【Canal】从原理、配置出发,从0到1完成Canal搭建
文章目录
-
- 简介
- 工作原理
-
- MySQL主备复制原理
- canal 工作原理
- Canal架构
- Canal-HA机制
- 应用场景
-
- 同步缓存 Redis /全文搜索 ES
- 下发任务
- 数据异构
- MySQL 配置
-
- 开启 binlog
- 扩展
-
- statement
- row
- mixed
- 配置权限
- Canal 配置
-
- 配置
- 启动
-
- 报错
- 解决
- 实战
-
- 引入依赖
- 代码样例
- 测试
前几天在网上冲浪的时候发现了一个比较成熟的开源中间件——Canal。在了解了它的工作原理和使用场景后,顿时产生了浓厚的兴趣。今天,就让我们跟随阿Q的脚步,一起来揭开它神秘的面纱吧。
简介
canal 翻译为管道,主要用途是基于 MySQL 数据库的增量日志 Binlog 解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像;
- 数据库实时备份;
- 索引构建和实时维护(拆分异构索引、倒排索引等);
- 业务 cache 刷新;
- 带业务逻辑的增量数据处理;
当前的 canal 支持源端 MySQL 的版本包括 5.1.x,5.5.x,5.6.x,5.7.x,8.0.x。
工作原理
MySQL主备复制原理

- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件 binary log events,可以通过 show binlog events 进行查看);
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log);
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据;
canal 工作原理
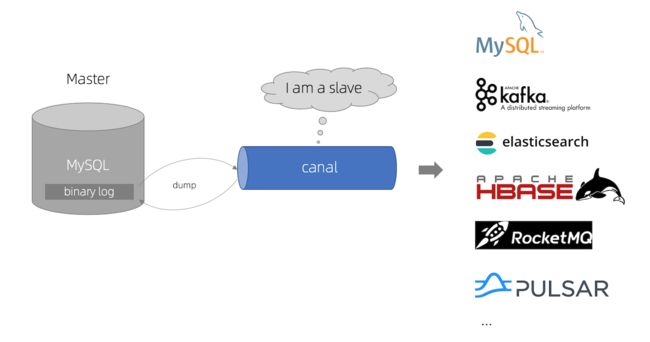
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议;
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal );
- canal 解析 binary log 对象(原始为 byte 流);
github地址:https://github.com/alibaba/canal
完整wiki地址:https://github.com/alibaba/canal/wiki
Canal架构
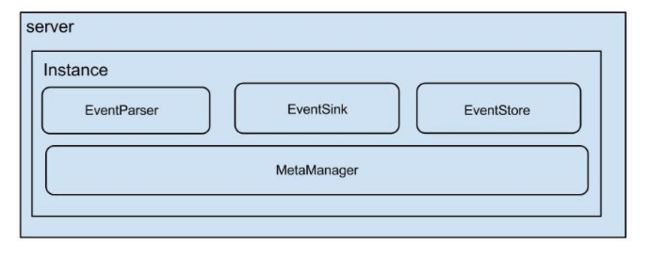
一个 server 代表一个 canal 运行实例,对应于一个 jvm,一个 instance 对应一个数据队列。
instance模块:
- eventParser :数据源接入,模拟 slave 协议和 master 进行交互,协议解析;
- eventSink :Parser 和 Store 链接器,进行数据过滤、加工、分发的工作;
- eventStore :数据存储;
- metaManager :增量订阅&消费信息管理器;
instance 是 canal 数据同步的核心,在一个 canal 实例中只有启动 instace 才能进行数据的同步任务。一个 canal server 实例中可以创建多个 Canal Instance 实例。每一个 Canal Instance 可以看成是对应一个 MySQL 实例。
Canal-HA机制
所谓 HA 即高可用,是 High Available 的简称。通常我们一个服务要支持高可用都需要借助于第三方的分布式同步协调服务,最常用的是zookeeper 。canal 实现高可用,也是依赖了zookeeper 的几个特性:watcher 和 EPHEMERAL 节点。
canal 的高可用分为两部分:canal server 和 canal client
- canal server: 为了减少对 mysql dump 的请求,不同 server 上的 instance(不同 server 上的相同 instance)要求同一时间只能有一个处于 running,其他的处于 standby 状态,也就是说,只会有一个 canal server 的 instance 处于 active 状态,但是当这个 instance down 掉后会重新选出一个 canal server。
- canal client: 为了保证有序性,一份 instance 同一时间只能由一个 canal client 进行 get/ack/rollback 操作,否则客户端接收无法保证有序。
server ha 的架构图如下:

