IDE /字符串 /字符编码与文本文件(如cpp源代码文件)
文章目录
- 概述
- 文本编辑器如何识别文件的编码格式
- 优先推测使用了UTF-8编码?
- 字符编码的BOM字节序标记
- 重分析各文本编辑器下的测试效果
-
- Qt Creator的文本编辑器
- 系统记事本
- VS的文本编辑器
- Notepad++
- 编译器与代码文件的字符编码
- ANSI编码
- 其他
概述
前期在整理 《IDE/VS项目属性中的 <字符集> 配置项》 和 《IDE /Qt Creator 文本编辑器之文件编码设置》和 《IDE /C4819: 该文件包含不能在当前代码页(936)中表示的字符》等文章的过程中,做了不少关于字符编码的测试,解决了一些问题,但是也让我有了些新的问题和思考。简单但麻烦的测试让我有点烦躁,总觉得有什么根本性的知识点,我没有get到,致使我在整理如上文章时很不舒服。于是我暂停了如上文章的整理,试图先找出如它们共同关注的问题。初步分析后,我把这些问题的总和称作 “字符编码与文本文件编辑器之间的协同运作机制”。具体的可能要关注:
文本编辑器是如何识别文件的编码类型的?靠谱吗?
为什么删除文本文件中的全部中文字符后,其又从 GB2312 “变回了” UTF-8 编码格式?
BOM因何而生,是如何运作的?
QtCreator 和 VS 中的文本编辑器,可以“篡改”源代码文件的编码格式,这似乎不太合理!
系统记事本以及Notepad++等文本编辑器是查看或修改字符编码的基础工具,你可能了解的并不够!
文本编辑器如何识别文件的编码格式
如下是我在踩了很多坑之后才明白的,把它提到前面来讲,这样有些原本晦涩问题就好解释了。
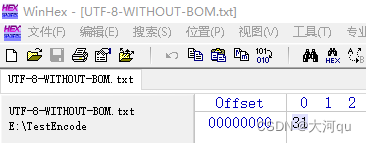
如上图,Notepad++中选择使用最常见的UTF-8编码格式(文中UTF-8均代表无BOM格式,带BOM的我们将标称做UTF-8-BOM),在文本文件中只输入一个数字1,保存,使用WinHex打开查看其二进制存储。只有一个0x31字节值,没有其他的。你能通过0x31判断出这个文件使用了什么编码格式吗?你不能,大神也不能!
目前并没有一种通用的、百分之百准确的编码识别技术。因为在没有明确的标识信息或者上下文的情况下,仅仅根据字节序列等信息来确定文件的编码是具有一定难度的,是不太可能的。不同的文本编辑工具可能使用不同的编码识别技术。一种常见的方法是根据文件的字节序列进行推测和猜测,尝试识别文件的编码方式。这包括检查文件是否有 BOM(字节顺序标记),以及通过分析字符分布和编码规律来猜测文件的编码。然而,由于某些编码的相似性或文件的特殊性,这种猜测并不总是准确的。
因此,在处理文件编码时,最好的方式是结合其他信息进行判断,比如文件的来源、文件的约定等。或者如果可行的话,在文件中显式地包含编码信息,如采用 BOM 或添加特定的编码声明。这样可以确保编码的准确性和可靠性。
以Notepad++为例,
Notepad++会根据文件的开头几个字节来识别编码方式。它会检查文件是否包含字节顺序标记(BOM,Byte Order Mark),如果文件包含BOM,Notepad++会使用BOM中指定的编码方式。如果文件没有BOM,Notepad++会根据字节序列的分布模式和特征来尝试猜测编码方式。它会使用一系列的编码检测算法,比较文件在不同编码方式下的字节序列与预定义的模式之间的相似性,从而推断出最有可能的编码方式。这种编码识别并不是完全准确的,特别是对于一些特殊或混合编码的文件,可能会存在识别错误的情况。因此,在处理文件时,建议根据实际情况选择适当的编码方式,并进行必要的确认和调整。
优先推测使用了UTF-8编码?
前期的测试中,记录了一些规律:通常在IDE下被新建出来的代码文件中若不包含中文字符,则它们始终被记事本或Notepad等文本编辑器软件加载识别为UTF-8无BOM编码格式;我们使用记事本或Notepad新建的文件,在其为空或者输入任何中文字符之前,无论你保存和重新加载多少次,它们也都始终显示为UTF-8无BOM格式。
这难道是因为UTF-8过硬的威望吗?非要先创建为UTF-8,然后伺机而动,再改变其他编码格式?
