云计算学习-Kubernetes Controller Manager
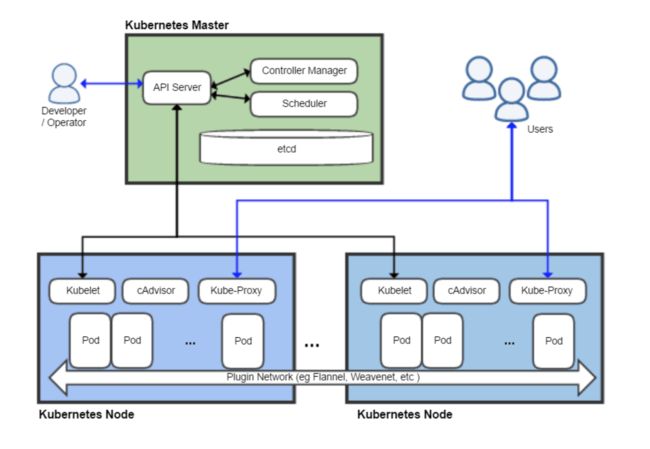
在 Kubernetes Master 节点中,有三个重要组件:ApiServer、ControllerManager、Scheduler,它们一起承担了整个集群的管理工作
实际操作:
路径
/etc/kubernetes/manifests

-rw-r--r-- 1 root root 706 May 17 07:19 command
-rw------- 1 root root 1840 Feb 3 09:39 etcd.yaml
-rw-r--r-- 1 root root 706 May 17 07:16 ion
-rw-r--r-- 1 root root 1919 May 17 07:15 ionversion
-rw------- 1 root root 5082 May 14 22:51 kube-apiserver.yaml
-rw------- 1 root root 3425 May 14 22:51 kube-controller-manager.yaml
-rw------- 1 root root 1608 May 14 22:51 kube-scheduler.yaml
-rw-r--r-- 1 root root 676 May 17 07:19 s
-rw-r--r-- 1 root root 764 May 17 07:16 version
配置文件kube-controller-manager.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-controller-manager
tier: control-plane
name: kube-controller-manager
namespace: kube-system
spec:
containers:
- command:
- kube-controller-manager
- --feature-gates=RotateKubeletServerCertificate=true
- --profiling=false
- --terminated-pod-gc-threshold=10
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
中间还有很多。。省略
- hostPath:
path: /etc/ca-certificates
type: DirectoryOrCreate
name: etc-ca-certificates
- hostPath:
path: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
type: DirectoryOrCreate
name: flexvolume-dir
- hostPath:
path: /etc/kubernetes/pki
type: DirectoryOrCreate
name: k8s-certs
- hostPath:
path: /etc/kubernetes/controller-manager.conf
type: FileOrCreate
name: kubeconfig
- hostPath:
path: /usr/share/ca-certificates
type: DirectoryOrCreate
name: usr-share-ca-certificates
status: {} - hostPath:
path: /etc/ca-certificates
type: DirectoryOrCreate
name: etc-ca-certificates
- hostPath:
path: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
type: DirectoryOrCreate
name: flexvolume-dir
- hostPath:
path: /etc/kubernetes/pki
type: DirectoryOrCreate
name: k8s-certs
- hostPath:
path: /etc/kubernetes/controller-manager.conf
type: FileOrCreate
name: kubeconfig
- hostPath:
path: /usr/share/ca-certificates
type: DirectoryOrCreate
name: usr-share-ca-certificates
status: {}
注意:
kubeadm部署k8s集群,kube-controller-manager和kube-scheduler的监听IP默认为127.0.0.1,如果需要将其改为0.0.0.0用以提供外部访问,可分别修改对应的manifest文件。
kube-controller-manager:/etc/kubernetes/manifests/kube-controller-manager.yaml
kube-scheduler:/etc/kubernetes/manifests/kube-scheduler.yaml
分别修改对应文件中的address项,将127.0.0.1改为0.0.0.0即可
关于认证 参考https://www.cnblogs.com/yangyuliufeng/p/13548915.html
Kubernetes自身并没有用户管理能力,无法像操作Pod一样,通过API的方式创建/删除一个用户实例,也无法在etcd中找到用户对应的存储对象。
在Kubernetes的访问控制流程中,用户模型是通过请求方的访问控制凭证(如kubectl使用的kube-config中的证书、Pod中引入的ServerAccount)产生的
Kubernetes API的请求从发起到其持久化入库的流程如图:

