基于 FPGA 的 HDMI/DVI 显示
文章目录
- 前言
- 一、HDMI 与 DVI 的区别与联系
-
- 1.1 DVI 接口含义
- 1.2 HDMI 接口含义
- 1.3 HDMI 与 DVI 的区别
- 1.4 HDMI 与 DVI 的兼容性
- 1.5 HDMI 与 DVI 接口对比
- 二、DVI 数据链路介绍
-
- 2.1 输入接口层
- 2.2 TMDS 发送器
- 2.3 TMDS 接收器
- 2.4 输出接口层
- 三、传输原理与实现
-
- 3.1 TMDS原理
- 3.2 实现方式
-
- 3.2.1 传输最小化
- 3.2.1.1 最小化传输实现原理
- 3.2.2 直流平衡编码
- 3.3 TMDS 编码实现
- 3.3 仿真展示
- 3.4 串行发送
-
- 3.4.1 串行发送原理
- 3.4.2 FPGA 实现 DDR 接口
- 3.4.3 编码实现
- 3.4.4 serdes_4b_10to1仿真展示
- 3.5 DVI 发送器实现
- 四、基于 DVI 接口的串口传图实验
-
- 4.1 串口传图实验
- 4.2 上板展示
前言
本节对 DVI 电路接口和 DVI 数据链路原理做简单的介绍,并在 FPGA 上实现基于 DVI接口的显示器彩条显示实验。
提示:以下是本篇文章正文内容,下面案例可供参考
一、HDMI 与 DVI 的区别与联系
1.1 DVI 接口含义
DVI(Digital Visual Interface),即数字视频接口,是一种视频接口标准,设计的目的是用来传输未经压缩的数字化视频。目前广泛应用于 LCD、数字投影机等显示设备上。此标准由显示业界数家领导厂商所组成的论坛:“数字显示工作小组”(Digital Display Working Group,DDWG)制订。DVI 接口可以发送未压缩的数字视频数据到显示设备。本规格部分兼容于 HDMI 标准。
1.2 HDMI 接口含义
高清晰度多媒体接口(High Definition Multimedia Interface)是一种全数位化影像和声音传送接口,可以传送无压缩的音频信号及视频信号。HDMI 接口可以提供高达 5Gbps 的数据传输带宽,可以传送无压缩的音频信号及高分辨率视频信号。同时无需在信号传送前进行数/模或者模/数转换,可以保证最高质量的影音信号传送。
1.3 HDMI 与 DVI 的区别
接口外观不同,下图中,左侧为 HDMI 接口,右侧为 DVI 接口,可以看得出 HDMI接口体积比 DVI 小。
HDMI 可以同时传输数字视频和音频信号,用一根电缆就可以了,DVI 只能传输数字视频信号,传输音频信号只能用另外的接口和电缆。
HDMI 最高传输速率比 DVI 高,HDMI 可以传输更高清数字视频信号。
在保证不失真前提下 HDMI 传输距离比 DVI 远,HDMI 电缆最长可以达 15 米,DVI 只能达到 8 米。

1.4 HDMI 与 DVI 的兼容性
HDMI 兼容 DVI,可以通过转换接口将视频信号接到 DVI 接口上。使用 DVI 标准发送的视频数据可以直接接入 HDMI 接口的 LCD 显示器正常显示。同样的,使用 HDMI 标准发送的视频数据在符合 DVI 规范的范围内,也能直接接到 DVI 接口的 LCD 显示器上正常显示。
在本节中讨论的使用 FPGA 实现 HDMI 发送的功能,实际只能算 DVI,因为我们没有加入 HDMI 所拥有的的音频数据传输功能。而且受 FPGA 的 IO 口翻转速度限制,也仅能实现 DVI 规范所规定的传输速率,达不到 HDMI 规范的高速传输能力。但是为了接口易用,我们在硬件上使用了 HDMI 的连接接口。在下述描述内容中,将不再刻意区分 DVI 和 HDMI,介绍协议时多以 DVI 描述,介绍接口时则多以 HDMI 描述。
1.5 HDMI 与 DVI 接口对比
在 DVI 甚至 HDMI 接口出现之前,应用很广泛的一直是 VGA 接口,早期的 CRT 显示器多以 VGA 接口与计算机连接,哪怕是到了 2020 年的现在,还有不少的计算机设备将 VGA接口作为标配功能。VGA 接口传输的是模拟信号,通过模拟电压的变化来表示像素颜色。这种传输方式适合在早期的 CRT 显示设备中使用,因为 CRT 显示器的成像原理本身就是模拟信号的放大,变换等。通过 VGA 传输的模拟信号送入显示器后经过一系列的放大后可以直接驱动 CRT 显示器的电子枪扫描荧光屏。而现代 LCD 液晶显示屏则采用液晶材质在会根据加载其两端的电压大小而改变透光性
的特性实现的被动颜色显示,在液晶显示器中,通过将众多细小的液晶颗粒按照矩阵的形式排布在一起,实现显示面板。所以 LCD 液晶显示屏是以像素作为基本的成像单元,通过让像素点显示不同的颜色来实现彩色图案的显示。一个 LCD 显示屏的物理像素数量是确定的,每个像素点的颜色都可以对应一个图像数据,而这个数据是数字信号,所以 LCD 显示屏从原理上讲可以认为是数字显示屏(虽然最终控制单颗液晶的透光程度时也会将这个数字信号转换为模拟电压信号,但是这已经是像素点级别的成像原理了,而非液晶显示器显示整幅图案的成像原理)。显示时,只需要得到对应像素点的颜色数据即可,所以这类显示屏接收的是数字信号。下图为 LCD 液晶显示器分别使用 VGA 接口和 HDMI 接口与显卡传输图像数据的数据流变换示意图。左图为 VGA 接口,右图为 HDMI 接口。
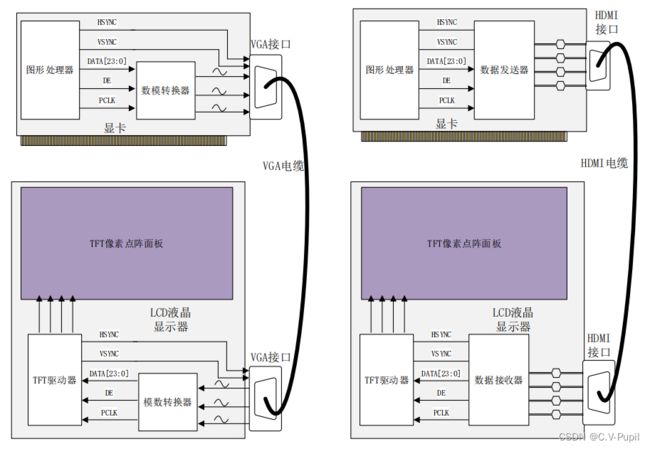
在使用 VGA 接口的传输方式中,图像数据从图形处理器(也就是常说的显卡芯片)输出(此时的信号为数字信号),为了能够变成 VGA 接口传输所需的模拟信号,会使用一片数模转换器转换为模拟信号后再输出到 VGA 接口上。然后模拟信号通过 VGA 电缆传输到LCD 液晶显示屏的 VGA 接口,由于 TFT 像素面板为数字显示屏,每一个像素的颜色是由一个 TFT 驱动器实时的扫描描的。TFT 驱动器的输入要求为数字信号,所以 TFT 驱动器和 VGA 接口之间使用了一片模数转换将 VGA 接口上的模拟信号转换为数字信号后再送给 TFT 驱动器使用。整个信号的变换流程为:
数字信号 -> 模拟信号 -> 模拟信号 -> 数字信号
在使用 HDMI 接口的传输方式中,图像数据从图形处理器(也就是常说的显卡芯片)输出(此时的信号为数字信号),为了能够将数字信号转换为 HDMI 标准的高速差分信号,会经过一个数据发送器。该数据发送器仅仅是改变了数据的传输方式,将原本的并行数据转换为高速串行数据输出,以符合 HDMI 协议标准,在 HDMI 接口上传输的内容实际还是数字信号。数字信号从显卡的 HDMI 接口经由 HDMI 线缆传输到 LCD 显示器的 HDMI 接口,再由 LCD 显示器内的数据接收器将HDMI 接口上的高速串行数字信号转换为并行数据,提供给 TFT 驱动器使用。整个信号的变换流程为:
数字信号 -> 数字信号 -> 数字信号 -> 数字信号
使用 HDMI 方式传输的过程中,数据的内容没有发生任何的变化。图形处理器发送的是什么数据,最终送到 TFT 驱动器的就是什么数据,不会有哪怕一位数据发生变化。所以图像还原度很高,而且由于 HDMI 传输方式为差分传输,其抵抗干扰的能力也比模拟信号高很多,一般不会受到干扰。
使用 VGA 方式传输数据,由于数据在传输过程中经过了两次数字和模拟信号间的变换,所以无法保证图形处理器发送的数据就一定是 TFT 驱动器收到的数据,中间总会有一定的差异,虽然这些差异可能不会对最终的显示效果产生明显的影响。但是由于数模转换和模数转换的存在,当数据的变化速度过快时,可能造成拖影现象,所谓拖影现象,就是指在图像颜色变化较大的边界,后一个像素的图像数据可能无法真正显示其想显示的颜色,而是介于需要显示的颜色和前一个像素的颜色之间的一种颜色。而且,模拟信号在传输过程中容易受到噪声的干扰。导致显示的图像中会出现很多杂点。
综上所述,使用 HDMI 传输图像具有还原度高,抗干扰能力强,数据带宽大的优势,目前新出产的计算机和显示器已经都标配 HDMI 接口了。就笔者使用体验来说,使用 VGA 接口传输图像内容时,受不同显示器和显卡的影响,很容易就会遇到拖影和噪声干扰的问题,而 HDMI 接口的则都能保证图像质量。