事实上,UTF-8字符编码格式只是文本编辑器软件给当前这个文件贴上的一个标签。因为,对于一个文本文件,在其没有BOM、没有其他外部描述的情况下,任何使用者都不知道它是何种编码的;文件自己也不知道它是啥编码的,因为它的造物主并没有告诉它它是谁。字符编码不是文本文件的属性,也不是文本编辑器的属性,而是介于两者之间的一种约定。当文本编辑器尝试加载文件时,由于文件不能自述其到底使用了何种约定,其只能使用一定的算法来进行推测,优先推演出来的那个类型,就被显示在了文件编辑器软件中。
是的,只能去猜测,
一个磁盘上的文本文件就那里存放着,EncodeA能加载它显示为有意义的字符内容,我们就可以说他是EncodeA编码类型。EncodeB能加载它显示为有意义的字符内容,我们就可以说他是EncodeB编码类型。
对于只包含ASCII字符的文本文件,主流的多种编码格式通常都可以正确的加载它,且加载结果完全一致。即使是包含中文字符的文本文件,我觉得如果经过非常刻意地设计,甚至EncodeM和EncodeN都可以加载它为有意义的内容,只不过此时不同的编码方式会将文件加载成不同的字符内容。写到这里,我想起了 “菩提本无树,明镜亦非台。本来无一物,何处染尘埃”。从早些年一开始的时候,就把字符编码这个事情看的过于神秘过于复杂啦。文件的编码格式格式就是一种约定,这种约定告诉你,该如何去正确的将它们显示为合理的字符。你甚至可以自己去定义这种约定,比如 0x01代表"中",0x02代表"国"。
确实是UTF-8具有优先被尝试的机会,
验证过程,我们使用Notepad++新建两个文件,然后在 编码(N) 菜单中均选择使用ANSI编码,如下图,
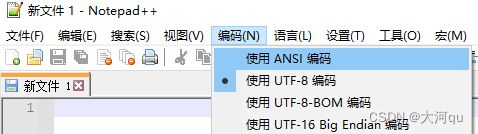
然后在第一个文件中输入 “//abc”,在第二个文件中输入 “中国汉字”,分别将它们保存为 text1.txt 和 text2.txt 文本文件。使用记事本或Notepad++重新打开加载它们,可以发现,text1.txt 编码格式 “变回了” UTF-8格式,而 text2.txt 显示为 ANSI 格式。
在《IDE /Qt Creator 文本编辑器之文件编码设置》一文中,我当时觉得上述 “变回UTF-8” 的现象是神奇的。到这里我们就明白其中的原因啦。原来,这只是文本编辑器尝试认定它为UTF-8时,没有发现什么异常,便盖棺定论了。本质上 GB2312、UTF-8等主流字符编码,都完全兼容ASCII字符集,所以当一个文本文件中只用ASCII字符时,任何主流编码都能无异常的加载它,但是文本编辑器优先使用UTF-8来进行尝试,故此UTF-8便优先上位。
字符编码的BOM字节序标记
BOM,全称为字节顺序标记(Byte Order Mark),是一种特殊的字符序列,用于标识文本文件中的字节顺序和编码方式。BOM最初是为了使用Unicode字符集的文件而设计的,因为Unicode编码支持多种字节序,如UTF-16的大端序和小端序,因此需要一种机制来标识文件的字节顺序。然而随着时间的推移,BOM的使用已经扩展到其他编码方案,如UTF-8、UTF-32等。在这些编码方案中,BOM的含义和用途可能有所不同。那些非Unicos的多字节编码体系,如GB2312,是没有字符编码BOM这么一说的。
UTF-8的BOM由三个字节表示,分别是0xEF, 0xBB, 0xBF。UTF-16 编码的BOM由两个字节表示, 0xFFFE 表示大端序、0xFEFF表示小端序。如下测试中,使用Notepad++,分别构建 UTF-8-BOM.txt 和 UTF-16-BE.txt 文本文件,使用的编码格式如文件名称所示,其文本内容都只输入一个数字1,使用WinHex打开,