一、认证阶段(Authentication)
判断用户是否为能够访问集群的合法用户。
apiserver目前提供了9种认证机制。每一种认证机制被实例化后会成为认证器(Authenticator),每一个认证器都被封装在http.Handler请求处理函数中,它们接收组件或客户端的请求并认证请求。
假设所有的认证器都被启用,当客户端发送请求到kube-apiserver服务,该请求会进入Authentication Handler函数(处理认证相关的Handler函数)。在Authentication Handler函数中,会遍历已启用的认证器列表,尝试执行每个认证器,当有一个认证器返回true时,则认证成功,否则继续尝试下一个认证器;如果用户是个非法用户,那apiserver会返回一个401的状态码,并终止该请求。
9种认证方式:RequestHeader认证、BasicAuth认证、clientCA认证、TokenAuth认证、ServiceAccountAuth认证、Bootstrap Token认证、OIDC认证、Webhook TokenAuth认证、Anonymous认证
目前用的是RequestHeader认证/ServiceAccountAuth认证/BasicAuth 多种认证,根据用户选择认证方式
参考博客
https://kubernetes.io/docs/reference/access-authn-authz/authentication/#authentication-strategies
kube-controller-manager.yaml认证信息配置如下
containers:
- command:
- kube-controller-manager
- --feature-gates=RotateKubeletServerCertificate=true
- --profiling=false
- --terminated-pod-gc-threshold=10
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf #配置文件在/etc/kubernetes
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=192.168.xx.xx/xx #内网ip
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
- --node-cidr-mask-size=24
- --port=0
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=192.168.xx.xx/24 #内网ip
- --use-service-account-credentials=true
什么是 Controller Manager
根据官方文档的说法:kube-controller-manager 运行控制器,它们是处理集群中常规任务的后台线程。
说白了,Controller Manager 就是集群内部的管理控制中心,由负责不同资源的多个 Controller 构成,共同负责集群内的 Node、Pod 等所有资源的管理,比如当通过 Deployment 创建的某个 Pod 发生异常退出时,RS Controller 便会接受并处理该退出事件,并创建新的 Pod 来维持预期副本数。
几乎每种特定资源都有特定的 Controller 维护管理以保持预期状态,而 Controller Manager 的职责便是把所有的 Controller 聚合起来:
- 提供基础设施降低 Controller 的实现复杂度
- 启动和维持 Controller 的正常运行
可以这么说,Controller 保证集群内的资源保持预期状态,而 Controller Manager 保证了 Controller 保持在预期状态。
Controller 工作流程
在讲解 Controller Manager 怎么为 Controller 提供基础设施和运行环境之前,我们先了解一下 Controller 的工作流程是什么样子的。
从比较高维度的视角看,Controller Manager 主要提供了一个分发事件的能力,而不同的 Controller 只需要注册对应的 Handler 来等待接收和处理事件。

