缓存的使用
缓存的使用
缓存的使用,主要是为了提高性能。
redis
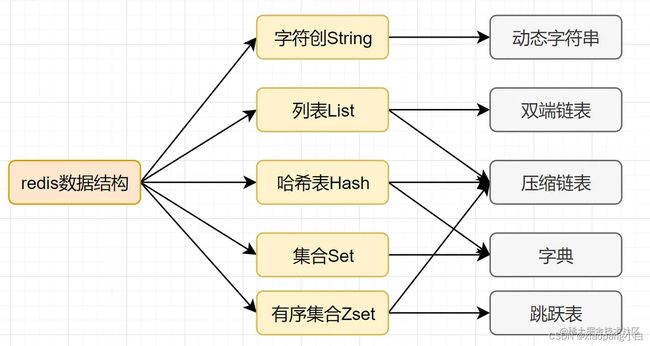
- 基本类型
(1)String
set key value、get key
(2)Hash
hset key field value,hget key field
(3)list
lpush key value,lrange key start end
(4)set
sadd key element,smembers key
(5)zset
zadd key score member,zrank key member - 用途
非关系型数据库,主要用于缓存。也可以作为分布式锁。redis支持事务,持久化,LUA脚本,LRU驱动事件,多种集群方案。 - redis为什么这么快?
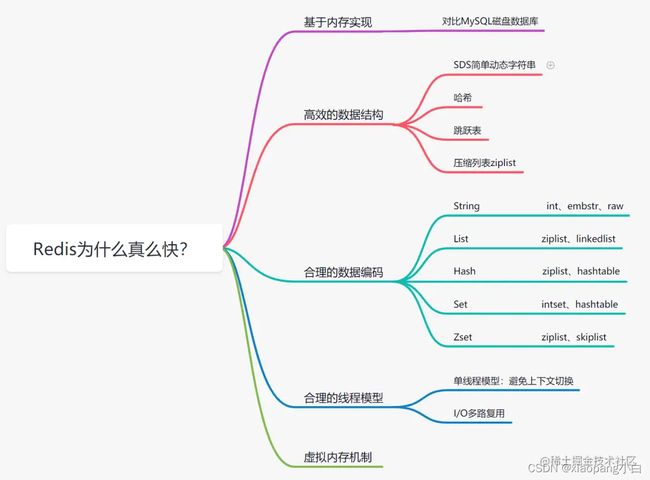
(1)基于内存实现
我们知道内存读写比磁盘快的多,redis基于内存存储的数据库,省去了磁盘I/O的开销。
(2)高效的数据结构
Mysql索引为了提高效率,采用B+树的数据结构。采用合理的数据结构,就是可以让你的应用程序更快。
(3)合理的数据编码
(4)合理的线程模型
I/O多路复用:
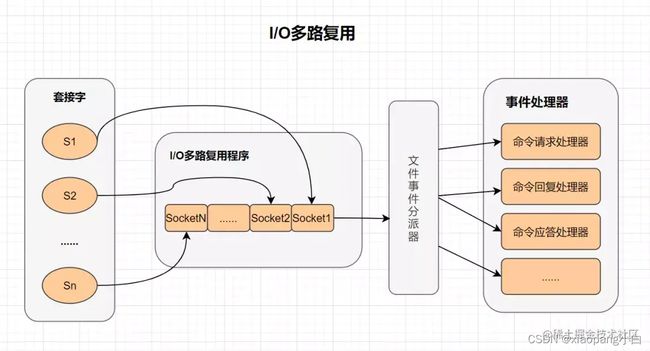
多路I/O多路技术可以让单个线程高效的处理多个连接请求。Redis使用epoll作为I/O多路服务技术的实现。并且,Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为事件,不在网络I/O上浪费过多的时间。
什么是I/O多路复用:
I/O:网络I/O
多路:多个网路连接
复用:复用一个线程
I/O多路复用其实就是一种同步IO模型,它实现了一个线程可以监控多个文件句柄。一旦某个文件句柄准备就绪,就能够通知应用程序进行相应的读写操作。而没有文件句柄就绪时,就会阻塞应用程序,交出CPU。
单线程模型:
Redis是单线程模型的,而单线程避免了CPU不必要的上下文切换和竞争锁的消耗。也正因为是单线程,如果某个命令执行过长(如hgetall命令),会造成阻塞。Redis是面向快速执行场景的数据库。,所以要慎用如smembers和lrange、hgetall等命令。
Redis 6.0 引入了多线程提速,它的执行命令操作内存的仍然是个单线程。
(5)虚拟内存机制
持久化
持久化就是把内存中的数据保存到磁盘上。
Redis提供了RDB和AOF两种不同的数据持久化方式。
ROB
ROB就是一种快照存储方式,具体就是将Redis某一时刻的数据保存到磁盘文件中。默认保存的文件名为dump.rdb。而在Redis服务器启动时,会重新加载dump.rdb文件的数据到内存当中恢复数据。
开启ROB的方式:
- 通过save命令
当客户端向服务器发送save命令请求进行持久化时,服务器会阻塞save命令之后的其他客户端的请求,直到数据同步完成。 - bgsave命令
与save命令不同,bgsave命令是一个异步操作。当客户端发服务发出bgsave命令时,Redis服务器主进程会forks一个子进程来数据同步问题,在将数据保存到rdb文件之后,子进程会退出。 - 服务器配置自动触发
Redis配置文件中的save指定到达触发RDB持久化的条件,比如【多少秒内至少达到多少写操作】就开启RDB数据同步。
配置文件redis.conf指定如下的选项:
# 900s内至少达到一条写命令
save 900 1
