Java多线程和流的应用
最近看到了一个例子,是使用多线程的方式下载文件,感觉很有趣,探索了一下,并且尝试了使用多线程进行本地复制文件。写完之后,发现了这两个其实很相似,无论是本地文件复制,还是网络多线程下载,对于流的使用都是一样的。对于本地文件系统来说,输入流就是从本地文件系统的一个文件来获取,对于网络资源来说,是从远处服务器上的一个文件来获取。
注: 虽然这个多线程下载的代码,很多人都写过了,不过应该不是所有人都能理解吧,我这里就再写一遍,哈。
使用多线程的一个显而易见的好处就是:利用空闲的 CPU,加快速度。 但是注意不是线程越多越好,虽然好像n个线程一起下载,每个线程下载一小部分,下载时间就会变为1/n 了。这是很浅显的认识,就好像一个人盖一个房子需要100天,难道10000个人,只需要1/10 天一样了?(这是一个夸张的说法,哈哈!)
线程之间的切换也是需要系统开销的,线程的数目还是要控制在一个合理的范围内才行。
RamdomAccessFile
这个类比较独特,它即可以从文件中读取数据,也可以向文件中写入数据。但是它不是 OutputStream 和 InputStream 的子类,它是实现了这两个接口 DataOutput 、DataInput 的一个类。
API 中的介绍:
该类的实例支持读取和写入随机访问文件。 随机访问文件的行为类似于存储在文件系统中的大量字节。 有一种游标,或索引到隐含的数组,称为文件指针 ; 输入操作读取从文件指针开始的字节,并使文件指针超过读取的字节。 如果在读/写模式下创建随机访问文件,则输出操作也可用; 输出操作从文件指针开始写入字节,并将文件指针提前到写入的字节。 写入隐式数组的当前端的输出操作会导致扩展数组。 文件指针可以通过读取getFilePointer方法和由设置seek方法。
所以,这个类最重要的就是 seek 方法了,使用 seek 方法,可以控制写入的位置,所以实现多线程就容易的多了。因此,无论是本地文件复制,还是网络多线程下载都需要这个类的作用。
具体思路是: 首先使用 RandomAccessFile 创建一个 File 对象,然后设置这个文件的大小。(对的,它可以直接设置文件的大小。)将这个文件设置成和要复制或下载的文件一样的。(虽然我们并没有向这个文件中写入数据,但是这个文件已经创建了。)将文件分为若干部分,使用线程复制或者下载每一部分的内容。
这有点类似文件的覆盖,如果一个已经存在的文件,从这个文件的头部开始写入数据,一直写到文件的尾部,那么原来的文件就不存在了,变成了写入的新文件。
设置文件大小:
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
}
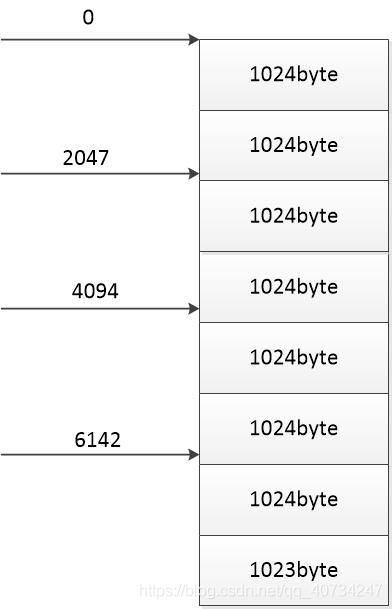
用图片来说明: 这个图表示一个 8191 字节大小的文件: 每一个部分大小是:8191 / 4 = 2047字节
将这个文件的分为四个部分,每一个部分使用一个线程进行复制或下载,其中每一个箭头代表一个线程的开始下载位置。我特意将最后一个部分,没有设置为 1024 byte,这是因为文件很少是正好能被 1024 byte 整除的。(之所以使用 1024 byte,是因为我每次会读取 1024 byte,如果读取到 1024 byte的话, 否则写入读取到的相应字节数)。
按照这个示意图,每一个线程下载 2047 byte,那么总共下载的字节数是:2047 * 4 = 8188 字节 < 8191 字节(文件的总大小) 所以这就产生了一个问题,下载的字节数少于总字节数,这就是问题了,所以必须要下载的字节数大于总字节数才行。(多了没有关系,因为多下载的部分,会被后面的给覆盖掉,不会产生了问题。)
所以每个部分的大小应该是:8191 / 4 + 1 = 2048 字节。(这样四部分的大小相加是超过总大小的,不会发生数据的丢失问题。)
所以,这里这个加 1 是很有必要的。
long size = len / FileCopyUtil.THREAD_NUM + 1;
每个线程下载完成的位置(右边) 每个线程,只复制下载自己的那部分,所以不需要全部下载完所有的内容,所以读取文件数据并写入文件的部分,会多加一个判断。
这里增加一个计数器:curlen。它表示是当前复制或者下载的长度,然后每次读取后和 size(每部分的大小)进行比较,如果 curlen 大于 size 就表示相应的部分下载完成了(当然了,这些都要在数据没有读取完的条件下判断)。
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position);
raf.seek(position);
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}

还有需要注意的是,每个线程下载的时候都要: 1. 输出流设置文件指针的位置。 2. 输入流跳过不需要读取的字节。
这是很重要的一步,应该是很好理解的。
bis.skip(position); raf.seek(position);
多线程本地文件复制(完整代码)
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 用于进行文件复制,但不是常规的文件复制 。
* 准备仿照疯狂Java,写一个多线程的文件复制工具。
* 即可以本地复制和网络复制
* */
/**
* 设计思路:
* 获取目标文件的大小,然后设置复制文件的大小(这样做是有好处的),
* 然后使用将文件分为 n 分,使用 n 个线程同时进行复制(这里我将 n 取为 4)。
*
* 可以进一步拓展:
* 加强为断点复制功能,即程序中断以后,
* 仍然可以继续从上次位置恢复复制,减少不必要的重复开销
* */
public class FileCopyUtil {
//设置一个常量,复制线程的数量
private static final int THREAD_NUM = 4;
