2021-3-13论文学习——SENet,StairNet,Generalized Focal Loss,R3Det,CARAFE
[1]Squeeze-and-Excitation Networks
论文地址:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/moskomule/senet.pytorch/blob/master/senet
论文发表于CVPR 2018,同时提交于IEEE TPAMI 2019

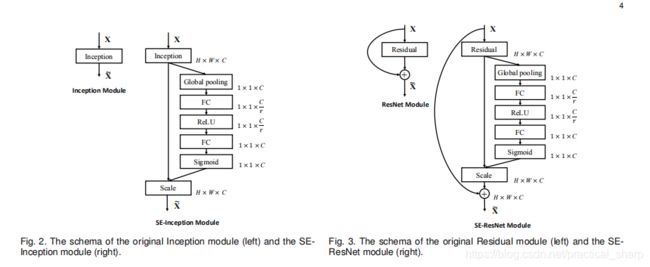
结构图
一个全局avg pooling得到11C的向量,然后通过一个MLP感知机得到进行线性变换的11C
向量。 再通过一个Sigmod函数进行激活。

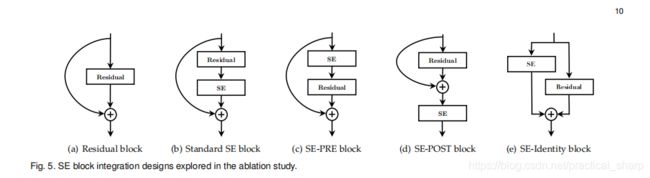
各种SE block的变体
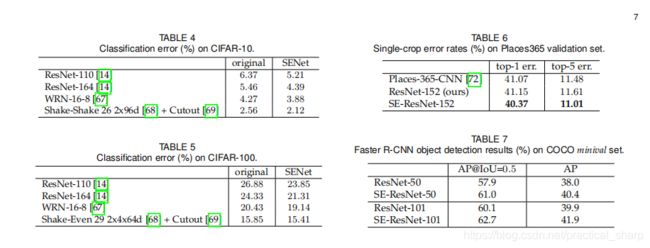
实验结果证明了SE net的有效性。
我认为其作用就是它对于通道施加了注意力机制,能够提取更加有用的信息。
Pytorch代码
import torch
from torch import nn
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
## 定义全局平均池化层
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)
## 定义一个MLP感知机
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x): # exsample x.size() = [8,128,256,256]
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c) ## [8,128]
print(y.size())
y = self.fc(y).view(b, c, 1, 1) # [8,128,1,1]
print(y.size())
return x * y.expand_as(x) # [8,128,256,256]
"""
x = torch.Tensor(8,128,256,256)
print(x.size())
se = SELayer(128,16)
print(se(x).size())
"""
[2]StairNet: Top-Down Semantic Aggregation for Accurate One Shot Detection
论文地址:https://arxiv.org/pdf/1709.05788.pdf
论文发表于 2018 IEEE Winter Conference on Applications of Computer Vision(WACV)

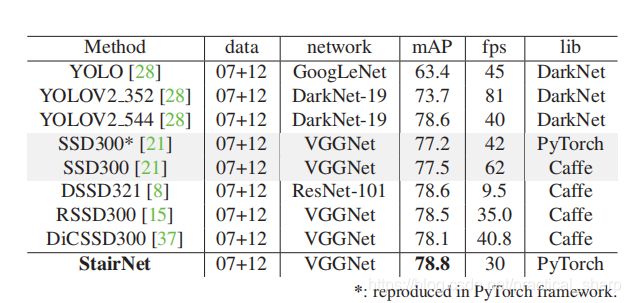
针对于单阶段目标检测算法对于小目标检测难的问题,提出了一种自上而下的语义增强方式,设计的算法成为StairNet,在VOC数据集上改进了SSD算法,性能超过了其他单阶段目标检测SOTA算法。
总结:改进版本的FPN+一些小trick
创新之处:
- 上采样模块使用反卷积自主学习而不是使用临近插值什么的;
- 在FPN中1X1和3X3 的卷积处加入relu和BN层组合成高效卷积;
- 针对于VOC数据集进行了聚类得到先验的anchor纵横比,除了SSD原有的{2,3}加入了一个1.6的纵横比。

