oracle数据库笔记
数据库笔记
DML数据操纵语言
增删改查
DDL数据定义语言
create,alter,drop
DCL数据控制语言
grant,
其他知识
元组:数据库中一行记录就是一个元组
执行批量sql脚本:使用.pdc文件,参考:pdc执行多个sql示例1、pdc执行多个sql示例2
归档:数据库有联机重做日志,一般数据库有两个联机重做日志,一个写满了就会切换,在归档模式下,在切换时,日志1的数据会被保存到归档目录中(这个文件叫归档重做日志),不归档就直接消失了。
空值null参与算数运算,结果为空
一般都是单引号
表空间
是一种用于存储数据库对象的逻辑空间,是oracle中信息存储最大的逻辑单元,其下还有段、区、数据块等逻辑数据类型。
分类:
- 永久表空间:存储要永久化存储的对象,如表、视图、存储过程等。
- 临时表空间:存储数据库的中间执行过程,比如保存order by 排序,分组时产生的临时数据,存储完成后自动释放。
- undo表空间:保存数据修改前的副本。存储事务所修改的旧址,即被修改之前的数据。当我们对一张表中的数据进行修改的同时会对修改之前的信息进行保存,为了对数据执行回滚、恢复、撤销的操作。
权限
系统权限:规定用户使用数据库的权限。针对用户
对象权限:用户对其他用户的表或视图的存取权限。针对视图
系统权限分类:
- DBA: 拥有全部特权,是系统最高权限,只有DBA才可以创建数据库结构。
- RESOURCE:拥有Resource权限的用户只可以创建实体,不可以创建数据库结构。
- CONNECT:拥有Connect权限的用户只可以登录Oracle,不可以创建实体,不可以创建数据库结构。
对于普通用户,给与connect和resource权限
dba用户给与connect、resource和dba权限
授权命令:
--授予系统权限
grant connect,[resource],[dba] to 用户名1,[用户名2];
--授予对象权限
grant create session,create table to [用户名][with admin option];
给用户转授权限的权限:
with grant option级联,比如给A转授,A授予了B权限,收回A权限时,B的权限也会失效。
with admin option不是级联,收回A的权限,B的权限不会失效。
增删改查语法
insert into 表名 [(列名)] values (值列表)
update 表名 set 列名 = 更新值 [where 更新条件]
delete [from] 表名 [where <删除条件>]
select [(列名)或*] from 表名 [where 查询条件]
批量更新:
merge into 目标表
using 数据来源(表/视图/查询)
on 目标和数据来源的条件(table1.c = table2.c , ......)
when matched then
条件满足则更新 update set table1.a = table2.a , table1.b = table2.b ;
when not matched then
条件不满足则插入 insert (table1.a,table1.b) values (table2.a,table2.b);
查询表
desc 表名;--查询表结构
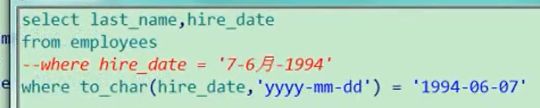
where to_char(date,'yyyy-mm-dd') = '2021-09-25';--判断日期属于9.25号的
where [not] between 20 and 40;--查询大于等于20小于等于40的
order by排序
order by A asc,B asc;--先按A升序,之后再按B升序
select wareqty*12 as salary from t_ware order by salary;--可以用别名进行排序
模糊查询
where 字段名 [not] like '%红%';--查询带红字的
where 字段名 [not] like '%红%黑%';--查询红某黑/某红黑某/某红黑/红黑某,红在前,黑在后
where 字段名 [not] like '_红'; --查询某红的
where name like '%/_%' escspe '/';--查询名字中有_的

子查询
--from 子查询:
from(select ...)where...
--select 子查询:
select 字段,(select ...) as 别名 from...