二、DVI 数据链路介绍
无论是 HDMI 还是 DVI 规范,其数据链路层都是使用 TMDS 编码方式。在数据传输过程中,包括了输入接口层、TMDS 发送器、TMDS 接收器和输出接口层。
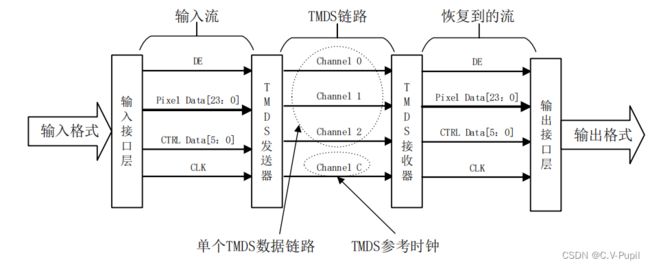
2.1 输入接口层
输入接口层的信号格式为典型的 RGB 行场同步数字接口,该接口包括数据使能信号 DE
(Data Enable)、24 位像素数据(Pixel Data)、6 位的控制数据(包括 HSYNC、VSYNC 和
空信号)和同步时钟信号。
2.2 TMDS 发送器
TMDS 发送器完成对输入接口层的数据和控制信号按照 TMDS 编码方式进行编码,再将编码的数据通过高速串行接口输出,最终将输入接口层的信号编码进 4 个 TMDS 链路层中。关于输入接口层的信号到最终 TMDS 链路层的编码和串行化过程,将在下一节介绍。
2.3 TMDS 接收器
与 TMDS 发送器相反,TMDS 接收器的功能是将 TMDS 链路上的高速串行数据接收,解串TMDS 解码,得到与输入接口层相同的控制信号和数据。
2.4 输出接口层
输出接口层将 TMDS 接收器解码得到的数据流和控制信号传递给最终的数据消费者,例如 RGB 接口的液晶显示面板
三、传输原理与实现
HDMI传输原理和DVI相同,由Silicon Image公司发明的TMDS(Time Minimized Differential Signal)最小化传输差分信号传输技术。TMDS是一种微分信号机制,采用的是差分传动方式。这不仅是DVI技术的基础,也是HDMI技术的基础原理。
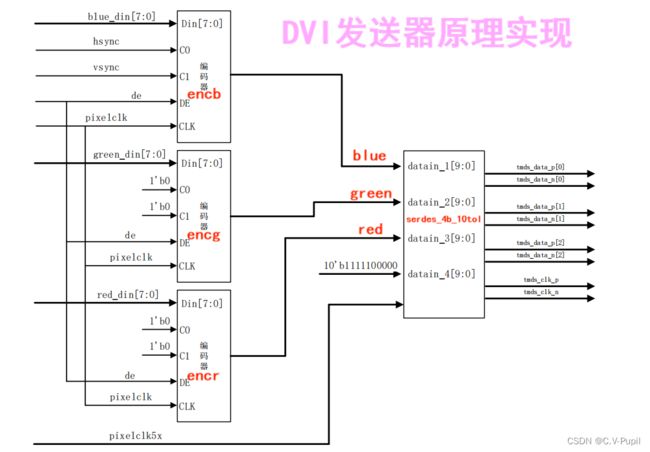
3.1 TMDS原理
在上面介绍 DVI 数据链路层的时候,提到了 TMDS 发送器是将数据和控制信号进行编码并串行化后发送,那么什么是 TMDS 编码呢,TMDS 编码又是怎样的一种编码方式呢?
(1)每一个标准的HDMI连接,都包含了3个用于传输数据的TMDS传输通道,还有1个独立的TMDS时钟通道,以保证传输时所需的统一时序。
(2)在一个时钟周期内,每个TMDS通道都能传送10bit的数据流。而这10bit数据,可以由若干种不同的编码格式构成。一个HDMI包括3个TMDS数据通道和1个TMDS时钟通道。
(3)每个数据通道都通过编码算法(异或、异或非等),将8位数据转换成10位数据,前8为数据由原始信号经运算后获得,第9位指示运算的方式,第10位用来对应直流平衡。通过这种算法,会使得数据的传输和恢复更加可靠。
第一组中,将像素数据中的蓝色(BLUE)分量和控制信号中的行同步(HSYNC)、场同步
(VSYNC)划分成了一组,经过编码器和串行调制器后输出,名为 Channel 0。
第二组中,将像素数据中的绿色(GREEN)分量和两个空的控制信号 CTL0、CTL1 划分成了一组,经过编码器和串行调制器后输出,名为 Channel 1。在这一组中,CTL0 和 CTL1 接入
的是空信号。
第三组中,将像素数据中的红色(RED)分量和两个空的控制信号 CTL2、CTL3 划分成了一组,经过编码器和串行调制器后输出,名为 Channel 2。在这一组中,CTL2 和 CTL3 接入的是空信号。
至此,关于 TMDS 对数据的划分方式就非常的清晰了。设计的重点就是编码器和串行化数据发送器的设计即(encode模块和serdes_4b_10to1模块)。
3.2 实现方式
3.2.1 传输最小化
什么是最小化传输,为什么要使用最小化传输呢?和各位一样,笔者在第一次听到这个概念的时候,首先头脑中冒出的也是这个疑问。所谓最小化传输,其本质就是要通过对输入数据的变换,得到一个跳变次数最少的新数据。什么是跳变次数最少呢?举个例子。8 位的数据 0x55,其二进制值为 01010101b,这个数据中,相邻的两个数如果个数不一样,则认为是一次跳变。从最低位看起,bit[0] = 1,bit[1] = 0,0 和 1 的状态不同,则为一次跳变。再接着看,bit[1] = 0,bit[2] = 1,1 和 0 的状态又不同,所以又是一次跳变。对于 0x55,其 8 位数据中,任意相邻的两个位的值都不相同,所以认为 0x55 这个数据的跳变次数为 7。而对于 8 位的 0x80,其二进制值为10000000b,其跳变次数为 1。所以不同的数据,其位跳变次数也是不一样的。所以,最小化传输,就是要通过一定的手段,将数据进行重新编码,让所有的编码后的数据其跳变次数都尽可能的少。为什么要使用最小化传输呢?这个就涉及到信号在具体的线缆中传输的问题了。对于TMDS 规范,其最终的数据是通过串行的方式将每个 10 位的数据逐位输出的。那么在传输过程中,假设前一个数据是 0,后一个数据是 1,则信号线在传完前一位数据之后,需要马上把电平设置为代表 1 的电平,这个过程中就必然会出现信号线高低电平的变化,信号的变化就会产生磁场。对信号线产生电磁干扰。所以,越少的信号翻转次数,就会产生越小的电磁干扰。
3.2.1.1 最小化传输实现原理
经过最小化传输方式实现的 TMDS,其用来作为像素数据的 TMDS 字符包含 5 个或更少的跳变,而用来作为控制数据的 TMDS 字符包含 7 个或更多的跳变。在空期间传送的多跳变内容形成解码端的字符边界的基础,这些字符在串行数据流中个体不是独一无二,但它们足够相似,使得在发送空间隙期间,解码器它们可以唯一地检测出它们连续的存在。TMDS 数据通道传送的是一个连续的 10bit TMDS 字符流,在空期间,传送 4 个有显著特征的字符,它们直接对应编码器的 2 个控制信号的 4 个可能的状态。在数据有效期间,10bit的字符包含 8bit 的像素数据,编码的字符提供近似的 DC 平衡,并最少化数据流的跳变次数,对有效像素数据的编码处理可以认为有两个阶段:第一个阶段是依据输入的 8bit 像素数据产生跳变最少的 9bit 代码字;第二阶段是产生一个 10bit 的代码字,最终的 TMDS 字符,将维持发送字符总体的 DC 平衡。编码器在第一个阶段产生的 9bit 代码字由“8bit” + “1bit”组成,“8bit”反映输入的8bit 数据位的跳变,“1bit”表示用来描述跳变的两个方法中哪一个被使用,无论哪种方法,输出的最低位都会与输入的最低位相匹配。用一个建立的初值,输出字的余下 7bit 的产生是按照顺序将输入的每一位与前一导出的位进行 XOR 或 NOR(XNOR)。使用 XOR 还是 XNOR要看哪个方法使得编码结果包含最少的跳变,代码字的第 9 位用来表示导出输出代码是使用 XOR 还是 XNOR,这 9bit 代码字的解码方法很简单,就是相邻位的 XOR 或 XNOR 操作。从解码输入到解码器输出最低位不改变。在有效数据期间,编码器执行使传输的数据流维持近似的 DC 平衡处理,这是通过选择性地反转第一阶段产生的 9bit 代码中的 8bit 数据位来实现的,第 10bit 被加到代码字上,表示是否进行了反转处理,编码器是基于跟踪发送流中 1 和 0 个数的不一致以及当前代码字 1和 0 的数目来确定什么时候反转下一个 TMDS 字符。如果太多的 1 被发送,且输入包含的 1多于 0,则代码字反转,这个发送端的动态编码决定在接收端可以很简单地解码出来,方法是以 TMDS 字符的第 10bit 决定是否对输入代码进行反转。关于这个编码的详细方法,结合下述流程图将非常的容易理解。
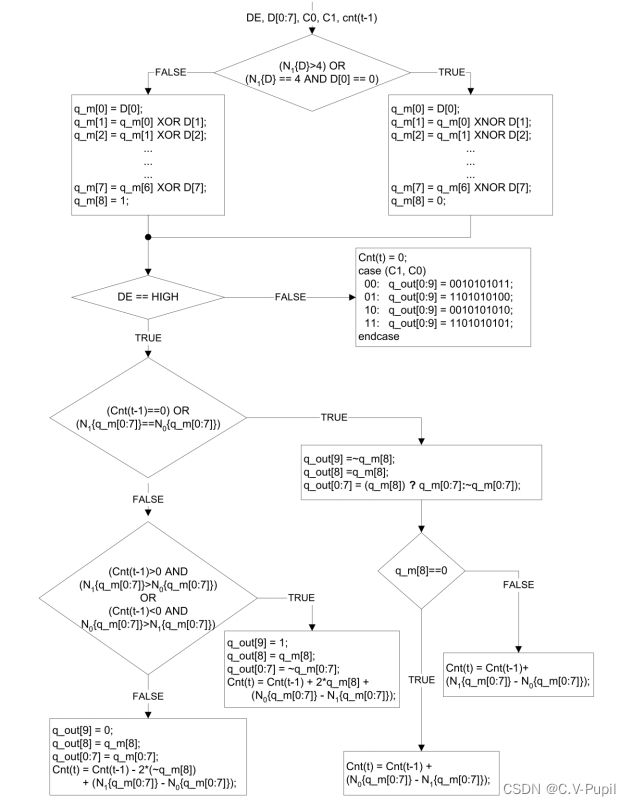

先统计输入的数据中有多少个 1。
根据输入数据中 1 的个数和输入数据的最低位的值,来确定编码方向。
根据编码方向,对输入数据进行编码,方向为 1,则采用异或编码方式,方向为 0,则采用同或编码方式,并将编码方向值作为编码后数据的第 9 位,也就是 q_m[8]。(即:8bit -> 9bit: (q_m[7:0]是被编码后的数据,q_m[8]是表示方向:q_m[8]为 0,采用同或运算;q_m[8]为 1,采用异或运算,这就是 TMDS 编码的第一阶段——最小化传输,也就是将 8 位数据变 9 位。)
