linux命令与shell编程
文章目录
- 一、概念
-
- linux内存
- 嵌入式
- 嵌入式层次图
- 判断小端和大端
- 二、linux系统操作命令
-
- ls查看
- cd 命令
- pwd命令
- touch 创建文件
- mkdir 创建目录
- chmod 修改权限
- man命令
- cp 拷贝
- mv 移动
- rm命令
- cat命令
- echo 命令
- tty命令->查看当前终端号
- clear 命令
- ldd命令 ->查看文件依赖哪些库
- printenv命令->打印环境变量
- eog命令 + 图片名-> 显示图片
- 权限掩码 umask命令
- 修改权限掩码
- 安装软件命令
- 离线安装命令dpkg
- 在线安装apt-get
- 在ubuntu中阅读代码的工具ctags
- 压缩和打包
-
- 1. 压缩:对象是文件
- 2.打包(归档):对象是目录
- 文件操作的命令
-
- 文件的查看
- cat命令
- head命令
- tail命令 ->tail -f +文件名 实时显示文件更新
- more命令
- less命令
- 查看二进制文件
- 文件中内容搜索的命令 grep
- 文件搜索命令 find
- 文件中内容截取cut(以行为单位处理)
- 通配符
-
- “*” 可以匹配任意长度的字符
- ? 只去匹配一个字符
- [字符1字符2...字符n]
- [起始字符-结束字符]
- [^ 字符1字符2...字符n]
- 文件权限的修改
-
- 修改用户的权限chmod
- 修改文件所属的用户chown
- 修改文件所属组的命令chgrp
- 链接
-
- 软链接 ln -s
- 硬链接 ln
- 用户管理命令
-
- 添加用户 adduser (添加组addgroup)
- 新添加用户没有sudo权限解决方法
- 关机或重启命令
- 用户切换命令 su 用户名 (输入当前用户的密码即可)
- 退出用户 exit
- 修改密码的命令 sudo passwd 用户名
- 用户信息修改命令usermod
-
-
- 问题:修改完用户信息后,新用户通过图形界面登录不进去?
-
- 查看用户信息的命令 id 用户名
- 删除用户deluser (删除组delgroup)
- 磁盘操作相关命令
-
- 查看ubuntu系统的磁盘 sudo fdisk -l
- 查看磁盘使用量信息的命令 sudo df -h
- 查看磁盘挂载相关的命令 sudo mount
- 对硬盘操作相关的命令
- 指定磁盘类型的命令
- 环境变量问题
-
- 添加只对当前终端生效的环境变量
- 添加只对当前用户生效的环境变量
- 添加对所有用户生效的环境变量
- 网络相关命令
-
- ip
- ip组成
- ip表示方式
- ip的种类
- .ipv4的网段划分
- 子网掩码
- 网关
- DNS 域名解析器
- 查看网络的命令 ifconfig
- 图像界面设置静态IP
- vim使用
-
- 修改自动补全的文件
- vim分为三种工作模式
-
- 1.命令行工作模式
-
- 复制 y
- 剪切 d
- gg直接跳到首行
- G直接跳到尾行
- 粘贴 p
- 撤销 u
- 反向撤销 ctrl + r
- 代码对齐
- 搜索及高亮显示
- 插入模式
- 底行模式
-
- 保存/退出文件
- 水平打开多个文件 vsp 文件名
- 垂直打开多个文件 sp 文件名
- 拷贝、剪切
-
- :n 跳转到第n行
- vi test.c +100 打开文件的时候直接跳转到100行
- :set nonu 取消行号
- :set nu 显示行号
- .:nohl 取消高亮显示
- 替换
- 三 、shell编程
-
- shell定义
- 什么是shell脚本
- 执行shell脚本
-
- ./脚本名 (chmod 0777 脚本名.sh)
- bash 脚本名
- source 脚本名
- 三者的区别
- shell中变量
-
- 变量引用
- 变量赋值
- shell中的注释
- 清除变量 unset
- 位置变量
- 变量的作用域local
- 只读变量 readonly
- 给变量赋值命令(命令->linux操作命令)
- 例:
- 字符串相关操作
-
- 1.字符串长度
- 2.字符串拷贝
- 3.字符串的追加
- 4.字符串中子字符串的提取
- shell中的数组
-
- 数组成员重新赋值
- 数组成员的访问
- 数组中所有成员
- 数组的成员的个数
- 数组成员的追加
- shell中的输入与输出
-
- read输入
-
- read 变量名
- read 变量名1 变量2
- read -a 数组名
- read -n number 变量名
- read -p "描述字段" 变量名
- read -s 变量名
- read -t 5 变量名
- echo输出
-
- echo $变量名
- echo -n $变量名
- echo -e $变量名
- 运算符
-
- 算数运算符
-
- (())整数运算
- $[]整数运算
- expr整数运算
-
- expr字符串的操作
- let整数运算
- if语句
-
-
- 在if语句中判断数字的大小
- 逻辑运算符
- 1.对字符串的判断(在if语句中字符串需要加上"")
-
- 练习:
- 2.对文件的类型的判断bsp-lcd
-
- 练习
- 3.文件权限的判断
-
- 练习
- 4.判断文件的时间戳
- 5.判断文件的inode号是否相同
-
- case ... in 语句
-
- 练习1
- 练习2
- while循环
-
- 练习1
- 练习2
- until循环
-
- 练习1
- for循环
-
- c语言风格的for循环(算术运算)
- shell特有风格的for循环(文件)
- 省略in部分的for循环
- 练习
- select in 语句
- break和continue
- shell中的函数
-
- 函数的调用
- 函数的参数通过位置变量获取
- shell中函数返回值的问题?
- 练习1
- 练习2
- 练习3
- 练习4
一、概念
linux内存

嵌入式
嵌入式以计算机应用为中心,软硬件可裁剪的,对功耗,功能体积,可靠性等有要求的专用的计算机系统。
嵌入式层次图
user:(用户空间)
命令 shell脚本 APP(glibc)
-----------------------------
命令行解析器
| [0-3G]
---------------系统调用-----------------------------
kernel:(内核层)
5大功能 | [3-4G]
1.进程管理 //有进程的创建、销毁与调用
2.内存管理 //内存申请、释放
3.文件管理
4.网络管理
5.设备管理 //设备驱动管理
hardware: (硬件层)
led camera sensor lcd sound
linux系统:分时多任务/多用户操作系统 linux系统一切皆文件
用户空间进入内核需要使用系统调用完成,系统 调用接口是内核已经给用户提供了。linux分为用户 空间和内核空间的原因是处于安全角度考虑。
判断小端和大端
在我们发送数据的时候,我们首先要确定是大端还是小端模式来进行的,在接收方接收的数据必须知道数据是大端还是小端模式,才能正确地读取和存储数据起来,否则就会出错
小端:ubuntu用的一般是小端
大端:数据通过网络字节区

代码区分:
#include 二、linux系统操作命令
ls查看
- ls -a // 显示隐藏文件
- ls -l // 列出文件属性
- ls -lh // 列举文件的时候将文件的属性信息一并显示,并把文件的大小按照单位显示
- ls -i // 显示文件的inode号,文件系统,唯一识别文件的一个序号
- ls -R // 递归显示所有文件,包括子目录文件
cd 命令
- cd ~ 或cd 回到家目录下
- cd - 回到上一次操作的目录下
- cd / 切换到根目录下
- cd . 切换到当前目录下
- cd …/ 切换到上一级目录下
pwd命令
显示当前的路径
touch 创建文件
touch 文件名
如果文件存在,更新文件的时间戳
如果文件不存在,创建文件
touch 文件1 文件2 文件3 …
同时创建多个文件
mkdir 创建目录
mkdir 目录名 //用来创建目录
mkdir -p 1/2/3 创建具备层级关系的目录
mkdir -m 0777 list 创建一个具备0777权限的目录
chmod 修改权限
chmod 权限 文件/目录
例:
chmod 0777 hello/
将hello目录的权限修改为0777