以 Deployment Controller 举例,在 pkg/controller/deployment/deployment_controller.go 的 NewDeploymentController 方法中,便包括了 Event Handler 的注册,对于 Deployment Controller 来说,只需要根据不同的事件实现不同的处理逻辑,便可以实现对相应资源的管理。
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
可以看到,在 Controller Manager 的帮助下,Controller 的逻辑可以做的非常纯粹,只需要实现相应的 EventHandler 即可,那么 Controller Manager 都做了哪些具体的工作呢?
Controller Manager 架构
辅助 Controller Manager 完成事件分发的是 client-go,而其中比较关键的模块便是 informer。
kubernetes 在 github 上提供了一张 client-go 的架构图,从中可以看出,Controller 正是下半部分(CustomController)描述的内容,而 Controller Manager 主要完成的是上半部分。

controller manager 的结构
1. Controller Manager简介
Controller Manager作为集群内部的管理控制中心,负责Pod副本(Replication Controller)、集群内的Node(Node Controller)、资源定额(ResourceQuota Controller)、命名空间(Namespace Controller)、服务账号(ServiceAccount Controller)与Token Controller是与安全相关的两个控制器、服务端点(Endpoint)、的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。

每个Controller通过API Server提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”
Replication controller
controller manager 中的 Replication controller(副本控制器) 和 K8S 中的资源 replication controller 不是同一个东西, 为了区别, 此处将资源类型的 replication controller 用RC 表示, controller manager 中的replication controller 仍然用 replication controller 表示,指代副本控制器
副本控制器的作用即保证集群中一个RC所关联的Pod副本数始终保持预设值
只有当Pod的重启策略是Always的时候(RestartPolicy=Always),副本控制器才会管理该Pod的操作(创建、销毁、重启等)。
RC中的Pod模板就像一个模具,模具制造出来的东西一旦离开模具,它们之间就再没关系了。一旦Pod被创建,无论模板如何变化,也不会影响到已经创建的Pod。
Pod可以通过修改label来脱离RC的管控,该方法可以用于将Pod从集群中迁移,数据修复等调试。
删除一个RC不会影响它所创建的Pod,如果要删除Pod需要将RC的副本数属性设置为0。
不要越过RC创建Pod,因为RC可以实现自动化控制Pod,提高容灾能力
replication controller 的职责
- 确保集群中有且仅有N 个POD的实例, N 是RC 中定义的POD 副本数量
- 通过调整 RC 的 spec.replicas 属性值来扩容或缩容
- 通过改变 RC 中的 POD 模版(主要是镜像), 来实现滚动升级
replication controller 的使用场景
- 重新调度
- 弹性伸缩
- 滚动升级
当 RC 的spec.relicas 设置为0 时, 相关pod 将会被删除
RC会在每个节点上创建Pod,Pod上如果有相应的Images可以直接创建,如果没有,则会拉取这个镜像再进行创建
一.下面直接来看下在RC中的常见操作:参考博客https://blog.csdn.net/chenxijie1985/article/details/112586414
1.编辑配置文件
vim rc.json
内容如下
{
"apiVersion": "v1",
"kind": "ReplicationController",
"metadata": {
"name": "nginx-rc"
},
"spec": {
"replicas": 2,
"selector": {
"name": "myservice"
},
"template": {
"metadata": {
"labels": {
"name": "myservice"
}
},
"spec": {
"containers": [{
"name": "nginx",
"image": "nginx",
"imagePullPolicy": "IfNotPresent",
"ports": [{
"containerPort": 80
}]
}]
}
}
}
}
如遇如下报错 则在微信粘贴下再复制回来(估计过滤了特殊字符 或者编码问题)
error: error parsing rc.json: json: line 1: invalid character 'Â' looking for beginning of object key string

