【AI底层逻辑】——篇章3(上):数据、信息与知识&香农信息论&信息熵
目录
引入
一、数据、信息、知识
二、“用信息丈量世界”
1、香农信息三定律
2、一条信息的价值
3、信息的熵
总结
引入
AI是一种处理信息的模型,我们把信息当作一种内容的载体,计算机发明以前很少有人思考它的本质是什么。随着通信技术的发展,很多关于信息处理的问题接踵而至,如不知如何把信息有效地编码成通信信号、如何在不可靠的网络环境下传输信息等。
人们发现,信息本身很难被定性或定量地描述清楚,它是一种逻辑概念,如果要通过计算机这样的物理装置准确传递出去,就必须对信息有一种全新的解读。中间有许多技术难点,关键一点是必须把信息处理转换成数学模型,另外一旦涉及通信问题,干扰信息的噪声就会无处不在,必须有方法处理它们。
一、数据、信息、知识
关于信息处理的理论称为信息论,专门研究有关信息处理和可靠传输的一般规律,它对于计算机技术的发展具有重大意义。为了阐释此理论,先简单介绍数据、信息、知识3个概念:
以一个实例引入:如随意给3个数字99、39、132,这三个数字仅仅是数据,现在给它们一些说明如鞋子价格99元,今天气温39℃,我的体重132斤,此时这些数据有了明确含义就成了信息。再加入一些判断,如鞋子不算特别贵,今天北京真是热死了,我的体重与身高匹配十分正常等,做出这些判断依赖于平时的经验和常识,即知识。

①数据是一组有意义的符号
如果只把数字、字符、字母这些的集合当作数据,是不准确的,在如今的“大数据”语境中,数据是可以被记录和识别的一组有意义符号,一般可通过原始观察和度量得到。数据是对客观事物的逻辑归纳,可以用来表示一个事实、一种状态、一个实体特征、一个观察结果,有的用于描述某个对象的事实性数据,有些则是通过观察、分析、归纳得到的总结性数据。
数据可以是连续的,如无线电通信时在空气中传输的电磁波,属于模拟数据;也可以是离散的,如计算机中存储的文档和照片,属于数字数据。承载数据形式很多,不仅包括文字、数字、符号、图像、语音、视频等,也可以是对某个事物属性、数量、位置、关系的抽象表示。
②信息用来消除不确定性
数据是信息的载体,信息则是需要依托数据来表达。两者既有联系又有区别,是形与质的关系。如甲骨文上记载的仅仅是数据,要读懂这些数据就必须了解数据背后表达的含义,一旦对数据做出解释,就能得到甲骨文的信息。
1928年哈特莱在《信息传输》中首次提出将信息定量化的设想;1948年信息论创始人香农在《关于通信的数学原理》指出——“信息是用来消除随机不确定性的东西”。在他看来,一旦我们想要对信息进行量化和比较,就不要去关注这些信息到底承载了什么内容,而是要看这条信息出现后,是否改变了某些不确定性事件的概率。
③知识是对信息的总结和提炼
知识从实践、经验中得到,它由数据记录,从信息中提炼。知识是高度概括的信息,如果说信息可以回答一些简单的问题,比如“谁”“在哪里”“做什么”,那么知识可以回答一些更具深刻认知的问题,比如“怎样”“为何”。人在日常生活中有很多常识,很多都是从生活实践中总结的,如火可伤人、火可熟食、热油不能遇水等。对于AI要解决的核心问题是让计算机具有常识,很多常识实际上背后有着复杂的知识体系,机器必须真正“理解”知识,而不是“记忆”它们。如计算机知道人有2只眼睛,但它无法判断这个世界是否存在1只/3只眼睛的人,如今的AI只能从数据中学习到数据之间的联系,还不能很好的处理有关常识的问题,这方面的研究之路还很长。
计算机要处理的知识与人脑里的是不同的,本质上计算机只是通过特定方法模仿人类的知识表达,并没有真正掌握这些“知识”,这个特定方法是基于图技术。图是一种表示知识的工具,是描述知识的状态、关系、路径距离等相关要素的最自然的数学表达,擅长存储和处理复杂的网状关系,所以在知识图谱、社交网络、用户关系分析等领域有着广泛的应用。