# 300s内至少达至10条写命令
save 300 10
# 60s内至少达到10000条写命令
save 60 10000
启动服务器时加载配置文件:
# 启动服务器加载配置文件
redis-server redis.conf
RDB的几个优点:
- 与AOF方式相比,通过rdb文件恢复数据比较快。rdb文件非常紧凑,适合于数据备份。
- 通过RDB进行数据备,由于使用子进程生成,所以对Redis服务器性能影响较小。
RDB的几个缺点:
- 如果服务器宕机的话,采用RDB的方式会造成某个时段内数据的丢失,比如我们设置10分钟同步一次或5分钟达到1000次写入就同步一次,那么如果还没达到触发条件服务器就死机了,那么这个时间段的数据会丢失。
- 使用save命令会造成服务器阻塞,直接数据同步完成才能接收后续请求。
使用bgsave命令在forks子进程时,如果数据量太大,forks的过程也会发生阻塞,另外,forks子进程会耗费内存。
AOF
与RDB存储某个时刻的快照不同,AOF持久化方式会记录客户端对服务器的每一次写操作命令,并将这些写操作以Redis协议追加保存到以后缀为aof文件末尾,在Redis服务器重启时,会加载并运行aof文件的命令,以达到恢复数据的目的。
Redis默认不开启AOF持久化方式。我们可以在配置文件中开启并进行更加详细的配置,如下面的redis.conf文件:
# 开启aof机制
appendonly yes
# aof文件名
appendfilename "appendonly.aof"
# 写入策略,always表示每个写操作都保存到aof文件中,也可以是everysec或no
appendfsync always
# 默认不重写aof文件
no-appendfsync-on-rewrite no
# 保存目录
dir ~/redis/
AOF的写入策略
appendfsync always
# appendfsync everysec
# appendfsync no
- always
客户端每一次写错做都保存到aof文件。这样很安全,但是每次写入都有I/O操作,所以会很慢。 - everysec
默认的写入策略,每秒写入一次aof文件。因此,最多丢失1秒的数据。 - no
redis服务器不负责写入aof文件,而是交由操作系统来处理什么时候写入aof文件。更快,但也是最不安全的选择,不推荐使用。
集群搭建
哨兵模式
redis3.0之前,redis使用哨兵结构,他使用sentinel具来监控 master节点的状态,如果 master 节点异常,则会做主从切换,将一台 slave 作为master。哨兵模式是redis高可用的实现方式之一。
使用一个哨兵或者多个哨兵(sentinel)实例组成的系统,对redis节点进行监控,在主节点出现问题的情况下,能将从节点中的一个升级为主节点,进行故障转移,保证系统的可用性。
哨兵模式的缺点:
- 当master挂掉的时候,sentinel 会选举出来一个 master,选举的时候是没有办法去访问Redis的,会存在访问瞬断的情况;若是在电商网站大促的时候master给挂掉了,几秒钟损失好多订单数据;
- 哨兵模式,对外只有master节点可以写,slave节点只能用于读。尽管Redis单节点最多支持10W的QPS,但是在电商大促的时候,写数据的压力全部在master上。
- Redis的单节点内存不能设置过大,若数据过大在主从同步将会很慢;在节点启动的时候,时间特别长;(从节点上有主节点的所有数据).
