven values(1,t_q('Jack','杰克','克'));
select * from table(select myname from seven where ids = 1); --这样就可以查出嵌套表中以集合形式存在的数据
declare
type t_q is table of trainee%rowtype;
v_q t_q;
begin
-- 初始化嵌套表
v_q := t_q(trainee%rowtype);
dbms_output.put_line(v_q(1));
end;
10、变长数组之bulk collect和批量绑定
/*
1、特点:下标连续且只能为正的整数,元素个数有限制(初始化大小),可用于
PLSQL中,同样也可存储到数据库中
2、语法:
type 名称 is array(length) of 元素类型
3、注意:声明边长数组时,该变长指的是:使用extend进行扩展时,不得超出
定义时的长度,否则就溢出
问题:
*/
-- 可变长度数组
declare
-- 声明可变数组
type a is array(103) of varchar2(10);
-- 声明变量接收数据
v_a a;
--v_b a;
begin
-- 初始化数组
--v_a := a();
-- v_a := a('sad','weq','csa');
--v_a.extend(4);
v_a := a('sad','dq');
--v_b := a('sad','weq','csa');
v_a.extend(3);
v_a(3) := 'fga';
v_a(4) := 'fga2';
v_a(5) := 'fgaf';
-- v_a(7) := 'fgaf';
--v_a := a('sad','ddq','fg','u','ui','j','8ui','o');
--v_a(8) := 'f';
-- 打印出数组中元素个数,不给初始值,那么该数组
dbms_output.put_line(v_a(1));
dbms_output.put_line(v_a(2));
dbms_output.put_line(v_a.last);
dbms_output.put_line(v_a.count);
dbms_output.put_line(v_a(3));
dbms_output.put_line(v_a(4));
dbms_output.put_line(v_a(5));
--dbms_output.put_line(v_a(7));
end;
------------------------------------------------------
-- 在创建表的同时创建变长数组 <----明天完成
-- 先创建变长数组
create type a is array(190) of varchar2(10);
create table mytab(id number(10),name a);
select * from mytab;
insert into mytab values(1,a('b','d','c','a'));
drop type a;
drop table mytab;
-------------------------------------------------------
/*
bulk collect
:将查询出来的数据放入到一个集合变量中
语法:
select (需要查询的列) bulk collect into (集合变量)
*/
declare
-- 声明变量
--v_name trainee.traineename%type;
-- 定义集合类型嵌套
type t_q is table of trainee.traineename%type;
-- 定义变量接收
v_q t_q;
begin
-- 查询数据,将数据存放到集合中
select traineename bulk collect into v_q from trainee;
for i in v_q.first .. v_q.last loop
dbms_output.put_line(v_q(i));
end loop;
end;
-- 在游标中使用 bulk collect
declare
cursor t_q is select * from trainee;
-- 定义集合类型嵌套
type s_q is table of trainee%rowtype;
-- 定义变量接收
v_q s_q;
begin
-- 打开游标
open t_q;
-- 查询数据,将数据存放到集合中
fetch t_q bulk collect into v_q;
for i in v_q.first .. v_q.last loop
dbms_output.put_line(v_q(i).traineename);
end loop;
close t_q;
end;
select * from dept;
delete from dept where deptno = 10;
/*
批量绑定:做批量绑定时,对表中的列所做的操作都是对整张表的数据进行操作
问题:是否对表进行增、改、查操作
*/
-- 批量绑定
declare
-- 声明一个嵌套表