近年来,基于图技术的知识图谱是十分热门的研究领域,如维基百科就是一个典型的应用案例。知识图谱可用来描述各种实体以及它们之间的关系,是一个庞大的图形网络知识库。基本组成是“实体-关系-实体”的三元组,每个节点是一个实体,如人名、地名、事件、活动,任意两个节点之间的边表示它们之间的存在关系。知识图谱不仅能把与关键词有关的知识系统化地展示给用户,也可以基于知识进行推演,如从<东方明珠,坐落在,浦东>和<浦东,属于,上海>两个组合中推测出<东方明珠,位于,上海>。它还会不断更新迭代,用户搜索次数越多范围越广,这个知识库就能获取越多的信息和内容。
二、“用信息丈量世界”
对于计算机而言,无论是数据、信息还是知识都是逻辑运算的对象,不知道它们是什么,只要能完成相应的存储、计算和表达即可,但是有个前提条件——度量/量化它们!度量数据最简单,在计算机中表现为一个二进制数,它的存储量需求最大;信息比数据抽象一点,要用概率来描述、消除不确定性;知识的概念最为抽象,直到今天也很难度量。
1、香农信息三定律
1948年,香农发表了他在二战前后对通信和密码学的研究成果,系统论述了信息的定义、如何量化信息、如何更好地对信息编码。他用热力学中“熵”的概念描述信息的不确定性,并把通信和密码学的所有问题都看成数学问题,让信息变得可测。在“信息论”中香农提出了三个著名定律:
①香农第一定律——无失真信源编码定律。给出了有效编码信息的方法,告诉我们如何让通信信号携带尽可能大的信息量,提高信息存储和传输效率。例如,摩斯电码使用长音和短音信号组合表示不同的数字和字母,有效降低整体编码的长度。

②香农第二定律定量地描述了一个信道中的极限信息传输率和带宽的关系,它主要用来保证信息在通信和传输过程中不出错,数学表达式如下:
![]()
其中,C是信道容量,B是信道带宽,S是信号功率,N是噪声功率。根据公式,如果要增加信道容量C(即增加信息最大传输速率),最好的方法是增加带宽B(频率范围)或增加信噪比S/N。
举个例子:5G网络技术的传输速率比4G块几十倍甚至上百倍,这是因为5G使用的是毫米波(对应波长只有1mm到10mm),它的通信带宽在30GHz至300GHz,比只有100MHz频段的4G要宽的多。根据香农第二定律,在信噪比一定的条件下,信道越宽,传输速度越大,这也是5G比4G传输速度大幅提高的原因。

③香农第三定律指出信息传输率无法超过信道容量,一旦超过便无法保证可靠传输。比如听广播时,两个电台频率很接近就会产生干扰,因为一旦频率范围确定,信道容量就被固定在一个有限的范围。假设两个电台的总宽带很窄(频率范围很窄),无法承载单位时间内要传输的语音信息,即信道容量小于实际要传输信息的速率,电台内容就会听不清。此时只能让两个电台的频率间隔变大,增加总带宽而不是把收音机的频率调准。
起初科学家很难理解香农的理论,因为通过描述不确定性的概率方法解释信息,有悖于直觉上的理解。但如今,这一理论已经成为现代通信的基础框架,在科学、数学、工程等方面有着举足轻重的作用。
2、一条信息的价值
信息具有价值,但不同信息的价值程度不同,那么该如何衡量一条信息的价值呢?1948年,香农在《关于通信的数学原理》中提出了一种方法真正解决了信息的度量问题——他认为信息是用来消除不确定性的,哪条信息能够消除的不确定性大,哪条信息的信息量就大。也就是说量化信息不是看信息的重要性,也不管其含义和数量,而只关注它可消除多大的不确定性。关于信息量的数学模型至少应该体现一下几点:
①要能反映信息大小和事件概率之间的关系。简单说,事件发生的概率越小,信息量就越大,如果事件概率接近0,信息量就应该近似无限大;反之若事件概率为1,则信息量为0。
②多个事件发生的概率和信息量能相互联系起来。对于概率,如果两个事件同时发生,则可以把两者的概率相乘;对于信息量,它更可能是两个信息量的和。
综上,关于概率和信息量的数学函数呼之欲出,若用数学函数图像表示为:
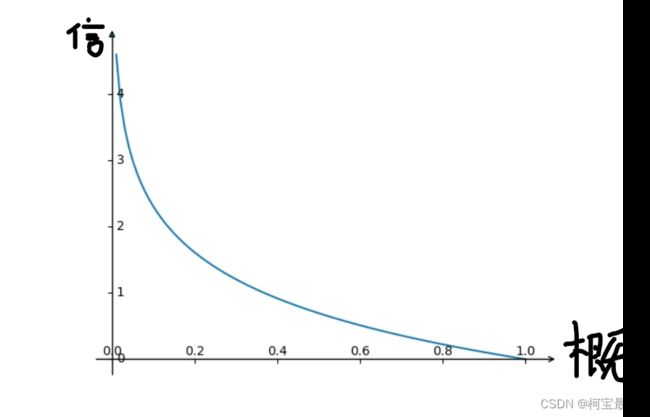
香农都是这样定义信息量的:![]() ,其中P(x)代表了事件发生的概率。该公式告诉我们:小概率事件一旦发生,就会引起人们的关注,也就是说极少见的事件会带来极大的信息量。信息量的多少与事件发生的频繁程度(即概率大小)恰好相反。注意不是反比关系。
,其中P(x)代表了事件发生的概率。该公式告诉我们:小概率事件一旦发生,就会引起人们的关注,也就是说极少见的事件会带来极大的信息量。信息量的多少与事件发生的频繁程度(即概率大小)恰好相反。注意不是反比关系。
当信息量公式的对数计算以2为底数时,它的计算结果的单位是bit(比特)。通信领域的带宽的单位就是bit/s,计算机系统中数据存储的最小单位是bit。如抛一枚硬币出现正反面的概率都是0.5,所以硬币正面朝上的信息量是![]() 。
。
重复的信息没有价值。以数据分析为例,对于数据分析人员面对海量的数据,通常需要建立一个基于数据训练出的数据模型,如果训练时一开始就把所有数据输入模型去训练,那么之后无论再训练多少次,模型都不会有明显改善,因为从信息论的角度,用同样的数据重复训练模型无意义(重复训练给模型的信息量是0)。那么我们应该如何训练模型——通常情况下,在模型训练前可以把数据分成多份,比如按3:1:1的比例分成用于模型训练的训练集数据、用于模型效果验证的验证集数据(记录下模型预测的准确率,确定效果最佳的模型)和用于模型最终测试的测试集数据(评估模型性能和分类能力)。——可形象为课本、作业、考卷三部分。
3、信息的熵
信息量度量的是一个具体事件所携带的信息,这个事件是已知的。不过有时,我们会面对一个充满不确定性的复杂系统,要度量其信息状况,就要计算各种可能发生的事件所带来的信息量的期望,此时可使用信息熵。信息熵是对信息的杂乱程度的量化描述:
![]() ,其中
,其中![]()
信息熵代表了每个事件发生的概率乘以这些事件发生时的信息量的总和。公式中对数的底数也可以是其他数,但是要明白计算信息熵的目的是量化和比较,所以应该保证底数相同。

本质:信息熵是在结果出来之前对可能产生的信息量的期望,它考虑随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。概括说,信息越确定、越单一,信息熵就越小;信息越不确定、越混乱,信息熵就越大。
应用:AI领域很多主流的机器学习算法都会运用信息熵,如决策树算法,是一种高效的分类算法。在构建该决策树模型时,算法会计算和比较不同特征划分后的信息熵。如果说某个特征可以让无序数据变得更加有序,也就是信息熵的变化更大(减小的更多),这个特征就具备更强的分类能力,找到这些特征是构建决策树的关键。
拓:“熵”由热力学中的概念而来,在希腊中的含义是“变化”或“进化”,中文译名“火”字旁代表能量和温度,“商”表示数学运算的除法。熵关注的是物体不对外做功时内部的能量情况,等温条件下一个物体增加的熵等于它的吸热量与温度的比值,即热能相对温度的变化率。
总结
以上讨论了数据、信息、知识的概念;香农信息三定律;信息价值的度量;信息熵的概念。随后我们还将讨论信息的交换、信息的加密和信息中的噪声等内容!
往期精彩:
【机器学习】——卷积神经网络
【AI底层逻辑】——篇章1&2:统计学与概率论&数据“陷阱”