2.创建RC文件
原博客写的是rps 文件名不统一 要统一才对的
kubectl create -f rc.json
replicationcontroller "nginx-rc" created
3. 查询rc
kubectl get rc nginx-rc
要求有2个,已经成功创建的也是两个
实际操作:
root@lxco:/etc/kubernetes/manifests# kubectl get rc nginx-rc
NAME DESIRED CURRENT READY AGE
nginx-rc 2 2 2 84m
4. 查询pod运行情况
kubectl get pod -l name #-l 指定selector的key
可以看到两个创建好的pod,已经在Running状态
实际操作:
root@lxco:/etc/kubernetes/manifests# kubectl get pod -l name
NAME READY STATUS RESTARTS AGE
nginx-rc-m6sd6 1/1 Running 0 84m
nginx-rc-r7cp5 1/1 Running 0 84m
5. 当删除其中一个Pod或者删除全部Pod的时候,RC会自动再次创建Pod,直到满足配置文件中定义的个数
kubectl delete pod nginx-rc-lbb7m
pod "nginx-rc-lbb7m" deleted
kubectl get pod -l name
实际操作:
root@lxco:/etc/kubernetes/manifests# kubectl get pod -l name
NAME READY STATUS RESTARTS AGE
nginx-rc-r7cp5 1/1 Running 0 85m
nginx-rc-wjvhw 1/1 Running 0 30s
root@lxco:/etc/kubernetes/manifests# kubectl delete pod nginx-rc-wjvhw
pod "nginx-rc-wjvhw" deleted
root@lxco:/etc/kubernetes/manifests# kubectl get pod -l name
NAME READY STATUS RESTARTS AGE
nginx-rc-lr9v9 1/1 Running 0 8s
nginx-rc-r7cp5 1/1 Running 0 86m
root@lxco:/etc/kubernetes/manifests#

二.弹性伸缩
弹性伸缩就是在现有环境不能满足业务需求的时候,进行的扩容或缩容
1.缩容Pod
kubectl scale replicationcontroller nginx-rc --replicas=1
提示 replicationcontroller "nginx-rc" scaled
kubectl get pod -l name
kubectl get rc nginx-rc
实际操作:之前为2个nginx,缩容后为1个nginx
root@lxco:/etc/kubernetes/manifests# kubectl scale replicationcontroller nginx-rc --replicas=1
replicationcontroller/nginx-rc scaled
root@lxco:/etc/kubernetes/manifests# kubectl get pod -l name
NAME READY STATUS RESTARTS AGE
nginx-rc-457mq 0/1 Terminating 0 44s
nginx-rc-6xt58 0/1 Terminating 0 44s
nginx-rc-r7cp5 1/1 Running 0 103m
root@lxco:/etc/kubernetes/manifests# kubectl get rc nginx-rc
NAME DESIRED CURRENT READY AGE
nginx-rc 1 1 1 103m
2.扩容Pod
kubectl scale replicationcontroller nginx-rc --replicas=3
提示 replicationcontroller "nginx-rc" scaled
kubectl get pod -l name
kubectl get rc nginx-rc
实际操作:之前为2个nginx,缩容后为1个nginx,扩容后为3个nginx
root@lxco:/etc/kubernetes/manifests# kubectl scale replicationcontroller nginx-rc --replicas=3
replicationcontroller/nginx-rc scaled
root@lxco:/etc/kubernetes/manifests# kubectl get pod -l name
NAME READY STATUS RESTARTS AGE
nginx-rc-2ggj4 1/1 Running 0 4s
nginx-rc-qppg5 1/1 Running 0 4s
nginx-rc-r7cp5 1/1 Running 0 103m
root@lxco:/etc/kubernetes/manifests# kubectl get rc nginx-rc
NAME DESIRED CURRENT READY AGE
nginx-rc 3 3 3 103m
3.判断当前Pod副本是否正确,并修改数量
kubectl scale rc nginx-rc --current-replicas=3 --replicas=1
判断当前副本数是否为3个,如果是,则更改为1个副本
实际操作:
root@lxco:/etc/kubernetes/manifests# kubectl scale rc nginx-rc --current-replicas=3 --replicas=1
replicationcontroller/nginx-rc scaled
root@lxco:/etc/kubernetes/manifests#
root@lxco:/etc/kubernetes/manifests# kubectl get pod -l name
NAME READY STATUS RESTARTS AGE
nginx-rc-r7cp5 1/1 Running 0 109m
root@lxco:/etc/kubernetes/manifests# kubectl get rc nginx-rc
NAME DESIRED CURRENT READY AGE
nginx-rc 1 1 1 109m
root@lxco:/etc/kubernetes/manifests# kubectl scale rc nginx-rc --current-replicas=3 --replicas=5
error: Expected replicas to be 3, was 1
root@lxco:/etc/kubernetes/manifests# kubectl scale rc nginx-rc --current-replicas=1 --replicas=5
replicationcontroller/nginx-rc scaled
root@lxco:/etc/kubernetes/manifests# kubectl get pod -l name
NAME READY STATUS RESTARTS AGE
nginx-rc-mb7ld 1/1 Running 0 6s
nginx-rc-mddzm 1/1 Running 0 6s
nginx-rc-r7cp5 1/1 Running 0 109m
nginx-rc-rtpz5 1/1 Running 0 6s
nginx-rc-xfmpc 1/1 Running 0 6s
root@lxco:/etc/kubernetes/manifests# kubectl get rc nginx-rc
NAME DESIRED CURRENT READY AGE
nginx-rc 5 5 5 109m
查看kubectl的版本
root@lxco:/etc/kubernetes/manifests# kubectl version
Client Version: version.Info{Major:"1", Minor:"18+", GitVersion:"v1.18.14-rc.1-dirty", GitCommit:"7c9cf96ded21080001db72aec6681a21a135b8b2", GitTreeState:"dirty", BuildDate:"2021-01-26T16:22:32Z", GoVersion:"go1.14.12", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.13", GitCommit:"4c00c3c459261e8ff3381c1070ddf798f0131956", GitTreeState:"clean", BuildDate:"2020-12-09T11:09:27Z", GoVersion:"go1.13.15", Compiler:"gc", Platform:"linux/amd64"}
三.滚动升级
在滚动升级/更新方面,有一种更简单的机制,Depolyment
1.创建Depolyment
vim nginx-deployment.yaml #配置文件基本一致,就是改个类型,这里就不赘述了
Node Controller
kubelet 在进程启动时通过API SERVER 注册自身节点信息, 并定时想API SERVER 回报状态信息. API server 将状态信息更新到ETCD 中
Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能。流程如下

