基于Elasticsearch + Fluentd + Kibana(EFK)搭建日志收集管理系统
目录
1、EFK简介
2、EFK框架
2.1、Fluentd系统架构
2.2、Elasticsearch系统架构
2.3、Kibana系统架构
3、Elasticsearch接口
4、EFK在虚拟机中安装步骤
4.1、安装elasticsearch
4.2、安装kibana
4.3、安装fluentd
4.4、进入kibana创建索引
5、Fluentd配置介绍
Elasticsearch,Fluentd和Kibana(EFK)可以进行收集,索引,搜索和可视化日志数据。Elasticsearch负责数据的存储和索引,Fluentd负责数据的调整、过滤、传输,Kibana负责数据的展示。今天就来详细介绍一下使用Elasticsearch,Fluentd和Kibana搭建日志管理系统的详细过程。
1、EFK简介

Elasticsearch,Fluentd和Kibana(EFK)可以进行收集,索引,搜索和可视化日志数据。Elasticsearch负责数据的存储和索引,Fluentd负责数据的调整、过滤、传输,Kibana负责数据的展示。
fluentd实时收集日志,把日志作为JSON stream,可以同时从多台server上收集大量日志,易于安装,有灵活的插件机制和缓冲,支持日志转发。它统一实现了每一环节的数据传输,只需要关注数据处理的逻辑,也不用学习各种API,通过配置就可以实现实时增量数据的流出和流入。
Elasticsearch提供了一个分布式多用户能力的全文搜索引擎。基于RESTful web接口,且提供持久存储、统计等多项功能。可用于全文搜索、结构化搜索、分析以及将这三者混合使用,通过简单的配置就可以做数据复制和分片,并且,它在NRT(Near Real Time)方面做了一些优化,使得应用在实时性方面有很好的表现。
Kibana 是一个基于浏览器页面的 ElasticSearch 前端展示工具,内置了各种查询和聚合操作,并拥有图形化展示功能。使用它对日志进行高效地搜索、可视化、分析等各种操作。可以通过各种图表进行高级数据分析及展示。
2、EFK框架
EFK日志处理系统的流程框架如下所示:
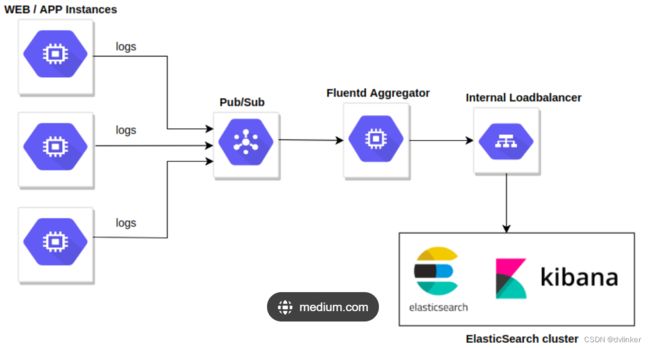
具体的流程为:fluentd进行日志的收集,数据来源可以自己设置为容器日志或者存储在本地文件的日志文件,收集之后发送给Elasticsearch进行统一的管理、搜索等操作,最后kibana将结果展示在web界面上。
日志的处理流程可以简化为:

当考虑健壮性时,需要复杂配置,如图:

多了一层fluentd,以及备选的点,这样日志收集的过程更加稳定以及可靠。
2.1、Fluentd系统架构

fluentd系统如下图所示:
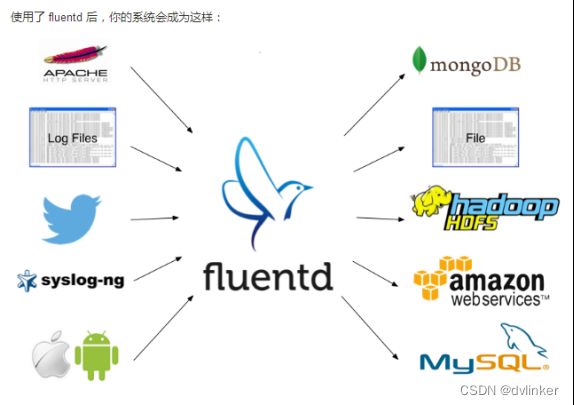
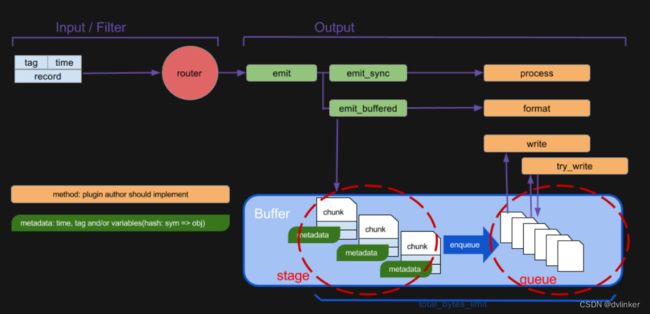
fluentd的数据流简单,从数据源获取,进行集中,然后发送到输出的地方,流程:输入input --> 处理filter(不是必须的) --> 输出output
input:读取日志内容。
output:输出,常见的有mongodb,elasticsearch,kafka等,只需安装相关的插件即可。
详细结构如下图所示:
2.2、Elasticsearch系统架构