chmod 0441 2.c
将2.c的文件的权限修改为0441
man命令
man 1 ==>查看命令帮助手册
例 :
man 1 ls
man 2 ==>查看系统调用的帮助手册
例:
man 2 open ==>查看系统调用函数open
man 3 ==> 查看库函数的帮助手册
例:
man 3 fflush
man 7 ==> 查看网络相关的帮助手册
例:
man 7 ip
man 7 socket
cp 拷贝
cp 文件/目录 目录
将文件或者目录拷贝到某一个目录下
cp 绝对路径/文件名 目录名
cp 相对路径/文件名 目录名
将一个文件拷贝到目标目录下
拷贝目录需要加-r 或 -a
cp 绝对路径/目录名 目录名 -r 或 -a
cp 相对路径/目录名 目录名 -r 或 -a
将一个目录拷贝到目标目录下
cp ./COPYING ~/test.c
将COPYING文件拷贝到家目录下并重命名为test.c
cp ./net ~/1/2/3/aaa -r
拷贝目录的同时进行重命名
例:
1.在用户的家目录下,创建一个my-dir目录
cd
mkdir my-dir
2.将/etc下的passwd文件拷贝到my-dir目录下,并重命名为farsight.c
$ cp /etc/passwd ~/my-dir/farsight.c
3.将etc下的groff目录拷贝到my-dir下,并重命名为hello
cp /etc/groff/ ~/my-dir/hello -r
mv 移动
如果目标目录存在表示移动,如果不存在重命名
mv 文件/目录 目标目录下
mv 1.c ~
//将当前的1.c文件移动到/home/linux下
mv hello/ ~/1/2/3 (注意不需要加-r)
//将当前目录下的hello目录,移动到1/2/3目录下
重命名:
mv test.c farsight.c
将test.c重命名为farsight.c文件
mv net/ netnet/
将net目录重命名为netnet目录
例:
1.在用户的家目录下,创建一个my-dir1目录
cd
mkdir my-dir1
2.将/etc下的passwd文件拷贝到my-dir1目录下,并重命名为farsight.c (不使用cp重命名)
cp /etc/passwd ~/my-dir1/
mv passwd farsight.c
3.将etc下的groff目录拷贝到my-dir1下,并重命名为hello (不使用cp重命名)
cp /etc/groff/ ~/my-dir1/ -r
mv groff/ hello/
4.将my-dir1移动到共享目录下
mv ~/my-dir1 /mnt/hgfs/share
rm命令
rm 文件名 //删除文件
rm 目录名 -rf //删除目录 -r 递归删除
//-f 强制删除
rm *.c -f //强制删除所有的.c文件
例:
rm !(22.txt) //删除22.txt之外的所有的文件
cat命令
cat 命令用于查看文件内容,后跟文件名作为参数。
cat -n //显示每一行的行号
more命令一页一页显示文件内容,用法与cat一致
more在命令会在最后显示一个百分比,表示已显示内容占整个文件的比例。按空格键向下翻动一页,按Enter键向下滚动一行,按Q键退出
echo 命令
- echo “123123” 将字符串显示到终端上
- echo 123123 > 1.c //重定向,本来要在终端上显示的字符串,重定/向到1.c
- echo 123123 >> 1.c //>>追加,在文件的尾部新起一行,将字符串写入这一行
例:

在终端输入echo $? ==>可以查看int main函数的返回值
tty命令->查看当前终端号

clear 命令
清屏 或者 ctrl + l
ldd命令 ->查看文件依赖哪些库
ldd + 文件名

printenv命令->打印环境变量
eog命令 + 图片名-> 显示图片
权限掩码 umask命令
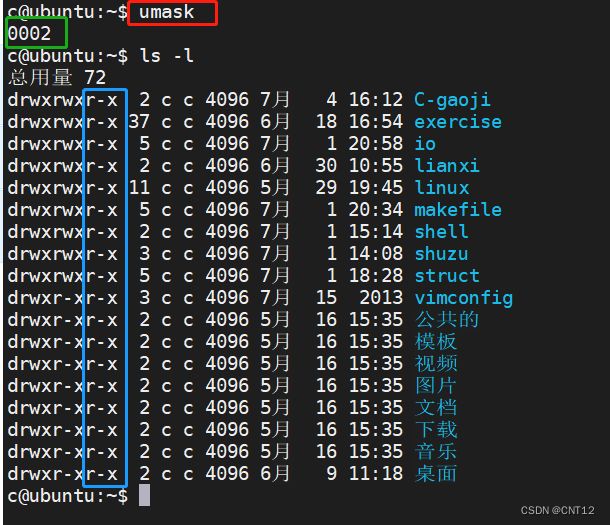
修改权限掩码
umask 0(把权限掩码去掉)

安装软件命令
linux软件包的管理
(1)rpm(redhat)
(2)deb(ubuntu)
在.deb这个软件包中包含可执行程序,
说明文档,man手册,配置文件等。
软件包的命名规则:
sl _ 3.03 - 16 _ i386 . deb
软件名 版本号 修订版本 架构 包的后缀
i386 :32位操作系统
amd64:64位操作系统
离线安装命令dpkg
在安装软件的时候,不会检查软件的依赖关系
安装软件:
sudo dpkg -i 软件包名
例:
sudo dpkg -i sl_3.03-16_i386.deb
查看安装软件的版本号
sudo dpkg -l 软件名
查看软件对应的各种信息安装的位置
sudo dpkg -L 软件名
软件的卸载(配置信息会保留)
sudo dpkg -r 软件名
完全卸载
sudo dpkg -P 软件名
在线安装apt-get
先检查软件的依赖,如果发现软件有依赖的其他软件,一并安装到自己的系统中
1.更新本地的源
sudo apt-get update
2.安装软件(/var/cache/apt/archives)
sudo apt-get install sl //安装小火车应用程序
sudo apt-get install oneko //安装一个小猫
sudo apt-get install bastet //俄罗斯方块
sudo apt-get install frozen-bubble //泡泡龙
sudo apt-get install kolourpaint4 //画图板
sudo apt-get install xawtv //打开摄像头的软件
sudo apt-get install -f sl //强制安装
3.卸载软件
sudo apt-get remove 软件名
4.获取软件的源码
sudo apt-get source 软件名
(获取软件对应源码)
例:
sudo apt-get source sl //下载sl的源码
tar -xvf sl_3.03.orig.tar.gz //解压
cd sl-3.03.orig //进入解压后的目录
vi sl.c //这个就是sl的源码
5.只下载不安装(下载到当前路径下)
sudo apt-get download 软件名
6.清除下载的软件包
sudo apt-get clean
仓库1 仓库2 … 仓库n
|------------------------|
|
服务器1 服务器2 … 服务器n
由于用户所在的位置不同,访问服务器的时候,速率也不同。
选择这个访问最快的服务器自己使用。
比如选择的服务器是163服务器。
选择163服务器的方法如下:
1.点击->search->Update Manager->settings->
输入密码1->ubuntu software->download from->
->http://mirrors.163.com/ubuntu
可以将上述的服务器1中的仓库的地址同步到ubuntu的本机上,
在本机上/etc/apt/source.list //源路径-如163服务器
每一个仓库中又有很多的软件包,在本机的这个目录
/var/lib/apt/lists/下记录的就是软件的链接位置。 //各个软件的地址
错误1:
如果提示错误在错误信息中看到/var/lib/apt/lists/内容
解决办法:
cd /var/lib/apt/lists/
sudo rm * -rf
错误2:
ubuntu没有联网?
联网的方法如下:
1.在vmware中找到“编辑”选项->虚拟网络编辑器->
更改设置->如果点进来没有看到vnet0 vnet1 vnet8
->点击还原默认配置(需要在关机情况下进行)
2.在上述还原默认配置之后,选择vnet0,桥接模式
在桥接模式先选择
1.自动
2.pcie :有线网卡
3.wireless:无线网卡选择完之后点击确认
3.虚拟机->设置->硬件->网络适配器->选择“桥接模式”
4.做完上述操作之后“开机”
5.在开机之后,在ubuntu窗口的右上角能看到上下箭头或者wifi图标的选项,点击->edit connections–>将看到的默认选项删除—>点击add添加一个联网的选项—>然后关闭即可。
6.测试是否能联通
ping www.baidu.com
PING www.a.shifen.com (182.61.200.7) 56(84) bytes of data.