3.2.2 直流平衡编码
直流平衡编码中,主要是根据前一个编码过程统计的整个数据流中的 1 和 0 的差值,来指导本次编码过程的差值,确保在整个数据流的传输过程中,传输的 1 和 0 的总个数是相差不大的。这样能够保证整个传输链路的直流平衡。
所谓直流平衡,就是指信号在传输中 0 和 1 的数据个数相同,则发送方和接收方直接的就不会有直流电流的传递,在通信系统中,直流平衡可以有效避免由于收发两端电压不稳引起的问题。
3.3 TMDS 编码实现
事实上,只要按照上述流程图中的顺序设计相应的逻辑电路,就能实现该编码器,下述代码为我们根据该流程图编写设计的编码器,实测能够正常的用于图像数据发送中。
/
// Module Name : encode
// Description : 8b10b编码模块
// Name : 小王在努力...
// Revision :Vivado 2018.3
/
`timescale 1 ps / 1ps
`define D #1
module encode(
clk,
rst_p,
din,
c0,
c1,
de,
dout
);
input clk; // 像素时钟输入
input rst_p; // 异步复位高电平有效
input [7:0] din; // 数据输入,需要寄存
input c0; // c0 输入
input c1; // c1 输入
input de; // 数据使能,输入
output reg [9:0] dout; // 数据输出
parameter CTL0 = 10'b1101010100;
parameter CTL1 = 10'b0010101011;
parameter CTL2 = 10'b0101010100;
parameter CTL3 = 10'b1010101011;
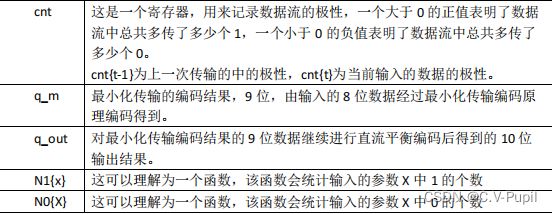
reg [3:0] n1d; //统计输入的8bit数据中1的个数
reg [7:0] din_q; //同步寄存输入的8bit数据(统计需要一拍时间)
// 统计每次输入的8bit数据中1和0的个数。流水线输出.同步寄存输入的8bit数据
always @ (posedge clk) begin
din_q <= `D din;
n1d <= `D din[0] + din[1] + din[2] + din[3] + din[4] + din[5] + din[6] + din[7];
end
// 第一步:8 bit -> 9 bit
// 参考DVI规范1.0,第29页,图3-5
wire decision1; //0
assign decision1 = (n1d > 4'h4) | ((n1d == 4'h4) & (din_q[0] == 1'b0));
// 最低位不变,剩下的等于前一位跟对应的din_q相异或运算,或者是同或运算
// q_m[0] = din_q[0];
// q_m[i+1] = q_m[i] ^ din_q[i+1]; q_m[8] = 1;
// q_m[i+1] = q_m[i] ^~ din_q[i+1]; q_m[8] = 0;
wire [8:0] q_m;
assign q_m[0] = din_q[0];
assign q_m[1] = (decision1) ? ~(q_m[0] ^ din_q[1]) : (q_m[0] ^ din_q[1]);
assign q_m[2] = (decision1) ? ~(q_m[1] ^ din_q[2]) : (q_m[1] ^ din_q[2]);
assign q_m[3] = (decision1) ? ~(q_m[2] ^ din_q[3]) : (q_m[2] ^ din_q[3]);
assign q_m[4] = (decision1) ? ~(q_m[3] ^ din_q[4]) : (q_m[3] ^ din_q[4]);
assign q_m[5] = (decision1) ? ~(q_m[4] ^ din_q[5]) : (q_m[4] ^ din_q[5]);
assign q_m[6] = (decision1) ? ~(q_m[5] ^ din_q[6]) : (q_m[5] ^ din_q[6]);
assign q_m[7] = (decision1) ? ~(q_m[6] ^ din_q[7]) : (q_m[6] ^ din_q[7]);
assign q_m[8] = (decision1) ? 1'b0 : 1'b1;
// 第二步:9 bit -> 10 bit
// 参考DVI规范1.0,第29页,图3-5
reg [3:0] n1q_m, n0q_m; // 统计q_m中1和0的个数
always @ (posedge clk) begin
n1q_m <= `D q_m[0] + q_m[1] + q_m[2] + q_m[3] + q_m[4] + q_m[5] + q_m[6] + q_m[7];
n0q_m <= `D 4'h8 - (q_m[0] + q_m[1] + q_m[2] + q_m[3] + q_m[4] + q_m[5] + q_m[6] + q_m[7]);
end
reg [4:0] cnt; // 计数器差距统计:统计1和0是否过量发送,最高位(cnt[4])是符号位
wire decision2, decision3;
assign decision2 = (cnt == 5'h0) | (n1q_m == n0q_m);
// [(cnt > 0) and (N1q_m > N0q_m)] or [(cnt < 0) and (N0q_m > N1q_m)]
assign decision3 = (~cnt[4] & (n1q_m > n0q_m)) | (cnt[4] & (n0q_m > n1q_m));
// 流水线对齐(同步寄存器2拍)
reg [1:0] de_reg;
reg [1:0] c0_reg;
reg [1:0] c1_reg;
reg [8:0] q_m_reg;
always @ (posedge clk) begin
de_reg <= `D {de_reg[0], de};
c0_reg <= `D {c0_reg[0], c0};
c1_reg <= `D {c1_reg[0], c1};
q_m_reg <= `D q_m;
end
// 10-bit 数据输出
always @ (posedge clk or posedge rst_p) begin
if (rst_p) begin
dout <= 10'h0;
cnt <= 5'd0;
end else begin
if (de_reg[1]) begin// 数据周期:发送对应编码的数据
if (decision2) begin
dout[9] <= `D ~q_m_reg[8];
dout[8] <= `D q_m_reg[8];
dout[7:0] <= `D (q_m_reg[8]) ? q_m_reg[7:0] : ~q_m_reg[7:0];
cnt <= `D (~q_m_reg[8]) ? (cnt + n0q_m - n1q_m) : (cnt + n1q_m - n0q_m);
end else begin if (decision3) begin
dout[9] <= `D 1'b1;
dout[8] <= `D q_m_reg[8];
dout[7:0] <= `D ~q_m_reg;
cnt <= `D cnt + {q_m_reg[8], 1'b0} + (n0q_m - n1q_m);
end else begin
dout[9] <= `D 1'b0;
dout[8] <= `D q_m_reg[8];
