Hadoop集群环境搭建(我这里是搭建的一个主节点,两个从节点)
hadoop集群弄得我心力交瘁,终于弄好后决定记录一下。(以下步骤仅供参考)
一、首先,需要准备的东西(基于电脑是64位的)
1.虚拟机VMware12以上(我这里用的是VMware14)
下载链接:https://pan.baidu.com/s/1mx7913tXtVz57Ywi_gYh5A 提取码:87am
2.Linu系统CentOs6.4以上(我这里用的是Centos6.5)
下载链接:https://pan.baidu.com/s/1A2W_-VHK6SqScvWUrpkK2A 提取码:g7wy
3.jdk(我用的是jdk-8u191-linux-x64.tar)
下载链接:https://pan.baidu.com/s/1_nTzpzxvzTPyBZG4slFJgg 提取码:zdrr
4.hadoop(我用的是hadoop-2.8.0.tar)
下载链接:https://pan.baidu.com/s/14rs4tLMHpmZ_5k5jyT-Ddw 提取码:0yh4
5.先关闭防火墙 ,最好是选择永久关闭(很重要!!!!!!)
service iptables status 查看防火墙状态
service iptables stop 即时生效,重启后复原
chkconfig iptables off 永久关闭防火墙
二、部署CentOs64位操作系统
1、安装过程很简单,这里就不细述了。比如我这里就是装好的主节点名为master的,起什么名字都可以的。
2、网络配置这里选择NAT,如下图

3、设置静态IP
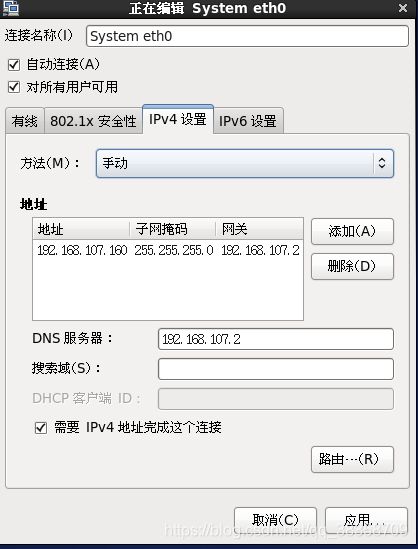
(1)指向右上角的电脑,点击右键,点击编辑连接,选择System eth0,单击编辑按钮,选择“IPv4设置”,设置如下图
(我这里用的IP是192.168.107.160)107和160那个是随便写的,写自己喜欢的一个就行了(1-254)
(2)在终端,执行命令 vim /etc/sysconfig/network-scripts/ifcfg-eth0,进去修改IPADDR,NETMASK,GATEWAY为之前设置的,记得BOOTPROTO要设置为“static”,然后保存。执行ifconfig可以查看配置效果。
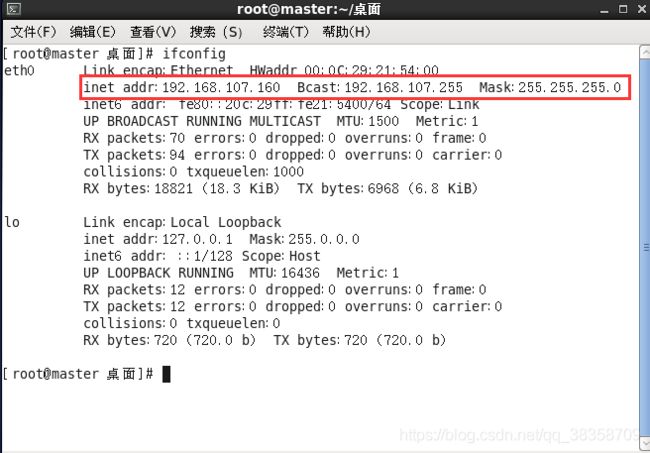
(3)修改主机名和映射文件
修改主机名,执行命令 vim /etc/sysconfig/network,将主机名修改为master(此修改需要重启后生效),下面是修改后查看效果。

