2022年我的网络爬虫学习心得
目录
一、学习心得
二、爬虫用到的pip模块以及对应的功能
三、单个网页爬虫代码及结果
四、scrapy框架爬虫
五、Gerapy搭建
一、学习心得
本学期我开始接触网络爬虫,从爬虫的基础知识开始学习,到简单的网页信息的抓取和简单的数据处理,将数据保存到MySQL数据库、MongoDB数据库中,乃至于scrapy、gerapy爬虫框架的应用,整体上对数据爬虫有了认识。爬虫工作首先是获取网页,再向服务器发送请求获取信息,将提取到的数据进行存储,以及自动化程序。
万事开头难,刚开始学习需要了解的基础知识挺多,代码报错是经常的事,还有软件的安装,各种库的安装,都很容易出错。在爬虫学习的过程中,我遇到了很多问题,通过请教老师、同学,百度,CSDN等方式,解决了问题,也学到了很多新的知识,积累了经验,更加严谨。我觉得能够把想要的数据抓取下来是一件非常有成就感的事情,每一次看到代码的成功运行,数据被不断的爬取,看到后都会充满欣喜,大大提高了我对爬虫学习的积极性。技术总是在不断地发展与进步,网页也采取了各种防护措施,爬虫和反爬虫在不断斗争,像WebDiver检测、参数加密、前端代码的压缩等,要做到高效的数据爬取,还有许多需要学习的东西。
二、爬虫用到的pip模块以及对应的功能
urllib:设定相关的头部信息然后和网站建立请求连接,请求连接建立完成后就能够去获取到网页的整体数据
requests:用作发送网络请求,根据对方服务器的要求不同,可使用GET、POST和PUT等方式进行请求。并且可以对请求头进行伪装、使用代理访问等
pandas:pandas 是基于NumPy 的一种工具, 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
pymysql:Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求。
pymongo:是在python中操作mongodb数据库的程序,操作者可以在python中使用python语法+mongodb语法实现对mongodb数据库的操作。将数据存储为一个文档,数据结构为键值对,类似JSON对象,也可以当作Python的字典来看待。
BeautifulSoup:BeautifulSoup是一个灵活方便的网页解析库,处理搞笑,支持多种解析器。利用它可以不用编写正则表达式就可以方便的实现网页信息的抓取。
Numpy:numpy模块支持高阶、大量的矩阵计算和向量计算的方法,还提供了非常丰富的函数。
sqlalchemy:是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作。
lxml:是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
json:是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。
gerapy:是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:更方便地控制爬虫运行,更直观地查看爬虫状态,更实时地查看爬取结果,更简单地实现项目部署,更统一地实现主机管理。
三、单个网页爬虫代码及结果
爬取数据并保存到MySQL