dout[7:0] <= `D q_m_reg[7:0];
cnt <= `D cnt - {~q_m_reg[8], 1'b0} + (n1q_m - n0q_m);
end
end
end else begin // 控制周期:发送控制信号
cnt <= `D 5'd0;
case ({c1_reg[1], c0_reg[1]})
2'b00: dout <= `D CTL0;
2'b01: dout <= `D CTL1;
2'b10: dout <= `D CTL2;
default: dout <= `D CTL3;
endcase
end
end
end
endmodule
3.3 仿真展示
3.4 串行发送
3.4.1 串行发送原理
在完成了最小化传输编码之后,剩下的就是要将编码好的内容按照串行方式发送出去了。对于发送器来说,使用 5 倍的编码器工作时钟速率,将编码的 10 位数据采用双数据速率(DDR)形式一位一位的输出。所以整个 TMDS 编码发送模块共需要 2 路时钟,一路供给编码器使用,其时钟速率等于输入接口层的时钟速率,另一路供串行发送器使用,其时钟速率等于输入接口层时钟速率的 5 倍。至于经常有人疑问的,为啥串行发送时钟的频率是编码器的 5 倍而不是 10 倍,因为做过UART 串口通信的人都知道,一个 10 位的数据(8 位数据位+1 位起始位+1 位停止位)要通过串口发出去,需要分 10 次发送,每次发送 1 位。而这里为啥只要 5 次呢?这是因为在这里,发送是在时钟的上升沿和下降沿各发送一位。也就是一个时钟周期可以发送 2 位数据,所以 10 位数据只需要 5 个时钟周期即可发完。这样每个 10 位的数据都可以在编码器的一个时钟周期内由串行发送器发送完毕,发送示意图如下图所示。
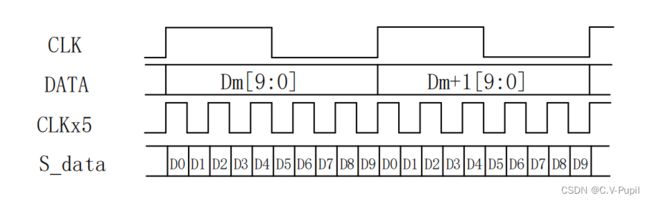
在时钟的上升沿和下降沿都发送数据,这就是 DDR(Double Data Rate 双数据速率)接口,DDR 接口能够在不改变传输时钟频率的情况下将单根信号线上传输的数据数量扩大一倍。就大家所感兴趣的 DDR SDRAM 与 SDRAM 来说,两者在结构上的最大区别就是 DDR SDRAM 使用了 DDR 接口来传输数据,使得相同的时钟频率下,DDR SDRAM 的数据传输带宽为 SDRAM 的2 倍。
3.4.2 FPGA 实现 DDR 接口
几乎所有现在流行的 FPGA 都支持双数据速率接口,Xilinx 的 FPGA 也不例外。在使用时,我们可以在 Vivado 软件中通过调用原语来使用双数据速率 IO。双数据速率 IO 包括 IDDR 输入型双速率 IO)、ODDR(输出型双速率 IO)。通过调用双速率数据 IO 原语,就能够实现双数据速率传输了。打开 Vivado 工具栏 Tools 下的 Language Templates,在打开的搜索框中输入 DDR 就能看到。
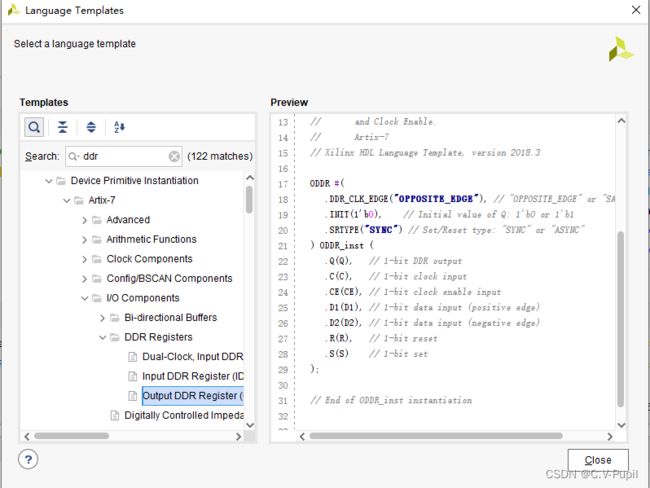
ODDR 原语结构图如下:
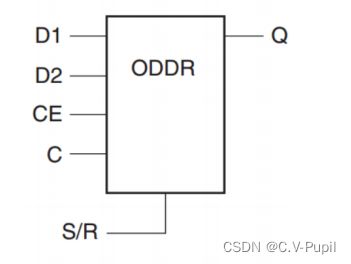
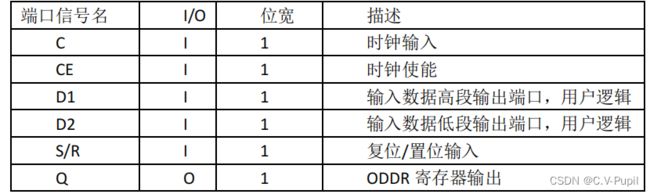
其端口具体介绍如下:
ODDR 参数 DDR_CLK_EDGE 为模式设置,ODDR 原语支持 OPPOSITE_EDGE 模式、SAME_EDGE模式。SAME_EDGE 模式与 Virtex-6 架构相同,这个模式允许设计者在 ODDR 时钟的上升沿向ODDR 原语提供数据输入,从而节省 CLB 和时钟资源,并提高性能。
(1)OPPOSITE_EDGE 模式
在此模式中,时钟边沿被用来以两倍的吞吐量从 FPGA 逻辑中捕获数据。这种结构与virtex-6 的实现比较相似。两个输出都提供给 IOB 的数据输入或者三态控制输入。使用OPPOSITE_EDGE 模式的输出 DDR 时序图如下图所示:
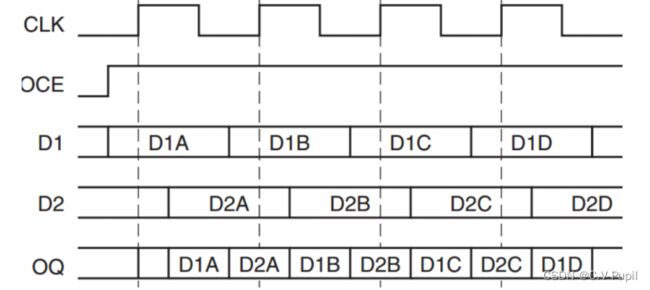
(2)SAME_EDGE 模式
在此模式下,数据可以在相同的时钟边沿送给 IOB。相同的时钟沿将数据送给 IOB 可以避免建立时间违规,并允许用户使用最小的寄存器来执行更高的 DDR 频率来进行寄存器的延迟,而不是使用 CLB 寄存器。下图显示了使用 SAME_EDGE 模式的输出 DDR 的时序图。
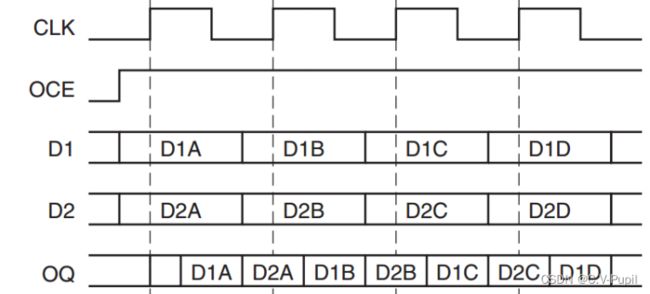
本节设计模式采用 SAME_EDGE 模式。
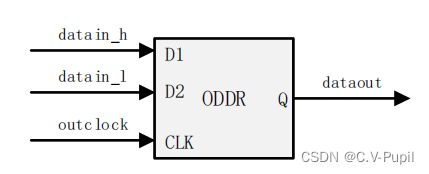
在 TMDS 发送中,数据从 FPGA 发出,所以只需要使用 ddio_out 核即可。下图为 1 位的
ddio_out 核示意图。
DVI 总共有 4 个通道,其中三个通道为数据通道。由于每个通道需要在 5 个时钟周期内完成 10 位数据的输出,且输出时,从低位开始顺序输出,所以需要每时钟周期切换一次送给 datain_h 和 data_l 端口的数据,具体每个时钟周期对应的 datain_h 和 datain_l 上连接的数据如下表所示:

所以实现时,只需要使用一个计数器,循环的对 5 个时钟周期计数(计数器计数满 4 之后下一个时钟周期既清零,或称为模 5 计数器),并使用计数器的输出值作为多路选择器的选择端,选择当前将 q_out 中的哪两位数据接到 datain_h 和 datain_l 上。据此可以绘制出如下所示的逻辑电图:
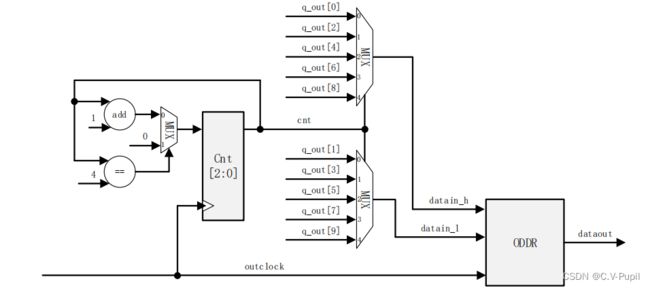
上述图中,使用的是多路器的思路来选择切换 q_out 中的每一位,事实上,也可以使用移位寄存器的方式来实现移位。
3.4.3 编码实现
/
// Module Name : serdes_4b_10to1
// Description : 4路信号并行10bit转串行
// Name : 小王在努力...
// Revision :Vivado 2018.3
/
module serdes_4b_10to1(
clkx5,
datain_0,
datain_1,
datain_2,
datain_3,
dataout_0_p,
dataout_0_n,
dataout_1_p,
dataout_1_n,
dataout_2_p,
dataout_2_n,
dataout_3_p,
dataout_3_n
);
input clkx5; // 5x clock input
input [9:0] datain_0; // input data for serialisation
input [9:0] datain_1; // input data for serialisation
input [9:0] datain_2; // input data for serialisation
input [9:0] datain_3; // input data for serialisation
output dataout_0_p; // out DDR data
output dataout_0_n; // out DDR data
output dataout_1_p; // out DDR data
output dataout_1_n; // out DDR data
output dataout_2_p; // out DDR data
output dataout_2_n; // out DDR data
output dataout_3_p; // out DDR data
output dataout_3_n; // out DDR data
wire dataout_0_n;
wire dataout_1_n;
wire dataout_2_n;
wire dataout_3_n;
reg [2:0] TMDS_mod5 = 0; // 模5计数器
reg [4:0] TMDS_shift_0h = 0, TMDS_shift_0l = 0;