相关子查询
外层查询的条件作为一个元组与内层查询判断,判断完再将下一个元组与内层查询判断
相关子查询的执行依赖于外部查询。多数情况下是子查询的WHERE子句中引用了外部查询的表。执行过程:
(1)从外层查询中取出一个元组,将元组相关列的值传给内层查询。
(2)执行内层查询,得到子查询操作的值。
(3)外查询根据子查询返回的结果或结果集得到满足条件的行。
(4)然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕。

SElECT 图书名,出版社,类编号,价格
FROM Books As a
WHERE 价格 >
(
SELECT AVG(价格)
FROM Books AS b
WHERE a.类编号=b.类编号
)
先将Books表中的第一条记录的“类编号”的值“2”代入子查询中,子查询变为:
SELECT AVG(价格)
FROM Books AS b
WHERE b.类编号=2
子查询的结果为该类图书的平均价格,所以外部查询变为:
SElECT 图书名,出版社,类编号,价格
FROM Books As a
WHERE 价格 > 34
修改表结构
alter table 表名 add 字段名 字段类型;--增加字段
alter table 表名 modify 已存在字段名 类型;--修改字段类型,在字段无数据时
--字段有数据时,长度可以改(可以增大,减小时要看字段中数据最长值),类型不能改
alter table 表名 drop column 字段名;--删除字段
删除数据truncate 和 delete区别
数据量小,没有区别,数据量大,truncate更快
delete支持rolllback回滚,truncate不支持
delete会记录日志,truncate不会记录日志
delete可以结合where部分删除,truncate只能删除所有数据
truncate删除后自增id会初始化,delete删除后自增id不变
异常
raise_application_error(error_number,message[,[truefalse]]);
用于在plsql使用程序中自定义不正确消息,该异常只好在数据库端的子程序(流程、函数、包、触发器)中运用。
- error_number用于定义不正确号,该不正确号必须在-20000到-20999之间的负整数;
- message用于指定不正确消息,并且该消息的长度无法超过2048字节;
- 第三个参数假如为true,则该不正确会被放在先前不正确堆栈中,假如为false(默认值)则会替代先前所有不正确。
用法:if 条件 then raise_application_error();
循环
for 变量 in (select 语句) loop 执行语句 end loop;
变量中可以存储多个值。
去空格+取首字母
select f_st2zjm('王瑞') from dual;
update s_user_base set USERABC = f_st2zjm(USERNAME);--取首字母
update s_user_base set USERNAME = replace(USERNAME,' ','');--去掉姓名中空格
取中文首字母函数
CREATE OR REPLACE FUNCTION f_st2zjm(p_name IN VARCHAR2) RETURN VARCHAR2 AS
v_compare VARCHAR2(100);
v_return VARCHAR2(4000);
v_name VARCHAR2(4000);
v_para1313 s_sys_ini.inipara%TYPE;
v_p_mark VARCHAR2(4000);
FUNCTION f_nlssort(p_word IN VARCHAR2) RETURN VARCHAR2 AS
BEGIN
RETURN nlssort(p_word, 'NLS_SORT=SCHINESE_PINYIN_M');
END;
BEGIN
IF p_name IS NULL THEN
RETURN NULL;
END IF;
BEGIN
SELECT defpara
INTO v_para1313
FROM s_sys_ini_base
WHERE inicode = '1313';
EXCEPTION
WHEN no_data_found THEN
v_para1313 := '1';
END;
IF v_para1313 = '2' THEN
RETURN f_st2wb(p_name);
END IF;
v_name := f_get_py_group(p_name);
--将符号剔除
v_p_mark := '~,!,@,#,$,%,^,&,*,(,),_,+,|,},{,",:,<,>,?,\,`,-,=,[,],/,.,~,!,@,#,¥,%,……,&,*,(,),——,+,|,},{,“,”,:,?,》,《';
FOR i IN 1 .. length(v_name) LOOP
v_compare := f_nlssort(substr(v_name, i, 1));
IF v_compare >= f_nlssort('吖') AND v_compare <= f_nlssort('驁') THEN
v_return := v_return || 'A';
ELSIF v_compare >= f_nlssort('八') AND v_compare <= f_nlssort('簿') THEN
v_return := v_return || 'B';
ELSIF v_compare >= f_nlssort('嚓') AND v_compare <= f_nlssort('錯') THEN
v_return := v_return || 'C';
ELSIF v_compare >= f_nlssort('咑') AND v_compare <= f_nlssort('鵽') THEN