sentinel配置
sentinel.conf文件配置参数:
1)sentinel monitor mymaster 192.168.10.199 6379 2
Sentine监听的maste地址,第一个参数是给master起的名字,第二个参数为master IP,第三个为master端口,第四个为当该master挂了的时候,若想将该master判为失效,
在Sentine集群中必须至少2个Sentine同意才行,只要该数量不达标,则就不会发生故障迁移。也就是说只要有2个sentinel认为master下线,就认为该master客观下线,
启动failover并选举产生新的master。通常最后一个参数不能多于启动的sentinel实例数。
这个配置是sentinel需要监控的master/slaver信息,格式为sentinel monitor <mastername> <masterIP> <masterPort> <quorum>
其中<quorum>应该小于集群中slave的个数,当失效的节点数超过了<quorum>,则认为整个体系结构失效
不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移,
并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。
换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。
-------------------------------------------------------------------------
2)sentinel down-after-milliseconds mymaster 30000
表示master被当前sentinel实例认定为失效的间隔时间。
master在多长时间内一直没有给Sentine返回有效信息,则认定该master主观下线。也就是说如果多久没联系上redis-servevr,认为这个redis-server进入到失效(SDOWN)状态。
如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为主观下线(subjectively down,简称 SDOWN )。
不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线
(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。
将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。
-------------------------------------------------------------------------
3)sentinel parallel-syncs mymaster 2
当在执行故障转移时,设置几个slave同时进行切换master,该值越大,则可能就有越多的slave在切换master时不可用,可以将该值设置为1,即一个一个来,这样在某个
slave进行切换master同步数据时,其余的slave还能正常工作,以此保证每次只有一个从服务器处于不能处理命令请求的状态。
parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。
如果从服务器被设置为允许使用过期数据集(参见对 redis.conf 文件中对 slave-serve-stale-data 选项的说明), 那么你可能不希望所有从服务器都在同一时间向新的主服务器发送同步请求,
因为尽管复制过程的绝大部分步骤都不会阻塞从服务器, 但从服务器在载入主服务器发来的 RDB 文件时, 仍然会造成从服务器在一段时间内不能处理命令请求: 如果全部从服务器一起对新的主
服务器进行同步, 那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。
当新master产生时,同时进行"slaveof"到新master并进行"SYNC"的slave个数。
默认为1,建议保持默认值
在salve执行salveof与同步时,将会终止客户端请求。
此值较大,意味着"集群"终止客户端请求的时间总和和较大。
此值较小,意味着"集群"在故障转移期间,多个salve向客户端提供服务时仍然使用旧数据。
-----------------------------------------------------------------------------------------------
4)sentinel can-failover mymaster yes
在sentinel检测到O_DOWN后,是否对这台redis启动failover机制
-----------------------------------------------------------------------------------------------
5)sentinel auth-pass mymaster 20180408
设置sentinel连接的master和slave的密码,这个需要和redis.conf文件中设置的密码一样
-----------------------------------------------------------------------------------------------
6)sentinel failover-timeout mymaster 180000
failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。
执行故障迁移超时时间,即在指定时间内没有大多数的sentinel 反馈master下线,该故障迁移计划则失效
-----------------------------------------------------------------------------------------------
7)sentinel config-epoch mymaster 0
选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步。这个数字越小, 完成故障转移所需的时间就越长。
-----------------------------------------------------------------------------------------------
8)sentinel notification-script mymaster /var/redis/notify.sh
当failover时,可以指定一个"通知"脚本用来告知当前集群的情况。
脚本被允许执行的最大时间为60秒,如果超时,脚本将会被终止(KILL)
-----------------------------------------------------------------------------------------------
9)sentinel leader-epoch mymaster 0
同时一时间最多0个slave可同时更新配置,建议数字不要太大,以免影响正常对外提供服务。
一主二从三sentinel:
192.168.1.1 redis-master redis(6379)、sentinel(26379)
192.168.1.2 redis-slave01 redis(6379)、sentinel(26379)
192.168.1.3 redis-slave02 redis(6379)、sentinel(26379)
- redis一键安装(三个节点上都要进行操作)
- 编辑redis-master主节点的redis.conf文件
[root@redis-master src]# mkdir -p /usr/local/redis/data/redis
[root@redis-master src]# cp /usr/local/redis/etc/redis.conf /usr/local/redis/etc/redis.conf.bak
[root@redis-master src]# vim /usr/local/redis/etc/redis.conf
bind 0.0.0.0
daemonize yes #指定配置文件启动
pidfile "/usr/local/redis/var/redis-server.pid"
port 6379
tcp-backlog 128
timeout 0
tcp-keepalive 0
loglevel notice