reg [4:0] TMDS_shift_1h = 0, TMDS_shift_1l = 0;
reg [4:0] TMDS_shift_2h = 0, TMDS_shift_2l = 0;
reg [4:0] TMDS_shift_3h = 0, TMDS_shift_3l = 0;
wire [4:0] TMDS_0_l = {datain_0[9],datain_0[7],datain_0[5],datain_0[3],datain_0[1]};
wire [4:0] TMDS_0_h = {datain_0[8],datain_0[6],datain_0[4],datain_0[2],datain_0[0]};
wire [4:0] TMDS_1_l = {datain_1[9],datain_1[7],datain_1[5],datain_1[3],datain_1[1]};
wire [4:0] TMDS_1_h = {datain_1[8],datain_1[6],datain_1[4],datain_1[2],datain_1[0]};
wire [4:0] TMDS_2_l = {datain_2[9],datain_2[7],datain_2[5],datain_2[3],datain_2[1]};
wire [4:0] TMDS_2_h = {datain_2[8],datain_2[6],datain_2[4],datain_2[2],datain_2[0]};
wire [4:0] TMDS_3_l = {datain_3[9],datain_3[7],datain_3[5],datain_3[3],datain_3[1]};
wire [4:0] TMDS_3_h = {datain_3[8],datain_3[6],datain_3[4],datain_3[2],datain_3[0]};
// 5倍速度移位发送数据
always @(posedge clkx5)
begin
TMDS_mod5 <= (TMDS_mod5[2]) ? 3'd0 : TMDS_mod5 + 3'd1;
TMDS_shift_0h <= TMDS_mod5[2] ? TMDS_0_h : TMDS_shift_0h[4:1];
TMDS_shift_0l <= TMDS_mod5[2] ? TMDS_0_l : TMDS_shift_0l[4:1];
TMDS_shift_1h <= TMDS_mod5[2] ? TMDS_1_h : TMDS_shift_1h[4:1];
TMDS_shift_1l <= TMDS_mod5[2] ? TMDS_1_l : TMDS_shift_1l[4:1];
TMDS_shift_2h <= TMDS_mod5[2] ? TMDS_2_h : TMDS_shift_2h[4:1];
TMDS_shift_2l <= TMDS_mod5[2] ? TMDS_2_l : TMDS_shift_2l[4:1];
TMDS_shift_3h <= TMDS_mod5[2] ? TMDS_3_h : TMDS_shift_3h[4:1];
TMDS_shift_3l <= TMDS_mod5[2] ? TMDS_3_l : TMDS_shift_3l[4:1];
end
/
//Altera FPGA DDIO
/
// altddio_out altddio_out_0(
// .datain_h ({TMDS_shift_3h[0],TMDS_shift_2h[0],TMDS_shift_1h[0],TMDS_shift_0h[0]}),
// .datain_l ({TMDS_shift_3l[0],TMDS_shift_2l[0],TMDS_shift_1l[0],TMDS_shift_0l[0]}),
// .outclock (clkx5 ),
// .dataout ({dataout_3_p,dataout_2_p,dataout_1_p,dataout_0_p}),
// .aclr (1'b0 ),
// .aset (1'b0 ),
// .oe (1'b1 ),
// .oe_out ( ),
// .outclocken (1'b1 ),
// .sclr (1'b0 ),
// .sset (1'b0 )
// );
// defparam
// altddio_out_0.extend_oe_disable = "OFF",
// altddio_out_0.invert_output = "OFF",
// altddio_out_0.lpm_hint = "UNUSED",
// altddio_out_0.lpm_type = "altddio_out",
// altddio_out_0.oe_reg = "UNREGISTERED",
// altddio_out_0.power_up_high = "OFF",
// altddio_out_0.width = 4;
// altddio_out altddio_out_1(
// .datain_h (~{TMDS_shift_3h[0],TMDS_shift_2h[0],TMDS_shift_1h[0],TMDS_shift_0h[0]}),
// .datain_l (~{TMDS_shift_3l[0],TMDS_shift_2l[0],TMDS_shift_1l[0],TMDS_shift_0l[0]}),
// .outclock (clkx5 ),
// .dataout ({dataout_3_n,dataout_2_n,dataout_1_n,dataout_0_n}),
// .aclr (1'b0 ),
// .aset (1'b0 ),
// .oe (1'b1 ),
// .oe_out ( ),
// .outclocken (1'b1 ),
// .sclr (1'b0 ),
// .sset (1'b0 )
// );
// defparam
// altddio_out_1.extend_oe_disable = "OFF",
// altddio_out_1.invert_output = "OFF",
// altddio_out_1.lpm_hint = "UNUSED",
// altddio_out_1.lpm_type = "altddio_out",
// altddio_out_1.oe_reg = "UNREGISTERED",
// altddio_out_1.power_up_high = "OFF",
// altddio_out_1.width = 4;
/
/
//Xilinx FPGA ODDR
/
ODDR #(
.DDR_CLK_EDGE("SAME_EDGE"), // "OPPOSITE_EDGE" or "SAME_EDGE"
.INIT(1'b0), // Initial value of Q: 1'b0 or 1'b1
.SRTYPE("SYNC") // Set/Reset type: "SYNC" or "ASYNC"
) ODDR_0 (
.Q (dataout_0 ),// 1-bit DDR output
.C (clkx5 ),// 1-bit clock input
.CE(1'b1 ),// 1-bit clock enable input
.D1(TMDS_shift_0h[0] ),// 1-bit data input (positive edge)
.D2(TMDS_shift_0l[0] ),// 1-bit data input (negative edge)
.R (1'b0 ),// 1-bit reset
.S (1'b0 ) // 1-bit set
);
OBUFDS #(
.IOSTANDARD("DEFAULT"), // Specify the output I/O standard
.SLEW("SLOW") // Specify the output slew rate