64 bytes from 182.61.200.7: icmp_req=1 ttl=53 time=5.27 ms
在ubuntu中阅读代码的工具ctags
1.安装ctags工具
sudo apt-get install exuberant-ctags
2.创建索引
ctags -R ==>会生成一个tags的索引文件
执行make tags ==> 在内核中创建索引文件
3.查找
3.1在终端上查找
vi -t 想查找的对象
若vi -t 无法使用,可以在查看的内核源码处,执行make tags
3.2在文件内查找
ctrl+] 跳转到实现的位置
ctrl+t 返回
压缩和打包
1. 压缩:对象是文件
将文件可以压缩成如下格式的文件
.gz ---->gzip
.bz2 ---->bzip2
.xz ---->xz
上述三者的压缩率从上到下逐渐递增
上述三者的压缩速率从上到下逐渐递减
例:
gzip COPYING //将COPYING压缩成COPYING.gz
//压缩完之后源文件就不存在了
gunzip COPYING.gz //将.gz格式的压缩文件解压
bzip2 COPYING //将COPYING压缩成COPYING.bz2
//压缩完之后源文件就不存在了
bunzip2 COPYING.bz2 //将.bz2格式的压缩文件解压
xz COPYING //将COPYING压缩成COPYING.xz
//压缩完之后源文件就不存在了
unxz COPYING.xz //将.xz格式的压缩文件解压
2.打包(归档):对象是目录
tar 参数 对象
参数:
- -c :打包
- -x :解包
- -v :显示打包或者拆包的过程信息的
- -f :f可以理解为file,f后必须跟文件名
- -z :压缩成gzip格式
- -j :要压缩成bzip2格式
- -J :要压缩成xz格式
打包的命令如下:
tar -cvf 目录名.tar 目录名/
注意:c和v位置可以互换,但是f一定是在最后的位置的
拆包的命令如下:
tar -xvf 目录名.tar
就会生成以"目录名"命名的目录
例:有一个名为"work"的目录名
tar -czvf work.tar.gz work/ 打包并压缩
tar -xzvf work.tar.gz
tar -cjvf work.tar.bz2 work/
tar -xjvf work.tar.bz2
tar -cJvf work.tar.xz work/
tar -xJvf work.tar.xz
通用的解压命令
tar -xvf 名字.tar.bz2
目录在打包的时候,可以更换打包名字,但是解压出来名字还是原来的名字
文件操作的命令
文件的查看
vim 文件名(可以查看文件,也可以来编辑文件)
cat命令
cat -n 文件名
将文件的内容和行号显示到终端上
cat /etc/issue
用来查看ubuntu的版本号
head命令
head 文件名
默认显示文件中的前10行
head -20 文件名
显示文件的前20行的内容
head -3 文件名
显示文件的前3行的内容
tail命令 ->tail -f +文件名 实时显示文件更新
tail 文件名
显示文件的后10行
tail -20 文件名
显示文件的后20行
显示文件的13-16行
head -16 文件名 | tail -3
|(管道符):这个符号的功能是将前面的结果,作为下一个命令的输入。
例:
请将用户信息显示到终端上
用户信息存放在 /etc/passwd里面在第40行的位置
c: x:1000:1000:c,:/home/c:/bin/bash
c: \表示用户名
x: \表示有密码 -> 密码存放在 /etc/shadow 里面
1000:\ 表示用户的序列号
1000: \ 表示组的序列号
c \ 表示用户信息的描述字段
/home/c: \ 用户的主目录
/bin/bash \命令行解析器
使用:head -40 /etc/passwd | tail -1
more命令
more 文件名 //按照文件的本分比显示
按下回车往下显示
less命令
less 文件名
上键 向上显示
下键 向下显示
退出的时候使用q键
查看二进制文件
od -c 二进制文件名(例:a.out)
文件中内容搜索的命令 grep
grep “main”(要搜索的内容) * 参数
参数:
-n: 显示搜索到的行号
-R: 递归搜索
-i: 忽略大小写
-w: 精确搜索,只能知道main 对应的内容,main有前缀或后缀都检测不到
搜索以main开头的行:“^main”
搜索以main结尾的行:“main ” " m a i n ” "^main ”"main":只有有main这一个单词
grep “main” * -nR //经常用的一种写法
例:

文件搜索命令 find
find 路径 -name 文件的名字
例:
find ./ -name test.c
搜索当前目录及子目录的所有的以test.c命名的文件
find …/…/ -name test.c
搜索上上级目录及子目录下的所有的以test.c命名的文件
find -name 文件名 (常用的写法)
搜索当前目录及子目录的所有的以test.c命名的文件
注意:
如果find命令在当期目录下所有搜索文件的时候,
不能模糊搜索(不能使用通配符号),必须精确搜索。
否则出现如下错误:find -name *.c
find: paths must precede expression: test.c
find -name * .c -exec grep -l “main” {} ;
// find -name *.c 搜索当前目录及子目录中的
所有的.c结尾的文件
//-exec grep:执行完find之后去执行grep命令
//-l :显示文件列表
//“main” :被搜索的字符串
//{} :它代表的是就是find -name *.c搜索
到的结果文件。
// ; :-exec执行的时候遇到;才会停止,
:但是由于;是一个特殊字符,必须使用
:转译才可以。
文件中内容截取cut(以行为单位处理)
cut(处理的时候是以行为单位)
-d :分割符号
-f :域
例:
test.txt
北京市:海淀区:育新花园:17号楼:304室
cut -d : -f 1 test.txt==>北京市
cut -d : -f 2,4 test.txt==>海淀区:17号楼
cut -d : -f 1,3-5 test.txt==>北京市:育新花园:17号楼:304室
北京市"海淀区"育新花园"17号楼"304室
cut -d " -f 2 test.txt ==>海淀区
例:
1.请将用户信息中的/etc/passwd
在终端上显示 用户名:uid:pid
结果:linux:1000:1000
命令:head -40 /etc/passwd | tail -1 | cut -d : -f 1,3-4
2.请将用户信息文件中,当前用户的行号显示出来
结果:40
命令:cat /etc/passwd | cut -d : -f 1 | grep “c” -nw | cut -d: -f 1
通配符
“*” 可以匹配任意长度的字符
例:
1.c 2.c 3.c 123123123.c sdfsfsdfsd.txt
ls * .c
显示当前目录下的所有的.c结尾的文件
? 只去匹配一个字符
例:
aa1.c aa2.c aaa.c aa12.c
ls aa?.c
结果是:aa1.c aa2.c aaa.c
[字符1字符2…字符n]
通配[]内部的任意的一个字符
例:
aa1.c aa2.c aaa.c aab.c
ls aa[1ab].c
结果:aa1.c aaa.c aab.c
[起始字符-结束字符]
通配起始字符到结束字符中的任意一个字符
例1:
aa1.c aa2.c aaa.c aab.c
执行:ls aa[1-9].c
结果:aa1.c aa2.c
执行:ls aa[a-z].c
结果:aaa.c aab.c
例2:
aaa.c aab.c aaA.c aaB.c
执行:ls aa[A-C].c
结果:aaA.c aab.c aaB.c
想得到的结果:aaA.c aaB.c
出现上述的原因是系统的语系问题,本地
的语系中字母的排序是
aAbBcC…zZ
解决办法:export LC_ALL=C
LC_ALL是系统中保存本地语系的一个变量
=C作用清除本地语系。
上述命令只在当前终端生效,换一个终端,
或者重启ubuntu就不生效了。
清除后的语系的排序:
abcd…z ABCD…Z
执行上述操作之后就可以得到正确的结果了
ls aa[A-C].c
结果:aaA.c aaB.c
[^ 字符1字符2…字符n]
通配除字符1 字符2 … 字符n之外的所有字符
例:
aa1.c aa2.c aaA.c aaB.c aaY.c aaa.c aab.c aay.c
执行:ls aa[^1y].c
结果:aa2.c aaA.c aaB.c aaY.c aaa.c aab.c
| 通配符 | 含义 |
|---|---|
| [:alnum:] | 代表英文大小写字母及数字 |
| [:alpha:] | 代表英文大小写字母 |
| [:blank:] | 代表空格和tab键 |
| [:cntrl:] | 键盘上的控制按键,如CR,LF,TAB,DEL |
| [:digit:] | 代表数字 |
| [:graph:] | 代表空格符以外的其他 |
| [:lower:] | 小写字母 |
| [:print:] | 可以被打印出来的任何字符 |
| [:upper:] | 代表大写字母 |
| [:space:] | 任何会产生空白的字符如空格,tab,CR等 |
| [:xdigit:] | 代表16进位的数字类型 |
文件权限的修改
d r-x r-x r-x 2 c c 4096 6月 18 17:09 dem01
r-x r-x r-x:权限
2:硬链接数
c : 用户
c : 组
修改用户的权限chmod
r-x r-x r-x
第一个表示:用户的权限 用 u 表示
第二个表示:组的权限 用g表示
第三个表示:其他用户的权限 用o表示
用+ :给权限
用- :去除权限
chmod u+w dem01 //给用户添加写的权限
chmod g-r dem01 //清除组读的权限
chmod uo+x aaA.c //将用户和其他人的可执行的权限添加上
chmod ugo+w aaA.c //将所有的写的权限添加上去
chmod a+w aaA.c //将所有的写的权限添加上去
a相当于ugo
修改文件所属的用户chown
chown 新用户名 文件
例:
将day2.txt文件所属的用户修改为root
sudo chown root day2.txt
将day2.txt文件所属的用户和组修改为root
sudo chown root:root day2.txt
将day2.txt文件所属的组修改为linux
sudo chown :linux day2.txt