Elasticsearch作用:fluentd将过滤后的日志内容发给全文搜索服务ElasticSearch,提供检索功能。Elasticsearch 的rest请求的传递流程如下所示:

用户发起http请求,Elasticsearch 的9200端口接受请求后,传递给对应的RestAction。RestAction做的事情很简单,将rest请求转换为RPC的TransportRequest,然后调用NodeClient,相当于用客户端的方式请求RPC服务,只不过transport层会对本节点的请求特殊处理。
2.3、Kibana系统架构

Kibana是一个强大的数据展示工具。大多数情况下,不需要开发任何代码,就可以得到一个Dashboard。使用 Kibana 来查询,浏览并且可以与存储在 Elasticsearch indices(索引)中的数据交互。需要做的是:
(1)把数据放到ES中
(2)是在Kibana页面上配置报表模版,或按照规则写一套报表模版。
kibana的工作流程如下:

3、Elasticsearch接口
多种语言都可以使用 REST API 通过端口 9200 和 Elasticsearch 进行通信,REST请求和应答是典型的JSON(JavaScript对象 符号)格式。通常情况下,一个REST请求包含一个JSON文件,其回复也是一个JSON文件。
一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X
' :// : / ? ' -d ''。
其中被 < > 标记的部分分别为:
VERB:适当的 HTTP 方法 或 谓词 : GET`、 `POST`、 `PUT`、 `HEAD 或者 `DELETE`。
PROTOCOL:http 或者 https`(如果你在 Elasticsearch 前面有一个 `https 代理)。
HOST:Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。
PORT:运行 Elasticsearch HTTP 服务的端口号,默认是 9200。
PATH:API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm。
QUERY_STRING:任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读)。
BODY:一个 JSON 格式的请求体 (如果请求需要的话)。
GET 可以用来检索文档,同样的,可以使用 DELETE 命令来删除文档,以及使用 HEAD 指令来检查文档是否存在。如果想更新已存在的文档,只需再次 PUT。
在请求的查询串参数中加上 pretty 参数,这将会调用 Elasticsearch 的 pretty-print 功能,该功能 使得 JSON 响应体更加可读。但是, _source 字段不能被格式化打印出来。相反,我们得到的 _source 字段中的 JSON 串,刚好是和我们传给它的一样。例如:
curl -XGET http://localhost:9200/website/blog/123 -d ‘{...}’
一个查询语句的典型结构:
curl -XGET http://localhost:9200/search -d ‘
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
} ‘
要启用表头,添加 ?v 参数即可。
Elasticsearch集群个数:应该始终被配置为 master 候选节点的法定个数(大多数个)。法定个数就是 ( master 候选节点个数 / 2) + 1。Elasticsearch 自己会输出很多日志,都放在 ES_HOME/logs 目录下。默认的日志记录等级是 INFO。
4、EFK在虚拟机中安装步骤
4.1、安装elasticsearch
首先,安装JDK或者openJDK(这里以openJDK为例),然后安装elasticsearch,最后启动elasticsearch:
[root@elk elk]# yum install java-1.8.0-openjdk -y
[root@elk elk]# wget -c https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.3.3/elasticsearch-2.3.3.rpm
[root@elk elk]# yum localinstall elasticsearch-2.3.3.rpm –y
[root@elk elk]# systemctl daemon-reload
[root@elk elk]# systemctl enable elasticsearch
[root@elk elk]# systemctl start elasticsearch修改防火墙,开放9200和9300端口:
[root@elk elk]# firewall-cmd --permanent --add-port={9200/tcp,9300/tcp}
[root@elk elk]# firewall-cmd –reload4.2、安装kibana
[root@elk elk]# wget https://download.elastic.co/kibana/kibana/kibana-4.5.1-1.x86_64.rpm
[root@elk elk]# yum localinstall kibana-4.5.1-1.x86_64.rpm –y
[root@elk elk]# systemctl enable kibana
[root@elk elk]# systemctl start kibana修改防火墙,对外开放tcp/5601:
[root@elk elk]# firewall-cmd --permanent --add-port=5601/tcp
[root@elk elk]# firewall-cmd --reload打开浏览器测试访问kibana的首页http://localhost:5601/
4.3、安装fluentd
安装前查看当前最大打开文件数:
$ ulimit -n如果查看到的是1024,那么这个数值是不足的,则需要修改配置文件提高数值
vi /etc/security/limits.conf设置值如下:
root soft nofile 65536
root hard nofile 65536
* soft nofile 65536
* hard nofile 65536
然后重启系统。
4.3.1、安装fluentd
执行如下命令(命令将会自动安装td-agent,td-agent即为fluentd):
$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent2.sh | sh启动td-agent:
$ /etc/init.d/td-agent start
$ /etc/init.d/td-agent status或者
$ systemctl start td-agent
$ systemctl status td-agent简单demo测试HTTP logs:
curl -X POST -d 'json={"json":"message"}' http://localhost:8888/debug.test
安装必要的插件:
$ /usr/sbin/td-agent-gem install fluent-plugin-elasticsearch
$ /usr/sbin/td-agent-gem install fluent-plugin-typecast
$ /usr/sbin/td-agent-gem install fluent-plugin-secure-forward
$ systemctl restart td-agent如果上面直接安装不了,则要gem插件(安装rubygems)。
4.3.2、配置td-agent
使docker生成的日志输出到elasticsearch,修改td-agent的配置
$ vi /etc/td-agent/td-agent.conf修改内容为如下(这里没有填写端口,默认使用9200端口)
@type forward
port 24224
bind 0.0.0.0
@type elasticsearch
logstash_format true
flush_interval 10s # for testing
host 127.0.0.1
重启td-agent:
$ systemctl restart td-agent启动docker镜像,这里使用alpine做测试:
docker run --log-driver=fluentd --log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}" alpine:3.3 echo "helloWorld"检查fluentd是否正常转发数据,检查td-agent日志,如果最后出现如下一行,则表明正常连接elasticsearch。/var/log/td-agent/td-agent.log中最后一行如下:
2017-12-26 00:40:37 -0500 [info]: #0 Connection opened to Elasticsearch cluster => {:host=>"127.0.0.1", :port=>9200, :scheme=>"http"}
2017-12-26 01:22:42.071896593 -0500 debug.test: {"json":"message"}
4.3.3、fluentd使用
td-agent默认将配置收集来自http的日志,并将日志转储到/var/log/td-agent/td-agent.log,如果需要配置fluent接收docker日志,则在/etc/td-agent/td-agent.conf中增加,并重启td-agent,systemctl restart td-agent
type stdout
配置docker使用fluent为log-driver,有两种方法,指定特定的容器或者配置docker daemon将所有容器日志均存储到fluent中。
方法1:指定容器
docker run --log-driver=fluentd --log-opt fluentd-address=myhost.local:24224
方法2: 设置全局log-driver
docker daemon --log-driver=fluentd
至此,已经成功将docker的日志交给fluent处理。
4.4、进入kibana创建索引
访问页面:http://localhost:5601/
点击“create”,即可看到如下设置:

5、Fluentd配置介绍
配置文件为vi /etc/td-agent/td-agent.conf,配置文件主要由以下指令组成:
1)source 决定输入源.
2)match 决定输出目的地.
3)filter 决定事件处理管道.
4)system 设置系统广泛的配置.
5)label 输出分组和筛选内部路由
6)@include 包括其他文件.
source: 输入源包括http和forward,http将fluentd转换为http端点以接收传入的http消息,forward将fluentd转换为TCP端点,以接受TCP包。当然,它可以同时出现。每个源指令必须包含一个类型参数,类型参数指定要使用的输入插件。
match: 告诉fluentd做什么,match指令使用匹配的标记查找事件,并处理它们。最常用的匹配指令是将事件输出到其他系统。Fluentd的标准输出插件包括文件file和转发forward。让我们将这些添加到配置文件中。每个匹配指令必须包含匹配模式和类型参数。只有带有与模式匹配的标记的事件才会被发送到输出目的地. 广泛的匹配模式应该在严格的匹配模式之后定义。
流程就是source 收集日志,然后由串联的 filter 做流式的处理,最后交给 match 进行分发。同时还可以用 label 将任务分组,用 error 处理异常,用 system 修改运行参数。日志存储的格式,根据源不同,比如源是docker的syslog,格式就是syslog的日志形式按配置修改,主要的格式化配置都在配置文件中的 format 这段配置里,主要采用正则表达式拆分数据到自定义的以 <> 包围起来的属性中。