从零开始的知识图谱生活,构建一个百科知识图谱,完成基于Deepdive的知识抽取、基于ES的简单语义搜索、基于 REfO 的简单KBQA

项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

-
专栏订阅:项目大全提升自身的硬实力
-
[专栏详细介绍:项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域)
从零开始的知识图谱生活,构建一个百科知识图谱,完成基于Deepdive的知识抽取、基于ES的简单语义搜索、基于 REfO 的简单KBQA
个人入门知识图谱过程中的学习笔记,算是半教程类的,指引初学者对知识图谱的各个任务有一个初步的认识。目前暂无新增计划。
1.简介
目标是包含百度百科、互动百科、中文wiki百科的知识,千万级实体数量和亿级别的关系数目。目前已完成百度百科和互动百科部分,其中百度百科词条4,190,390条,互动百科词条4,382,575条。转换为RDF格式得到三元组 128,596,018个。存入 neo4j中得到节点 16,498,370个,关系 56,371,456个,属性 61,967,517个。
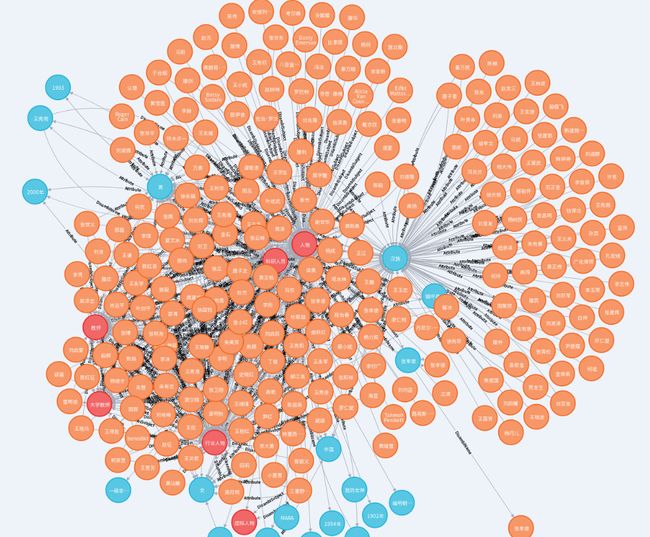
项目码源见文章顶部或文末
https://download.csdn.net/download/sinat_39620217/87988980
- 目录
-
百度百科与互动百科的知识抽取
- 半结构化数据
- 百度百科爬虫
- 互动百科爬虫
- 非结构化数据
- 微信公众号爬虫
- 虎嗅网爬虫
- 半结构化数据
-
非结构化文本的知识抽取
- 制作类似于NYT的远程监督学习语料–baidu_6w
- 神经网络关系抽取
-
知识存储
- D2RQ 的使用
- Jena 的使用
-
知识融合
- Silk 实战
-
KBQA
- 基于 REfO 的简单KBQA
-
语义搜索
- 基于elasticsearch 的简单语义搜索 支持实体检索、实体属性检索和条件检索
-
2.获取数据
2.1 半结构化数据
半结构化数据从百度百科和互动百科获取,采用scrapy框架,目前电影领域和通用领域两类。
- 通用领域百科数据:百度百科词条4,190,390条,互动百科词条3,677,150条。爬取细节请见从零开始构建知识图谱(七)百科知识图谱构建(一)百度百科的知识抽取
- 电影领域: 百度百科包含电影22219部,演员13967人,互动百科包含电影13866部,演员5931 人。项目详细介绍请见从零开始构建知识图谱(一)半结构化数据的获取
2.2 非结构化数据
非结构化数据主要来源为微信公众号、虎嗅网新闻和百科内的非结构化文本。
微信公众号爬虫获取公众号发布文章的标题、发布时间、公众号名字、文章内容、文章引用来源,对应 ie/craw/weixin_spider。虎嗅网爬虫 获取虎嗅网新闻的标题、简述、作者、发布时间、新闻内容,对应 ie/craw/news_spider。
3. 非结构化文本的知识抽取
3.1 基于Deepdive的知识抽取
Deepdive是由斯坦福大学InfoLab实验室开发的一个开源知识抽取系统。它通过弱监督学习,从非结构化的文本中抽取结构化的关系数
据 。本次实战基于OpenKG上的[支持中文的deepdive:斯坦福大学的开源知识抽取工具(三元组抽取)](http://www.openkg.cn/ dataset/cn-deepdive),我们基于此,抽取电影领域的演员-电影关系。
详细介绍请见从零开始构建知识图谱(五)Deepdive抽取演员-电影间关系
3.2 神经网络关系抽取
利用自己的百科类图谱,构建远程监督数据集,并在OpenNRE上运行。最终生成的数据集包含关系事实18226,无关系(NA)实体对336 693,总计实体对354 919,用到了462个关系(包含NA)。
详细介绍请见从零开始构建知识图谱(九)百科知识图谱构建(三)神经网络关系抽取的数据集构建与实践
4.结构化数据到 RDF
结构化数据到RDF由两种主要方式,一个是通过direct mapping,另一个通过R2RML语言这种,基于R2RML语言的方式更为灵活,定制性强。对于R2RML有一些好用的工具,此处我们使用d2rq工具,它基于R2RML-KIT。
详细介绍请见从零开始构建知识图谱(二)数据库到 RDF及 Jena的访问