1、Controller Manager在启动时如果设置了--cluster-cidr参数,那么为每个没有设置Spec.PodCIDR的Node节点生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,防止不同的节点的CIDR地址发生冲突
2、具体流程见以上流程图
3、逐个读取节点信息,如果节点状态变成非“就绪”状态,则将节点加入待删除队列,否则将节点从该队列删除
ResourceQuota Controller
资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源
支持三个层次的资源配置管理:
1)容器级别:对CPU和Memory进行限制
2)Pod级别:对一个Pod内所有容器的可用资源进行限制
3)Namespace级别:包括
Pod数量
Replication Controller数量
Service数量
ResourceQuota数量
Secret数量
可持有的PV(Persistent Volume)数量

Namespace Controller
用户通过API Server可以创建新的Namespace并保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace信息
如果Namespace被API标记为优雅删除(即设置删除期限,DeletionTimestamp),则将该Namespace状态设置为“Terminating”,并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount、RC、Pod等资源对象
Endpoint Controller
Service、Endpoint、Pod的关系:

Endpoints表示了一个Service对应的所有Pod副本的访问地址,而Endpoints Controller负责生成和维护所有Endpoints对象的控制器。它负责监听Service和对应的Pod副本的变化
如果监测到Service被删除,则删除和该Service同名的Endpoints对象
如果监测到新的Service被创建或修改,则根据该Service信息获得相关的Pod列表,然后创建或更新Service对应的Endpoints对象
如果监测到Pod的事件,则更新它对应的Service的Endpoints对象
kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能
Service Controller
Service Controller是属于kubernetes集群与外部的云平台之间的一个接口控制器。Service Controller监听Service变化,如果是一个LoadBalancer类型的Service,则确保外部的云平台上对该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表