修改文件所属组的命令chgrp
chgrp 新的组名 文件
例:
将day2.txt文件所属的组修改为root
sudo chgrp root day2.txt
链接
软链接 ln -s
软链接类似于windows的快捷方式
ln -s 被链接的文件 创建的链接文件
例:ln -s ~/exercise/dem01/num.c /home/c/1
软链接 可以链接文件或目录,两个都需要是绝对路径
建立软链接后,把软链接删除对原文件没影响
ln -f 强制创建链接文件,如果目标存在,那么先删除掉目标文件,然后再建立链接文件。
软链接特点:
①可以连接到目录
②可以跨文件系统
③删除源文件后,软链接文件也就打不开了
④符号连接文件通过->来指示具体的链接文件
⑤软链接需要创建给出绝对路径
拷贝 应使用 cp -d 命令,保持原文件类型不变
硬链接 ln
相当于是文件的别名
ln 被链接的文件 创建的链接文件
例:ln days my_days
建立硬链接后,两个文件是独立的文件,但是更改其中一个里面的内容后,另一个里面的内容也会更改
①具有相同inode的多个文件互为硬链接文件,创建硬链接相当于文件实体多了入口
②对于硬链接文件,只有删除了源文件以及对应的所有硬链接文件,文件实体才会被删除
③根据硬链接文件的特点,我们可以通过给文件创建硬链接的方式来防止文件误删除
④不论修改源文件还是链接文件,另一个文件的数据都会被改变
⑤硬链接不能跨文件系统 因为硬链接是根据inode号识别的
⑥硬链接不能连接目录
由于以上这些限制,硬链接不常用
用户管理命令
vi /etc/hostname ==> 修改主机名
vi /etc/hosts ==> 修改主机名
在172. … 里面把名字修改为主机名
在终端输入 hostname 可以查看
/etc/passwd =>用户信息的文件
/etc/group =>组信息的文件
/etc/shadow =>密码的文件
/etc/skel =>系统配置文件的模板目录
添加用户 adduser (添加组addgroup)
例:添加farsight 用户
sudo adduser farsight //添加fasight用户
添加时候显示如下信息:
Adding user farsight' ... Adding new group farsight’ (1001) … =>组名及id号
Adding new user farsight' (1001) with group farsight’ …=>用户名及id号
Creating home directory /home/farsight' ... Copying files from /etc/skel’ … =>/etc/skel模板目录,里面是系统配置文件
Enter new UNIX password: =>密码2
Retype new UNIX password:
passwd: password updated successfully
Changing the user information for farsight
Enter the new value, or press ENTER for the default
Full Name []: =>名字
Room Number []: =>地址
Work Phone []: =>电话
Home Phone []:
Other []:
Is the information correct? [Y/n] Y

新添加用户没有sudo权限解决方法
执行sudo 出现如下错误:
farsight:is not in the sudoers file.This incident will be reported
解决办法:
首先切换到root 用户
su root
cd /etc/
chmod u+w sudoers //给sudoers这个文件的用户的写的权限添加上去
vi sudoers
找到 root ALL=(ALL:ALL) ALL
添加 farsight ALL=(ALL:ALL) ALL //表示给farsight用户sudo的权限
然后执行 chmod u-w sudoers //把添加的权限去掉
重启系统就生效了(16.04不用重启)
关机或重启命令
sudo shutdown -h +50 //50分钟后关机
sudo shutdown -h 10:30 //10:30关机
sudo shutdown -h now //立即关机
sudo poweroff //立即关机
sudo shutdown -r +50 //50分钟后重启
sudo shutdown -r 10:30 //10:30重启
sudo shutdown -r now //立即重启
sudo reboot //立即重启
用户切换命令 su 用户名 (输入当前用户的密码即可)
退出用户 exit
修改密码的命令 sudo passwd 用户名
用户信息修改命令usermod
切换用户,当前用户没有登录 //使用该命令,用户应处于没有登录状态
sudo usermod -aG linux farsight // 将farsight用户追加到linux组中
sudo usermod -c “hellohellohello” farsight //用来修改farsight用户/etc/passwd中描述字段信息,
//这里的,描述字段就是登陆时候显示的名字
sudo usermod -d /home/hello farsight // 用来修改用户的主目录,将farsight的主目录修改为/home/hello
sudo usermod -l hello farsight // 将farsight的用户名修改为hello
sudo usermod -g linux hello //将hello用户所属的组修改为linux(组名)
问题:修改完用户信息后,新用户通过图形界面登录不进去?
可以通过终端登录进入?
错误的原因是执行了如下命令:
sudo usermod -d /home/hello farsight
解决办法:
(fn)ctrl + alt +F1 ===>进入虚拟终端
1.将farsight目录下的内容拷贝到hello目录下
(注意这里需要将文件和hello目录的用户和组从root
用户修改当前用户和组即可)
2.sudo usermod -d /home/farsight hello
(fn)ctrl + alt +F7 ===>退出虚拟终端
查看用户信息的命令 id 用户名
删除用户deluser (删除组delgroup)
删除用户需要把用户关闭,在另一个用户进行
sudo deluser hello(要删除的用户) //删除用户,并将用户的主目录删除掉
磁盘操作相关命令
查看ubuntu系统的磁盘 sudo fdisk -l
查看磁盘使用量信息的命令 sudo df -h
/media/c/FAT32是U盘的目录

查看磁盘挂载相关的命令 sudo mount
一般为设备名(/dev/sdb1)目录名
对硬盘操作相关的命令
sudo fdisk /dev/sdb
Command (m for help): m
Command action
d 删除分区
l 列举分区
m 打印帮助菜单
n 添加新的分区
p 打印磁盘菜单
q 不保存退出
w 保存退出
指定磁盘类型的命令

sudo mkfs.ext4 /dev/sdb2 ===>ext4 日志文件系统 ubuntu
sudo mkfs.ntfs /dev/sdb2 ===>ntfs 单个文件可以超过4G
环境变量问题
保存系统启动相关,或者系统配置相关的变量。
在系统中可以通过env命令打印系统当前的环境变量
HOME=/home/linux #linux用户家目录
PATH=/usr/lib/lightdm/lightdm:/usr/local/sbin:
/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
添加只对当前终端生效的环境变量
export PATH=${PATH}:/home/c //使用绝对路径 并且只对当前层有效,进入下一层或上一层失效

添加只对当前用户生效的环境变量
.bashrc (在用户家目录下)
vi .bashrc
在最后添加
export PATH=${PATH}:/home/c
重启ubuntu生效
添加对所有用户生效的环境变量
sudo vi /etc/environment
在最后添加:
PATH=“/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/home/c/”
网络相关命令
ip
主机在网络中的一个编号,这个编号就是ip地址
ip组成
网络号+主机号 组成
ip表示方式
点分十进制
ip的种类
ipv4 (4字节,32bit) ipv6(16字节,128bit)
.ipv4的网段划分
| 等级 | 网络号 | 主机号 | 最高位 | 范围 | 使用单位 |
|---|---|---|---|---|---|
| A | 1字节 | 3字节 | 0 | [0-127] | 政府、大公司、学校 |
| B | 2字节 | 2字节 | 10 | [128-191] | 中等规模公司 |
| C | 3字节 | 1字节 | 110 | [192-233] | 个人 |
| D | 1110 | [224-239] | 组播 | ||
| E | 11110 | [240-255] | 未使用或(实验室) |
A : 0.0.0.0 - 127.255.255.255 //A网段地址范围
B: 128.0.0.0-191.255.255.255 //B网段地址范围
C:192.0.0.0-223.255.255.255 //C网段地址范围
D:224.0.0.0-239.255.255.255 //D网段地址范围
E:240.0.0.0-255.255.255.255 //E网段地址范围
子网掩码
例: 子网掩码:获取网络编号 192.168.1.160 & 255.255.255.0
得 : 192.168.1.0
网关
和外网通讯的ip地址,叫网关,一般咱们认为交换机的ip地址
DNS 域名解析器
www.baidu.com -->182.61.200.7
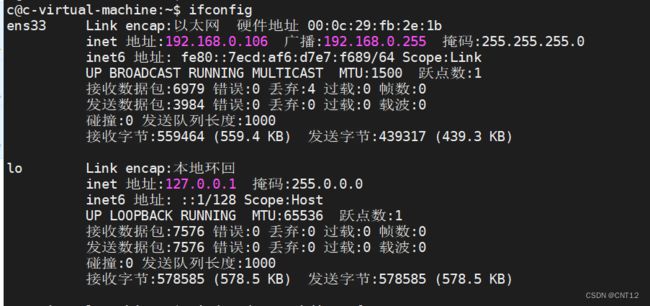
查看网络的命令 ifconfig
图像界面设置静态IP
address : 192.168.1.250
netmask : 255.255.255.0
gateway : 192.168.1.1
DNS : 8.8.8.8
重启网络管理服务
sudo service network-manager restart
测试:
ping www.baidu.com
PING www.a.shifen.com (182.61.200.7) 56(84) bytes of data.
