Java-Stream详解
Stream 定义
Stream是Java 8新增的接口,Stream可以认为是一个高级版本的 Iterator。
Stream跟Iterator的差别
| 名称 | 含义 |
|---|---|
| 无存储 | Stream是基于数据源的对象,它本身不存储数据元素,而是通过管道将数据源的元素传递给操作。 |
| 函数式编程 | 函数式编程:对Stream的任何修改都不会修改背后的数据源,比如对Stream执行filter操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新的Stream。 |
| 延迟执行 | Stream的操作由零个或多个中间操作(intermediate operation)和一个结束操作(terminal operation)两部分组成。只有执行了结束操作,Stream定义的中间操作才会依次执行,这就是Stream的延迟特性。 |
| 可消费性 | Stream只能被“消费”一次,一旦遍历过就会失效。就像容器的迭代器那样,想要再次遍历必须重新生成一个新的Stream。 |
Stream的操作是建立在函数式接口的组合之上的
Java8中新增的函数式接口都在java.util.function包下。这些函数式接口可以有多种分类方式。其中B开头的是二元函数,其他是一元函数
| 名称 | 函数 | 示例 |
|---|---|---|
| 一般函数 | Function,BiFunction | 例如:get方法 |
| 算子函数 | UnaryOperator,BinaryOperator | 例如:stream.reduce方法的参数 |
| 谓词函数 | Predicate,BiPredicate | 例如:stream.filter方法的参数 |
| 消费者 | Consumer,BiConsumer | 例如:set方法 |
| 供应者 | Supplier,BiSupplier | 例如:get方法 |
Stream的操作符
流的操作类型主要分为两种:中间操作符(Intermediate)、终端操作符(Terminal)
-
Stream的操作由零个或多个中间操作(intermediate operation)和一个结束操作(terminal operation)两部分组成。只有执行了结束操作,Stream定义的中间操作才会依次执行,这就是Stream的延迟特性。
-
中间操作只是将流从一个流变成了另一个流,结束操作会生成对应的数据
-
这里无状态即无序,短路操作和非短路操可以理解为对应的算法操作
| 操作分类 | 名称 | 含义 | 示例 |
|---|---|---|---|
| 中间操作符 | 无状态 | 指元素的处理不受之前元素的影响 | unordered() filter() map() mapToint() mapToLong() mapToDouble() flatMap() flatMapToInt() flatMapToLong() flatMapToDouble() peek() |
| 中间操作符 | 有状态 | 指该操作只有拿到所有元素之后才能继续下去 | distinct() sorted() limit() skip() |
| 终端操作符 | 非短路操作 | 指必须处理所有元素才能得到最终结果 | forEach() forEachOrdered() toArray() reduce() collect() max() min() count() |
| 终端操作符 | 短路操作 | 指遇到某些符合条件的元素就可以得到最终结果,如 A或B,只要A为true,则无需判断B的结果 | anyMatch() allmatch() noneMatch() findFirst() findAny() |
Stream的使用
对 Stream 的使用可以分为3步:
一、创建 Stream
1、使用Collection下的 stream() 和 parallelStream() 方法
List list = new ArrayList<>();
Stream stream = list.stream(); //获取一个顺序流
Stream parallelStream = list.parallelStream(); //获取一个并行流
2、使用Arrays 中的 stream() 方法,将数组转成流
Integer[] nums = new Integer[10];
Stream stream = Arrays.stream(nums);
3、使用Stream中的静态方法:of()、iterate()、generate()
Stream stream = Stream.of(1,2,3,4,5,6);
Stream stream2 = Stream.iterate(0, (x) -> x + 2).limit(6); // 不使用limit会无限生成
Stream stream3 = Stream.generate(Math::random).limit(2); // 不使用limit会无限生成
4、使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("D:\\stream.txt"));
Stream lineStream = reader.lines();
lineStream.forEach(System.out::println);
5、使用 Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");
Stream stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);
二、Intermediate(可以多次):通过一系列中间操作,对数据集进行过滤、检索等数据集的再次处理。
1、筛选与切片
| 名称 | 含义 | 参数类型 |
|---|---|---|
| filter | 过滤流中的某些元素 | Predicate |
| limit(n) | 获取n个元素 | long |
| skip(n) | 跳过n元素,配合limit(n)可实现分页 | long |
| distinct | 通过流中元素的 hashCode() 和 equals() 去除重复元素 | 无 |
// list中大于6且小于9的元素个数
List list = Arrays.asList(7, 6, 9, 3, 8, 2, 1, 2);