需要注意的是,使用UTF-8或UTF-16编码文件都是可以不包含BOM的。对于UTF-8编码,大多应用程序和系统都不使用BOM,因此对于UTF-8编码来说,BOM是可选但不推荐使用的。 对于UTF-16编码,一般推荐使用BOM,但是有些应用程序或操作系统可能不在UTF-16文件中包含BOM,而是假设文件使用特定的大端或小端字节顺序中的一个。
重分析各文本编辑器下的测试效果
在着手写本文之前,整理摘要中提到的那些文章额过程中,我已对系统记事本、Notepad++、VS文本编辑器、Qt Creator 文本编辑器,做了不少的测试,有了一丁点心得。再结合上几个章节新get到的新知识点,将重新分析当时的一些测试现象,以便让神奇不再神奇。
Qt Creator的文本编辑器
迫使我较为深入的来研究学习字符编码相关问题的,正是Qt Creator集成开发环境下遇到的多个问题,尤其是 Qt Creator + MSVC编译器组成的集成开发环境的搭建和使用过程中遇到的那些。
无论你为QtCreator文本编辑器文件编码配置了GB2312编码还是UTF-8编码,由工程创建过程或新建类等过程触发而创建的源代码文件,都会被Notepad++识别为UTF-8编码。但我们也注意到,这些文本文件统统的是不包含任何的中文字符的。现在我们可以轻松理解它,正是因为全都为ASCII字符,Notepad++优先使用UTF-8对其尝试加载,因为异常,便盖棺定论。
这里我们可以大胆的猜测,若将QtCreator文本编辑器的文件编码配置成GB2312编码,QtCreator本意上在创建过程就想要使用GB2312编码的,奈何,这里的创建过程无法包含进任何中文字符去,因此无法验证。
不必纠结,那没有意义,我们只要明确:在将IDE配置为GB2312编码的情况下,只要有中文输入进去,QtCreator文本编辑器便会以GB2312编码来存储代码文件中的任意中文字符;若将IDE配置为UTF-8编码,则只要有中文字符输入进去并保存,QtCreator文本编辑器便会以UTF-8编码来存储代码文件中的任意中文字符。
其实更合理的理解,更抽象的总结描述,应该是这样的:
在QtCreator文本编辑器配置的文件编码格式是被用作代码文本文件的默认加载方式的,如果加载过程没有异常,则后续的保存过程,都将以此编码格式进行。QtCreator文本编辑器没有改变文件编码类型的功能,但是会进行编码检查,然后使用默认编码格式加载时遇到无法解析的编码值,会告警,进而提示你选择新的编码方式重新载入。如果没有告警提示,便算是加载成功。
系统记事本
在 Windows 操作系统中,记事本(Notepad)是一个基本的文本编辑器应用程序,它通常随操作系统安装。在一些版本较高或较商用的系统中,其记事本程序是可以在右下角展示文件的编码格式的,
![]()
— 20230701 --Begin–
在《IDE/VS项目属性中的 <字符集> 配置项》整理过程中的某个测试阶段,我得出了如下荒谬的结论:任何编码格式的文件,只要经过OS记事本编辑,并输入了汉字字符,文件的编码格式都变成ANSI编码。当时肯定是哪个步骤上自己耍了自己,因为即使从理论上分析,这也是不可能的。细想若OS记事本真有此功能,那实在是太危险了,只是从你走了一遭,你却彻底改变了我。
我还是重新验证了下,使用Notepad++建立了如下4个不同编码的文件,并分别输入以下内容后保存,
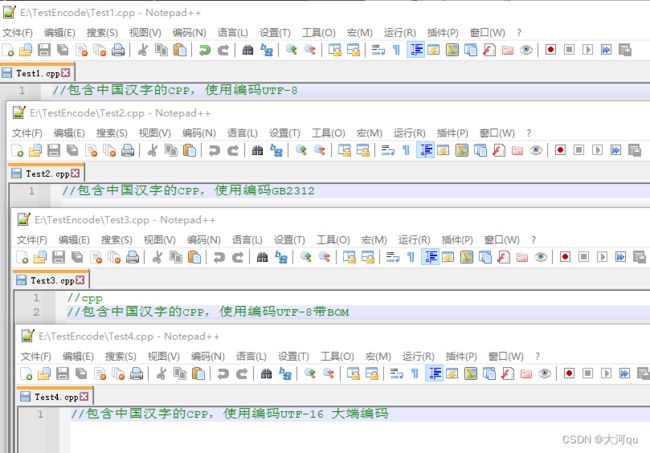
使用OS记事本,分别在上述4个文件中编辑添加中文字符串 “//我是大河”,然后保存,要注意的是文件中本来就含有中文。使用Notepad++重新打开查看它们的编码格式,可以发现,它们的编码格式并没有变化。
再重新新建4个文件,依然通过Notepad编码菜单分别选择使用上述上图所示的编码格式,保存文件名称分别为 TesstA/B/C/D.cpp。这回只先输入英文字符,保存后关闭。
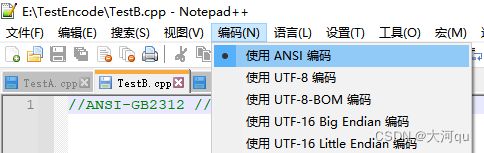