) OBUFDS_0 (
.O (dataout_0_p ),// Diff_p output (connect directly to top-level port)
.OB (dataout_0_n ),// Diff_n output (connect directly to top-level port)
.I (dataout_0 ) // Buffer input
);
ODDR #(
.DDR_CLK_EDGE("SAME_EDGE"), // "OPPOSITE_EDGE" or "SAME_EDGE"
.INIT(1'b0), // Initial value of Q: 1'b0 or 1'b1
.SRTYPE("SYNC") // Set/Reset type: "SYNC" or "ASYNC"
) ODDR_1 (
.Q (dataout_1 ),// 1-bit DDR output
.C (clkx5 ),// 1-bit clock input
.CE(1'b1 ),// 1-bit clock enable input
.D1(TMDS_shift_1h[0] ),// 1-bit data input (positive edge)
.D2(TMDS_shift_1l[0] ),// 1-bit data input (negative edge)
.R (1'b0 ),// 1-bit reset
.S (1'b0 ) // 1-bit set
);
OBUFDS #(
.IOSTANDARD("DEFAULT"), // Specify the output I/O standard
.SLEW("SLOW") // Specify the output slew rate
) OBUFDS_1 (
.O (dataout_1_p ),// Diff_p output (connect directly to top-level port)
.OB (dataout_1_n ),// Diff_n output (connect directly to top-level port)
.I (dataout_1 ) // Buffer input
);
ODDR #(
.DDR_CLK_EDGE("SAME_EDGE"), // "OPPOSITE_EDGE" or "SAME_EDGE"
.INIT(1'b0), // Initial value of Q: 1'b0 or 1'b1
.SRTYPE("SYNC") // Set/Reset type: "SYNC" or "ASYNC"
) ODDR_2 (
.Q (dataout_2 ),// 1-bit DDR output
.C (clkx5 ),// 1-bit clock input
.CE(1'b1 ),// 1-bit clock enable input
.D1(TMDS_shift_2h[0] ),// 1-bit data input (positive edge)
.D2(TMDS_shift_2l[0] ),// 1-bit data input (negative edge)
.R (1'b0 ),// 1-bit reset
.S (1'b0 ) // 1-bit set
);
OBUFDS #(
.IOSTANDARD("DEFAULT"), // Specify the output I/O standard
.SLEW("SLOW") // Specify the output slew rate
) OBUFDS_2 (
.O (dataout_2_p ),// Diff_p output (connect directly to top-level port)
.OB (dataout_2_n ),// Diff_n output (connect directly to top-level port)
.I (dataout_2 ) // Buffer input
);
ODDR #(
.DDR_CLK_EDGE("SAME_EDGE"), // "OPPOSITE_EDGE" or "SAME_EDGE"
.INIT(1'b0), // Initial value of Q: 1'b0 or 1'b1
.SRTYPE("SYNC") // Set/Reset type: "SYNC" or "ASYNC"
) ODDR_3 (
.Q (dataout_3 ),// 1-bit DDR output
.C (clkx5 ),// 1-bit clock input
.CE(1'b1 ),// 1-bit clock enable input
.D1(TMDS_shift_3h[0] ),// 1-bit data input (positive edge)
.D2(TMDS_shift_3l[0] ),// 1-bit data input (negative edge)
.R (1'b0 ),// 1-bit reset
.S (1'b0 ) // 1-bit set
);
OBUFDS #(
.IOSTANDARD("DEFAULT"), // Specify the output I/O standard
.SLEW("SLOW") // Specify the output slew rate
) OBUFDS_3 (
.O (dataout_3_p ),// Diff_p output (connect directly to top-level port)
.OB (dataout_3_n ),// Diff_n output (connect directly to top-level port)
.I (dataout_3 ) // Buffer input
);
/
endmodule
另外,对于 TMDS,其传输时使用的是差分传输方式,既对每一个通道都使用 2 根信号线,两根信号线传输的电平刚好相反,所以在最终输出时,需要再使用 Xilinx 的 OBUFDS 原语,用来将上述 ODDR 模块输出信号转成差分信号输出。

差分信号输出波形结果如下:
![]()
3.4.4 serdes_4b_10to1仿真展示
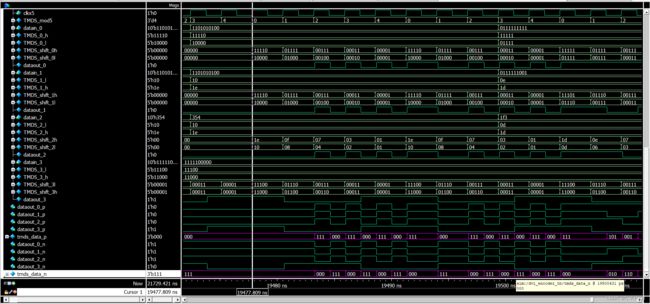
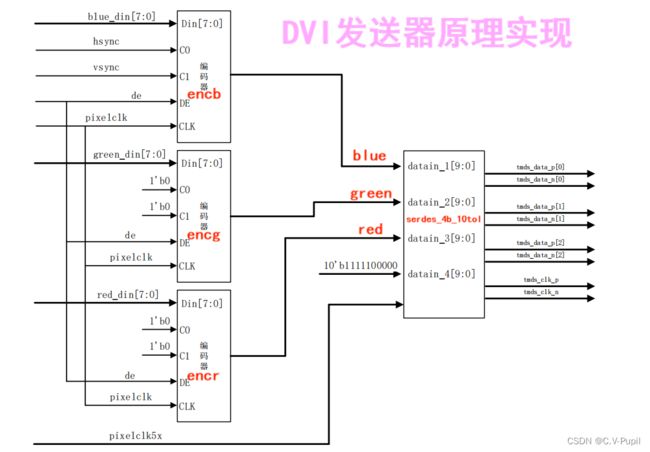
3.5 DVI 发送器实现
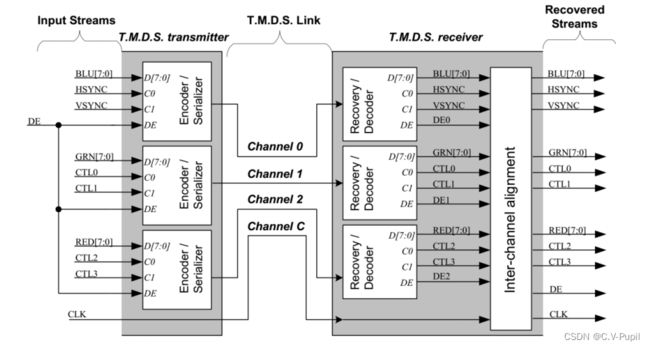
完成了底层编码和串行发送器的设计之后,对于 DVI 接口,只需要将编码器和发送器例化并与图像数据流的数据和控制信号按照 DVI 规范链接到一起即可。如下图所示:
TMDS 要求在发送时将像素时钟随数据一起发送,注意,这里的时钟频率应该是和pixelclk 的频率一致,而不是和 pixelclk5x 一致,也就是说,tmds_clk 并不是数据的位同步时钟而是一个完整编码数据的同步时钟,每次 tmds_clk 的下降沿标志着新的 10 位数据的开始发送。tmds_clk 和 data 的关系如下图所示。

为了产生 tmds_clk,有两种方式,一种方式是直接将 pixelclk 及其取反信号输出作为tmds_clk,另一种方式是使用 ODDR 以数据的形式产生。使用 ODDR 以数据的形式产生,能够一定程度上保证输出的 tmds_clk 和 tmds_data 之间拥有相同的相位关系,便于数据在接收端进行同步,所以这里使用 ODDR 以数据的形式产生。产生这种波形的方式很简单,就是让 ODDR 引脚的前 2.5 个时钟周期输出低电平,后 2.5 个时钟周期输出高电平即可。此时,只需要对串行发送器的 datain_3 端口赋值一个常量 10’b1111100000 即可。完整的 DVI 编码发送器顶层如下所示。
/
// Module Name : dvi_encoder
// Description : rgb转tmds(hdmi)
// Name : 小王在努力...