64 bytes from 182.61.200.7: icmp_req=1 ttl=53 time=4.56 ms
使用命令配置网络
sudo vi /etc/network/interfaces
auto ens33
iface ens33 inet static
address 192.168.0.106 //ip 根据实际情况设定
netmask 255.255.255.0
gateway 192.168.0.1 //根据实际情况设定
broadcast 192.168.0.255 //根据实际情况设定
dns-nameservers 8.8.8.8
重启:
sudo /etc/init.d/networking restart 或 sudo systemctl restart NetworkManager.service
注意,上述重启之后需要修改配置文件,联网图标才能正常显示
在 /etc/NetworkManager/NetworkManager.conf. 中修改
ifupdown:managed=false ==>true //把false 修改为true

vim使用
先安装vim编辑器:
sudo apt-get install vim-gtk
修改自动补全的文件
linux@ubuntu:~/.vim/snippets$ vi c.snippets 路径
70 snippet main
71 #include
72
73 int main(int argc, const char *argv[])
74 {
75 ±-- 2 lines: ${1}---------------------------------------------------------------------
77 }
~
vim分为三种工作模式
1.命令行工作模式
打开一个新的文件默认在命令行模式,或者按下键盘上的Esc键,也能回到命令行模式
复制 y
yy 复制光标所在的一行
3yy 复制光标所在的向下三行
nyy 复制光标所在的向下n行
使用鼠标选中想要拷贝的行,按下键盘的y
按下键盘的shift键,鼠标选中想要拷贝的行,
松开shift键,右键拷贝即可,然后在windows中粘贴。
如果是16.04之后的版本中,shift不松开即可。
剪切 d
dd 剪切光标所在的一行
3dd 剪切光标所在的向下三行
ndd 剪切光标所在的向下n行
使用鼠标选中想要剪切的行,按下键盘的d
dG 剪切光标所在到尾行的所有内容
dgg 剪切光标所在到首行的所有内容
gg直接跳到首行
G直接跳到尾行
粘贴 p
p 将缓冲区的内容粘贴,在光标的下一行粘贴
撤销 u
反向撤销 ctrl + r
代码对齐
gg=G
或者
鼠标选中想要 对齐的行,然后按下键盘的“=”
搜索及高亮显示
/^abc :高亮显示abc开头的行
/abc$ :高亮显示abc结尾的行
/^abc$ :高亮显示abc开头并结尾的行
插入模式
从命令行模式进入到插入模式
i :在光标前进入插入模式
I :在光标的行首进入插入模式
a :在光标后进入插入模式
A :在光标的行尾进入插入模式
o :在光标的行的下面新起一行进入插入模式
O :在光标的行的上面新起一行进入插入模式
底行模式
从命令行模式进入到底行模式shift + :
保存/退出文件
:w 保存
:q 退出
:q! 不保存退出
:wq 或x 保存退出
:wq! 强制保存退出
:wa 保存所有的文件
:qa! 不保存退出所有文件
:wqa 保存退出所有文件
水平打开多个文件 vsp 文件名
垂直打开多个文件 sp 文件名
拷贝、剪切
:7,8y 拷贝7-8行,通过命令行的p进行粘贴
:4,$y 拷贝4-尾行的内容
:1,7y 拷贝文件开头到第七行的内容
:7,8d 剪切7-8行,通过命令行的p进行粘贴
:4,$d 剪切4-尾行的内容
:1,7d 剪切文件开头到第七行的内容
:n 跳转到第n行
vi test.c +100 打开文件的时候直接跳转到100行
:set nonu 取消行号
:set nu 显示行号
.:nohl 取消高亮显示
替换
**:%s/旧字符串/新字符串/g**
例:
**:%s/abc/www/g**
//表示将文档中的所有的abc替换为www
**:%s/abc/www/**
//表示将文档中每行首次出现的abc替换为www
**:3,7s/abc/www/g**
//表示将3-7行所有的abc替换为www
**:3,7s/abc/www/**
//表示将3-7行首次出现的abc替换为www
**:4,$s/abc/www/g**
//表示将4到尾行所有的abc替换为www
**:4,$s/abc/www/**
//表示将4到尾行首次出现的abc替换为www
三 、shell编程
shell定义
(1)sh :(全称 Bourne Shell)是UNIX最初使用的 shell,
而且在每种 UNIX 上都可以使用。Bourne Shell 在 shell
编程方面相当优秀,但在处理与用户的交互方面做得不如
其他几种 shell。
(2)csh :是一种比 Bourne Shell更适合的变种 Shell,它的语法与 C 语言很相似
(3)ksh :集合了 C Shell 和 Bourne Shell 的优点并且和 Bourne Shell 完全兼容。
(4)bash :LinuxOS 默认的,它是 Bourne Shell 的扩展。
与 Bourne Shell 完全兼容,并且在 Bourne Shell 的基
础上增加了很多特性。可以提供命令补全,命令编辑和命
令历史等功能。它还包含了很多 C Shell 和 Korn Shell
中的优点,有灵活和强大的编辑接口,同时又很友好的用户界面
什么是shell脚本
它本身是一个以sh结尾的文件。在这个文件中就是命令的集合以及一些复杂的逻辑语句。
#!/bin/bash
作用:指定解析这个脚本文件的解析器是bash
执行shell脚本
./脚本名 (chmod 0777 脚本名.sh)
bash 脚本名
source 脚本名
三者的区别
-
./执行脚本的时候需要权限
bash/source执行脚本的时候不需要权限 -
./和bash在执行脚本的时候,系统会自动新开一个子终端,子终端我们看不到,在子终端执行完之后,将执行的结果返回给当前终端
source 解析脚本的时候是在当前终端解析的
shell中变量
在shell中变量不需要定义,也没有数据类型,直接使用即可
shell中的变量的变量名和c语言类似
1.不能和shell中的关键字重复 test if while echo cat
2.变量名一般写成大写的
3.变量名命名格式数字,字母,下划线,不能以数字作为开头
变量引用
$ 变量名 或者 ${变量名}
$() 错误的用法
变量赋值
变量再被赋值的时候,都是字符串,就没有整形,字符型,字符串类型,浮点类型之分
例:
VAR1= helloworld (一句话结束不需要向c一样加;)
VAR2='hello world V A R 1 ′ V A R 3 = " h e l l o w o r l d VAR1' VAR3="hello world VAR1′VAR3="helloworldVAR1"
注意:
1.在赋值的时候=前后不允许有空格
2.如果在赋值的时候没有’'或"",赋值的字符串是不允许有空格的
3.’ '(单引号)在赋值的时候,可以有空格,但是不能够引用变量
4.“”(双引号)在赋值的时候,可以有空格,也能够引用变量,可以识别转译字符
shell中的注释
“#”单行注释
:<
EOF
:< 被注释掉的多行
!
例:
#!/bin/bash
:<<EOF
这是注释部分
EOF
:<<!
这也是注释部分
!
# 这是单行注释部分
TMP=www.hqyj.com
VAR1=helloworld
VAR2='hello world\n$TMP'
VAR3="hello world\n$TMP"
echo -n ${VAR1}
echo $VAR2
echo -e $VAR3
echo ${VAR1}
清除变量 unset
unset 变量名 #(注意不能再变量前加$)
位置变量
| 参数 | 意义 |
|---|---|
| $0 | 显示脚本文件名 |
| $1,$2,…$9 | 分别包含第一个到第九个命令行参数,后面还可以加$10,$11,但是写的时候,要用大括号{}扩起来 |
| $# | 包含命令行参数的个数,这个值不包含文件名这个成员 |
| $@ | 包含所有命令行参数:“$1,$2,…$9”,不包含文件名 |
| $? | 1.程序上一步执行的结果,如果是0,表示执行成功了 如果是1,表示执行失败了。2.可以用来获取shell中函数的返回值 |
| $* | 包含所有命令行参数:“$1,$2,…$9” ,不包含文件名 |
| $$ | 包含正在执行进程的ID号 |
| 例: | |
| 如果在执行脚本的时候使用的是**./** |
**$0 => ./05var.sh**
如果在执行脚本的时候使用的是bash
$0 => 05var.sh
如果在执行脚本的时候使用的是source
$0 => bash
变量的作用域local
local 变量名
如果变量前不加local,默认的就是全局变量,如果添加了local只在{}内部有效
只读变量 readonly
readonly 变量名=“初值”
只读变量一定要赋初值,否则无意义。
给变量赋值命令(命令->linux操作命令)
VAR1=` ls ` (注意这不是单引号,是~对应的符号)
VAR2=$(ls)
注意上面: 或者$()这叫做命令置换
例:
#!/bin/bash
readonly HELLO="fsdddsds" #只读变量
echo $HELLO
HELLO="123" #HELLO是只读变量,在赋值会出错
echo $HELLO
Z=hello
echo $Z #Z的值为hello
unset Z #清除变量Z的值
echo $Z
VAR1=`ls` #使用ls命令
VAR2=$(ls) #使用ls命令
echo $VAR1
echo $VAR2
echo $0 #输出脚本名
echo $1 #输出终端输入的第一个值
echo $2 #输出终端输入的第二个值
echo $3 #输出终端输入的第三个值
echo "----------------------------------------"
echo $* #输出命令行参数,不包括脚本名
echo "----------------------------------------"
echo $@ #输出命令行参数,不包括脚本名
echo "----------------------------------------"
echo $# #输出命令行参数个数,不包括脚本名
字符串相关操作
1.字符串长度
echo $ {# STRING}
2.字符串拷贝
VAR1=“hello”
VAR2=“world”
VAR1=${VAR2}
3.字符串的追加
VAR1=“hello”
VAR2=“world”
VAR3=“$VAR1 $VAR2”