代码在哪里?找呢,这是个问题;
StairNet的代码实验:以后补上
[3]Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
论文地址:https://arxiv.org/pdf/2006.04388.pdf
暂未发表,还是预印版
这篇论文全是公式,我还是辅助了知乎进行理解的,推荐:
https://zhuanlan.zhihu.com/p/147691786

用于单阶段目标检测算法的广义 focal loss
[4]R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object
论文地址:https://arxiv.org/pdf/1908.05612.pdf
论文收录于 Thirty-Five AAAI Conference on Artificial Intelligence (AAAI 2021)
pytorch代码地址:https://github.com/SJTU-Thinklab-Det/r3det-on-mmdetection

旋转目标检测是一项有挑战性的任务,因为难以定位多角度物体并且与背景准确和快速的分离。虽然已经取得了长足的进步,但在实际设置中,对于大宽高比,密集分布和类别不平衡的旋转目标检测仍然存在困难。
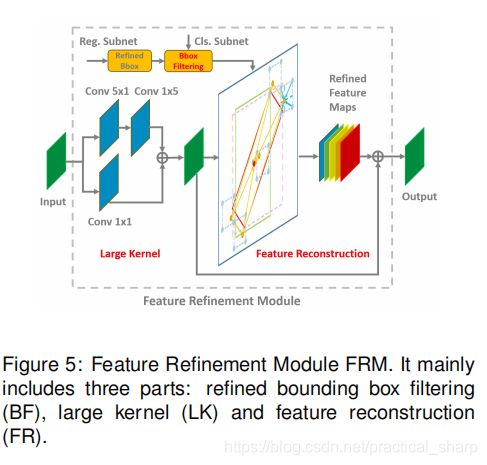
在这篇论文中,提出了一种快速,准确且端到端的的旋转目标检测器。考虑到现有精炼单级检测器的特征未对齐的缺点,这篇论文设计了一个特征精炼模块来获取更准确的特征以提高旋转目标检测性能。
特征精炼模块的关键思想是通过特征插值将当前精炼的边界框位置信息重新编码为对应的特征点,以实现特征重构和对齐。
在DOTA,HRSC2016和ICDAR2015数据集上进行的广泛实验显证明了这种算法的有效性。目前这篇论文的代码已开源。
遥感检测领域和文本检测领域面临的挑战:
- 大尺度的长宽比:比如舰船,桥梁,港口等;
- 密集排列的物体,比如飞机场的飞机,港口的轮船等;
- 类别极不平衡,比如DOTA数据集中的15个类别物体的数量分布非常不平衡;
主要创新点:
- 为了提高大尺度高宽比的定位精度,采用refine的单阶段目标检测算法;
- 作者发现水平框能得到更大的召回率,旋转框能得到更精确的定位,作者使用两种定位框相结合的方法进行回归,首先在第一阶段使用水平框提高召回率,在refine阶段使用旋转框提高定位精确率;
- 作者认为双阶段目标检测算法不管使用ROI pooling还是ROI align都实现了对于定位特征的对齐,但是在单阶段目标检测算法中这一问题很难解决,存在着严重的特征不对齐问题,极大的限制了分类和精炼阶段回归的可靠性。作者设计了一个特征精炼模块(FRM),该模块使用特征插值来获取精炼Anchor的位置信息并重建特征图实现特征对齐。FRM还可以在第一阶段之后减少精炼边界框的数量,从而加速模型;
- 作者将上述技术结合在一起,成为R3Det,在三个旋转目标公开数据集DOTA,HRSC2016,ICDRA2015数据集上实现了SOTA性能。
相关工作:
相关工作里面介绍了双阶段目标检测算法,单阶段目标检测算法,旋转目标检测算法和refine目标检测算法。
旋转目标检测器
遥感和文本检测是旋转目标检测器的主要应用场景。由于遥感影像场景的复杂性以及拥有大量小的,杂乱和旋转的目标,双阶段旋转目标检测器仍然是最鲁棒的选择,例如ICN,ROI-Transformer和SCRDet。但是它们使用了相对复杂的结构导致速度较慢。对于文本检测,有许多有效的旋转目标检测方法,包括双阶段的方法(R2CNN,RRPN,FOTS)和单阶段的方法(EAST,TextBoxes)。
refine目标检测算法
为了获得更好的定位精度,许多级联或者精炼目标检测器被提出。Cascade RCNN,HTC和FSCascade在第二阶段执行了多次分类和回归,极大的提高了分类的准确性和定位精度。
同样的想法也适用于单级检测器,例如RefineDet。和双阶段检测器不同,后者使用ROI Pooling或ROI Aligin进行特征对齐。
在特征对齐方面,当前的精炼目标检测器不能很好的解决这个问题。精炼单阶段目标检测器的一个关键要求是保持一个全卷积网络结构,这可以获得速度优势,但是诸如ROIAlign之类的方法无法满足要求,因此不得不引入全连接层。
尽管一些工作使用可变形卷积进行特征对齐,但其偏移参数通常是通过学习预定义Anchor和精炼Anchor之间的偏移量来获得的。这些基于可变性卷积的特征对齐方法的一个目的是扩大感受野,这个感受野往往是不明显并且不能确保特征真正对齐。
特征对齐仍然限制着精炼单级目标检测器的性能。与这些方法相比,本文的方法通过计算可以清楚的找到对应的特征区域,并通过特征图重建达到特征对齐的目的。
The Proposed Method
3.1. Rotation RetinaNet
介绍旋转RetinaNet。
这一点需要在RetinaNet的基础上,进行代码层面的掌握,还得实验,以后做了实验挂在这里。
作者受SCRDet的启发,我们提出了一个可推导的近似的Skew IOU损失
3.2. Refined Rotation RetinaNet
refine检测器的总的损失函数的定义:由多个阶段的损失加权求和。