// Revision :Vivado 2018.3
/
module dvi_encoder(
pixelclk,
pixelclk5x,
rst_p,
blue_din,
green_din,
red_din,
hsync,
vsync,
de,
tmds_clk_p,
tmds_clk_n,
tmds_data_p,
tmds_data_n
);
input pixelclk; // system clock
input pixelclk5x; // system clock x5
input rst_p; // reset
input [7:0] blue_din; // Blue data in
input [7:0] green_din; // Green data in
input [7:0] red_din; // Red data in
input hsync; // hsync data
input vsync; // vsync data
input de; // data enable
output tmds_clk_p; //clock
output tmds_clk_n; //clock
output [2:0] tmds_data_p; //rgb
output [2:0] tmds_data_n; //rgb
wire [9:0] red;
wire [9:0] green;
wire [9:0] blue;
encode encb(
.clk (pixelclk ),
.rst_p (rst_p ),
.din (blue_din ),
.c0 (hsync ),
.c1 (vsync ),
.de (de ),
.dout (blue )
);
encode encr(
.clk (pixelclk ),
.rst_p (rst_p ),
.din (green_din ),
.c0 (1'b0 ),
.c1 (1'b0 ),
.de (de ),
.dout (green )
);
encode encg(
.clk (pixelclk ),
.rst_p (rst_p ),
.din (red_din ),
.c0 (1'b0 ),
.c1 (1'b0 ),
.de (de ),
.dout (red )
);
serdes_4b_10to1 serdes_4b_10to1_inst(
.clkx5 (pixelclk5x ),// 5x clock input
.datain_0 (blue ),// input data for serialisation
.datain_1 (green ),// input data for serialisation
.datain_2 (red ),// input data for serialisation
.datain_3 (10'b1111100000 ),// input data for serialisation
.dataout_0_p (tmds_data_p[0] ),// out DDR data
.dataout_0_n (tmds_data_n[0] ),// out DDR data
.dataout_1_p (tmds_data_p[1] ),// out DDR data
.dataout_1_n (tmds_data_n[1] ),// out DDR data
.dataout_2_p (tmds_data_p[2] ),// out DDR data
.dataout_2_n (tmds_data_n[2] ),// out DDR data
.dataout_3_p (tmds_clk_p ),// out DDR data
.dataout_3_n (tmds_clk_n ) // out DDR data
);
endmodule
至此,整个串行发送模块的设计思路就完全介绍清楚了。
四、基于 DVI 接口的串口传图实验
4.1 串口传图实验
设计完成该控制器之后,在使用时,只需要基于基本的 VGA 或者 TFT 显示系统,将 VGA或 TFT 控制器逻辑的相关信号接到 dvi_encoder 的对应端口上即可。如下图所示:
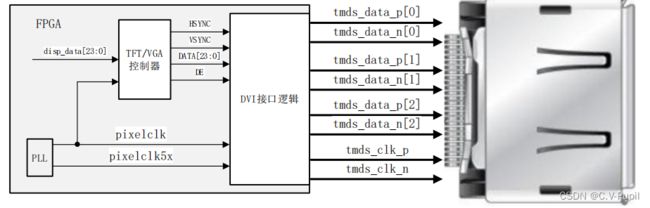
可以看到,在上述框图中,只是将传统的直接输出到 FPGA 管脚的 VGA/TFT 控制器的输出信号接到了 DVI 接口逻辑的对应输入接口,即可实现 HDMI 接口的图像发送所以,使用该DVI 接口逻辑不会改变原有图像显示系统的框架结构,只是对最终输出的信号多加入了一级变换处理而已。
本次实验将在基于 DDR3 的串口传图帧缓存系统设计实现的基础上增加HDMI显示效果,其只需要添加本次设计的dvi_encoder模块即可。
`timescale 1ns / 1ps
//
// Create Date: 2023/06/20 08:58:45
// Name : 小王在努力...
