机器学习(3)--随机森林
目录
一、集成算法
1、概述
2、集成思想
3、sklearn中的集成算法
二、随机森林
1、概述
2、RandomForestClassfier
2.1重要参数
3、红酒数据集,随机森林和决策树对比
3.1导入库
3.2建立决策树和随机森林
3.3随机森林的重要接口
3.4交叉验证
3.5重复十次交叉验证后
3.6剪枝策略
3.7对n_estimators进行迭代
一、集成算法
1、概述
将多个分类器集成起来而形成的新的分类算法。通过考虑多个评估器的建模效果,汇总得到一个综合的结果,以此来获得比单个模型更好的回归或分类表现。
2、集成思想
boosting(提升法):通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。它是不断的重复学习以达到最终的要求。常用的集成算法为GBDT和Adaboost。弱评估器间存在强依赖关系、必须串行生成的,用于减少偏差。
bagging(装袋法): 使用装袋采样来获取数据子集训练基评估器。最常用的集成算法原模型是随机森林。弱评估器间不存在强依赖关系、可同时生成的,用于减少方差。
stacking(结合法):通过一个元分类器或者元回归器来整合多个分类模型或回归模型的集成学习技术。用于提升预测结果。
3、sklearn中的集成算法
| ensemble.AdaBoostingClassfier | AdaBoost分类 |
| ensemble.AdaBoostingRegressor | AdaBoost回归 |
| ensemble.BaggingClassfier | 装袋分类器 |
| ensemble.BaggingRegressor | 装袋回归器 |
| ensemble.ExtraTreesClassfier | Extra-trees分类(超树、极端随机树) |
| ensemble.ExtraTreesRegressor | Extra-trees回归 |
| ensemble.GradientBoostingClassfier | 梯度提升分类 |
| ensemble.GradientBoostingRegressor | 梯度提升回归 |
| ensemble.isolationForest | 隔离森林 |
| ensemble.RandomForestClassfier | 随机森林分类 |
| ensemble.RandomForestRegressor | 随机森林回归 |
| ensemble.RandomTreesEmbedding | 完全随机树的集成 |
| ensemble.VotingClassfier | 用于不适合估算的软投票/多数规则分类器 |
二、随机森林
1、概述
随机森林是在决策树的基础上衍生出来的。决策树和随机森林的关系就是树和森林的关系。
通过增加决策树的个数,提升随机森林的准确率。
随机森林基本模型:
from sklearn import ensemble #导入ensemble库
rfc=ensemble.RandomForestClassifier() #建立随机森林模型
rfc=rfc.fit(Xtrain,Ytrain) #模型训练
score_r=rfc.score(Xtest,Ytest) #输出acc值2、RandomForestClassfier
sklearn.ensemble._forest.RandomForestClassifier
def __init__(self,
n_estimators: Any = 100,
*,
criterion: Any = "gini",
max_depth: Any = None,
min_samples_split: Any = 2,
min_samples_leaf: Any = 1,
min_weight_fraction_leaf: Any = 0.0,
max_features: Any = "sqrt",
max_leaf_nodes: Any = None,
min_impurity_decrease: Any = 0.0,
bootstrap: Any = True,
oob_score: Any = False,
n_jobs: Any = None,
random_state: Any = None,
verbose: Any = 0,
warm_start: Any = False,
class_weight: Any = None,
ccp_alpha: Any = 0.0,
max_samples: Any = None) -> None
2.1重要参数
| n_estimators | 随机森林中树模型的数量,默认为100 |
| criterion | 衡量不纯度指标,“gini”或“entropy” |
| random_state | 类似于random.seed,随机生成树种子 |
| max_depth | 树的最大深度,默认为None,即生成树所有叶节点不纯度为0,或者直到每个叶节点的所含样本量均小于参数min_samples_split值 |
| max_features | 限制分枝时考虑的特征个数,超过限制个数都会被舍弃,默认值为总特征数的开平方取整 |
| min_samples_split
|
一个中间结点要分枝为所需要的最小样本量,如果一个节点包含的样本量小于min_samples_split值,则该节点的分枝不会发生。 默认=2,可填整型或浮点型 输入的为浮点型作为分枝比例,即分枝所需最小样本量:输入模型数据集的样本量。 |