VAR3=“hello $VAR2”
VAR3=‘hello’’ world’
VAR3=‘hello’" world"
4.字符串中子字符串的提取
STRING=“w w w . h q y j . c o m”
echo ${STRING:4} 输出 #hqyj.com
#从第四个字符开始提取,提取到字符串的结尾
echo ${STRING:4:4} 输出 #hqyj
#从第四个字符开始提取,提取4个字符
STRING=“w w w . h q y j . c o m”
echo ${STRING:0-6} 输出 #yj.com
#从倒数第六个字符开始向后截取,截取到字符串的尾部
echo ${STRING:0-6:2} 输出 #yj
#从倒数第六个字符开始向后截取,截取向后的两个字符
STRING=“www.hqyj.com.hqyj.com”
echo ${STRING# yj}* 输出 #.com.hqyj.com
#获取yj首次出现的字符后的内容(从左向右)
echo ${STRING## yj}* 输出 #.com
#获取yj最后一次出现的字符后的内容(从左向右)
echo ${STRING%yj }* 输出 #www.hqyj.com.hq
#获取yj首次出现的字符前的内容(从右向左)
echo ${STRING%%yj }* 输出 #www.hq
#获取yj最后一次出现的字符前的内容(从右向左)
例:
#!/bin/bash
STRING="www.hqyj.com"
echo ${#STRING}
#获取字符串的长度
VAR1="hello"
VAR2="world"
VAR3="$VAR1 $VAR2"
VAR4='hello'' world'
echo $VAR3
echo $VAR4
#字符串的追加
#下面的都是字符串的提取方法
STRING="www.hqyj.com"
echo ${STRING:4} #hqyj.com
echo ${STRING:4:4} #hqyj
echo ${STRING:0-6} #yj.com
echo ${STRING:0-6:2} #yj
STRING="www.hqyj.com.hqyj.com"
echo ${STRING#*yj} #.com.hqyj.com
echo ${STRING##*yj} #.com
echo ${STRING%yj*} #www.hqyj.com.hq
echo ${STRING%%yj*} #www.hq
shell中的数组
shell中的数组只有一维数组,shell中的数组通过括号()代表。
shell中的数组也是不需要定义的,数组没有类型,全部认为是
字符串。
例:
arr=(11 22 33 “hello” “tt”)
arr=([0]=11 [2]=123123 [5]=“helloworld”)
数组成员重新赋值
数组名[下标]=新的值
数组成员的访问
${数组名[数组的下标]}
数组中所有成员
${数组名[@]} 或者 ${数组名[*]}
数组的成员的个数
${#数组名[@]} 或者 ${#数组名[*]}
数组成员的追加
arr=(${arr[@]} “rrr” “ttt”)
arr=(“rrr” “ttt” ${arr[@]})
例:
#!/bin/bash
arr=(
11
22
33
"hello"
"world"
)
#echo ${arr[0]}
#echo ${arr[1]}
#echo ${arr[2]}
#echo ${arr[3]}
#echo ${arr[4]}
echo ${arr[@]} #数组中成员的遍历
echo ${#arr[@]} #数组中成员的个数
#arr=(${arr[@]} "rrr" "ttt") #数组的追加
arr=("rrr" "ttt" ${arr[@]}) #数组的追加
echo ${arr[@]}
unset arr #清除整个数组中的成员
unset arr[0] #清除第0个成员
arr=(
[0]=123
[2]="hello"
[5]="ttt"
)
arr[1]="456" #对数组中的成员赋值
#echo "arr[0] = "${arr[0]}
#echo "arr[1] = "${arr[1]}
#echo "arr[2] = "${arr[2]}
echo ${arr[*]} #数组成员的遍历
echo ${#arr[*]} #数组中(被赋值)成员的个数
echo ${#arr[1]} #a[1]成员中字符的个数
shell中的输入与输出
read输入
read 变量名
#从终端读取一个字符串赋值给变量
read 变量名1 变量2
#从终端读取两个字符串赋值给两个变量,
#字符串和字符串间使用空格或Tab作为间隔
read -a 数组名
#输入一个数组,数组的成员以空格分开
read -n number 变量名
#从终端读取n个字符给变量,如果输入的字符的格式=number,会自动结束输入
read -p “描述字段” 变量名
#在让你输入字符串给变量前先将描述字段给显示一下
read -s 变量名
#在输入的时候取消回显
read -t 5 变量名
#在5s内如果没有输入,read就结束输入。
例:
echo -n "请输入一个变量"
read VAR1 VAR2
echo $VAR1
echo $VAR2
echo -n "请输入一个数组"
read -a ARR
echo ${ARR[@]}
echo ${#ARR[@]}
echo -n "请输入一个字符串"
read -n 5 VAR #字符串输入到5个后结束
echo
echo $VAR
read -n 5 -p "请输入一个整数> " VAR2
echo $VAR2
read -s -t 3 -p "密码 > " VAR2
echo $VAR2
read -t 10 -p "请输入一个有5个成员的数组" -a arr #10s内没有输入,自动结束输入
echo ${arr[@]}
echo输出
echo $变量名
#打印变量的内容并会加上换行
echo -n $变量名
#打印变量的内容,不会加上换行
echo -e $变量名
#打印变量的内容并会解析转译字符 \n
运算符
算数运算符
* / % **(幂) = == != + -
++ – && || ! > <
由于shell中没有指定数据的类型,所有的变量都当成字符串来处理。
所以要完成两个变量的运算,需要使用shell中算数运算符、算数指令
shell中对两个变量直接进行运算,会被当成字符串来处理
(())整数运算
$[] 整数运算
let 整数运算
expr整数运算,字符串相关操作
上述运算方式,指向效率(())—>expr依次递减的expr可以做字符串相关的操作,其他的是不行的。
(())整数运算
((表达式))
((表达式1,表达式2,…表达式n))
如果(())有多个表达式,最后一个表达式的结果
就是这个(())运算的结果
1.(())内部使用变量的时候,变量前可以加 也可以不加 也可以不加 也可以不加符号
2.如果想获取(())执行的结果,必须在前面加上$(())
3.(())可以做复杂的运算,比如for循环 ,判断大小
例:
#!/bin/bash
read -p "请输入两个整数 >" VAR1 VAR2 #比如输入55,12
echo $(($VAR1 + $VAR2)) #输出67
echo $((VAR1 + VAR2)) #输出67
echo $(($VAR1 + $VAR2,$VAR1 - $VAR2)) #输出最后一个表达式的结果为43
#!/bin/bash
read -p "请输入两个整数 >" VAR1 VAR2 #比如输入55,12
VAR3=$((VAR1++))
echo $VAR1 #56
echo $VAR3 #55
VAR4=$((++VAR1))
echo $VAR1 #57
echo $VAR4 #57
#!/bin/bash
read -p "请输入两个整数 >" VAR1 VAR2 #比如输入 2 3
VAR3=$((VAR1 * VAR2))
echo $VAR3 #6
VAR4=$((VAR1 ** VAR2))
echo $VAR4 #8
for((i=1;i<=100;i++)){
((sum+=i))
}
echo $sum #5050
RET=$((3,4,5,6))
echo $RET #6 输出最后一个数
a=6
b=5
VAL=$((a<b))
echo $VAL #a
$[]整数运算
ret= [ 表达式 ] r e t = [表达式] ret= [表达式]ret=[表达式1,表达式2,…表达式n]
如果 [ ] 有多个表达式,最后一个表达式的结果就是这个 []有多个表达式,最后一个表达式的结果 就是这个 []有多个表达式,最后一个表达式的结果就是这个[]运算的结果
1.$[]在执行运算的时候,必须有变量去承接它的结果
$[a+b] #运行错误
必须按如下写法:
echo [ a + b ] r e t = [a+b] ret= [a+b]ret=[a+b]
2.在 [ ] 内部调用变量的时候,变量前可以加 []内部调用变量的时候,变量前可以加 []内部调用变量的时候,变量前可以加也可以不加 ∗ ∗ ∗ ∗ 3. ** **3. ∗∗∗∗3.[]不支持复杂的运算,比如for $[] 错误
例:
#!/bin/bash
a=5
b=6
ret=$[a + b]
echo $ret #11
echo $[$a + $b] #11
c=$[a++]
echo $c #5
echo $a #6
a=5
b=6
var1=$[$a<$b]
echo $var1 #1
expr整数运算
1.expr中运算的时候,变量必须使用 ∗ ∗ ∗ ∗ 2. e x p r 在运算的时候,运算符前后必须加空格 ∗ ∗ ∗ ∗ 3. e x p r 运算的结果会自动打印到终端上 ∗ ∗ ∗ ∗ 4. 将 e x p r 运算的结果赋值给某个变量的时候要使用命令置换 ‘ ‘ 或者 ** **2.expr在运算的时候,运算符前后必须加空格** **3.expr运算的结果会自动打印到终端上** **4.将expr运算的结果赋值给某个变量的时候要使用命令置换 ` ` 或者 ∗∗∗∗2.expr在运算的时候,运算符前后必须加空格∗∗∗∗3.expr运算的结果会自动打印到终端上∗∗∗∗4.将expr运算的结果赋值给某个变量的时候要使用命令置换‘‘或者()
5.expr做自加运算不行,可以替换成a=expr $a + 1
6.expr在运算*时候需要加上转译字符 ,不能运算等等**
例:
#!/bin/bash
a=5
b=6
echo `expr $a + $b` #输出11
expr $a + $b #输出11
a=`expr $a + 1`
echo $a #输出6
mul=`expr $a * $b`
echo $mul #输出36
expr字符串的操作
1.expr match 源字符串 子字符串
在源字符串中查找字符串差,如果源字符串中的
第一个字符和子字符串不相等结果为0,如果子字符串
有字符和源字符串中的字符不相等,返回的也是0.
