Hive优化
1.HQL优化思路
Hive的优化主要分为:配置优化、SQL语句优化、任务优化等方案。其中在开发过程中主要涉及到的可能是SQL优化这块。
优化的核心思想是:
- 减少数据量(例如分区、列剪裁)
- 避免数据倾斜(例如加参数、Key打散)
- 避免全表扫描(例如on添加加上分区等)
- 减少job数(例如相同的on条件的join放在一起作为一个任务)
2.HQL语句优化
1.使用分区剪裁、列剪裁
在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
select a.*
from a
left join b on a.uid = b.uid
where a.ds='2020-08-10'
and b.ds='2020-08-10'
上面这个SQL主要犯了两个错误:
- 副表(上方b表)的where条件写在join后面,会导致先全表关联在过滤分区。
注:虽然a表的where条件也写在join后面,但是a表会进行谓词下推,也就是先执行where条件,再执行join,但是b表不会进行谓词下推!
- on的条件没有过滤null值的情况,如果两个数据表存在大批量null值的情况,会造成数据倾斜。
select a.*
from a
left join b on (d.uid is not null and a.uid = b.uid and b.ds='2020-08-10')
where a.ds='2020-08-10'
如果null值也是需要的,那么需要在条件上转换,或者单独拿出来
select a.*
from a
left join b on (a.uid is not null and a.uid = b.uid and b.ds='2020-08-10')
where a.ds='2020-08-10'
union all
select a.* from a where a.uid is null
2. 分组聚合
一个分组聚合的查询语句,默认是通过一个MapReduce Job完成的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个Hash Table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至Reduce端,完成最终的聚合。
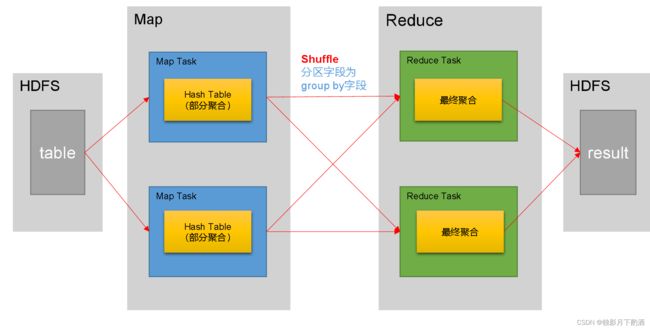
--启用map-side聚合,默认是true
set hive.map.aggr=true;
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
3.尽量不要用COUNT DISTINCT
因为COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换,虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
select count(distinct uid)
from test
where ds='2020-08-10' and uid is not null
-- 转换后
select count(a.uid)
from
(select uid
from test
where uid is not null and ds = '2020-08-10'
group by uid
) a
4.大小表的join
写有Join操作的查询语句时有一条原则:**应该将条目少的表/子查询放在Join操作符的左边。**原因是在Join操作的Reduce阶段,位于Join操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生OOM错误的几率。**但新版的hive已经对小表JOIN大表和大表JOIN小表进行了优化。小表放在左边和右边已经没有明显区别。**不过在做join的过程中通过小表在前可以适当的减少数据量,提高效率。
--启动Map Join自动转换
set hive.auto.convert.join=true;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
--无条件转Map Join小表阈值,默认值10M,推荐设置为Map Task总内存的三分之一到二分之一
set hive.auto.convert.join.noconditionaltask.size=10000000;
5.小文件合并
根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并。
--开启合并map only任务输出的小文件
set hive.merge.mapfiles=true;
--开启合并map reduce任务输出的小文件
set hive.merge.mapredfiles=true;
--合并后的文件大小
set hive.merge.size.per.task=256000000;
--触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;
6.CBO优化
CBO是指Cost based Optimizer,即基于计算成本的优化。
在Hive中,计算成本模型考虑到了:数据的行数、CPU、本地IO、HDFS IO、网络IO等方面。Hive会计算同一SQL语句的不同执行计划的计算成本,并选出成本最低的执行计划。目前CBO在Hive的MR引擎下主要用于Join的优化,例如多表Join的Join顺序。
--是否启用cbo优化
set hive.cbo.enable=true;
7.分区
-
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹。
-
Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。
-
在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
-
分区表的目的:分散数据、避免全表扫描
-- 开启动态分区功能(默认true,开启) set hive.exec.dynamic.partition=true; -- 设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。) set hive.exec.dynamic.partition.mode=nonstrict
8.数据倾斜
数据倾斜的原理都知道,就是某一个或几个key占据了整个数据的90%,这样整个任务的效率都会被这个key的处理拖慢,同时也可能会因为相同的key会聚合到一起造成内存溢出。
-
数据倾斜只会发生在shuffle过程中。
-
可能会触发shuffle操作的算子:distinct、 groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等
数据倾斜的解决方案
1.分组聚合导致的数据倾斜
-
判断倾斜的值是否为null
- 若倾斜的值为null,可考虑最终结果是否需要这部分数据,若不需要,只要提前将null过滤掉,就能解决问题。
-
Map-Side聚合
-
set hive.map.aggr=true; set hive.map.aggr.hash.min.reduction=0.5; set hive.groupby.mapaggr.checkinterval=100000; set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
-
-
Skew-GroupBy优化
-
--启用分组聚合数据倾斜优化 set hive.groupby.skewindata=true;
-
2.Join导致的数据倾斜
- Map Join
- Skew Join