private FileCopyUtil() {}
/**
* @param targetPath 目标文件的路径
* @param outputPath 复制输出文件的路径
* @throws IOException
* */
public static void transferFile(String targetPath, String outputPath) throws IOException {
File targetFile = new File(targetPath);
File outputFilePath = new File(outputPath);
if (!targetFile.exists() || targetFile.isDirectory()) { //目标文件不存在,或者是一个文件夹,则抛出异常
throw new FileNotFoundException("目标文件不存在:"+targetPath);
}
if (!outputFilePath.exists()) { //如果输出文件夹不存在,将会尝试创建,创建失败,则抛出异常。
if(!outputFilePath.mkdir()) {
throw new FileNotFoundException("无法创建输出文件:"+outputPath);
}
}
long len = targetFile.length();
File outputFile = new File(outputFilePath, "copy"+targetFile.getName());
createOutputFile(outputFile, len); //创建输出文件,设置好大小。
long[] position = new long[4];
//每一个线程需要复制文件的起点
long size = len / FileCopyUtil.THREAD_NUM + 1;
for (int i = 0; i < FileCopyUtil.THREAD_NUM; i++) {
position[i] = i*size;
copyThread(i, position[i], size, targetFile, outputFile);
}
}
//创建输出文件,设置好大小。
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
}
private static void copyThread(int i, long position, long size, File targetFile, File outputFile) {
int n = i; //Lambda 表达式的限制,无法使用变量。
new Thread(()->{
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position); //跳过不需要读取的字节数,注意只能先后跳
raf.seek(position); //跳到需要写入的位置,没有这句话,会出错,但是很难改。
int hasRead = 0;
byte[] b = new byte[1024];
/**
* 注意,每个线程只是读取一部分数据,不能只以 -1 作为循环结束的条件
* 循环退出条件应该是两个,即写入的字节数大于需要读取的字节数 或者 文件读取结束(最后一个线程读取到文件末尾)
*/
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
多线程网络下载(完整代码)
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.net.URL;
import java.net.URLConnection;
/*
* 多线程下载文件:
* 通过一个 URL 获取文件输入流,使用多线程技术下载这个文件。
* */
public class FileDownloadUtil {
//下载线程数
private static final int THREAD_NUM = 4;
/**
* @param url 资源位置
* @param output 输出路径
* @throws IOException
* */
public static void transferFile(String url, String output) throws IOException {
init(output);
URL resource = new URL(url);
URLConnection connection = resource.openConnection();
//获取文件类型
String type = connection.getContentType();
if (type != null) {
type = "."+type.split("/")[1];
} else {
type = "";
}
//创建文件,并设置长度。
long len = connection.getContentLength();
String filename = System.currentTimeMillis()+type;
try (RandomAccessFile raf = new RandomAccessFile(new File(output, filename), "rw")){
raf.setLength(len);
}
//为每一个线程分配相应的下载其实位置
long size = len / THREAD_NUM + 1;
long[] position = new long[THREAD_NUM];
File downloadFile = new File(output, filename);
//开始下载文件: 4个线程
download(url, downloadFile, position, size);
}