同上,使用记事本分别编辑添加中文字符串 “//我是大河”,然后保存。使用Notepad++重新打开查看它们的编码格式,可见,TestA/C/D,保持了原有的文件编码格式。而TestB.cpp 从ANSI编码 "变回“ UTF-8 编码。
— 20230701 --End–
— 20230712 --Begin–
嘿,此刻相比于10天前,我们有了新的知识支撑,
结合BOM那一节的讲述,UTF-8-BOM编码 和 UTF-16-BE 编码,都是有BOM标识的,因此text3和text4的即使在只有ASCII字符的情况下,也不会再被识别为UTF-8无BOM类型。
当我们使用记事本打开TestB.cpp时,该文件被是被为UTF-8,这正符合我们在 “优先推测文件使用了UTF-8编码” 这一章节的描述。而由于记事本是以UTF-8来正确加载和显示了TestB.cpp文件,因此后续的保存工作,也将以此编码格式进行,而不是以那个早就没有蛛丝马迹的曾经想作用于它的GB2310编码格式。系统记事本的这个行为与QtCreator文本编辑器的保存行为是完全一致的,可以将它们表现出来的此规律,相对统一的描述为:文本编辑器以什么编码正确打开加载了文本文件,便会以此编码保存后续用户编辑的所有内容。
— 20230712 --End–
VS的文本编辑器
在 《IDE/VS项目属性中的 <字符集> 配置项》的相关测试过程中,有一个小插曲,当时没理解,
在VS项目中新建ClassX类(生成的文件没有中文字符串),加载显示为UTF-8编码,现在这些都可以很好理解。但当时,我在 ClassX.h 中输入 “//中国”,保存后,使用Notepad++查看识别出来的编码格式是"斯拉夫语",且在Notepad++编辑页面显示为乱码,但在VS编辑器中显示是正常的。我继续在VS编辑器中将上述注释修改为“中国汉字”,再保存,重新打开查看其编码,可见文件编码称为GB2312,当时没有搞明白这是什么情况?
现在基本可以理解为:"中国"这两个字的编码在斯拉夫语编码中也是存在的,而Notepad++先尝试了这种编码来解析文本文件。当汉字变多时,Notepad的识别算法有了更多的参考依据,从而将ClassX.h识别为本地编码的文件,即识别为ANSI-GB2312编码格式。
另外在 《IDE/VS项目属性中的 <字符集> 配置项》文中,我们已经验证了,VS项目属性中字符集配置,与其文本编辑器的行为是没有半毛关系的。该配置不会影响代码文件的默认加载方式,也不会影响文件保存时的字符编码方式,它也不是源字符集设置、也不是执行字符集设置,而只是影响了UNICODE宏的定义,进而决定接口上是使用宽字节字符串还是多字节字符。
默认情况下,VS编译器不能正确加载 UTF-8无BOM的代码文件,除非你设定了/source-charset :utf-8。进一步的探究,将返回到《IDE/VS项目属性中的 <字符集> 配置项》博文中继续,敬请参考。
Notepad++
Notepad++是一个开源项目,其源代码托管在GitHub上,可以在GitHub仓库中找到。前阵子网传其在原则性问题上有点作妖,因此在码云上又出来个Notepad–的项目。都是开源的,有机会可以去看看其在字符编码识别这一块的代码实现。Notepad++ 的字符编码识别原理的一般步骤:
1、检查文件的 BOM (字节顺序标记),若存在则根据 BOM 的类型确定文件的编码。
2、使用统计信息进行猜测。如果文件没有 BOM,Notepad++ 将根据文件内容的统计信息进行猜测,将其与已知的字符编码进行匹配。根据匹配结果和一些启发式算法,Notepad++ 可能会猜测文件使用的字符编码。
3、用户手动指定编码。如果 Notepad++ 无法准确识别文件的编码,它将提示用户手动选择适当的编码。