long count = list.stream().filter(x -> x > 6&&x < 9).count();
System.out.println("list中大于6且小于9的元素个数:" + count);
// 对流进行过滤去重,跳过和限制获取
Stream newStream = list.stream()
.filter(e -> e > 1) // 7, 6, 9, 3, 8, 2, 2
.distinct() // 7, 6, 9, 3, 8, 2
.skip(2) // 9, 3, 8, 2
.limit(2); // 9, 3
2、映射
| 名称 | 含义 | 参数类型 |
|---|---|---|
| map | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素 | Function |
| flatMap | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流,及扁平化流,降低集合或对象的复杂程度,就像下面的例子一样把String[] 降级为String,然后在进行操作 | Function> T表示映射对象的类型,R表示返回的值是Stream的子类型 |
// map
List stringList = Arrays.asList("hello", "world");
List collect = stringList.stream()
.map(str -> str.split(""))
.distinct().collect(Collectors.toList());
collect.forEach(col-> System.out.println(Arrays.toString(col)));
//[h, e, l, l, o]
//[w, o, r, l, d]
// flatMap
List flatMapCollect = stringList.stream()
.map(str -> str.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
System.out.println(flatMapCollect);
//[h, e, l, o, w, r, d]
3、排序
| 名称 | 含义 | 参数类型 |
|---|---|---|
| sorted() | 自然排序,流中元素需实现Comparable接口 | 无 |
| sorted(Comparator com) | 定制排序,自定义Comparator排序器 | Comparator comparator |
单个排序
// sorted()
List authors = StreamDataInit.getAuthors();
List defaultList = authors.stream().sorted().collect(Collectors.toList());
defaultList.forEach(e -> System.out.println("Id:"+ e.getId()+", Name: "+e.getName()+", Age:"+e.getAge()));
// sorted(Comparator com)
defaultList = authors.stream().sorted(Comparator.comparing(Author::getAge).reversed()).collect(Collectors.toList());
defaultList.forEach(e -> System.out.println("Id:"+ e.getId()+", Name: "+e.getName()+", Age:"+e.getAge()));
多个排序
//方法1:先对年龄进行升序,升序结果进行反转,再对班级进行降序
userList = userList.stream().sorted(Comparator.comparing(User::getAge).reversed().thenComparing(User::getClassNo, Comparator.reverseOrder())).collect(Collectors.toList());
//方法2:直接对年龄进行降序,再对班级进行降序
userList = userList.stream().sorted(Comparator.comparing(User::getAge, Comparator.reverseOrder()).thenComparing(User::getClassNo, Comparator.reverseOrder())).collect(Collectors.toList());
//方式3:先对年龄进行升序,再对班级进行升序,最后对结果进行反转
userList = userList.stream().sorted(Comparator.comparing(User::getAge).thenComparing(User::getClassNo).reversed()).collect(Collectors.toList());
总结: sorted的参数
-
如果只进行单个字段的升序降序排列,我们使用reversed() 或者 Comparator.reverseOrder() 都可以
-
如果要进行多个字段的升序降序排列,我们还是使用 Comparator.reverseOrder() 会更优雅、更好理解一些
-
参数形式速记
- 无参数sorted() 这种排序相当于没有排序,他返回的是自然排序,而stream本身是无序的
- Comparator.comparing(Author::getAge)
- Comparator.comparing(Author::getAge).reversed()
- Comparator.comparing(User::getAge, Comparator.reverseOrder())
- Comparator.comparing(User::getAge, Comparator.reverseOrder()).thenComparing(User::getName, Comparator.reverseOrder())
4、消费
- peek:如同于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,没有返回值。