特征refine模块,实现和双阶段目标检测算法一样的ROI align的功能:特征对齐
实验结果
实验结果表格看论文比较清楚。
结论
这篇论文针对航空和文本数据集中常常出现的大长宽比,密集分布和类别极度不平衡的旋转目标提出一种端到端的精炼旋转目标检测器。
考虑到当前单级精炼检测器中有特征未对齐的缺点,本文设计了一个特征精炼模块(FRM)来提高检测性能,这在长尾数据集中特别有效。
FRM的主要思想是通过特征插值将当前精炼的边界框位置信息重新编码到对应的特征点上,以实现特征重构和对齐。
论文在DOTA,HRSC2016和ICDAR2015数据集上的进行了丰富的消融实验和对比实验,证明了本方法可以高效的实现SOTA的检测精度。论文已经开源,感兴趣的同学可以结合源码进一步理解此算法。
代码实现,以后补上关于代码实验的博客
知乎解说:https://zhuanlan.zhihu.com/p/108255937
有点难度。
推荐一个网站:https://paperswithcode.com/task/object-detection-in-aerial-images
[5]CARAFE: Content-Aware ReAssembly of FEatures
论文地址:https://arxiv.org/pdf/1905.02188.pdf
论文发表于ICCV 2019
代码开源:https://github.com/myownskyW7/CARAFE