大致步骤:
- canal server 要启动某个 canal instance 时都先向 zookeeper 进行一次尝试启动判断(实现:创建 EPHEMERAL 节点,谁创建成功就允许谁启动);
- 创建 zookeeper 节点成功后,对应的 canal server 就启动对应的 canal instance,没有创建成功的 canal instance 就会处于 standby 状态。
- 一旦 zookeeper 发现 canal server A 创建的 instance 节点消失后,立即通知其他的 canal server 再次进行步骤1的操作,重新选出一个 canal server 启动 instance。
- canal client 每次进行 connect 时,会首先向 zookeeper 询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试 connect。
Canal Client 的方式和 canal server 方式类似,也是利用 zookeeper 的抢占 EPHEMERAL 节点的方式进行控制。
应用场景
同步缓存 Redis /全文搜索 ES
当数据库变更后通过 binlog 进行缓存/ES的增量更新。当缓存/ES更新出现问题时,应该回退 binlog 到过去某个位置进行重新同步,并提供全量刷新缓存/ES的方法。

下发任务
当数据变更时需要通知其他依赖系统。其原理是任务系统监听数据库变更,然后将变更的数据写入 MQ/kafka 进行任务下发,比如商品数据变更后需要通知商品详情页、列表页、搜索页等相关系统。
这种方式可以保证数据下发的精确性,通过 MQ 发送消息通知变更缓存是无法做到这一点的,而且业务系统中不会散落着各种下发 MQ 的代码,从而实现了下发归集。

数据异构
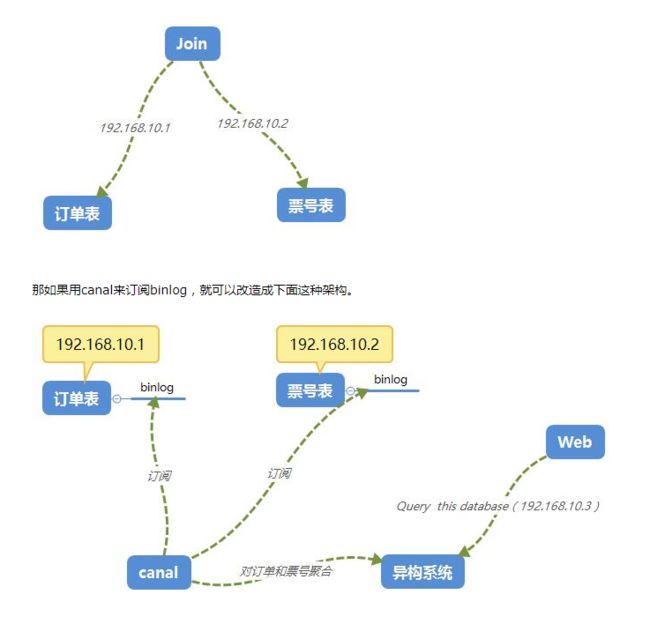
在大型网站架构中,DB都会采用分库分表来解决容量和性能问题。但分库分表之后带来的新问题,比如不同维度的查询或者聚合查询,此时就会非常棘手。一般我们会通过数据异构机制来解决此问题。
所谓的数据异构,那就是将需要 join 查询的多表按照某一个维度又聚合在一个 DB 中让你去查询,canal 就是实现数据异构的手段之一。
MySQL 配置
开启 binlog
首先在 mysql 的配置文件目录中查找配置文件 my.cnf(Linux环境)
[root@iZ2zebiempwqvoc2xead5lZ mysql]# find / -name my.cnf
/etc/my.cnf
[root@iZ2zebiempwqvoc2xead5lZ mysql]# cd /etc
[root@iZ2zebiempwqvoc2xead5lZ etc]# vim my.cnf
在 [mysqld] 区块下添加配置开启 binlog
server-id=1 #master端的ID号【必须是唯一的】;
log_bin=mysql-bin #同步的日志路径,一定注意这个目录要是mysql有权限写入的
binlog-format=row #行级,记录每次操作后每行记录的变化。
binlog-do-db=cheetah #指定库,缩小监控的范围。
重启 mysql:service mysqld restart,会发现在 /var/lib/mysql 下会生成两个文件 mysql-bin.000001 和 mysql-bin.index,当 mysql 重启或到达单个文件大小的阈值时,新生一个文件,按顺序编号 mysql-bin.000002,以此类推。
扩展
binlog 日志有三种格式,可以通过 binlog_format 参数指定。
statement
记录的内容是 SQL语句 原文,比如执行一条 update T set update_time=now() where id=1,记录的内容如下
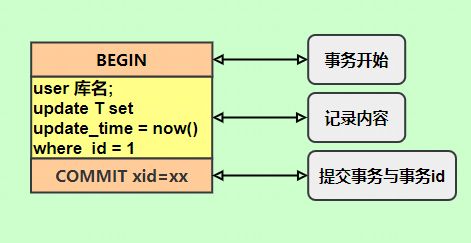
同步数据时,会执行记录的 SQL 语句,但是有个问题,update_time=now() 这里会获取当前系统时间,直接执行会导致与原库的数据不一致。
row
为了解决上述问题,我们需要指定为 row,记录的内容不再是简单的 SQL 语句了,还包含操作的具体数据,记录内容如下。