logfile "/usr/local/redis/var/redis-server.log"
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir "/usr/local/redis/data/redis"
#masterauth "20180408" #master设置密码保护,即slave连接master时的密码
#requirepass "20180408" #设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendonly yes #打开aof持久化
appendfilename "appendonly.aof"
appendfsync everysec # 每秒一次aof写
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
- 配置redis从节点中的redis.conf文件
[root@redis-slave01 src]# mkdir -p /usr/local/redis/data/redis
[root@redis-slave01 src]# cp /usr/local/redis/etc/redis.conf /usr/local/redis/etc/redis.conf.bak
[root@redis-slave01 src]# vim /usr/local/redis/etc/redis.conf
bind 0.0.0.0
daemonize yes #指定配置文件启动
pidfile "/usr/local/redis/var/redis-server.pid"
port 6379
tcp-backlog 128
timeout 0
tcp-keepalive 0
loglevel notice
logfile "/usr/local/redis/var/redis-server.log"
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir "/usr/local/redis/data/redis"
#masterauth "20180408"
#requirepass "20180408"
slaveof 192.168.1.1 6379 #相对主redis配置,多添加了此行
slave-serve-stale-data yes
slave-read-only yes #从节点只读,不能写入
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
- 配置sentinel.conf
[root@redis-master src]# mkdir -p /usr/local/redis/data/sentinel
[root@redis-master src]# vim /usr/local/redis/etc/sentinel.conf
port 26379
pidfile "/usr/local/redis/var/redis-sentinel.pid"
dir "/usr/local/redis/data/sentinel"
daemonize yes
protected-mode no
logfile "/usr/local/redis/var/redis-sentinel.log"
sentinel monitor redisMaster 192.168.1.1 6379 2
sentinel down-after-milliseconds redisMaster 10000
sentinel parallel-syncs redisMaster 1
sentinel failover-timeout redisMaster 60000
- 启动redis和sentinel
redis集群
redis集群是有多个主从节点群组成的布式服务集群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。
集群优点
- 可以由多个master,可以减小访问瞬断问题的影响;
- Redis集群有多个master,可以提供更高的并发量;
- Redis集群可以分片存储,这样就可以存储更多的数据;
Redis集群的搭建
Redis的集群搭建最少需要3个master节点,我们这里搭建3个master,每个下面挂一个slave节点,总共6个Redis节点;(3台机器,每台机器一主一从)
环境如下:
第1台机器: 192.168.1.1 8001端口 8002端口
第2台机器: 192.168.1.2 8001端口 8002端口
第3台机器: 192.168.1.3 8001端口 8002端口
- 创建文件夹
mkdir -p /usr1/redis/redis-cluster/8001 /usr1/redis/redis-cluster/8002
- 将redis安装目录下的 redis.conf 文件分别拷贝到8001目录下
cp /usr1/redis-5.0.3/redis.conf /usr1/redis/redis-cluster/8001
- 修改redis.conf中内容
(1)cluster-enabled yes 开启集群
(2)修改端口号 port 8001
port 8001 daemonize yes #指定配置文件启动
pidfile "/var/run/redis\_8001.pid" #指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据 dir /usr1/redis/redis-cluster/8001/ #启动集群模式
cluster\-enabled yes
#集群节点信息文件,这里800x最好和port对应上
cluster\-config-file nodes-8001.conf
# 节点离线的超时时间
cluster\-node-timeout 5000 #去掉bind绑定访问ip信息
#bind 127.0.0.1 #关闭保护模式
protected\-mode no
#启动AOF文件
appendonly yes
#如果要设置密码需要增加如下配置:
#设置redis访问密码
requirepass redis\-pw
#设置集群节点间访问密码,跟上面一致
masterauth redis\-pw
- 把配置文件从8001移动到8002文件夹下,并修改配置中的8001为8002
cp /usr1/redis/redis-cluster/8001/redis.conf /usr1/redis/redis-cluster/8002 cd /usr1/redis/redis-cluster/8002/ vim redis.conf
#批量修改字符串
:%s/8001/8002/g
- 将本机(192.168.1.1)机器上的文件拷贝到另外两台机器上
scp /usr1/redis/redis-cluster/8001/redis.conf root@192.168.1.2:/usr1/redis/redis-cluster/8001/
scp /usr1/redis/redis-cluster/8002/redis.conf root@192.168.1.2:/usr1/redis/redis-cluster/8002/
scp /usr1/redis/redis-cluster/8001/redis.conf root@192.168.1.3:/usr1/redis/redis-cluster/8001/
scp /usr1/redis/redis-cluster/8002/redis.conf root@192.168.1.3:/usr1/redis/redis-cluster/8002/
- 分别启动这6个redis实例,然后检查是否启动成功
/usr1/redis/redis-5.0.3/src/redis-server /usr1/redis/redis-cluster/8001/redis.conf /usr1/redis/redis-5.0.3/src/redis-server /usr1/redis/redis-cluster/8002/redis.conf
ps -ef | grep redis

- 使用 redis-cli 创建整个 redis 集群(redis5.0版本之前使用的
ruby脚本redis-trib.rb)
/usr1/redis/redis-5.0.3/src/redis-cli -a redis-pw --cluster create --cluster-replicas 1 192.168.1.1:8001 192.168.1.1:8002 192.168.1.2:8001 192.168.1.2:8002 192.168.1.3:8001 192.168.1.3:8002