作者提出了一个轻量级的通用上采样算子 CARAFE,相对最近邻和双线性等上采样算子,在不同任务中都取得了显著的提升,同时只引入很少的参数量和计算代价。
上采样方法大总结:
- 基于线性插值的上采样
- 基于deep learning的上采样
- unpooling的上采样
基于线性插值的上采样
比如最邻近采样,双线性插值,双三次插值,这些都是本科数字图像处理上面的算法,非常简单。不再赘述。
基于深度学习的上采样
- 反卷积,deconv(“Learning deconvolution network for semantic segmentation” ICCV 2015)
- pixelshuffle(CVPR 2016提出pixelshuffle进行视频超分辨,CVPR2018有一篇STDN也是采用的这个进行上采样并取名为Scale Transfer layer)
- Dupsampling(“Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation” CVPR 2019)
- Meta-Upscale(“Meta-SR: A Magnifification-Arbitrary Network for Super-Resolution” CVPR 2019)
- CAPAFE(ICCV 2019,也就是这篇论文)
其中Dupsampling,Meta-Upscale这两篇顶会论文我还没学习过,下周学习了再附上学习博客的链接。
Motivation
最近邻或者双线性上采样仅通过像素点的空间位置来决定上采样核,并没有利用到特征图的语义信息,可以看作是一种“均匀”的上采样,而且感知域通常都很小(最近邻1x1,双线性 2x2)。Deconvolution算子的上采样核并不是通过像素间的距离计算,而是通过网络学出来的,但对于特征图每个位置都是应用相同的上采样核,不能捕捉到特征图内容的信息,另外引入了大量参数和计算量,尤其是当上采样核尺寸较大的时候。Dynamic filter 对于特征图每个位置都会预测一组不同的上采样核,但是参数量和计算量更加爆炸,而且公认比较难学习。
所希望的上采样算子应该具备以下几个特性:
- Large receptive field:需要具有较大的感受野,这样才能更好地利用周围的信息。
- Content-aware:上采样核应该和特征图的语义信息相关,基于输入内容进行上采样。
- Lightweight:不能引入过多的参数和计算量,需要保持轻量化。
To demonstrate the universal effectiveness of CARAFE ,we conduct comprehensive evaluations across a wide range of dense prediction tasks, i.e., object detection, instance segmentation, semantic segmentation, image inpainting, with mainstream architectures. CARAFE can boost the performance of Faster RCNN [30] by 1.2% AP in object detection and Mask RCNN [8] by 1.3% AP in instance segmentation on MS COCO [19] test-dev 2018.
方法描述