- peek:如同于forEach,peek是中间操作,而forEach是终端操作
Student s1 = new Student("aa", 10);
Student s2 = new Student("bb", 20);
List studentList = Arrays.asList(s1, s2);
studentList.stream()
.peek(o -> o.setAge(100))
.forEach(System.out::println);
//结果:
Student{name='aa', age=100}
Student{name='bb', age=100}
三、Terminal(只有一次):通过最终(terminal)方法完成对数据集中元素的最终处理。
1、 匹配、聚合操作
| 名称 | 含义 | 参数类型 |
|---|---|---|
| allMatch | 接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false | Predicate |
| noneMatch | 接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false | Predicate |
| anyMatch | 接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false | Predicate |
| findFirst | 返回流中第一个元素 | 无 |
| findAny | 返回流中的任意元素 | 无 |
| count | 返回流中元素的总个数 | 无 |
| max | 返回流中元素最大值 | Comparator |
| min | 返回流中元素最小值 | Comparator |
List list = Arrays.asList(1, 2, 3, 4, 5);
boolean allMatch = list.stream().allMatch(e -> e > 10); //false
boolean noneMatch = list.stream().noneMatch(e -> e > 10); //true
boolean anyMatch = list.stream().anyMatch(e -> e > 4); //true
Integer findFirst = list.stream().findFirst().get(); //1
Integer findAny = list.stream().findAny().get(); //1
long count = list.stream().count(); //5
Integer max = list.stream().max(Integer::compareTo).get(); //5
Integer min = list.stream().min(Integer::compareTo).get(); //1
2、 规约操作
规约操作又被称作折叠操作,是通过某个连接动作将所有元素汇总成一个汇总结果的过程。元素求和、求最大值或最小值、求出元素总个数、将所有元素转换成一个列表或集合,都属于规约操作。_Stream_类库有两个通用的规约操作reduce()和collect(),也有一些为简化书写而设计的专用规约操作,比如sum()、max()、min()、count()等。

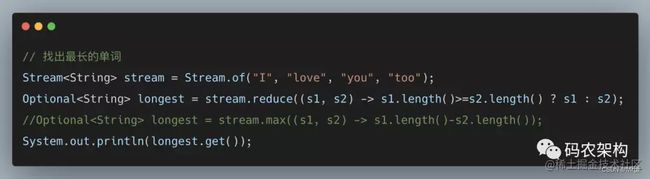
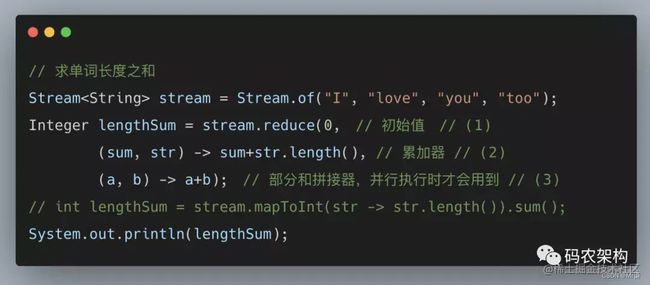
/**============================================================使用reduce求所有作者年龄的和===**/
List authors = StreamDataInit.getAuthors();
Integer sum = authors.stream()
.distinct()
.map(author -> author.getAge())
.reduce(0, (result, element) -> result + element);
System.out.println(sum);
/**============================================================使用reduce求所有作者中年龄的最大值===**/
Integer reduce1 = authors.stream()
.map(author -> author.getAge())
.reduce(Integer.MIN_VALUE, (result, element) -> result < element ? element : result);
System.out.println(reduce1);
/**============================================================使用reduce求所有作者中年龄的最小值===**/
Integer reduce2 = authors.stream()
.map(author -> author.getAge())
.reduce(Integer.MAX_VALUE, (result, element) -> result > element ? element : result);
System.out.println(reduce2);
/**============================================================用一个参数的重载方法去求最小值代码===**/
Optional reduce = authors.stream()
.map(author -> author.getAge())
.reduce(new BinaryOperator() {
@Override
public Integer apply(Integer result, Integer element) {
return result > element ? element : result;
}
});
reduce.ifPresent(age -> System.out.println(age));