v_return := v_return || 'D';
ELSIF v_compare >= f_nlssort('妸') AND v_compare <= f_nlssort('樲') THEN
v_return := v_return || 'E';
ELSIF v_compare >= f_nlssort('发') AND v_compare <= f_nlssort('猤') THEN
v_return := v_return || 'F';
ELSIF v_compare >= f_nlssort('旮') AND v_compare <= f_nlssort('腂') THEN
v_return := v_return || 'G';
ELSIF v_compare >= f_nlssort('妎') AND v_compare <= f_nlssort('夻') THEN
v_return := v_return || 'H';
ELSIF v_compare >= f_nlssort('丌') AND v_compare <= f_nlssort('攈') THEN
v_return := v_return || 'J';
ELSIF v_compare >= f_nlssort('咔') AND v_compare <= f_nlssort('穒') THEN
v_return := v_return || 'K';
ELSIF v_compare >= f_nlssort('垃') AND v_compare <= f_nlssort('擽') THEN
v_return := v_return || 'L';
ELSIF v_compare >= f_nlssort('嘸') AND v_compare <= f_nlssort('椧') THEN
v_return := v_return || 'M';
ELSIF v_compare >= f_nlssort('拏') AND v_compare <= f_nlssort('瘧') THEN
v_return := v_return || 'N';
ELSIF v_compare >= f_nlssort('筽') AND v_compare <= f_nlssort('漚') THEN
v_return := v_return || 'O';
ELSIF v_compare >= f_nlssort('妑') AND v_compare <= f_nlssort('曝') THEN
v_return := v_return || 'P';
ELSIF v_compare >= f_nlssort('七') AND v_compare <= f_nlssort('裠') THEN
v_return := v_return || 'Q';
ELSIF v_compare >= f_nlssort('亽') AND v_compare <= f_nlssort('鶸') THEN
v_return := v_return || 'R';
ELSIF v_compare >= f_nlssort('仨') AND v_compare <= f_nlssort('蜶') THEN
v_return := v_return || 'S';
ELSIF v_compare >= f_nlssort('侤') AND v_compare <= f_nlssort('籜') THEN
v_return := v_return || 'T';
ELSIF v_compare >= f_nlssort('屲') AND v_compare <= f_nlssort('鶩') THEN
v_return := v_return || 'W';
ELSIF v_compare >= f_nlssort('夕') AND v_compare <= f_nlssort('鑂') THEN
v_return := v_return || 'X';
ELSIF v_compare >= f_nlssort('丫') AND v_compare <= f_nlssort('韻') THEN
v_return := v_return || 'Y';
ELSIF v_compare >= f_nlssort('帀') AND v_compare <= f_nlssort('咗') THEN
v_return := v_return || 'Z';
ELSE
v_return := v_return || substr(v_name, i, 1);
END IF;
END LOOP;
IF v_para1313 = '1' THEN
v_return := v_return;
ELSIF v_para1313 = '3' THEN
v_return := v_return || ',' || f_st2wb(p_name);
ELSIF v_para1313 = '4' THEN
v_return := f_st2wb(p_name) || ',' || v_return;
ELSE
v_return := v_return;
END IF;
FOR rec IN (SELECT TRIM(regexp_substr(v_p_mark, '[^,]+', 1, LEVEL)) AS mk
FROM dual
CONNECT BY rownum <= regexp_count(v_p_mark, ',') + 1) LOOP
IF instr(v_return, rec.mk) > 0 THEN
v_return := REPLACE(v_return, rec.mk, '');
END IF;
END LOOP;
RETURN v_return;
END;
添加约束
主键
已经建好表了添加主键:
alter table 表名 add constraint PK_字段名 primary key (字段名);
外键
已经建好表了添加外键:
alter table 从表表名 add constraint 外键约束名称 foreign key(字段名) references 主表表名(主表字段名);
删除外键约束:
alter table 从表表名 drop foreign key 外键约束名称;
唯一约束
alter table 表名 add constraint 约束名称 unique(字段名);
非空约束
alter table 表名 modify 字段名 not null;
默认值
create table ceshiyueshu(
id number primary key,
name varchar2(40) unique,
是否团员 varchar2(10) default(('是')),
sex varchar2(10) not null,
bbid number,
foreign key(bbid) references bb(bbid)
)
| 约束名 | 关键字 | 描述 |
|---|---|---|
| 主键 | primary key | 不重复、不为空 |
| 外键 | primary key | 关联主表 |
| 唯一 | unique | 不重复 |
| 非空 | not null | 不为空 |
| 默认值约束 | default | 给字段设置默认值 |
存储过程
语法
CREATE OR REPLACE PROCEDURE 存储过程名(变量名 IN 变量类型,变量名 OUT 类型)
-- IN是输入变量,OUT是输出变量
IS
变量名 类型; -- 定义变量
BEGIN
select sum(score) into 变量 from student where name = '小王';
-- 用(select 值 into 变量 ...)将查询到的值赋给变量
END;
--运行存储过程方式1:
call 存储过程名(变量传值);
--运行存储过程方式2:
declare
begin
存储过程名(变量传值);
end;
if语句
if 逻辑表达式 then 内容
else if 逻辑表达式 then 内容
else if 内容
end if;
临时表
一般用于需要动态sql语句时使用,就是里面sql语句不是固定的,可以加条件。
str:='creat table.../select.../insert...';
execute immediate str;--使用动态SQL语句来执行
str:='insert into tablename values(aa,bb) where cc = '
自定义类型
create or replace type '自定义类型名称' is object(
a number(10),
b varchar2(100)
);
//或者
type '自定义类型名称' is record(
a number(10),
b varchar2(100)
);
初步接触是可以在创建数组类型时,使用自定义的类型;
/或者直接用来创建表:(暂时感觉这个没啥用)
create table '表名' of '自定义类型名称';
然后在对表操作时要用:
insert into '表名' select '自定义类型名称' (a,b) from dual;
数组类型
create or replace type '数组类型名称1' is table of '自定义类型名称';
或者
create or replace type '数组类型名称2' is varchar2(100) of aaa;
//或者type '数组类型名称2' is table of 'varchar2(100)';
初步接触,可以用来创建自定义类型的数组类型,
例如在存储过程中:{
create...is
'数组变量名1' '数组类型名称1';
'数组变量名2' '数组类型名称2';
begin
'数组变量名1'.extend;//使用数组时需要为数组增加空间,用一个加一个
'数组变量名1'.count;//获取数组计数
例如:
'数组变量名1'(1):='自定义类型名称'(a,b);
或者:
'数组变量名2'(1):='数组类型名称2'('varchar2(100)','varchar2(100)');//初始化值
'数组变量名2'(1):='varchar2(100)';//增加值
end ..;}
触发器
增删改自动激活
create trigger 触发器名
after -- instead of之前、after之后
insert or delete or update
on 表名
as
declare
变量名 表名.字段名%TYPE --引用变量,同步变量类型,如果表结构数据类型改变,这里也改变
begin
if (select count(*) from stu)>17
then
rollback tran; --回滚事务
else
end if;
end;
作业job
序列
索引
游标
外连接
join on
inner join on 内连接,连接两表的交集
left join on 左外连接
--左外连接在oracle中另一种写法:where a.id = b.id(+)
right join on 右外连接
--右外连接在oracle中另一种写法:where a.id(+) = b.id
full join on 全连接,没交集的也连,全部显示
函数
字符函数

substr(字符串,2[,2])--从第2个字符开始,截取2个字符,或从第2个字符开始,截取后面所有
substrb(字符串,2[,2])--从第2个字节开始,截取2个字节,或从第2个字节开始,截取后面所有
例:
select substr('我是个好人',3) from dual;
结果为:个好人