// Revision :Vivado 2018.3
// Module Name: uart_fifo_ddr3_fifo_tft
//
module uart_fifo_ddr3_fifo_tft(
//System clock reset
input clk50m , //系统时钟输入,50MHz
input reset_n , //复位信号输入
//LED
output [3:0] led ,
//Uart interface
input uart_rx , //串口输入信号
//TFT Interface
output [15:0] TFT_rgb , //TFT数据输出
output TFT_hs , //TFT行同步信号
output TFT_vs , //TFT场同步信号
output TFT_clk , //TFT像素时钟
output TFT_de , //TFT数据使能
output TFT_PWM , //TFT背光控制
//hdmi1 interface
output hdmi1_clk_p,
output hdmi1_clk_n,
output [2:0]hdmi1_dat_p,
output [2:0]hdmi1_dat_n,
output hdmi1_oe,
//hdmi2 interface
output hdmi2_clk_p,
output hdmi2_clk_n,
output [2:0] hdmi2_dat_p,
output [2:0] hdmi2_dat_n,
output hdmi2_oe,
//DDR3 Interface
// Inouts
inout [15:0] ddr3_dq ,
inout [1:0] ddr3_dqs_n ,
inout [1:0] ddr3_dqs_p ,
// Outputs
output [13:0] ddr3_addr ,
output [2:0] ddr3_ba ,
output ddr3_ras_n ,
output ddr3_cas_n ,
output ddr3_we_n ,
output ddr3_reset_n ,
output [0:0] ddr3_ck_p ,
output [0:0] ddr3_ck_n ,
output [0:0] ddr3_cke ,
output [0:0] ddr3_cs_n ,
output [1:0] ddr3_dm ,
output [0:0] ddr3_odt
);
//pll interface
wire loc_clk200M;
wire loc_clk33M ;
wire loc_clk50M ;
wire loc_clk165M;
wire pll_locked ;
//uart Interface
wire [7:0]uart_byte ;
wire uart_byte_vaild;
//bit8_trans_bit16 interface
wire [15:0]image_data;
wire image_data_valid;
// frame_rx_done_flip interface
reg [15:0] image_data_hcnt ;
reg [15:0] image_data_vcnt ;
reg image_data_hs ;
reg image_data_vs ;
reg frame_rx_done_flip;
// fifo_mig_axi_fifo Interface
wire [15:0]rdfifo_dout ;
wire ui_clk ;
wire ui_clk_sync_rst ;
wire mmcm_locked ;
wire init_calib_complete;
wire rdfifo_rden ;
//disp_driver interface
wire frame_begin;
wire [4:0]disp_blue;
wire [5:0]disp_green;
wire [4:0]disp_red;
parameter DISP_WIDTH = 16'd800;
parameter DISP_HEIGHT= 16'd480;
assign led = {frame_rx_done_flip,init_calib_complete,mmcm_locked,pll_locked};
pll pll
(
// Clock out ports
.clk_out1 (loc_clk50M ), // output clk_out1
.clk_out2 (loc_clk200M ), // output clk_out2
.clk_out3 (loc_clk33M ), // output clk_out3
.clk_out4 (loc_clk165M ), // output clk_out4
// Status and control signals
.resetn (reset_n ), // input reset
.locked (pll_locked ), // output locked
// Clock in ports
.clk_in1 (clk50m ) // input clk_in1
);
uart_byte_rx#(
.CLK_FRQ(1000000000)
)
uart_byte_rx(
.clk (loc_clk50M ),
.reset_p (ui_clk_sync_rst ),
.baud_set (3'd5 ), //1562500bps
.uart_rx (uart_rx ),
.data_byte(uart_byte ),
.rx_done (uart_byte_vaild ) //一个字节数据有效的标志
);
bit8_trans_bit16 bit8_trans_bit16
(
.clk (loc_clk50M ),
.reset_p (ui_clk_sync_rst ),
.bit8_in (uart_byte ),
.bit8_in_valid (uart_byte_vaild ),
.bit16_out (image_data ),
.bit16_out_valid (image_data_valid)
);
//-------------------------------------------------------------------------------------------
//generate image data hs or vs观察数据是否产生了800*480
always@(posedge loc_clk50M or posedge ui_clk_sync_rst)
if(ui_clk_sync_rst)
image_data_hcnt <= 'd0;
else if(image_data_valid) begin
if(image_data_hcnt == (DISP_WIDTH - 1'b1))
image_data_hcnt <= 'd0;
else
image_data_hcnt <= image_data_hcnt + 1'b1;
end
always@(posedge loc_clk50M or posedge ui_clk_sync_rst)
if(ui_clk_sync_rst)
image_data_vcnt <= 'd0;
else if(image_data_valid) begin
if(image_data_hcnt == (DISP_WIDTH - 1'b1)) begin
if(image_data_vcnt == (DISP_HEIGHT - 1'b1))
image_data_vcnt <= 'd0;
else
image_data_vcnt <= image_data_vcnt + 1'b1;
end
end
//hs
always@(posedge loc_clk50M or posedge ui_clk_sync_rst)
if(ui_clk_sync_rst)
image_data_hs <= 1'b0;
else if(image_data_valid && image_data_hcnt == (DISP_WIDTH - 1'b1))
image_data_hs <= 1'b0;
else
image_data_hs <= 1'b1;
//vs
always@(posedge loc_clk50M or posedge ui_clk_sync_rst)
if(ui_clk_sync_rst)
image_data_vs <= 1'b0;
else if(image_data_valid && image_data_hcnt == (DISP_WIDTH - 1'b1) &&
image_data_vcnt == (DISP_HEIGHT - 1'b1))
image_data_vs <= 1'b0;
else
image_data_vs <= 1'b1;
always@(posedge loc_clk50M or posedge ui_clk_sync_rst)
if(ui_clk_sync_rst)
frame_rx_done_flip <= 1'b0;
else if(image_data_valid && image_data_hcnt == (DISP_WIDTH - 1'b1) &&
image_data_vcnt == (DISP_HEIGHT - 1'b1))
frame_rx_done_flip <= ~frame_rx_done_flip;
//-------------------------------------------------------------------------------------------
fifo_mig_axi_fifo
#(
. WR_DDR_ADDR_BEGIN ( 0 ) ,
. WR_DDR_ADDR_END ( DISP_WIDTH*DISP_HEIGHT*2 ) ,
. RD_DDR_ADDR_BEGIN ( 0 ) ,
. RD_DDR_ADDR_END ( DISP_WIDTH*DISP_HEIGHT*2 ) ,
. AXI_ID ( 4'b0000 )
)fifo_mig_axi_fifo
(
//wr_ddr3_fifo ports
. wrfifo_rst (ui_clk_sync_rst ) ,
. loc_clk50M (loc_clk50M ) ,
. wrfifo_din (image_data ) ,
. wrfifo_wren (image_data_valid ) ,
//rd_ddr3_fifo ports
. rdfifo_rst (ui_clk_sync_rst || frame_begin) ,
. loc_clk33M (loc_clk33M ) ,
. rdfifo_rden (rdfifo_rden ) ,
. rdfifo_dout (rdfifo_dout ) ,
//DDR3 Interface
//input
. loc_clk200M (loc_clk200M ) ,
. xx_sys_rst (pll_locked ) , //用于连接 pll_locked
. xx_aresetn (pll_locked ) , //用于连接 pll_locked
//output
. ui_clk (ui_clk ) ,
. ui_clk_sync_rst (ui_clk_sync_rst ) ,
. mmcm_locked (mmcm_locked ) ,
. init_calib_complete(init_calib_complete) ,
//DDR3 Interface
// Inouts
. ddr3_dq (ddr3_dq ) ,
. ddr3_dqs_n (ddr3_dqs_n ) ,
. ddr3_dqs_p (ddr3_dqs_p ) ,
// Outputs
. ddr3_addr (ddr3_addr ) ,
. ddr3_ba (ddr3_ba ) ,
. ddr3_ras_n (ddr3_ras_n ) ,
. ddr3_cas_n (ddr3_cas_n ) ,
. ddr3_we_n (ddr3_we_n ) ,
. ddr3_reset_n (ddr3_reset_n) ,
. ddr3_ck_p (ddr3_ck_p ) ,
. ddr3_ck_n (ddr3_ck_n ) ,
. ddr3_cke (ddr3_cke ) ,
. ddr3_cs_n (ddr3_cs_n ) ,
. ddr3_dm (ddr3_dm ) ,
. ddr3_odt (ddr3_odt )
);
disp_driver disp_driver
(
.ClkDisp (loc_clk33M ),
.Rst_p (ui_clk_sync_rst),
.Data (rdfifo_dout ),
.DataReq (rdfifo_rden ),
.Disp_HS (disp_hs ),
.Disp_VS (disp_vs ),
.Disp_Red (disp_red ),
.Disp_Green (disp_green ),
.Disp_Blue (disp_blue ),
.Frame_Begin (frame_begin ),
.Disp_DE (disp_de ),
.Disp_PCLK (TFT_clk ),
.TFT_PWM (TFT_PWM )
);
assign TFT_hs = disp_hs;
assign TFT_vs = disp_vs;
assign TFT_de = disp_de;
assign TFT_rgb = {disp_red,disp_green,disp_blue};
//HDMI1
dvi_encoder dvi_encoder1(
.pixelclk (loc_clk33M ),
.pixelclk5x (loc_clk165M ),
.rst_p (ui_clk_sync_rst ),
.blue_din ({disp_blue ,3'b000} ),
.green_din ({disp_green,2'b00 } ),
.red_din ({disp_red ,3'b000} ),
.hsync (disp_hs ),
.vsync (disp_vs ),
.de (disp_de ),
.tmds_clk_p (hdmi1_clk_p ),
.tmds_clk_n (hdmi1_clk_n ),
.tmds_data_p (hdmi1_dat_p ),
.tmds_data_n (hdmi1_dat_n )
);
assign hdmi1_oe = 1'b1;
//HDMI2
dvi_encoder dvi_encoder2(
.pixelclk (loc_clk33M ),
.pixelclk5x (loc_clk165M ),
.rst_p (ui_clk_sync_rst ),
.blue_din ({disp_blue ,3'b000} ),
.green_din ({disp_green,2'b00 } ),
.red_din ({disp_red ,3'b000} ),
.hsync (disp_hs ),
.vsync (disp_vs ),
.de (disp_de ),
.tmds_clk_p (hdmi2_clk_p ),
.tmds_clk_n (hdmi2_clk_n ),
.tmds_data_p (hdmi2_dat_p ),
.tmds_data_n (hdmi2_dat_n )
);
assign hdmi2_oe = 1'b1;
endmodule
4.2 上板展示

【附件:】https://pan.baidu.com/s/1NWh0b5x_cpvhNlwGFoZqtQ?pwd=4ql0
提取码:4ql0