/**============================================================求和方式===**/
List list = Arrays.asList(1, 3, 2, 8, 11, 4);
// 求和方式1
Optional sum1 = list.stream().reduce((x, y) -> x + y);
// 求和方式2
Optional sum2 = list.stream().reduce(Integer::sum);
// 求和方式3
Integer sum3 = list.stream().reduce(0, Integer::sum);
System.out.println("list求和:" + sum1.get() + "," + sum2.get() + "," + sum3);
// 求和方式4
Integer sum4 = authors.stream().collect(Collectors.reducing(0, Author::getAge, (i, j) -> (i + j - 5000)));
System.out.println("作家扣税薪资总和:" + sum4);
// 求和方式5
Optional sum5 = authors.stream().map(Author::getAge).reduce(Integer::sum);
System.out.println("作家薪资总和:" + sum5.get());
// 求和方式6
BigDecimal sumSalary = authors.stream()
.map(Author::getSalary)
.reduce(BigDecimal.ZERO, BigDecimal::add);
System.out.println("工资之和:"+sumSalary);
/**============================================================求乘积===**/
Optional product = list.stream().reduce((x, y) -> x * y);
/**============================================================求最大值===**/
// 求最大值方式1
Optional max1 = list.stream().reduce((x, y) -> x > y ? x : y);
// 求最大值写法2
Integer max2 = list.stream().reduce(1, Integer::max);
System.out.println("list求积:" + product.get());
System.out.println("list求和:" + max1.get() + "," + max2);
3、 收集操作
collect:接收一个Collector实例,将流中元素收集成另外一个数据结构。Collector
| 名称 | 含义 |
|---|---|
| Supplier supplier() | 创建一个结果容器A |
| BiConsumer |
消费型接口,第一个参数为容器A,第二个参数为流中元素T |
| BinaryOperator combiner() | 函数接口,该参数的作用跟上一个方法(reduce)中的combiner参数一样,将并行流中各 个子进程的运行结果(accumulator函数操作后的容器A)进行合并 |
| Function |
函数式接口,参数为:容器A,返回类型为:collect方法最终想要的结果R |
| Set characteristics() | 返回一个不可变的Set集合,用来表明该Collector的特征。有以下三个特征CONCURRENT:表示此收集器支持并发。UNORDERED:表示该收集操作不会保留流中元素原有的顺序。IDENTITY_FINISH:表示finisher参数只是标识而已,可忽略。 |
public class CollectorCustom {
public static void main(String[] args) {
Set collect = Arrays.asList(1, 2, 3, 3, 4, 5, 6).stream().collect(new MyCollector());
System.out.println(collect);
}
public static class MyCollector implements Collector, Set> {
@Override
public Supplier> supplier() {
System.out.println("MyCollector.supplier");
return HashSet::new; -->我们提供一个HashSet
}
@Override
public BiConsumer, T> accumulator() {
System.out.println("MyCollector.accumulator");
return Set::add; -->我们处理Set 和流中元素T的关系
}
@Override
public BinaryOperator> combiner() {
System.out.println("MyCollector.combiner");
return (st1, st2) -> {
st1.addAll(st2);
return st1; ->如果是并发流,创建了多个容器,我们处理多个容器间的关系
};
}
@Override
public Function, Set> finisher() {
System.out.println("MyCollector.finisher");
return Function.identity(); -> 处理 容器和最终返回的规约,我们选择都是返回Set
}
@Override
public Set characteristics() {
System.out.println("MyCollector.characteristics");
return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, UNORDERED));
--> 当我们使用了 IDENTITY_FINISH ,其实就不用再写finisher();不知道你明不明白?