否则返回的就是子字符串的长度。
例:
#!/bin/bash
string="www.hqyj.com"
expr match $string "www." #输出4
**2.expr substr $string 4 3 **
在string中截取从第四个字符开始,向后的3个字符
例:
#!/bin/bash
string="www.hqyj.com"
expr substr $string 4 3 #输出.hg
3.expr index $string “hj” #5
那h字符在string查找第一次出现的位置,如果
找到了就返回它前面的字符的个数,字符个数包括它本身,然后结束。
若找不到接着拿j字符在string查找第一次位置
如果找到返回j前面的字符个数,否则返回0
例:
#!/bin/bash
string="www.hqyj.com"
expr index $string "hj" #输出5
4.expr length $string
功能获取string变量字符串的长度
#!/bin/bash
string="www.hqyj.com"
expr length $string #输出12
let整数运算
let 表达式1 表达式2 … 表达式n
1.let会运算所有的表达式
2.let中变量可以加 , 也可以不加 ,也可以不加 ,也可以不加
3.运算符的前后不能加空格
例:
#!/bin/bash
a=5
b=6
let sum=$a+$b
echo $sum #11
let sum1=$a+$b sum2=$a+$b
echo $sum1 #11
echo $sum2 #11
let a=$a+1
echo $a #6
let mul=a*b
echo $mul #36
if语句
if 语句后面需要加空格 [ ] 里面的语句需要加空格与[ ]分开
♦ if …then …fi
语法结构:
if [ 表达式 ] ===>[ ] 用作判断的和test效果是一样
then ===>[ ] 替换为if test 表达式
分支语句
fi
● 如果表达式为真,则执行命令表中的命令;否则退出if 语句,即执行fi后面的语句
● if 和 fi 是条件语句的语句括号,必须成对使用
● 命令表中的命令可以是一条,也可以是若干条
如:
if [ 表达式 ]
then
分支语句
elif [ 表达式 ]
then
分支语句
else
分支语句
fi
在if语句中判断数字的大小
| 符号 | 判断 |
|---|---|
| -gt | 大于 |
| -lt | 小于 |
| -ge | 大于等于 |
| -le | 小于等于 |
| -eq | 等于 |
| -ne | 不等于 |
逻辑运算符
| 符号 | 判断 |
|---|---|
| -a | && |
| -o | || |
| ! | ! |
| 例: | |
| 练习: |
90-100 A
80-89 B
70-79 C
60-69 D
<60 E
#!/bin/bash
read -p "请输入学生的成绩->" str1
if [ $str1 -ge 100 -o $str1 -le 0 ] # 大于100 或者小于0
then
echo "input error!"
exit 1 #直接返回
fi
if [ $str1 -ge 90 -a $str1 -le 100 ] #大于等于90 并且 小于等于100
then
echo "A"
elif [ $str1 -ge 80 -a $str1 -lt 90 ]
then
echo "B"
elif [ $str1 -ge 70 -a $str1 -lt 80 ]
then
echo "C"
elif [ $str1 -ge 60 -a $str1 -lt 70 ]
then
echo "D"
else
echo "E"
fi
练习:
90-100 A
80-89 B
70-79 C
60-69 D
<60 E
if [ $score -gt 100 -o $score -lt 0 ]
then
echo "input error"
exit 1
fi
if test $score -ge 90 -a $score -le 100
then
echo "A"
elif test $score -ge 80
then
echo "B"
elif test $score -ge 70
then
echo "C"
elif [ $score -ge 60 ]
then
echo "D"
else
echo "E"
fi
1.对字符串的判断(在if语句中字符串需要加上"")
| 符号 | 意义 |
|---|---|
| -z | 判断字符串是否为空 |
| -n | 判断字符串是否为非空 |
| =或者== | 判断两个字符串是否相等 |
| != | 不等于 |
| \> | 判断字符串大小,大于 |
| \< | 判断字符串大小,小于 |
练习:
输入两个字符串,判断字符串的大小,并输出
#!/bin/bash
read -p "please input str1 > " str1
read -p "please input str2 > " str2
if [ -z "$str1" -o -z "$str2" ]
then
echo "input string error,please try agian"
exit 1
fi
if [ "$str1" == "$str2" ]
then
echo "str1 = str2"
elif [ "$str1" \> "$str2" ]
then
echo "str1 > str2"
else
echo "str1 < str2"
fi
2.对文件的类型的判断bsp-lcd
-b 判断文件是否存在,并且判断文件是否是块设备
-c 判断文件是否存在,并且判断文件是否是字符设备
-d 判断文件是否存在,并且判断文件是否是目录
-f 判断文件是否存在,并且判断文件是否是普通文件
-L 判断文件是否存在,并且判断文件是否是链接文件
-S 判断文件是否存在,并且判断文件是否是套接字文件
-p 判断文件是否存在,并且判断文件是否是管道文件
-e 判断文件是否存在
如果文件存在,结果为真
如果文件存在,结果为假
(如果是链接文件,链接断开了,认为文件不存在)
-s 判断文件是否存在,并且判断文件是否为空
练习
请输入一个文件的名字,将它的类型输出
#!/bin/bash
read -p "请输入1个文件的名字" filename
if test -b $filename
then
echo "这是一个块设备文件"
elif test -c $filename
then
echo "这是一个字符设备文件"
elif test -d $filename
then
echo "这是一个目录"
elif test -f $filename
then
echo "这是一个普通文件"
elif test -L $filename
then
echo "这是一个链接文件"
elif test -S $filename
then
echo "这是一个套接字文件"
fi
3.文件权限的判断
-w 判断文件是否存在,并判断是否具备写的权限
-r 判断文件是否存在,并判断是否具备读的权限
-x 判断文件是否存在,并判断是否具备可执行的权限
练习
请输入一个文件,判断这个文件是否是普通文件,
如果文件是普通文件,判断文件是否具备写的权限,
如果文件具备写的权限,将"hello world"追加到文件尾部
#!/bin/bash
read -p "请输入1个文件的名字" filename
if test -f $filename #判断普通文件
then
if test -w $filename #判断是否具有写的权限
then
echo "hello world" >> $filename
echo "追加成功"
else
"文件不具备写的权限"
fi
else
if [ ! -e $filename ]
then
echo "文件不存在"
else
echo "输入的不是一个普通文件"
fi
fi
./dem1.sh #调用自己重新执行,文件名为dem1.sh
4.判断文件的时间戳
-nt 前面文件时间戳是否比后面文件的时间戳新
-ot 前面文件时间戳是否比后面文件的时间戳旧
5.判断文件的inode号是否相同
-ef 判断文件的inode是否相同
case … in 语句
case 变量 in
选项1)
分支1
;;
选项2)
分支2
;;
*)
分支n
;;
esac
练习1
1.在终端上输入一个字符,a-z A-Z打印这是一个字母
0-9这是一个数字, ,;“ ?这是一个标点符号
#!/bin/bash
read -p "输入一个字符" str1
case $str1 in
[0-9])
echo "这是一个数字"
;;
[a-zA-Z])
echo "这是一个字母"
;;
, |. | \" | \?) #? 是一个通配符,需要转义
echo "这是一个标点符号"
;;
*)
echo "非法输入"
;;
esac
练习2
输入软件的名字[Y/N/Q]?来决定是否下载,用户的选择可以是Y y YES Yes yes等都要满足
#!/bin/bash
read -p "请输入软件的名字" name
read -p "是否进行下载->(y|n|q)" down
case $down in
Y|y|YES|Yes|yes)
echo "下载软件"
;;
n|N|no|No)
echo "不下载软件"
;;
q|Q|Quit|QUIT)
exit 1 #程序退出
;;
esac
while循环
while 表达式
do
循环体
done
♦ while语句首先测试其后的命令或表达式的值,如果为真,就执行一次循环体中的命令,然后再测试该命令或表达式的值,执行循环体,直到该命令或表达式为假时退出循环
♦ while语句的退出状态为命令表中被执行的最后一条命令的退出状态
写 成while true 是死循环
练习1
时钟程序
#!/bin/bash
sec=58
min=02
hour=20
day=24
month=4
year=2020
function years() #函数
{
if ((year%100==0))
then
if ((year%400==0))
then
echo 1
else
echo 2
fi
elif ((year%4==0))
then
echo 1
else
echo 2
fi
}
while true
do
sleep 1
((sec++))
if [ $sec -ge 60 ]
then
sec=0;
((min++))
elif [ $min -ge 60 ]
then
min=0
((hour++))
elif [ $hour -ge 24 ]
then
hour=0
((day++))
case $month in
1|3|5|7|8|10|12)
if [ $day -ge 32 ]
then
day=1
((month++))
fi
;;
4|6|9|11)
if [ $day -ge 31 ]
then
day=1
((month++))
fi
;;
2)
ret=`years year`
if [ $ret -eq 1 ]
then
if [ $day -ge 30 ]
then
day=1
((month++))
fi
elif [ $ret -eq 2 ]
then
if [ $day -ge 29 ]
then
day=1
((month++))
fi
fi
;;
esac
if [ $month -ge 12 ]
then
month=1
((year++))
fi
fi
printf "%4d-%2d-%2d %02d:%02d:%02d\r" $year $month $day $hour $min $sec
done
练习2
求1-100的和
#!/bin/bash
i=1
while [ $i -le 100 ]
do
((sum+=i++))
done
echo $sum
until循环
until 表达式
do
循环体
done
until循环和while循环的功能类似,只不过until循环中的表达式要和while循环的表达式结果相反,此时until和while的功能就是一样的了
练习1
1.实现一个累加器(在终端上可以任意多的输入数据它会将输入数的和给求出来)
ctrl + c 相当于给程序发送了一个杀死进程的信号
ctrl + d 相当于发送了一个EOF,可以让read结束
#!/bin/bash
i=1
until [ $i -gt 100 ]
do
((sum+=i++))
done
echo $sum
for循环
c语言风格的for循环(算术运算)
for ((i=0;i<10;i++))
do
循环体
done
例:
#!/bin/bash
for ((i=1;i<=100;i++))
do
((sum+=i))
done
echo $sum
shell特有风格的for循环(文件)
for 变量 in 单词列表
do
循环体
done
1.单词列表的成员间是通过空格隔开
2.单词类别中可以使用命令的结果,命令需要加上命令置换符号 `` $()
3.如果单词列表是连续的成员{start…end}
seq 1 100从1开始到100结束作为单词列表
seq 1 2 100 从1开始,中间跳过一个成员,到100结束
例:
#!/bin/bash
for i in `ls`
do
echo $i
done
省略in部分的for循环
for 变量 ==>省略in部分,会把命令行参数作为单词列表
do
循环体
done
#!/bin/bash
#1-100的和
for num in {1..100}
do
((sum+=$num))
done
echo $sum
#循环列表是a-z字符
for num in {a..z}
do
echo -n $num
done
printf "\n"
#1-100求和,跳过偶数部分
for num in $(seq 1 2 100)
do
echo $num
((sum+=$num))
done
echo $sum
#缺省in
for cmd_var
do
echo $cmd_var
done
练习
(1)判断用户主目录下是否存在file-dir和dir-dir的
子目录,如果存在则提示用户是否删除,如果用户输
入的是 yes,则删除,然后新建,否则结束 , 如果不
存在,则新建
(2)输入一个指定路径的目录,将这个目录下的文件和
目录分开存放,将文件拷贝到用户主目录下的
file-dir子目录下,将目录拷贝到用户主目录下
的dir-dir子目录下,并且统计文件和子目录的个数
(3)输出拷贝的文件和目录的个数
#!/bin/bash
user=("/home/c/file-dir/" "/home/c/dir-dir/")
for dir in ${user[@]}
do
if [ -d $dir ]
then
read -p "是否删除->$dir(y/n)" flase
case $flase in
y|Y|Yes|YES|yes)
echo "删除$dir目录"
rm $dir -rf
echo "新建$dir"
mkdir $dir
;;
n|N|NO|No|no)
echo "退出..."