-a :密码;
–cluster-replicas 1:表示1个master下挂1个slave; --cluster-replicas 2:表示1个master下挂2个slave。
查看帮助命令: src/redis‐cli --cluster help:
create:创建一个集群环境host1:port1 ... hostN:portN
call:可以执行redis命令
add\-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
del\-node:移除一个节点
reshard:重新分片
check:检查集群状态
- 验证集群
redis如何解决缓存三大问题
-
缓存穿透
(1)缓存空值或缺省值。当查询的数据在缓存和数据库都没有数据时,可以在缓存中缓存一个空值或缺省值,防止不存在数据访问到了数据库层。当后续新增了该数据时,注意需要将该空值缓存给移除掉。
(2)使用布隆过滤器。利用布隆过滤器的特点可以校验数据是否存在,每新增一个数据时,在布隆过滤器做个标记。这样当缓存缺失时,就可以先通过布隆过滤器检测到该数据不存在,就不用再去数据库中访问了。布隆过滤器可以使用Redis实现。
(3)前端拦截恶意请求。当有恶意请求访问不存在的数据时,在前端针对请求的参数进行合法性检测,过滤请求参数不合理、参数非法值、字段不存在的恶意请求。不让它们访问数据库,这样就不会产生缓存穿透的问题了。 -
缓存雪崩
搭建redis集群 -
热点数据失效
对于热点数据设置不同的失效时间。
Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp。
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数。
- Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式:

- 哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k:
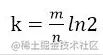
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考Bloom Filters - the math,Bloom_filter-wikipedia
要使用Bloom Filter,首先引用guava
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
- 测试验证
(1)往过滤器中放一百万个数,然后去验证这一百万个数是否能通过过滤器
(2)另外找一万个数,去检验漏网之鱼的数量
/**
* 测试布隆过滤器(可用于redis缓存穿透)
*
* @author 敖丙
*/
public class TestBloomFilter {
private static int total = 1000000;
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
// private static BloomFilter bf = BloomFilter.create(Funnels.integerFunnel(), total, 0.001);
public static void main(String[] args) {
// 初始化1000000条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put(i);
}
// 匹配已在过滤器中的值,是否有匹配不上的
for (int i = 0; i < total; i++) {
if (!bf.mightContain(i)) {
System.out.println("有坏人逃脱了~~~");
}
}
// 匹配不在过滤器中的10000个值,有多少匹配出来
int count = 0;
for (int i = total; i < total + 10000; i++) {
if (bf.mightContain(i)) {
count++;
}
}
System.out.println("误伤的数量:" + count);
}
}
运行结果:
![]()
Bloom Filter 源码
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) {
return create(funnel, (long) expectedInsertions);
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
......
}
BloomFilter一共四个create方法,不过最终都是走向第四个。看一下每个参数的含义:
funnel:数据类型(一般是调用Funnels工具类中的)
expectedInsertions:期望插入的值的个数
fpp 错误率(默认值为0.03)
strategy 哈希算法(我也不懂啥意思)Bloom Filter的应用
常见的几个应用场景:
-
cerberus在收集监控数据的时候, 有的系统的监控项量会很大, 需要检查一个监控项的名字是否已经被记录到db过了, 如果没有的话就需要写入db.
-
爬虫过滤已抓到的url就不再抓,可用bloom filter过滤
-
垃圾邮件过滤。如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
guava
guava作为goole公司开源本地缓存框架,受关注度还是很高的。
工具类就是封装平常用的方法,不需要你重复造轮子,节省开发人员时间,提高工作效率。谷歌作为大公司,当然会从日常的工作中提取中很多高效率的方法出来。所以就诞生了guava。
guava的核心类库:
(1)集合 [collections]
(2)缓存 [caching]
(3)原生类型支持 [primitives support]
(4)并发库 [concurrency libraries]
(5)通用注解 [common annotations]
(6)字符串处理 [string processing]
(7)I/O 等等。
guava使用
引入guava依赖。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>
- 集合的创建
// 普通Collection的创建
List<String> list = Lists.newArrayList();
Set<String> set = Sets.newHashSet();
Map<String, String> map = Maps.newHashMap();
// 不变Collection的创建
ImmutableList<String> iList = ImmutableList.of("a", "b", "c");
ImmutableSet<String> iSet = ImmutableSet.of("e1", "e2");
ImmutableMap<String, String> iMap = ImmutableMap.of("k1", "v1", "k2", "v2");
- 字符串连接器Joiner
StringBuilder stringBuilder = new StringBuilder("hello");
// 字符串连接器,以|为分隔符,同时去掉null元素
Joiner joiner1 = Joiner.on("|").skipNulls();
// 构成一个字符串foo|bar|baz并添加到stringBuilder
stringBuilder = joiner1.appendTo(stringBuilder, "foo", "bar", null, "baz");
System.out.println(stringBuilder); // hellofoo|bar|baz
- 将集合转换为特定规则的字符串
Joiner
//1 将list转换为特定规则的字符串是这样写的:
//use java
List<String> list = new ArrayList<String>();
list.add("aa");
list.add("bb");
list.add("cc");
String str = "";
for(int i=0; i<list.size(); i++){
str = str + "-" +list.get(i);
