哈希结构(详解)
目录
哈希表
哈希表原理
散列函数
哈希冲突和处理的办法
哈希集合
哈希集合的实现
哈希映射
哈希映射的基本操作
哈希映射的实现
哈希表
散列表(Hash table,也叫哈希表),是根据关键码值(Key)而直接进行访问的数据结构
也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度
这个映射函数叫做哈希函数,存放记录的数组叫做哈希表。
通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表,在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字
哈希表原理
h(key) = key % size若关键字为n,则其值存放在f(n)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数,按这个思想建立的表为散列表
对不同的关键字可能得到同一散列地址,即n1 ≠ n2,而f(n1)==f(n2),这种现象称为冲突。具有相同函数值的关键字对该散列函数来说称做同义词
在设计哈希表的时候,最需要注意两个基本因素:一个是散列函数的编写,一个是键冲突解决算法
散列函数
一般的线性表,树中,记录在结构中的相对位置是随机的,即和记录的关键字之间不存在确定的关系,因此,在结构中查找记录时需进行一系列和关键字的比较。这一类查找方法建立在“比较“的基础上,查找的效率依赖于查找过程中所进行的比较次数。 理想的情况是能直接找到需要的记录,因此必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应。
哈希表中元素的位置是由哈希函数确定的。将数据元素的关键字n作为自变量,通过一定的函数关系计算出的值,即为该元素的存储地址。在这推荐使用除留余数法 hash(k) = k mod p
- 直接定址法
- 数字分析法
- 平方取中法
- 折叠法
- 随机数法
- 除留余数数法
哈希冲突和处理的办法
在哈希表中,不同的关键字值对应到同一个存储位置的现象。即关键字n1 ≠ n2,但f(n1)= f(n2)。均匀的哈希函数可以减少冲突,但不能避免冲突。发生冲突后,必须解决;也即必须寻找下一个可用地址。
-
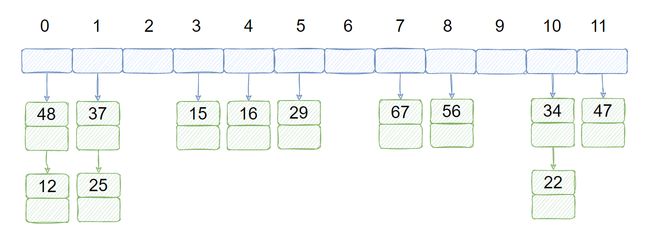
单独链表法(最常用的解决哈希冲突的算法)
将具有同一散列地址的记录存储在一条线性链表中。例,除留余数法中,设关键字为 (18,14,01,68,27,55,79),除数为13。散列地址为 (5,1,1,3,1,3,1),
-
开放定址法 hash(key)+n mod len(table)
- n为冲突的次数,线性探测
- n值为冲突次数的平方,平方探测
-
双散列
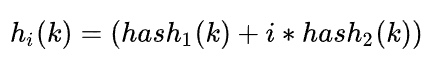
-
再散列
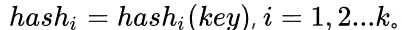
-
建立一个公共溢出区
哈希集合
def add(self, key: int) -> None: # 向哈希集合插入值key
def remove(self, key: int) -> None: # 将给定值key从哈希集合中删除
def contains(self, key: int) -> bool: #返回哈希集合中是否存在这个值key
哈希集合的实现
class MyHashSet:
def __init__(self):
# 由于我们使用整数除法作为哈希函数,为了尽可能避免冲突,应当将长度取为一个质数
self.len = 997
self.list_ = [list() for _ in range(self.len)]
def add(self, key: int) -> None:
hash_addr = key % self.len
if key not in self.list_[hash_addr]:
self.list_[hash_addr].append(key)
def remove(self, key: int) -> None:
#求地址 散列函数都是一样的
hash_addr = key % self.len
if key in self.list_[hash_addr]:
self.list_[hash_addr].remove(key)
def contains(self, key: int) -> bool:
hash_addr = key % self.len
if key in self.list_[hash_addr]:
return True
return False
# Your MyHashSet object will be instantiated and called as such
# obj = MyHashSet()
# obj.add(key)
# obj.remove(key)
# param_3 = obj.contains(key)
定义一个名为`MyHashSet`的类,实现了基本的哈希集合操作。
**构造函数`__init__(self)`**:
- 初始化了一个长度为997的列表`self.list_`,列表中的每个元素都是一个空列表,用于存储哈希集合中的元素。
**`add(self, key: int) -> None`方法**:
- 接收一个整数`key`作为输入。
- 计算`key`的哈希地址`hash_addr`,使用整数除法取余数来实现哈希函数。
- 如果`key`不在`self.list_[hash_addr]`中,则将`key`添加到`self.list_[hash_addr]`中。
**`remove(self, key: int) -> None`方法**:
- 接收一个整数`key`作为输入。