row 格式记录的内容看不到详细信息,要通过 mysql binlog 工具解析出来。
update_time=now() 变成了具体的时间 update_time=1627112756247,条件后面的 @1、@2、@3 都是该行数据第1个~3个字段的原始值(假设这张表只有3个字段)。
这样就能保证同步数据的一致性,通常情况下都是指定为 row,这样可以为数据库的恢复与同步带来更好的可靠性。
缺点:占空间、恢复与同步时消耗更多的IO资源,影响执行速度。
mixed
MySQL 会判断这条 SQL 语句是否可能引起数据不一致,如果是,就用 row 格式,否则就用 statement 格式。
配置权限
CREATE USER canal IDENTIFIED BY 'XXXX'; #创建用户名和密码都为 canal 的用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; #授予该用户对所有数据库和表的查询、复制主节点数据的操作权限
FLUSH PRIVILEGES; #重新加载权限
注意:如果密码设置的过于简单,会报以下错误
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
MySQL 有密码设置的规范,可以自行百度。
Canal 配置
官网下载地址,我下载的版本是 canal.deployer-1.1.6.tar.gz,然后通过 psftp 上传到服务器。
解压:tar -zxvf canal.deployer-1.1.6.tar.gz
配置
通过查看 conf/canal.properties 配置,发现需要暴漏三个端口
canal.admin.port = 11110
canal.port = 11111
canal.metrics.pull.port = 11112
修改 conf/canal.properties 配置
# 指定实例,多个实例使用逗号分隔: canal.destinations = example1,example2
canal.destinations = example
修改 conf/example/instance.properties 实例配置
# 配置 slaveId 自定义,不等于 mysql 的 server Id 即可
canal.instance.mysql.slaveId=10
# 数据库地址:自己的数据库ip+端口
canal.instance.master.address=127.0.0.1:3306
# 数据库用户名和密码
canal.instance.dbUsername=xxx
canal.instance.dbPassword=xxx
#代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK , ISO-8859-1
canal.instance.connectionCharset = UTF-8
# 指定库和表,这里的 .* 表示 canal.instance.master.address 下面的所有数据库
canal.instance.filter.regex=.*\\..*
如果系统是1个 cpu,需要将
canal.instance.parser.parallel设置为 false
启动
需要在安装目录 /usr/local 下执行:sh bin/startup.sh 或者 ./bin/startup.sh。
报错
发现在 logs 下没有生成 canal.log 日志,在进程命令中 ps -ef | grep canal 也查不到 canal 的进程。
解决
在目录 logs 中存在文件 canal_stdout.log ,文件内容如下:

报错信息提示内存不足,Java 运行时环境无法继续。更详细的错误日志在文件:/usr/local/bin/hs_err_pid25186.log 中。
既然是内存原因,那就检查一下自己的内存,执行命令free -h ,发现可用内存仅为 96M,应该是内存问题,解决方法如下:
- 杀死运行的一些进程;
- 增加虚拟机的内存;
- 修改 canal 启动时所需要的内存;
我就是用的第三种方法,首先用 vim 打开 startup.sh 修改内存参数,可以对照我的进行修改,按照自己服务器剩余内存进行修改,这里我将内存调整到了 80M。

改为
-server -Xms80m -Xmx80m -Xmn80m -XX:SurvivorRatio=2 -XX:PermSize=66m -XX:MaxPermSize=80m -Xss256k -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError
改完之后执行命令发现依旧报错:found canal.pid , Please run stop.sh first ,then startup.sh 意思是找到了 canal.pid,请先运行stop.sh。
这是由于 canal 服务不正常退出服务导致的,比如说虚拟机强制重启。
执行 stop.sh 命令后重新启动,成功运行,成功运行后可以在 canal/logs 文件夹中生成 canal.log 日志。

实战
引入依赖
com.alibaba.otter
canal.client
1.1.0
代码样例
代码样例来自官网,仅用于测试使用
public class SimpleCanalClientExample {
public static void main(String args[]) {
// 创建链接:换成自己的数据库ip地址
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage = null;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
CanalEntry.EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
测试
启动项目,打印日志
empty count : 1
empty count : 2
empty count : 3
empty count : 4
手动修改数据库中的字段:
================> binlog[mysql-bin.000002:8377] , name[cheetah,product_info] , eventType : UPDATE
-------> before
id : 3 update=false
name : java开发1 update=false
price : 87.0 update=false
create_date : 2021-03-27 22:43:31 update=false
update_date : 2021-03-27 22:43:34 update=false
-------> after
id : 3 update=false
name : java开发 update=true
price : 87.0 update=false
create_date : 2021-03-27 22:43:31 update=false
update_date : 2021-03-27 22:43:34 update=false
可以看出是在 mysql-bin.000002文件中,数据库名称 cheetah ,表名 product_info,事件类型:update。
看完上面,再看看我为了写这篇文章又日渐稀少的头发,我忍不住哭出声来。可能只有给我点赞,才能平复我的心情吧。
好看的皮囊千篇一律,有趣的灵魂万里挑一,让我们在冷漠的城市里相互温暖,我是阿Q,我们下期再见!