}
//str 为-aa-bb-cc
//2把map集合转换为特定规则的字符串
//use guava
List<String> list = new ArrayList<String>();
list.add("aa");
list.add("bb");
list.add("cc");
String result = Joiner.on("-").join(list);
//result为 aa-bb-cc
Map<String, Integer> map = Maps.newHashMap();
map.put("xiaoming", 12);
map.put("xiaohong",13);
String result = Joiner.on(",").withKeyValueSeparator("=").join(map);
// result为 xiaoming=12,xiaohong=13
- 将String转换为特定的集合
Splitter
//use java
List<String> list = new ArrayList<String>();
String a = "1-2-3-4-5-6";
String[] strs = a.split("-");
for(int i=0; i<strs.length; i++){
list.add(strs[i]);
}
//use guava
String str = "1-2-3-4-5-6";
List<String> list = Splitter.on("-").splitToList(str);
//list为 [1, 2, 3, 4, 5, 6]
//guava去除空格
String str = "1-2-3-4- 5- 6 ";
List<String> list = Splitter.on("-").omitEmptyStrings().trimResults().splitToList(str);
System.out.println(list);
//String转换为Map
String str = "xiaoming=11,xiaohong=23";
Map<String,String> map = Splitter.on(",").withKeyValueSeparator("=").split(str);
- 集合的过滤
//按照条件过滤
ImmutableList<String> names = ImmutableList.of("begin", "code", "Guava", "Java");
Iterable<String> fitered = Iterables.filter(names, Predicates.or(Predicates.equalTo("Guava"), Predicates.equalTo("Java")));
System.out.println(fitered);
// [Guava, Java]
//自定义过滤条件 使用自定义回调方法对Map的每个Value进行操作
ImmutableMap<String, Integer> m = ImmutableMap.of("begin", 12, "code", 15);
// Function F表示apply()方法input的类型,T表示apply()方法返回类型
Map<String, Integer> m2 = Maps.transformValues(m, input -> {
if(input > 12){
return input;
}else{
return input + 1;
}
});
System.out.println(m2);
//set的交集, 并集, 差集
HashSet setA = newHashSet(1, 2, 3, 4, 5);
HashSet setB = newHashSet(4, 5, 6, 7, 8);
SetView union = Sets.union(setA, setB);
System.out.println("union:");
for (Integer integer : union)
System.out.println(integer); //union 并集:12345867
SetView difference = Sets.difference(setA, setB);
System.out.println("difference:");
for (Integer integer : difference)
System.out.println(integer); //difference 差集:123
SetView intersection = Sets.intersection(setA, setB);
System.out.println("intersection:");
for (Integer integer : intersection)
System.out.println(integer); //intersection 交集:45
//map的交集,并集,差集
HashMap<String, Integer> mapA = Maps.newHashMap();
mapA.put("a", 1);mapA.put("b", 2);mapA.put("c", 3);
HashMap<String, Integer> mapB = Maps.newHashMap();
mapB.put("b", 20);mapB.put("c", 3);mapB.put("d", 4);
MapDifference differenceMap = Maps.difference(mapA, mapB);
differenceMap.areEqual();
Map entriesDiffering = differenceMap.entriesDiffering();
Map entriesOnlyLeft = differenceMap.entriesOnlyOnLeft();
Map entriesOnlyRight = differenceMap.entriesOnlyOnRight();
Map entriesInCommon = differenceMap.entriesInCommon();
System.out.println(entriesDiffering); // {b=(2, 20)}
System.out.println(entriesOnlyLeft); // {a=1}
System.out.println(entriesOnlyRight); // {d=4}
System.out.println(entriesInCommon); // {c=3}
- 文件操作
以前我们写文件读取的时候需要定义缓冲区,各种条件判断。现在,我们只需要使用好guava的API就能使代码变的简洁,并且不用担心逻辑错误背锅。
File file = new File("test.txt");
List<String> list = null;
try {
list = Files.readLines(file, Charsets.UTF_8);
} catch (Exception e) {
}
Files.copy(from,to); //复制文件
Files.deleteDirectoryContents(File directory); //删除文件夹下的内容(包括文件与子文件夹)
Files.deleteRecursively(File file); //删除文件或者文件夹
Files.move(File from, File to); //移动文件
URL url = Resources.getResource("abc.xml"); //获取classpath根下的abc.xml文件url
- guava缓存
guava缓存创建分为两种,一种是CacheLoader,另一种则是callback方式。
CacheLoader:
LoadingCache<String,String> cahceBuilder=CacheBuilder
.newBuilder()
.build(new CacheLoader<String, String>(){
@Override
public String load(String key) throws Exception {
String strProValue="hello "+key+"!";
return strProValue;
}
});
System.out.println(cahceBuilder.apply("begincode")); //hello begincode!