--> UNORDERED 不追求顺序,我们毕竟用的HashSet
}
}
}
4、collect实战
(1)收集 Stream 流中的数据到集合中
//1.收集数据到list集合中
stream.collect(Collectors.toList())
//2.收集数据到set集合中
stream.collect(Collectors.toSet())
//3.收集数据到指定的集合中
Collectors.toCollection(Supplier collectionFactory)
stream.collect(Collectors.joining())
/**
* 收集Stream流中的数据到集合中
* 备注:切记Stream流只能被消费一次,流就失效了
* 如下只是示例代码
*/
public class CollectDataToCollection{
public static void main(String[] args) {
//Stream 流
Stream stream = Stream.of("aaa", "bbb", "ccc", "bbb");
//收集流中的数据到集合中
//1.收集流中的数据到 list
List list = stream.collect(Collectors.toList());
System.out.println(list);
//2.收集流中的数据到 set
Set collect = stream.collect(Collectors.toSet());
System.out.println(collect);
//3.收集流中的数据(ArrayList)(不收集到list,set等集合中,而是)收集到指定的集合中
ArrayList arrayList = stream.collect(Collectors.toCollection(ArrayList::new));
System.out.println(arrayList);
//4.收集流中的数据到 HashSet
HashSet hashSet = stream.collect(Collectors.toCollection(HashSet::new));
System.out.println(hashSet);
}
}
(2)收集 Stream 流中的数据到数组中
//1.使用无参,收集到数组,返回值为 Object[](Object类型将不好操作)
Object[] toArray();
//2.使用有参,可以指定将数据收集到指定类型数组,方便后续对数组的操作
A[] toArray(IntFunction generator);
/**
* 收集Stream流中的数据到数组中
* 备注:切记Stream流只能被消费一次,流就失效了
* 如下只是示例代码
*/
public class CollectDataToArray{
public static void main(String[] args) {
//Stream 流
Stream stream = Stream.of("aaa", "bbb", "ccc", "bbb");
//2.1 使用 toArray()无参
Object[] objects = stream.toArray();
for (Object o: objects) {//此处无法使用.length() 等方法
System.out.println("data:"+o);
}
//2.2 使用有参返回指定类型数组
//无参不好的一点就是返回的是 Object[] 类型,操作比较麻烦.想要拿到长度,Object是拿不到长度的
String[] strings = stream.toArray(String[]::new);
for(String str : strings){
System.out.println("data:"+str + ",length:"+str.length());
}
}
}
(3)Stream流中数据聚合/分组/分区/拼接操作
//最大值
Collectors.maxBy();
//最小值
Collectors.minBy();
//总和
Collectors.summingInt();/Collectors.summingDouble();/Collectors.summingLong();
//平均值
Collectors.averagingInt();/Collectors.averagingDouble();/Collectors.averagingLong();
//总个数
Collectors.counting();
聚合操作
/**
* Stream流数据--聚合操作
* 备注:切记Stream流只能被消费一次,流就失效了
* 如下只是示例代码
* @author liuzebiao
* @Date 2020-1-10 13:37
*/
public class CollectDataToArray{
public static void main(String[] args) {
Stream studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77)
);
//聚合操作
//获取最大值(Stream流 max()方法亦可)
//max()方法实现
//Optional max = studentStream.max((s1, s2) -> s1.getScore() - s2.getScore());
//(聚合)实现
Optional max = studentStream.collect(Collectors.maxBy((s1, s2) -> s1.getScore() - s2.getScore()));
System.out.println("最大值:"+max.get());
//获取最小值(Stream流 min()方法亦可)
//min()方法实现
//Optional min = studentStream.max((s1, s2) -> s2.getScore() - s1.getScore());
//(聚合)实现
Optional min = studentStream.collect(Collectors.minBy((s1, s2) -> s1.getScore() - s2.getScore()));
System.out.println("最小值:"+min.get());
//求总和(使用Stream流的map()和reduce()方法亦可求和)
//map()和reduce()方法实现
//Integer reduce = studentStream.map(s -> s.getAge()).reduce(0, Integer::sum);
//(聚合)简化前
//Integer ageSum = studentStream.collect(Collectors.summingInt(s->s.getAge()));
//(聚合)使用方法引用简化
Integer ageSum = studentStream.collect(Collectors.summingInt(Student::getAge));
System.out.println("年龄总和:"+ageSum);
//求平均值
//(聚合)简化前
//Double avgScore = studentStream.collect(Collectors.averagingInt(s->s.getScore()));
//(聚合)使用方法引用简化
Double avgScore = studentStream.collect(Collectors.averagingInt(Student::getScore));
System.out.println("分数平均值:"+avgScore);
//统计数量(Stream流 count()方法亦可)
//count()方法实现
//long count = studentStream.count();
//(聚合)统计数量
Long count = studentStream.collect(Collectors.counting());