5.知识存储
5.1 将数据存入 Neo4j
图数据库是基于图论实现的一种新型NoSQL数据库。它的数据数据存储结构和数据的查询方式都是以图论为基础的。图论中图的节本元素为节点和边,对应于图数据库中的节点和关系。我们将上面获得的数据存到 Neo4j中。
百科类图谱请见:从零开始构建知识图谱(八)百科知识图谱构建(二)将数据存进neo4j
电影领域的请见从零开始构建知识图谱(六)将数据存进Neo4j
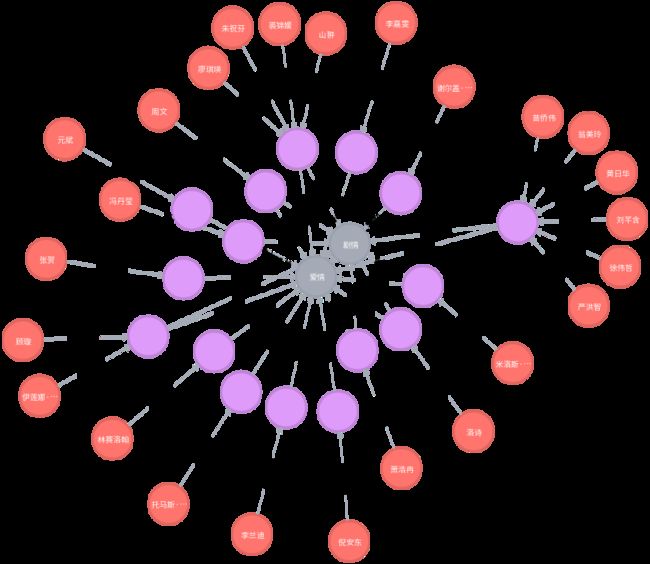

6.KBQA
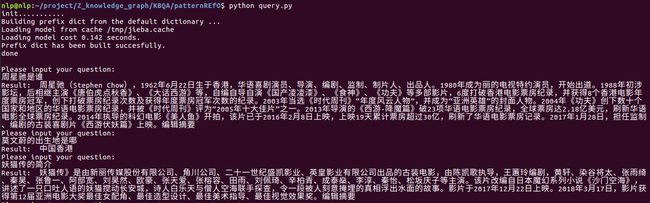
6.1 基于 REfO 的简单KBQA
基于浙江大学在openKG上提供的 基于 REfO 的 KBQA 实现及示例,在自己的知识图谱上实现简单的知识问答系统。
详细介绍请见从零开始构建知识图谱(三)基于REfO的简单知识问答
- 示例
语义搜索
基于elasticsearch 的简单语义搜索
本项目是对浙大的 基于elasticsearch的KBQA实现及示例 的简化版本,并在自己的数据库上做了实现。
详细介绍请见从零开始构建知识图谱(四)基于ES的简单语义搜索
- 示例

项目码源见文章顶部或文末
https://download.csdn.net/download/sinat_39620217/87988980