type a is table of dept%rowtype;
-- 声明变量接收数据
v_a a;
begin
--update dept set dname = Albert where deptno = 10;
--select deptno bulk collect into v_a from dept;
-- 批量绑定
forall i in v_a.first .. v_a.last
delete from dept where deptno = v_a(i);
end;
11、Oracle中XML语法
1、XML文本编写需注意:
- XML中的所有标签名和文档结构都是可以自定义的
- XML标签名称可包含字母、数字及其他字符。标签名称可以字符 'XML、Xml、xml’开始,但不能以数字、标点符号开始,不包含空格
- XML语法区分大小写,必须保持大小写一致
- XML必须正确嵌套开始结尾标签名
- XML文档中允许空元素的存在,所谓空元素就是标签中没有实际内容,表示方法有: 或
- XML文本内容中的所有空格都会被保留
- XML中特殊符号的引用:
- 注意:实体中的引用字符隐藏卡里,需点击实体
- > ; , < ; , & ; &apos ; " ; <–代表着下列符号的表示符,使用时需要将冒号和标识符之间的空格删除
| 名称 | 符号 | 实体引用 |
|---|---|---|
| 大于号 | > | > |
| 小于号 | < | < |
| 连接符 | & | & |
| 单引号 | ‘(英文单引号) | ' |
| 双引号 | ‘’ | " |
2、Oracle中操作XML数据
注意:函数中的属性值:xmlvalue,XQuery,new_value–>xmlvalue 为XMLType类型列名或变量,XQuery为字符串,用于指定查询XML实例中的XML节点的XQuery表达式,new_value:为修改的新节点树
- existsNode(xmlvalue,XQuery)函数:检查某一个节点是否存在,如果存在返回 1 ,否则返回 2 ,xmlvalue 为XMLType类型列名或变量,XQuery为字符串,用于指定查询XML实例中的XML节点的XQuery表达式
select count(*) from Xmltable where existsNode(LXFS,'/联系方式/地址/邮政编码')=1;
-
FLOWER表达式
-
包含模式匹配、过滤选择和结构构造
- FLOWER是’For、Let、Where、Order by、Return’的缩写
-
说明:
for $x in doc("note.xml")/book/note let $y := /book/note/to where $x/number<20 order by $x/brand return $x/brand- For:将note.xml文件中book元素下所有的note元素提取出来赋给变量$x,其中doc()是内置函数,作用是用于打开xml文档
- let:可选,用于在XQuery表达式中为变量赋值
- where:可选,用于选取note元素下number元素小于20的note元素,且number可改变
- order by:可选,用于指定查询结果,并且按照brand升序排序
- return:用于构造FLWOR中执行查询
-
12、补充
1、set unused目的:如果一张表中的某个字段存在数万条数据,使用直接删除可能会报错,除非添加足够的RSG空间,并且速度较慢,使用 set unused标记需要删除的列,然后该列会被隐藏,避开高峰期时,然后再删除
注意:
- set unused 是不可逆的,除非对底层的基表进行修改,否则该列将永久被隐藏,因为set unused列后,会清除掉数据字典中的信息
- 如果set unused的某列上存在索引,约束,同义词都会被自动删除,视图则会报错,如果重新添加原来的一列表中,那么视图即可重新使用
# 设置set unused
# ALTER TABLE [NAME] SET UNUSED CLOUNM [CLOUMN NAME];
alter table trainee set unused column tel; -- 单列
alter table trainee set un used (tel,deptid);-- 多列
# 删除被设置为set unused列
alter table trainee drop unused column;
2、分组 And 分组Rollup And cube分组
- Rollup:表示的意思是:除了分组的功能外,还进行累加的的,多了一个汇总。重点:后汇总
- cube:先汇总,然后再查询每个分组的值
SELECT emp_name, dept_id, SUM(emp_salary) FROM emp GROUP BY CUBE(dept_id, emp_name); ----------------------------------------------------- SELECT GROUPING (emp_name), GROUPING (dept_id), emp_name, dept_id,SUM (emp_salary) FROM emp GROUP BY ROLLUP (emp_name, dept_id) ORDER BY 1, 2;