System.out.println(cahceBuilder.get("begincode")); //hello begincode!
System.out.println(cahceBuilder.get("wen")); //hello wen!
System.out.println(cahceBuilder.apply("wen")); //hello wen!
System.out.println(cahceBuilder.apply("da"));//hello da!
cahceBuilder.put("begin", "code");
System.out.println(cahceBuilder.get("begin")); //code
缓存问题
缓存穿透
大多数互联网应用中,缓存的使用方式如下图所示:
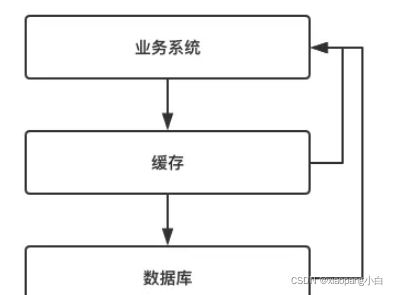
- 当业务系统发起某一个查询请求时,首先判断缓存中是否有改数据。
- 如果缓存中存在,则直接返回数据。
- 如果缓存中不存在,则再查询数据库,保存到缓存,返回数据给客户端。
缓存穿透:
当业务系统发起查询时,按照上述流程,首先会前往缓存中查询,由于缓存中不存在,然后前往数据库中查询。由于改数据压根不存在,因此数据库也返回空。这就是缓存穿透。
综上所述,大量访问业务系统中压根不不存在的数据,就成为缓存穿透。
缓存穿透的危害。
(1)恶意攻击,故意营造大量不存在的数据请求我们服务,由于缓存中并不存在这些记录,这些请求就直接落到了数据库中,从而可能导致数据库崩溃。
(2)代码逻辑错误,这是程序员的锅,开发中一定要避免。
解决方案。
(1)缓存空数据。
如果查询后返回的是空,我们也把查询条件作为key缓存起来,结果存为null。下次访问直接返回null。
(2)BloomFilter(布隆过滤器)
布隆过滤器简单来说就是申请一个二进制数组,通过固定几个hash函数运算,取出来每个hash运算结果对应数组下标结果。如果都为1,表示改结果可能存在记录。如果存在一个为0,那表示记录一定不存在。
它是把目前数据库中存储的所有key,通过几个hash运算,将结果保存到二进制数据中。然后查询的时候,请求参数通过hash运算,判断结果是否存在。过滤掉数据不存在的请求访问数据库。
区别:
- 如果是恶意攻击,往往key是不一样的,第一种方案就不行了。因为就算缓存key,因为每个key都不一样,达不到保护数据库的目的。这种情况应该使用第二种方案。使用bloomFilter(布隆过滤器)。
- 如果空对象的key不多的场景,key重复率高的场景,应该选择第一种方案。
缓存雪崩
缓存扮演一个保护数据库的角色,它帮数据库抵挡大量的查询请求。从而避免数据库收到伤害。
但是,如果某种情况下,导致缓存发生了跌机,那么原本被缓存抵挡的海量请求就会向疯狗一样涌向数据库。这就是缓存雪崩。
解决方案。
(1)使用缓存集群,保证高可用
通过缓存集群,使缓存架构高可用,保证缓存不会同时跌机。
(2)使用Hystrix
Hystrix是一款开源的"防雪崩工具",它通过熔断,降级,限流三个手段来降低雪崩发生后的损失。
Hystrix就是一个java类库,它采用命令模式,每一项服务处理请求都有各自的处理器。所有的请求都要经过各自的处理器。处理器会记录当前服务的请求失败率。一旦返现当前服务的请求失败率达到预设的值,Hystrix将会拒绝随后改服务的所有请求,直接返回一个预设的结果。这就是熔断。
当经过一段时间之后,Hystrix会放行改服务的一部分请求,再次统计它的请求失败率。如果此时请求失败率符合预设的值,则完全打开限流开关。如果请求失败率仍然很高,那么继续拒绝改服务的所有请求。这就是限流。
Hystrix预设的拒绝请求后的结果,就是降级。
热点数据集中失效
我们一般会给缓存设定一个失效时间,过了失效时间后,改缓存会被清掉。但是对于一些热点数据而言,一旦过了有效时间,将会有大量请求落在数据库。
解决方案。
(1)互斥锁
我们可以使用缓存自带的锁机制,当第一个数据库查询请求发起后,就将缓存中的数据上锁。此时到达缓存的请求将无法查询该字段,从而被阻塞等待。当第一个请求完成数据库查询,并将数据更新值缓存后,释放锁。此时其他请求将可以从缓存中查询到该数据。
当某一个热点数据失效后,只有第一个数据库查询请求发往数据库,其余所有的查询请求均被阻塞,从而保护了数据库。但是,由于采用了互斥锁,其他请求将会被阻塞等待,此时系统的吞吐量将会下降。这需要结合实际的业务考虑是否允许这么做。
互斥锁可以保证某一个热点数据失效导致数据库崩溃的问题,而在实际业务中,往往会存在一批热点数据同时失效的场景。
(1)设置不同的失效时间
当我们向缓存中存储这些数据的时候,可以将他们的缓存失效时间错开。这样能够避免同时失效。如:在一个基础时间上加/减一个随机数,从而将这些缓存的失效时间错开。