| min_sample_leaf | 一个叶节点要存在所需要的最小样本量,如果一个节点在分枝后的每个子节点中,必须包含至少min_sample_leaf个训练样本,否则该结点不能分枝。 默认=1,可填整型或浮点型 输入的为浮点型作为分枝比例,即分枝后叶节点所需最小样本量:输入模型数据集的样本量。 |
| min_impurity_decrease | 最小不纯度差,即根节点不纯度值与叶子结点的不纯度值至少为min_impurity_decrease值 |
| n_jobs | 训练和预测并行运行的作业数,默认为1。 输入值为-1,则表示使用整个处理器来运行。 |
| oob_score | 是否使用袋外样本来预测模型的泛化精确性,默认为False |
3、红酒数据集,随机森林和决策树对比
3.1导入库
from sklearn import tree #导入tree库
from sklearn import ensemble #导入ensemble库
from sklearn.datasets import load_wine #导入红酒数据集
from sklearn.model_selection import train_test_split #导入数据集分割函数3.2建立决策树和随机森林
wine=load_wine()
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
clf=tree.DecisionTreeClassifier() #建立决策树和随机森林
rfc=ensemble.RandomForestClassifier()
clf=clf.fit(Xtrain,Ytrain) #训练模型
rfc=rfc.fit(Xtrain,Ytrain)
score_c=clf.score(Xtest,Ytest) #生成acc值
score_r=rfc.score(Xtest,Ytest)
print(score_c,score_r)3.3随机森林的重要接口
rfc.apply(Xtest) #返回每个测试样本的分类结果rfc.predict(Xtest) #返回每个测试集样本所在叶子结点的索引rfc.feature_importances_ #返回测试集不同特征对随机森林的重要性rfc.predict_proba(Xtest) #返回每个测试样本对应的被分到每一类标签的概率, 概率越大的为其预测类别
3.4交叉验证
cross_val_score函数的参数cv,若为整数k则为k折交叉验证,即将数据集分成k分,轮流让其中一份作为测试集.
from sklearn.model_selection import cross_val_score #导入交叉验证函数
import matplotlib.pyplot as plt
rfc=ensemble.RandomForestClassifier(n_estimators=100)
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10)
clf=tree.DecisionTreeClassifier()
clf_s=cross_val_score(clf,wine.data,wine.target,cv=10) #注意第一个参数
plt.plot(range(1,11),rfc_s,label="random forest")
plt.plot(range(1,11),clf_s,label="decision tree")
plt.grid()
plt.show()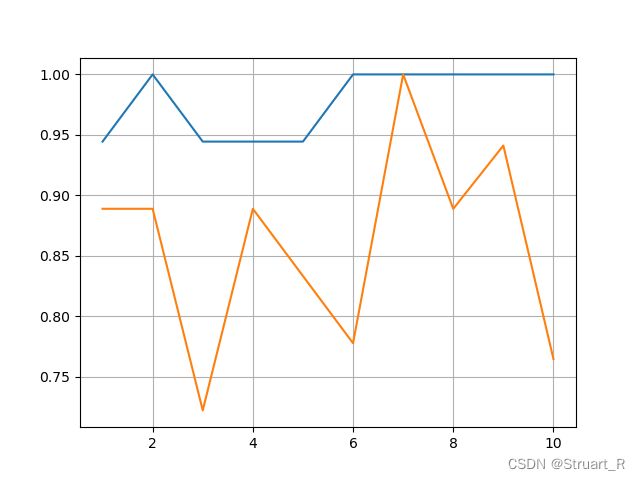
3.5重复十次交叉验证后
rfc_l=[]
clf_l=[]
for i in range(10):
rfc = ensemble.RandomForestClassifier(n_estimators=100)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean() #每一次十折交叉验证,取平均值
rfc_l.append(rfc_s)
clf = tree.DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1, 11), rfc_l, label="random forest")
plt.plot(range(1, 11), clf_l, label="decision tree")
3.6剪枝策略
3.6.1泛化误差
模型在未知数据上的表现可以用泛化程度来表示,泛化误差越大,模型效果越差。如下图所示,当模型太复杂,模型就会过拟合,泛化能力不够,泛化误差大。当模型太简单,模型就会欠拟合,拟合程度不足,泛化误差大。模型的复杂度追求泛化误差最小的点。

3.6.2调参顺序
n_estimators>max_depth>min_samples_leaf=min_sample_split>max_features
criterion看具体情况改变
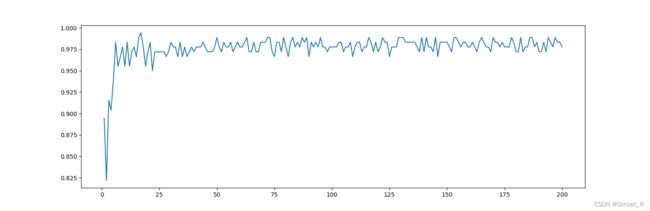
3.7对n_estimators进行迭代
score_e=[]
for i in range(200):
rfc = ensemble.RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
superpa.append(rfc_s)
print(f'十次交叉验证后最大的acc值:{max(score_e)},最大值索引:{score_e.index(max(score_e))}')
plt.figure(figsize=[20,5]) #图表长宽为20*5
plt.plot(range(1,201),score_e)
plt.show()