修改映射文件,执行命令vim /etc/hosts,将映射关系填入,我这里的slave1和slave2为后面要建立的子节点,下面是修改后查看效果。
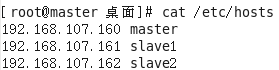
此时即可重启一下系统,使主机名修改生效。
三、JDK安装与配置
1、首先需要检测一下是否存在自带的jdk,一般情况下是没有的。执行命令java-version查看。
2、jdk的安装,把之前下载好的jdk压缩包放在系统盘的一个文件夹下(我这里是自己新建了一个simple文件夹,里面有我们需要的jdk和hadoop压缩包)
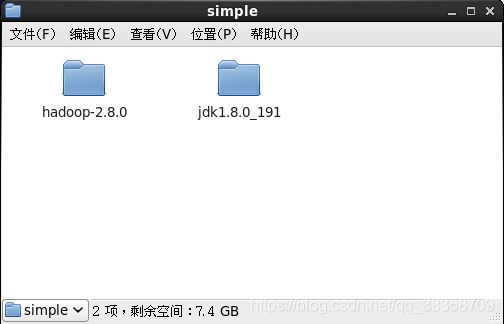
3、jdk的配置,执行命令 vim /ect/profile,如下是需要填入的,然后执行source /etc/profile,刷新配置,配置文件中的信息才会生效,如下图。
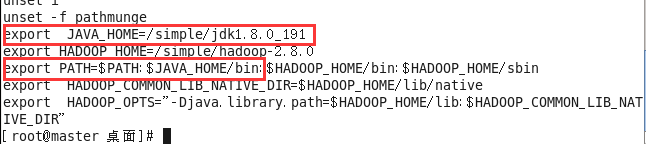
4.完成上述配置后,执行javac,如果提示“找不到命令”,则表示配置未成功,成功配置后如下图
也执行java,如果提示“找不到命令”,则表示配置未成功,成功配置后如下图
四、Hadoop安装和配置
1、hadoop的环境配置
执行命令 vi /etc/profile 配置hadoop到环境变量中,hadoop的安装目录和刚才jdk的一样,这里就不截图了。
export HADOOP_HOME=/simple/hadoop-2.8.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source /etc/profile ,使环境变量改动生效。
任意目录输入hado,然后按Tab,如果自动补全为hadoop,则说明环境变量配的没问题,否则检查环境变量哪出错了。

2、配置两个.sh文件(hadoop-env.sh 和yarn-env.sh)
(1)hadoop-env.sh Hadoop运行环境配置文件,配置java路径
export JAVA_HOME=/simple/jdk1.8.0_191
(2)yarn-env.sh yarn运行环境配置文件,配置java路径
export JAVA_HOME=/simple/jdk1.8.0_191
3、配置四个.xml文件,用 vi xxx.xml进行编辑(以下均在
(1)core-site.xml hadoop核心配置文件
(2)hdfs-site.xml HDFS相关配置文件
(3)mapred-site.xml mapreduce相关配置文件(目录下默认没有该文件,需要先执行命令mv mapred-site.xml.template mapred-site.xml )
(4) yarn-site.xml YARN框架配置文件
NodeManager上运行的附属服务。配置成mapreduce_shuffle,才可运行MapReduce程序
4、打开hadoop目录下的slaves(Centos7下为works),去掉localhost,加入从节点名,如下图。