System.out.println("数量为:"+count);
}
}
分组操作
//接收一个 Function 参数
groupingBy(Function classifier)
/**
* Stream流数据--分组操作
* 备注:切记Stream流只能被消费一次,流就失效了
* 如下只是示例代码
* @author liuzebiao
* @Date 2020-1-10 13:37
*/
public class CollectDataToArray{
public static void main(String[] args) {
Stream studentStream = Stream.of(
new Student("赵丽颖", 52, 56),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 53)
);
//1.按照具体年龄分组
Map> map = studentStream.collect(Collectors.groupingBy((s -> s.getAge())));
map.forEach((key,value)->{
System.out.println(key + "---->"+value);
});
//2.按照分数>=60 分为"及格"一组 <60 分为"不及格"一组
Map> map = studentStream.collect(Collectors.groupingBy(s -> {
if (s.getScore() >= 60) {
return "及格";
} else {
return "不及格";
}
}));
map.forEach((key,value)->{
System.out.println(key + "---->"+value.get());
});
//3.按照年龄分组,规约求每组的最大值(规约:reducing)
Map> reducingMap = studentStream.collect(
Collectors.groupingBy(Student::getAge,
Collectors.reducing(
BinaryOperator.maxBy(
Comparator.comparingInt(Student::getScore)
)
)
)
);
reducingMap .forEach((key,value)->{
System.out.println(key + "---->"+value);
});
}
}
多级分组操作
//接收两个参数: 1.Function 参数 2.Collector多级分组
groupingBy(Function classifier,Collector downstream)
/**
* Stream流数据--多级分组操作
* 备注:切记Stream流只能被消费一次,流就失效了
* 如下只是示例代码
* @author liuzebiao
* @Date 2020-1-10 13:37
*/
public class CollectDataToArray{
public static void main(String[] args) {
Stream studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33)
);
//多级分组
//1.先根据年龄分组,然后再根据成绩分组
//分析:第一个Collectors.groupingBy() 使用的是(年龄+成绩)两个维度分组,所以使用两个参数 groupingBy()方法
// 第二个Collectors.groupingBy() 就是用成绩分组,使用一个参数 groupingBy() 方法
Map>>> map = studentStream.collect(Collectors.groupingBy(str -> str.getAge(), Collectors.groupingBy(str -> str.getScore(), Collectors.groupingBy((student) -> {
if (student.getScore() >= 60) {
return "及格";
} else {
return "不及格";
}
}))));
map.forEach((key,value)->{
System.out.println("年龄:" + key);
value.forEach((k2,v2)->{
System.out.println("\t" + v2);
});
});
}
}
分组和分区
分组和分区的区别就在:分组可以有多个组。分区只会有两个区( true 和 false)
//1.一个参数
partitioningBy(Predicate predicate)
//2.两个参数(多级分区)
partitioningBy(Predicate predicate, Collector downstream)
/**
* Stream流数据--多级分组操作
* 备注:切记Stream流只能被消费一次,流就失效了
* 如下只是示例代码
* @author liuzebiao
* @Date 2020-1-10 13:37
*/
public class CollectDataToArray{
public static void main(String[] args) {
Stream studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33)
);
//分区操作
Map> partitionMap = studentStream.collect(Collectors.partitioningBy(s -> s.getScore() > 60));
partitionMap.forEach((key,value)->{
System.out.println(key + "---->" + value);
});
}
}
拼接操作
//无参数--等价于 joining("");
joining()
//一个参数
joining(CharSequence delimiter)
//三个参数(前缀+后缀)
joining(CharSequence delimiter, CharSequence prefix,CharSequence suffix)
/**
* Stream流数据--多级分组操作
* 备注:切记Stream流只能被消费一次,流就失效了
* 如下只是示例代码
* @author liuzebiao
* @Date 2020-1-10 13:37
*/
public class CollectDataToArray{
public static void main(String[] args) {
Stream studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33)
);
//拼接操作
//无参:join()
String joinStr1 = studentStream.map(s -> s.getName()).collect(Collectors.joining());
System.out.println(joinStr1);
//一个参数:joining(CharSequence delimiter)
String joinStr2 = studentStream.map(s -> s.getName()).collect(Collectors.joining(","));
System.out.println(joinStr2);
//三个参数:joining(CharSequence delimiter, CharSequence prefix,CharSequence suffix)
String joinStr3 = studentStream.map(s -> s.getName()).collect(Collectors.joining("—","^_^",">_<"));
System.out.println(joinStr3);
}
}