select substrb('我是个好人',3) from dual;
结果为:是个好人 --一个字符占两个字节
concat()--字符串拼接,多个字符串品拼接直接用||连接符
数值函数

round(小数,2)--四舍五入,保留2位小数点
trunc(小数,2)--截取,截小数点后2位
mod(10,3) = 1--取模,求余数
日期函数
sysdate--获取当前日期
add_months(sysdate,2)--加月函数,加2个月往后推2月,减月写负数即可
last_day()--当月最后一天
trunc(sysdate,'mm')--日期截取,按月截取(把日截掉,截到月份的一号)
--按年'yyyy',按小时'hh',按分钟'mi'
months_between()--两个日期相差的月数
转换函数
to_char()--数字转字符串
to_char(日期变量,'yyyy-mm--dd')--日期转字符串,'yyyy-mm--dd hh:mi:ss'
to_date('2021-8-12','yyyy-mm--dd')--字符串转日期
to_number('100')--字符串转数字
字符||数字--自动转为字符
字符+数字0--自动转为数字
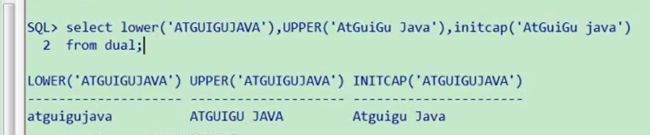
lower(字段)全转换为大写字符;
upper(字段)全转换为小写字符;
initcap(字段)只有首字母大写
其他函数
nvl(数字类型字段,999)--空值处理,为null的值显示999
--nvl2(字段,to_char(字段),'空值')空值显示字符
decode(条件,值1,翻译值1,即case2,内容2,缺省值)--条件判断,缺省值可不写
lpad(字段,10,'*');--查询字段的值,占10个字符,不足的在左侧补*
rpad();--在右侧补*
trim(['q' from] 字段);--去掉首尾空格/去掉首尾的'q'字符
replace('abcd','b','m');--替换b为m,替换所有的b
select name,
(case bbid
when 101 then
'实施部'
when 102 then
'支持部'
else
'其他'
end)
from aa --条件判断
行列转换

分析函数

值相同,排名相同,序号跳跃,比如12245
select rank() over(order by score desc) as 排名,t.* from student t;
值相同,排名相同,序号连续,比如12234
select dense_rank() over(prder by score desc) as 排名,t.* from student t;
序号连续,不管值是否相同,比如12345
select row_number() over(prder by score desc) as 排名,t.* from student t;
集合运算
视图
虚拟表,修改视图的数据同步修改表的数据
语法:
create or replace [force] view 视图名
as 表
[with check option] --检查约束,比如条件是部门为101的视图,添加102部门执行不通过
--加约束后对视图进行Insert/update有where条件的限制,如果没有where则约束无用
[with read only] --只读不能修改
索引
优点:索引大大提高检索速度,
缺点:太多的索引会影响更新表的速度,在Insert/update/delete时,不仅要保存数据,还要保存索引
分类:1、单列索引 2、多列索引 3、聚簇索引
创建索引:
create [unique] [cluster] index
索引名 on 表名(字段名 [asc/desc],字段名 [asc/desc]);
--unique表示索引中每一个索引值都对应唯一的数据记录,即唯一索引,不能重复
--cluter表示聚簇索引
--可以指定索引的排列次序,默认升序
修改索引名:
alter index 旧索引名 rename to 新索引名;
删除索引:
drop index 索引名;
震哥讲数据库
in 和 exists 的区别
in
- 适用于外查询的表比子查询的表大,
- 先执行子查询
- 先查內表,再內表和外表做笛卡尔积,按条件筛选
exists
- 适用于子查询的表比外查询的表大,
- 先执行外查询,在根据外查询的记录与子查询比较
- 对外查询做loop循环,每次循环再对子查询进行判断
not in 和 not exists 的区别
not in
- 无论内外表谁大,查询效率比not exists 低
- 没用用到索引,内外表都要全盘扫描
not exists
- 无论内外表谁大,查询效率高
- 子查询可以用索引
for update
一种排它锁:
X锁,其他用户不能对其进行修改和查询,同一时间允许一个用户在一个表上放置排它锁,不能再加任何锁
select ...for update [of 字段名][wait 数字]
--对表进行加锁,只允许当前用户对表进行更新
--of用于指定即将更新的字段(列)
--wait用于等待其他用户释放锁的秒数,防止无限期等待
共享锁:
S锁,其他用户可以读取,不能修改,可以再加S锁,不能加X锁
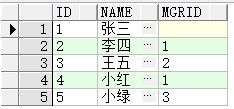
树形查询
创建表:
create table EMP1
(
id VARCHAR2(4) primary key,--id
name VARCHAR2(50),--姓名
mgrid VARCHAR2(4)--老板id
)
树形查询:
select level,t.id,t.name,t.mgrid,
connect_by_isleaf, --是否属于叶子节点,结果为1或0
sys_connect_by_path(t.name,',') --根节点到到当前节点的路径,用name显示
from 表 t