- 计算`key`的哈希地址`hash_addr`。
- 如果`key`在`self.list_[hash_addr]`中,则从`self.list_[hash_addr]`中移除`key`。
**`contains(self, key: int) -> bool`方法**:
- 接收一个整数`key`作为输入。
- 计算`key`的哈希地址`hash_addr`。
- 如果`key`在`self.list_[hash_addr]`中,则返回`True`,否则返回`False`。
总结:该类通过使用哈希函数将元素存储在列表中的特定位置来实现哈希集合的基本操作。使用哈希地址来查找、添加和移除元素,以提高操作的效率。
哈希映射
hash_map被称为映射。该容器中只能存放不重复的对象。 存放的是键值对,我们可以通过键(key)来找到对应的值(value)
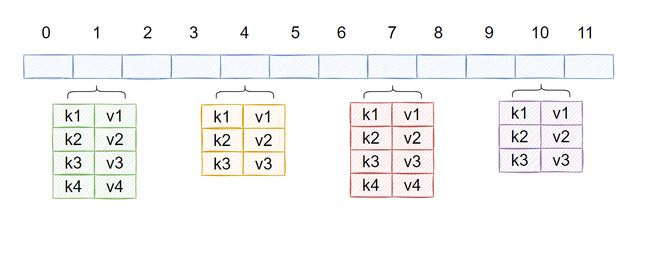
哈希映射的基本操作
def __init__(self) -> None: # 用空映射初始化对象
def put(key:int, value:int) -> None: # 向 HashMap 插入一个键值对 (key, value) 。如果 key 已经存在于映射中,则更新其对应的值 value 。
def get(key:int) -> None: # 返回特定的 key 所映射的 value ;如果映射中不包含 key 的映射,返回 -1 。
def remove(key) -> None: # 如果映射中存在 key 的映射,则移除 key 和它所对应的 value
哈希映射的实现
class MyHashMap:
def __init__(self):
self.len = 997
# 存放的键值对,第一个列表放key 第二个列表放value
self.list_ = [[[],[]] for _ in range(self.len)]
def put(self, key: int, value: int) -> None:
hash_addr = key % self.len
#如果key已经存在与映射中,更新value
for i, v in enumerate(self.list_[hash_addr][0]):
if v == key:
self.list_[hash_addr][1][i] = value
return
#如果没有
self.list_[hash_addr][0].append(key)
self.list_[hash_addr][1].append(value)
def get(self, key: int) -> int:
hash_addr = key % self.len
# 如果找到返回当前value
for i, v in enumerate(self.list_[hash_addr][0]):
if v == key:
return self.list_[hash_addr][1][i]
# 如果没有 返回-1
return -1
def remove(self, key: int) -> None:
hash_addr = key % self.len
for i, v in enumerate(self.list_[hash_addr][0]):
if v == key:
self.list_[hash_addr][0].pop(i)
self.list_[hash_addr][1].pop(i)
# Your MyHashMap object will be instantiated and called as such:
# obj = MyHashMap()
# obj.put(key,value)
# param_2 = obj.get(key)
# obj.remove(key)
定义一个名为`MyHashMap`的类,实现了基本的哈希映射操作。
**构造函数`__init__(self)`**:
- 初始化了一个长度为997的列表`self.list_`,列表中的每个元素都是一个包含两个空列表的列表。
- 第一个子列表用于存储键(key),第二个子列表用于存储对应的值(value)。
**`put(self, key: int, value: int) -> None`方法**:
- 接收一个整数`key`和一个整数`value`作为输入。
- 计算`key`的哈希地址`hash_addr`,使用整数除法取余数来实现哈希函数。
- 如果`key`已经存在于映射中,则更新对应的`value`。
- 如果`key`不存在于映射中,则将`key`和对应的`value`添加到`self.list_[hash_addr]`中的两个子列表中。
**`get(self, key: int) -> int`方法**:
- 接收一个整数`key`作为输入。
- 计算`key`的哈希地址`hash_addr`。
- 遍历`self.list_[hash_addr]`中的键列表,找到与`key`相等的键,并返回对应的值。
- 如果找不到相等的键,则返回-1。
**`remove(self, key: int) -> None`方法**:
- 接收一个整数`key`作为输入。
- 计算`key`的哈希地址`hash_addr`。
- 遍历`self.list_[hash_addr]`中的键列表,找到与`key`相等的键,并从键列表和值列表中删除对应的键值对。
总结:该类使用哈希函数将键值对存储在列表中的特定位置,通过哈希地址进行快速查找和操作。当插入或获取键值对时,通过计算哈希地址来定位存储位置,以提高操作的效率。如果键已经存在于映射中,则更新对应的值;如果键不存在,则将键值对添加到映射中。可以通过键获取对应的值,并且可以删除指定的键值对。