java实现缓存淘汰算法
java.util.LinkedHashMap已经实现了其中的99%,因此直接基于LinkedHashMap实现LRUCache非常简单。
- LinkedHashMap 构造方法提供了
accessOrder选项,开启后get方法会有额外操作保证链表顺序按访问顺序逆序排列。 - 底层结构使用双向链表,查询可以使用HashMap的特点。
- 覆盖父类HashMap的newNode方法和newTreeNode方法,这两个方法在HashMap中只是创建Node用的,而在LinkedHashMap中不但创建Node,还将Node放在链表末尾。
- 父类HashMap提供了3个void的Hook方法,方法没做任何事:
(1)afterNodeRemoval 父类在remove一个集合中存在的元素后调用
(2)afterNodeInsertion 父类在put、compute、merge后调用
(3)afterNodeAccess 父类在replace、compute、merge等替换值后会调用,LinkedHashMap在get中开启accessOrder时调用,究其根本是在对数据有操作时会调用。
(4)LinkedHashMap本质上还是复用HashMap的绝大部分功能,包括底层的Node - 但是LinkedHashMap实现了父类HashMap的3个Hook方法:
(1)afterNodeRemoval 实现链表的删除操作
(2)afterNodeInsertion 并没有实现链表的插入操作,但新添加了一个Hook方法
(3)boolean removeEldestEntry,当这个Hook方法返回true时,删除链表头的节点
afterNodeAccess 如前所述,开启accessOrder后会将被操作的节点放在链表末尾,保证链表顺序按访问顺序逆序排列. - LinkedHashMap还覆盖了父类的3个方法:
(1)newNode 在创建一个Node的同时,将Node添加到链表末尾
(2)newTreeNode 创建TreeNode的同时,将Node添加到链表末尾
(3)get 完成get功能的同时,如果accessOrder开启,会调用afterNodeAccess将Node移动到链表末尾。覆盖newNode和newTreeNode方法后,在put方法中调用的newNode和newTreeNode方法也就连带实现了链表的插入操作
LinkedHashMap为什么能够轻松实现LRUCache
- 继承父类HashMap,拥有HashMap的功能,因此在查找一个节点时时间复杂度为O(1),再加上链表是双向,做链表任意节点的删除工作就非常简单。
- 通过HashMap提供的3个Hook方法并覆盖了2个创建Node的方法,实现了自身链表的添加、删除工作,保证在不影响原本Array功能的前提下,正确完成自身的链表构建;这个过程实际上均是通过Hook方式增强原有功能的,因为原本的HashMap中创建节点其实也是使用的Hook方法
- 提供属性accessOrder并实现了afterNodeAccess方法,因此能够根据访问或操作顺序将最近使用或最近插入的数据放在链表尾,越久没被使用的数据就越靠近链表头,实现了整个链表按照LRU的要求排序
- 提供了一个Hook方法boolean removeEldestEntry,这个方法返回true时将会删除表头节点,即LRU中应当淘汰的节点,但是这个方法在LinkedHashMap中的实现永远返回false
代码实现
package com.example.demo.utils;
import java.util.LinkedHashMap;
import java.util.Map;
public class LruCache<K,V> extends LinkedHashMap<K,V> {
private final int MAX_CACHE_SIZE;
public LruCache(int cacheSize) {
// 使用构造方法 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
// initialCapacity、loadFactor都不重要
// accessOrder要设置为true,按访问排序
super((int) (Math.ceil(cacheSize / 0.75) + 1),0.75f,true);
MAX_CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
// 超过阈值时返回true,进行LRU淘汰
return size() > MAX_CACHE_SIZE;
}
}
java缓存淘汰算法原作者地址
布隆过滤器使用原作者地址
guava使用原作者