五、集群环境搭建
1、关闭虚拟机master,克隆slave1、slave2,现在我已克隆好虚拟机。
2、克隆后对slave1从机进行相关修改
(1)克隆后需修改克隆机的物理地址,进入目录 /etc/udev/rules.d/70-persistent-net.rules/ 把最后一个改为eth0
(2)进入目录 /etc/sysconfig/network-scripts/ifcfg-eth0 修改从机IP,一般最后一位自增1,IP为192.168.107.161,如下图
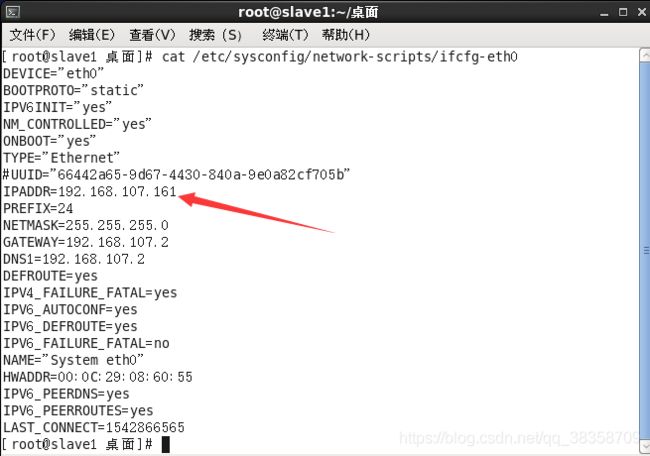
(3)进入目录 /etc/sysconfig/network 修改从机hostname为slave1

(4)从机slave2同理
3、节点间免密登录ssh (搭hadoop必须需要配免密登录,主节点上执行)
(1)生成密钥对:公私钥(id_rsa 是私钥,id_rsa.pub是公钥)
先执行cd ~/.ssh 再执行ssh-keygen -t rsa # 一直Enter即可(Enter四次)
ls查看 /root/.ssh/ 下生成情况
(2)公钥复制到从节点机器上
ssh-copy-id -i slave1 (可能会提示输入从节点密码)
(3)连接到slave1
执行ssh slave1
(4)需要相互连接则将以上slave1全部重新执行,连到master
exit(退出)
(5)slave2做和slave1一样的处理
4、集群启动
(1)在 master 任意目录输入 hdfs namenode -format 格式化namenode,修改配置文件还需格式化
(2)在master启动 Hadoop(在hadoop目录下执行)
分别执行start-dfs.sh和start-yarn.sh或者也可以直接执行start-all.sh
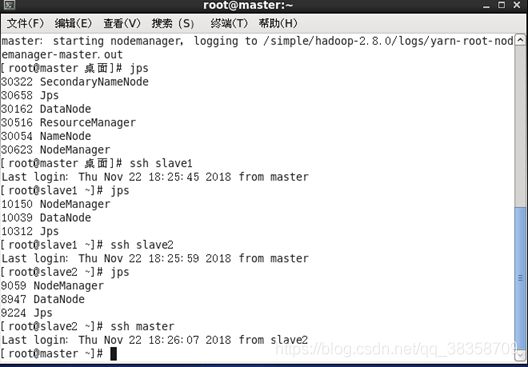
(3)查看jps
master执行jps,ssh slave1执行jps查看从节点jps,结果如下图(数目应该分别为6,3,3)
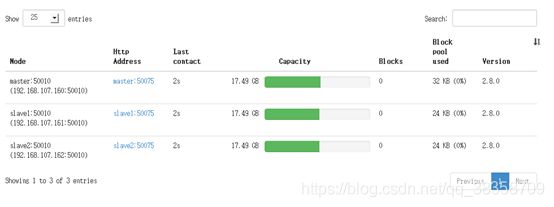
(4)在浏览器访问nameNode节点的8088端口(在地址栏输入192.168.107.160:8088)和50070端口(在地址栏输入192.168.107.106:50070)便可以查看hadoop的运行状况,如下图,说明节点运行成功。
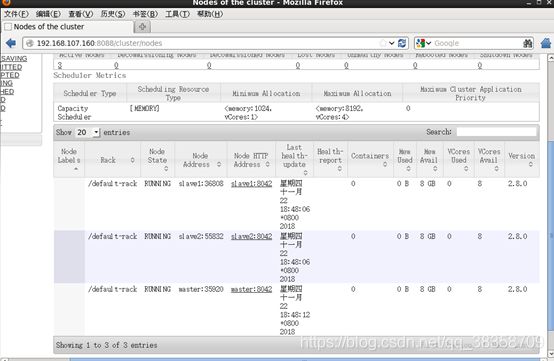
PS:以上均为个人做完后的心得总结,希望可以帮助到有需要的朋友,如有不足的地方,敬请见谅。