grouping groupset group
12、树形结构查询
-
俩个方向
-
自上而下 top–>dwon,一个boos可能有多个manager,一个manager可能有多个emp,自上而下遍历一个不丢,顺序从左至右
-
自下而上 down–>top,一个manager只能有一个boos,自下向上的顺序也是从左开始
-
-
格式
-
在select语句中使用connect by 和 start with 子句可以用来查询树形结构关系
# 注意:prior在做左边就自上而下查询,在右边就自下而上查询 select 【column】 from 【table】 connect by prior 父节点 = 子节点 【start with:表示从哪个节点开始】 # eg: select empno,ename.mgr from emp connect by prior empno = mgr start with empno = 7566 -- 自上而下开始查,并且指定从empno = 7566编号上开始往下查
-
-
分层—>Level
- 查询中,额可以使用伪列LEVEL显示每行数据的有关层次,LEVEL将返回树形结构中当前节点的层次
# 首先得使用 column level format A20 Level(level,level*3,'') # 层数字:有多少层级关系就有多少层 # 分层使用level隔开,计算是:当分层数字为多少,那么就乘以3,然后再将前面用空格填补 -
prior放的左右位置决定了检索是自底向上还是自顶向下. 左边是自上而下(找子节点),右边是自下而上(找父节点)
-
找父节点:从当前节点开始,向上搜索,直到找到最高节点
-
注意:只有当前分支的所有数据会被查询出来,若某个节点下伴随有多个分支节点,但是这些分支节点不在当前查询的分支节点上,就不会查询出来
-
select * from menu start with ids='132000' connect by ids = prior parent_id; -
找子节点:从当前节点开始,向下搜索,直到找到最底节点
-
注意:自上而下查询时,若当前分支节点下存在多个子分支节点,那么所有的子分支节点都会被查询出来,若某一个子分支节点下还存在子节点,那么优先将当前子分支节点下的数据查询出来,然后再继续查询当前分支节点下的其它子节点
-
select * from menu start with ids='130000' connect by prior ids = parent_id; select * from menu start with ids='132100' connect by prior parent_id = ids;
-
13、RESTRICT_REFERENCES
程序辅助检验码,减产子程序的纯度,是否存在违规的地方。一般用在函数上,调用函数过程时,也需要做相应的设置检查,这是为了避免在DML语句上调用函数时不会产生错误
PRAGMA RESTRICT_REFERENCES(function_name | default , )RNDS, WNDS, RNPS, WNPS) | , TRUST) <---语法
RNDS,WNDS,RNPS,WNPS可以同时指定。但当TRUST指定是,其它的被忽略。
DEFAUT是指作用在该程序包上的所有子程序,函数。
RNDS(Read No Database State),规定子程序不能读取任何的数据库状态信息。(即不会查询数据库的任何表,包括DUAL虚表)
RNPS(Read No Package State),规定子程序不能读取任何程序包的状态信息,如变量等。限制:如果子程序调用了SQLCODE和SQLERRM函数,就不能指定该变量
WNDS(Write No Database State),规定子程序不能向数据库写入任何信息。(即不能修改数据库表)
WNPS(Write No Package State),规定子程序不能向程序包写入任何信息。(即不能修改程序包变量的值),限制:如果子程序调用了SQLCODE和SQLERRM函数,就不能指定该变量
TRUST,指出子程序是可以相信的不会违反一个或多个规则。这个选项是需要的当用C或JAVA写的函数通过PL/SQL调用时,因为PL/SQL在运行是对它们不能检查。
这个编译指令只能在程序包及对象类型说明部分指定。
2、查询所有视图
select * from user_views <--- 当前DB的所有视图
13、权限管理
1、当数据库用户进行DDL操作时,如果没有commit,之后继续执行DCL操作,那么DCL操作会隐式提交事务,其次,不管DCL操作是否成功执行,前面的DDL语句都会被提交
update sp set shop_price = -1 where names='徐福记';
grant select on Albert.Sp to public; <====successfully
update sp set shop_price = 2 where names='徐福记'; <====当前记录被改变
grant a to b; <====successfully