结果

爬取数据并保存到MongoDB

结果

四、scrapy框架爬虫
(一)分步骤描述items,middlewares,pipelines,settings如何配置的文字描述以及对应代码。
用scrapy.Field()构建数据存储字段,定义title,url,date,content,site,item,student_id这七个要爬取的字段。
import scrapy
class NewsdataItem(scrapy.Item):
title = scrapy.Field() #文章标题
url = scrapy.Field() #文章链接
date = scrapy.Field() #发布日期
content = scrapy.Field() #文章正文
site = scrapy.Field() #站点
item = scrapy.Field() #栏目
student_id = scrapy.Field() #学号2. middlewares
SpiderMiddleware和DownloaderMiddleware这两个类默认不需要变动,这个部分需要添加header。
# 添加Header
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.utils.project import get_project_settings
import random
settings = get_project_settings()
class RotateUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
referer = request.url
if referer:
request.headers["referer"] = referer
USER_AGENT_LIST = settings.get('USER_AGENT_LIST')
user_agent = random.choice(USER_AGENT_LIST)
if user_agent:
request.headers.setdefault('user-Agent', user_agent)
print(f"user-Agent:{user_agent}")3.pipelines
host,port,dbname和sheetname对应settings里面的ip地址,端口号,数据库名,表名。数据写入时使用insert_one。
# 添加必备包和加载设置
import pymongo
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class NewsdataPipeline:
# class中全部替换
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DATABASE"]
sheetname = settings["MONGODB_TABLE"]
# username = settings["MONGODB_USER"]
# password = settings["MONGODB_PASSWORD"]
# 创建MONGODB数据库链接
#client = pymongo.MongoClient(host=host, port=port, username=username, password=password)
client = pymongo.MongoClient(host=host, port=port)
# 指定数据库
mydb = client[dbname]
# 存放数据的数据库表名
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
# 数据写入
self.post.insert_one(data)
return item4.setting
ROBOTSTXT_OBEY这个要改为False,不然有的网站不能爬取,mongodb数据库的设置:IP地址,端口号默认27017,数据库名称和表名称。将信息放入到USER_AGENT_YANGYUAN中
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
#'NewsData.middlewares.NewsdataDownloaderMiddleware': 543,
'NewsData.middlewares.RotateUserAgentMiddleware': 543,
}
ITEM_PIPELINES = {
'NewsData.pipelines.NewsdataPipeline': 300,
}
USER_AGENT_LIST = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 添加MONGODB数仓设置
MONGODB_HOST = "localhost" # 数仓IP
MONGODB_PORT = 27017 # 数仓端口号
MONGODB_DATABASE = "NewsData" # 数仓数据库
MONGODB_TABLE = "News_Process_YANGYUAN" # 数仓数据表单(二)分步骤描述爬虫启动start_requests、列表解析parse、内容解析parse_detail、以及数据存储的文字描述对应代码
1.爬虫启动start_requests
通过for循环爬取每个站点,site和item对应的每个网址列表里面的第一个和第二个元素,每爬取一次yeild进行传参,目标网址进行request访问。
def start_requests(self):
for url in self.start_urls:
item = NewsdataItem()
item["site"] = url[1]
item["item"] = url[2]
item["student_id"] = "20201949"
yield scrapy.Request(url=url[0], meta={"item": deepcopy(item)}, callback=self.parse)2.列表解析parse
定义三个列表title_list、url_list、date_list,采用response.xpath方法,通过对应的xpath去定位url,title和date,extract()函数解析成列表的形式,进行遍历循环,title,url,date对应列表的相应位置元素,再使用yield进行二次返回跳转。通过contains判断数据是否含有日期标签。
def parse(self, response):
item = response.meta["item"]
title_list = response.xpath('/html/body//li/descendant::h3/a/text()').extract()
url_list = response.xpath('/html/body//li/descendant::h3/a/@href').extract()
date_list = response.xpath('/html/body//li/descendant::label[1][contains(text(), "-" )]/text() ').extract()
if len(date_list) == 0:
date_list = response.xpath('/html/body//li/descendant::span[1][contains(text(), "-")]/text() ').extract()
print(title_list)
for each in range(len(title_list)):
item["title"] = title_list[each]
item["url"] = url_list[each]
item["date"] = date_list[each]
yield scrapy.Request(url=item["url"], meta={"item": deepcopy(item)}, callback=self.parse_detail)3.内容解析parse_detail
采用response.xpath方法,根据对应的xpath去定位正文内容content,通过管道把item数据保存到数据库。
def parse_detail(self, response):
item = response.meta["item"]
strs = response.xpath('//*[@id="news-body"]/descendant::p[string-length()>4]/text()').extract()
item["content"] = ''.join(str(i) for i in strs)
return item(三)在数据库可视化界面中截图抓取的数据截图(814条)。

五、Gerapy搭建
1.pip配置
pip install gerapy
pip install scrapyd

2.创建用户

创建表单 gerapy migrate
初始化账户


打开浏览器,输入127.0.0.1:8000,输入密码和用户名

3.主机管理
点击主机管理,点击创建

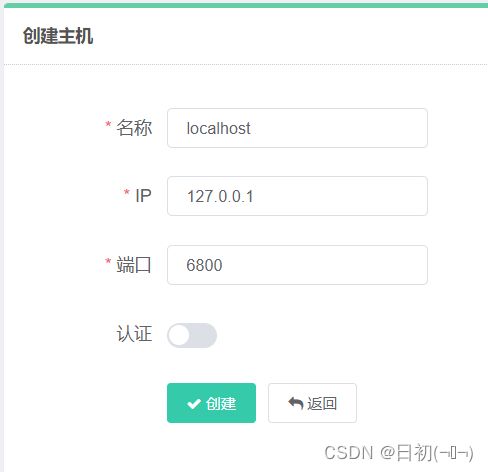
主机名为localhost,IP为127.0.0.1,端口号为6800,状态正常。

4.项目管理
将scrapy框架的整个文件夹放在gerapy文件夹下的projects里面,在项目管理中打包后部署。


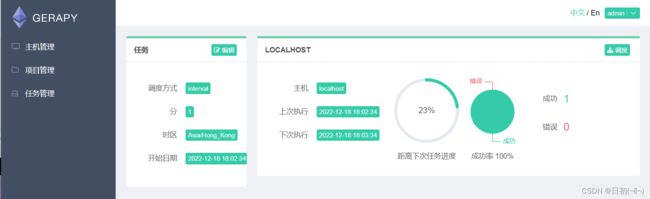
5.任务管理
编辑任务名称,项目是整个NewsData文件夹,脚本是spiders文件夹下的news,主机为连接好的localhost,调度方式可以自己定时间,可以在任务中查看每个任务的运行状态,下面是实际运行的数据结果。