start with t.mgrid is null --查询开始条件,根节点
connect by prior id = t.mgrid; --递归条件,
--先找到张三,再根据递归条件,找到与张三id相等的mgrid,再对下一个节点进行递归

作业job
示例:每三分钟调用一次过程 p_dbms_job_test:
declare
job binary_integer;
begin
dbms_job.submit(job => :job,
what => 'p_dbms_job_test();',
next_date => sysdate, -- 立即执行
interval => 'sysdate + 3/1440' -- 1天 = 24*60*60 = 1440
);
-- 记得哦
commit;
end;
参数解释:
3.查看所有job
select * from dba_jobs t;
4. 主要参数
(1) job : job 序列号(来自 sys.jobseq)
(2) what : 具体要做的事情,常为要调用的 '存储过程名'
(3) next_date: 下次运行时间
(4) interval : 时间间隔(周期),格式同平常咱写 日期一样,如:-- 不区分大小写
<1> 每 30 秒运行一次 'SYSDATE + 30/(24*60*60)'
<2> 每天午夜 12 点 'trunc(sysdate + 1)'
<3> 每分钟运行一次 'sysdate+1/1440'
5. 日期函数
select sysdate 当前时间,
sysdate + 1 每天,
sysdate + 1 / 24 每小时,
sysdate + 1 / (24 * 60) 每分钟,
sysdate + 1 / (24 * 60 * 60) 每秒,
sysdate + 7 每周,
trunc(sysdate + 1) 每天午夜12点,
trunc(sysdate + 1) + (8 * 60 + 30) / (24 * 60) 每天早上8点30分,
-- show parameter nls_date_language; 'TUESDAY'
next_day(trunc(sysdate), '星期二') + 12 / 24 每星期二中午12点,
trunc(last_day(sysdate)) + 1 每个月第一天的午夜12点,
trunc(add_months(sysdate + 2 / 24, 3), 'Q') - 1 / 24 每个季度最后一天的晚上11点,
-- 周六 saturday,周日 sunday
trunc(least(next_day(sysdate, '星期六'), next_day(sysdate, '星期日'))) +
(6 * 60 + 10) / (24 * 60) 每周六和周日早上6点10分
from dual;
id自动递增
为了创建一个作业,作业中执行存储过程,向aa表中插入相同数据,解决数据相同问题
--建表:
create table AA(
id number primary key,
name varchar2(10),
sex varchar2(10),
bbid number
);
--建序列:
create sequence T_RPT_TPYE_USER_autoinc
minvalue 1
maxvalue 9999999999999999999999999999
start with 10 --根据当前表中id最大值 + 1
increment by 1
nocache;
--建触发器:
create or replace trigger insert_T_RPT_TPYE_USER_autoinc
before insert on aa
for each row
begin
select T_RPT_TPYE_USER_autoinc.nextval into :new.id from dual; --通过序列生成新id
end insert_T_RPT_TPYE_USER_autoinc;
job中使用的存储过程:
create or replace procedure proc_test002
is
begin
insert into aa(name,sex,bbid) values('小王','男',102);
end proc_test002;
包
登录用户@服务器地址/实例名字(即登录的数据库)
函数funtions
select 函数名('参数',参数) from dual;
存储过程
包packages
包含过程、函数等等,打包
包体
触发器trigger
数量的改变一般是触发器实现(库存变化,,)
作业dbms_job(定时任务)+ jobs(也可以用)
存储过程实现某个逻辑,使用作业定时执行过程
table表:
数据存放在表空间,右键点击查看/描述
表中触发器的顺序,是根据新建时间排序执行
视图:
v开头,
好处:可以直接查询视图(视图中包含很多CURD语句),修改灵活方便
序列:
users/roles角色/同义词/database links/tablespaces表空间/
常用:索引、序列、作业、触发器、存储过程、表
连接符||
等于=
is [not] null 为空
between 小值 and 大值
compid企业编号
group by 在 order by 前面
like查询慢
exists not exists与in not in区别,使用情况,
for update
as 加别名 ,如果查询不同表的相同字段,做报表时会出错,一定要加别名
树形查询
comment添加备注
更新数据是可以先查询看一下,正常则提交事务,不正常则回滚事务
drop 不能回滚
右键都看看什么意思
查看错误信息详情,查看功能(窗体客户化设计器-窗口名称=功能名),方案顺序号,双击右侧点击方案
右击点击导出,会显示数据窗体名称,在数据窗体客户化调整器中搜索数据窗体名称