需要注意的是,字符编码的识别并非是一个绝对准确的过程,尤其是对于没有明确标识编码的文件。因此,有时候字符编码的自动识别可能会出现错误。在这种情况下,用户可以手动选择正确的编码以确保文件内容正确显示。
编译器与代码文件的字符编码
在《IDE/VS项目属性中的 <字符集> 配置项》写了个简单的测试用例,如下,
#include 在那篇文章中,我们重点从”VS字符集配置是否会影响文本编辑器行为 “这个角度上做出了分析。这里,我们将重点从 “VS编辑器是使用何种编码来解析代码文件” 这个角度上,重新分析测试过程中的现象。
在 设置执行字符集 这篇文章中找到了确切的VS如何加载代码文件的过程:

其实上述相关文件已经全部在 《IDE/VS项目属性中的 <字符集> 配置项,它到底是干什么用的?》文中讲明白啦。主要参考microsoft 设置源字符集、设置执行字符集、将源字符集和执行字符集设置为 UTF-8 等官方帮助文档。
以MSVC为例,正式编译过程前,编译器需要以一定的字符编码来读取源代码文件,并将其中的字节序列解析为相应的字符序列。这样编译器才能正确理解和处理源代码中的字符、字符串和符号,之后才能进行词法和语法分析等编译过程的其他步骤。编译器读取源代码的过程是独立于文本编辑器的。在这个过程中,
Visual Studio会检测字节顺序标记BOM,来确定源文件是否使用编码的Unicode格式,如UTF-16或UTF-8。如果没有找到字节顺序标记,源文件将被假定为使用当前用户代码页进行编码,除非通过 /source-charset 选项指定了字符集名称或代码页。
“编译过程”中在上述提到的加载代码文件时会用到字符编码,这通常称为源字符集设置。还有一个执行字符集设置,必须对比着来理解,在上述官网文章中也有较详实的说明,总结如下:
在将源代码编译位可执行文件时,编译器会将源代码中的字符转换成可执行程序中的二进制数据。由于不同字符集采用不同的编码方式,因此在编译时必须确定所使用的编码方式,以便程序运行时可以正确读取和显示字符。细细品味,源字符集和执行字符集,它们在编译过程的使用目的是相反的。前者是将字符转换为二进制数据,而后者讨论的是如何将二进制数据加载为字符。
ANSI编码
在其他的文章中,我们讲述了大部分的编码格式。这里我们重点说一下ANSI这种编码格式。
ANSI编码不是一个具体的字符集,而是表示一种字符编码的概念。具体使用哪种字符集来实现ANSI编码,取决于操作系统和软件的实现。在不同的环境中,ANSI编码可能指代不同的字符集。在 Windows 系统中,“ANSI 编码” 这个术语通常用于指代特定的默认本地编码。这个默认的本地编码是根据操作系统和区域设置来确定的。对于区域设置为中国的 Windows 系统,其默认的 ANSI 编码格式通常是 GBK(或称 GB2312)。
通常使用 0x00-0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80-0xFFFF来编码,即扩展的ASCII编码。为使计算机支持更多语言,通常使用 0x80~0xFFFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文Windows操作系统中,ANSI 编码代表 GB2312编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 JIS 编码。
从ANSI编码这个定义维度上来看,那么字符集可能要分为3个大类,ASCII、ANSI、UNICODE。
其他
还有一些问题,我没有十分确定的搞清楚,如:
输入法、剪切板等传递的应该是字符,不是字符编码把?否则你也怎么可能在不同编码的文件中来回复制文本。
控制台、IDE调试输出窗口、UI界面等都应该算是显示设备,它们的运行过程中,字符编码扮演了怎样的角色?
还有qDebug() 中文字符串乱码问题等,
这些问题的草稿也都存好多年了,加油,骚年!