private static void download(String url, File file, long[] position, long size) throws IOException {
//开始下载文件: 4个线程
for (int i = 0 ; i < THREAD_NUM; i++) {
position[i] = i * size; //每一个线程下载的起始位置
int n = i; // Lambda 表达式的限制,无法使用变量
new Thread(()->{
URL resource = null;
URLConnection connection = null;
try {
resource = new URL(url);
connection = resource.openConnection();
} catch (IOException e) {
e.printStackTrace();
}
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream());
RandomAccessFile raf = new RandomAccessFile(file, "rw")){ //每个流一旦关闭,就不能打开了
raf.seek(position[n]); //跳到需要下载的位置
bis.skip(position[n]); //跳过不需要下载的部分
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position[n]+" "+curlen+" "+size);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}) .start();
}
}
private static void init(String output) throws FileNotFoundException {
File path = new File(output);
if (!path.exists()) {
if (!path.mkdirs()) {
throw new FileNotFoundException("无法创建输出路径:"+output);
}
} else if (path.isFile()) {
throw new FileNotFoundException("输出路径不是一个目录:"+output);
}
}
}
测试代码及结果
因为这个多线程文件复制和多线程下载是很相似的,所以就放在一起测试了。我也想将两个写在一个类里面,这样可以做成方法的重载调用。 文件复制的第一个参数可以是 String 或者 URI。 使用这个作为目标文件的参数。
public File(URI uri)
网络文件下载的第一个参数,可以使用 String 或者是 URL。 不过,因为先写的这个文件复制,后写的多线程下载,就没有做这部分。不过现在这样功能也达到了,可以进行本地文件的复制(多线程)和网络文件的下载(多线程)。
package dragon;
import java.io.IOException;
public class FileCopyTest {
public static void main(String[] args) throws IOException {
//复制文件
long start = System.currentTimeMillis();
try {
FileCopyUtil.transferFile("D:\\DB\\download\\timg.jfif", "D:\\DBC");
} catch (IOException e) {
e.printStackTrace();
}
long time = System.currentTimeMillis()-start;
System.out.println("time: "+time);
//下载文件
start = System.currentTimeMillis();
FileDownloadUtil.transferFile("https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1578151056184&di=594a34f05f3587c31d9377a643ddd72e&imgtype=0&src=http%3A%2F%2Fn.sinaimg.cn%2Fsinacn%2Fw1600h1000%2F20180113%2F0bdc-fyqrewh5850115.jpg", "D:\\DB\\download");
System.out.println("time: "+(System.currentTimeMillis()-start));
}
}
运行截图: 注意:这里这个时间并不是复制和下载需要的时间,实际上它没有这个功能!
注意:虽然两部分代码是相同的,但是第三列数字,却不是完全相同的,这个似乎是因为本地和网络得区别吧。但是最后得文件是完全相同的,没有问题得。(我本地文件复制得是网络下载得那张图片,使用图片进行测试有一个好处,就是如果错了一点(字节数目不对),这个图片基本上就会产生问题。)

产生错误之后的图片: 图片无法正常显示,会出现很多的问题,这就说明一定是代码写错了,哈哈。不过代码的 bug 有时候还是很费时间的。

总结
多线程复制和多线程下载,对于IO 流的使用都是相同的,所以掌握好IO 流的使用是很关键的一步,这样就可以做很多很有趣的事情了。将IO流结合线程和网络是一片广阔的天地,但是我也是最近才看了一点网络的知识。(网络是很难的,写这个多线程下载就遇到了一些网络类上面的问题。)
使用计时器实现了多线程复制文件的断点复制功能,感兴趣的可以了解一下。 多线程断点复制
到此这篇关于详解Java多线程和IO流的应用的文章就介绍到这了,更多相关Java多线程和IO流内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!