exit 1
;;
*)
echo "选择无效..."
exit 1
esac
else
echo "新建目录"
mkdir $dir
fi
done
read -p "请输入一个路径> " mypath
if test -d $mypath
then
for file in `ls $mypath`
do
if test -f $mypath/$file
then
cp $mypath/$file ${user[0]}
((f++))
elif test -d $mypath/$file
then
cp $mypath/$file ${user[1]} -r
((d++))
fi
done
else
echo "输入的不是一个路径,请重试"
exit 1
fi
echo "拷贝的文件的个数$f"
echo "拷贝的文件的个数$d"
select in 语句
select 变量 in 单词列表
do
语句
done
#!/bin/bash
select ch in a b c d
do
echo $ch
break
done
#!/bin/bash
select sys in windows linux macOS ios Android
do
case $sys in
windows)
echo "welcome using windows"
;;
linux)
echo "welcome using linux"
;;
macOS)
echo "welcome using macOS"
;;
ios)
echo "welcome using ios"
;;
Android)
echo "welcome using Android"
;;
esac
break
done
#!/bin/bash
#PS3 它是系统的一个环境变量,默认值为#?
PS3="input >"
select ch in register login quit
do
case $ch in
register)
echo "注册"
;;
login)
echo "登录"
;;
quit)
echo "退出"
exit 1
;;
esac
done
select会生成一个选择的列表,如下
1) a
2) b
3) c
4) d
#? ==>可以输入用户的选择,这里只能
==>只能输入数字,不能输入单词列
==>表中的选项
select如果没有输入ctrl+d或者break它会一直
执行。
在工作或开发过程中select和case语句结合使用。
#PS3 它是系统的一个环境变量,默认值为#?
PS3=“input >”
break和continue
用法:
break ==>退出一层循环
break n ==>退出n层循环
用法:
continue ==>跳过一层循环
continue n ==>跳过n层循环
例:
输出:1 2 3 4
2 4 6 8
3 6 9 12
4 8 12 16
#!/bin/bash
i=0
j=0
while ((++i))
do
j=0
while ((++j))
do
if [ $j -gt 4 ]
then
break
fi
if [ $i -gt 4 ]
then
break 2
fi
printf "%-4d" $((i*j))
done
printf "\n"
done
使用for循环实现
#!/bin/bash
j=1
for((i=1;i<=4;i++))
do
for((j=1;j*i<=4*i;j++))
do
printf "%d\t" $((j*i))
done
echo
done
shell中的函数
function 函数名()
{
}
1.shell中的函数没有参数列表
2.shell中的函数没有返回值类型
3.shell中的函数是使用function声明的
4.shell的函数名的命名和c语言一样
5.shell的函数如果不调用的话是不会执行的
函数的调用
函数名 参数列表1 参数列表2
函数的参数通过位置变量获取
$0 :脚本的名字
$1 $2 $3 …
$@ ∗ " * " ∗"@" 将命令行的参数原封不动的传递给子函数
“$*” 将命令行的参数看成一个整体传递给子函数
shell中函数返回值的问题?
1.shell函数的的变量默认都是全局变量,
可以直接使用,但是如果变量被local声明了
它就变成了局部变量。
2.shell中的函数执行的结果可以通过return返回,
return返回的时候可以通过$?获取返回的结果。
返回值的范围是[0-255]
3.shell的函数可以通过echo来返回字符串
通过ret=`` 或ret=$() 获取结果,注意在
函数中使用一次echo即可,如果在函数内
使用了多次echo,获取的结果就是多次echo的值
中间通过空格分开
#!/bin/bash
function ShowVar()
{
echo $0
echo $1
echo $2
echo "----------------"
echo $@
echo "#########################"
}
#ShowVar $@
#ShowVar "$@"
#ShowVar $*
#ShowVar "$*"
function Add()
{
((sum=$1+$2))
}
Add 12 23 #函数中的sum是全局变量
echo $sum #可以直接获取值
function Add1()
{
local sum
((sum=$1+$2))
return $sum
}
Add1 255 0 #函数中的local sum是局部变量,可以通过return返回【0-255】
echo $? #$?获取上一步调用函数的结果
function ShowEcho()
{
((sum=$1+$2))
echo $sum
}
ret=`ShowEcho 255 255` #若函数需要返回【0-255】区间外的数据或者返回字符串
echo $ret #在函数中调用echo就行了,在调用函数执行的时候需要加上命
#令置换,不能通过$?获取结果
#ret=`ls /home/linux/` #通过对本次赋值理解为什么函数中的
#echo $ret #echo没有输出
练习1
1.输入用户的名字,判断该系统上是否存在该用户
2.若存在该用户将这个用户名和uid和gid显示出来
#!/bin/bash
#打印行号
function check_user()
{
local line=`cat /etc/passwd | cut -d : -f 1 |grep "$1" -nw |cut -d : -f 1`
echo $line
}
#打印uid,pid
function show_user_info()
{
local info=`head -"$1" /etc/passwd | tail -1 | cut -d : -f 1,3-4`
echo $info
}
while true
do
read -p "请输入用户的名 > " name
if [ $name = quit ]
then
echo "退出用户查询系统"
exit 1
fi
line=`check_user $name`
if [ -z "$line" ]
then
echo "用户不存在"
continue
else
echo "用户存在,行号是$line"
fi
info=`show_user_info $line`
echo $info
done
练习2
封装一个对数组成员求和的函数,并将求得结果返回
#!/bin/bash
function array_sum()
{
local sum
for i
do
((sum+=$i))
done
echo $sum
}
arr=(11 22 33 44 55)
sum=`array_sum ${arr[@]}`
echo $sum
练习3
1.请输入一个路径,若此目录下文件是以.c结尾
的文件,并且是普通文件,请将这个文件编译,
若文件不是.c结尾的文件,请在文件结尾加上.bak
#!/bin/bash
read -p "输入一个路径" mypath
if test -d $mypath
then
for file in `ls $mypath`
do
if test -f $mypath/$file
then
case $mypath/$file in
*.c)
gcc $mypath/$file
mv a.out $mypath
;;
*)
base=${file%.*} #把原来的后缀清除
mv $mypath/$file $mypath/${base}.bak #添加新的后缀
;;
esac
fi
done
fi
练习4
1.编写一个shell脚本完成如下功能 :
1.在家目录下创建文件夹filer
2.遍历当前文件夹下的文件,如果是普通文件则放入创建的filer中
3.打印出放入filer文件夹中的文件数目
#!/bin/bash
cd
mkdir filer
for file in `ls `
do
if test -f $file
then
cp $file ./filer
((f++))
fi
done
echo "拷贝文件的个数$f"