在目标检测上的实验结果

Pytorch代码
这是github非官方实现的代码,我进行了测试。完美运行,并理解注释。
import torch
from torch import nn
from torch.nn import functional as F
from collections import OrderedDict
# 这一部分 完成的是上采样核预测模块, 即论文图中的kernel prediction module
class KernelPredictionModule(nn.Module):
def __init__(self, input_channel, channel_cm=64, kernel_up=5, kernel_encoder=3, enlarge_rate=2):
super(KernelPredictionModule,self).__init__()
self.input_channel = input_channel
self.channel_cm = channel_cm
self.kernel_up = kernel_up
self.kernel_encoder = kernel_encoder
self.enlarge_rate = enlarge_rate
self.channel_compressor = nn.Sequential( # 通道压缩,channel压缩到Cm的卷积核大小为1
OrderedDict([
("compressor_conv" , nn.Conv2d(self.input_channel, self.channel_cm,1)),
("compressor_bn" , nn.BatchNorm2d(self.channel_cm)),
("compressor_relu" , nn.ReLU(inplace=True))
])
)
self.context_encoder = nn.Sequential( # 通道拓宽的卷积核 建议为kernel_size = 5 即kernel_up = 5
OrderedDict([
("encoder_conv" , nn.Conv2d(self.channel_cm, # 输入通道数为Cm
self.enlarge_rate*self.enlarge_rate*self.kernel_up*self.kernel_up,# 输出通道数为rate^2*kup^2 ,enlarge_rate是上采样倍数,kernel_up是通道拓宽部分的卷积核
self.kernel_encoder,padding=int((self.kernel_encoder-1)/2))), # padding通过输入输出的尺度进行计算
("encoder_bn" , nn.BatchNorm2d(self.enlarge_rate*self.enlarge_rate*self.kernel_up*self.kernel_up)),
("encoder_relu" , nn.ReLU(inplace=True))
])
)
self.kernel_normalizer = nn.Softmax(dim=-1) # 图中的kernel_normalizer 即softmax归一化
def forward(self, x):
b,c,w,h = x.shape
x = self.channel_compressor(x) # 首先利用1*1的卷积进行通道压缩
x = self.context_encoder(x) # 然后利用5*5的卷积进行通道拓宽
x = x.view(b,self.kernel_up*self.kernel_up,self.enlarge_rate*w,self.enlarge_rate*h)# batch*(kup^2)*(rate*w)*(rate*h) # 然后将通道维度在空间维度展开
x = self.kernel_normalizer(x) # 最后进行softmax归一化
return x
# CARAFE 上采样 类
class Carafe(nn.Module):
def __init__(self, input_channel, channel_cm=64, kernel_up=5, kernel_encoder=3, enlarge_rate=2):
"""
The Carafe upsample model(unoffical)
:param input_channel: The channel of input 输入特征图的channel
:param channel_cm: The channel of Cm, paper give this parameter 64 首先进行通道压缩之后的 通道数Cm
:param kernel_up: The kernel up, paper give this parameter 5 通道拓宽
:param kernel_encoder:The kernel encoder, paper suggest it kernel_up-2, so 3 here
:param enlarge_rate: The enlarge rate , your rate for upsample (2x usually) 上采样倍数,一般2倍上采样
"""
super(Carafe, self).__init__()
self.kernel_up = kernel_up
self.enlarge_rate = enlarge_rate
self.KPModule = KernelPredictionModule(input_channel,channel_cm,kernel_up,kernel_encoder,enlarge_rate)
def forward(self, x):
# KernelPredeictionModule : cost 0.7175s
kpresult = self.KPModule(x) # (b,kup*kup,e_w,e_h)
############Context-aware Reassembly Module########################
######## Step1 formal_pic deal : cost 0.1164s # 对于输出特征图中的每个位置,我们将其映射回输入特征图
x_mat = self.generate_kup_mat(x)
######## Step2 kernel deal : cost 0.001s
channel = x.shape[1]
w_mat = self.repeat_kernel(kpresult,channel) # 取出以之为中心的kup*kup的区域,
######## Step3 kernel mul : cost 0.0009s
output = torch.mul(x_mat,w_mat) # 取出以之为中心的kup*kup的区域,和预测出的该点的上采样核作点积,得到输出值
######## Step4 sum the kup dim : cost 0.0002s
output = torch.sum(output, dim=2)
return output
# 对于输出特征图中的每个位置,我们将其映射回输入特征图
def generate_kup_mat(self,x):
"""
generate the mat matrix, make a new dim kup for mul
:param x:(batch,channel,w,h)
:return: (batch,channel,kup*kup,enlarged_w,enlarged_h)
"""
batch, channel, w ,h = x.shape
# stride to sample
r = int(self.kernel_up / 2)
# pad the x to stride
pad = F.pad(x, (r, r, r, r))
# x_mat = torch.zeros((batch, channel, self.kernel_up**2 , w, h)).cuda()
x_mat = torch.zeros((batch, channel, self.kernel_up**2 , w, h))
for i in range(w):
for j in range(h):
pad_x = i + r
pad_y = j + r
x_mat[:, :, :, i, j] = pad[:, :, pad_x - r:pad_x + r + 1, pad_y - r:pad_y + r + 1]\
.reshape(batch, channel, -1)
x_mat = x_mat.repeat(1, 1, 1, self.enlarge_rate, self.enlarge_rate)
# each part of the stride part the same!
return x_mat
# # 取出以之为中心的kup*kup的区域,相同位置的不同通道共享同一个上采样核。
def repeat_kernel(self,weight,channel):
"""
Generate the channel dim for the weight
repeat the Kernel Prediction Module output for channel times,
and it can be mul just like the depth-width conv (The repeat on the batch dim)
:param weight: (batch,kup*kup,enlarged_w,enlarged_h)
:param channel: the channel num to repeat
:return: (batch,channel,kup*kup,enlarged_w,enlarged_h)
"""
batch, kup_2, w, h = weight.shape
# copy the channel in batch
w_mat = torch.stack([i.expand(channel, kup_2, w, h) for i in weight])
# each channel in batch is the same!
# print(torch.equal(w_mat[0, 0, ...], w_mat[0, 1, ...]))
return w_mat
"""
if __name__ == '__main__':
import os
# os.environ["CUDA_VISIBLE_DEVICES"] = '0'
x = torch.rand((1,2,26,26))
model = Carafe(input_channel=2,channel_cm=64)
print(x)
out = model(x)
print(out.size())
print(out)
"""