基于python爬虫下载网站在线视频
运行展示
程序运行后的结果如下所示:


系统可以对mp4和m3u8的视频进行下载,具体的下载方法见下文描述。
流程分析
对于下载网站的在线视频,首先需要找到视频对应的url,我们知道浏览器在线播放的视频肯定是从服务器端进行的资源获取,那么就存在视频的url来让浏览器端进行视频的获取,在线视频的url一般就是两种格式:.mp4 和 .ts,而.mp4的链接就可以直接对链接进行请求获取视频,但是以.ts结尾的视频,实际上是将一个大的视频进行分片,分为若干个小的视频片段,所以对于.ts结尾的视频,需要获取所有的完整的.ts片段,也就是需要获取.m3u8文件内的所有链接,对这些链接逐一请求下载,然后再对每一个片段合并即是完整的视频。
现在的部分网站的反爬措施做的比较好,而且视频进行加密处理,获取难度较高。所以我们仅针对没有进行视频加密的网站进行在线视频获取。主要分为MP4和m3u8两种视频的获取。
1、MP4
对于部分在线视频,直接可以利用浏览器的抓包工具获取视频的MP4链接, 例如,以浙江卫视为例,打开某个视频片段,然后右键检查,就可以看到网页的源代码,如下所示。
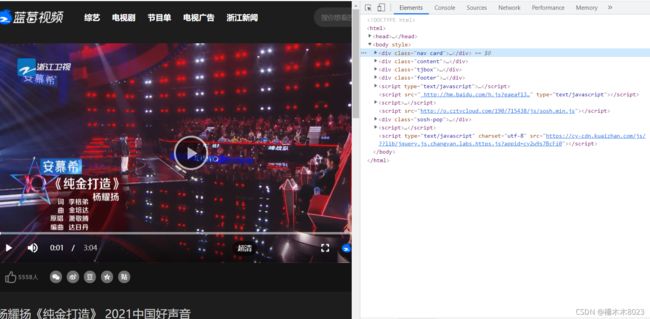
在源码中可以直接找到以.mp4结尾的视频的链接,如下所示。

或者,点击network,过滤MP4或者m3u8查看链接,如下图所示。

其中的request url就是MP4视频的链接。
2、m3u8
对于某些网站,其在线视频采用.ts的片段进行播放,所以需要获取到所有的.ts片段的链接,以cctv为例,进行抓包,可以看见大量的.ts结尾的包,如下所示。经过观察可以发现,每个ts的url只有最后一部分不一样。
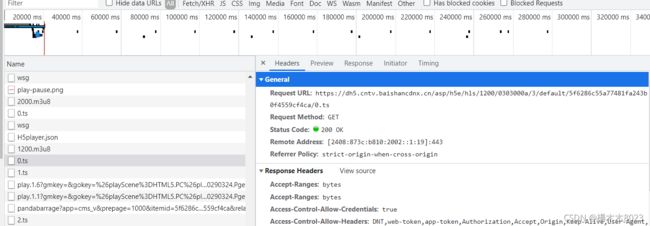
.ts片段的链接(或者每个ts不一样的部分)一般会存放在.m3u8文件中,过滤出m3u8,如下所示。

利用m3u8里面的数据就可以获取到每一个ts片段了。
代码编写
主要实现的功能如下:
实现对在线视频(mp4、m3u8)的下载,具体包括:
(1)多线程下载
(2)ts视频文件合并
(3)进度条显示
(4)日志记录
(5)重复下载提示
1、mp4文件下载方法
"""以下是对直接有mp4文件地址的视频进行下载的操作"""
# 直接针对mp4链接视频的获取
def get_video_mp4(self):
mp4_path = 'videoMP4\\' + 'video' + ''.join(str(time.time()).split('.', 2)) + '.mp4'
# stream=True 意味着,当函数返回时,仅响应标头被下载,响应主体不会
try:
response_head = requests.get(url=self.url_m3u8, stream=True, headers=self.headers)
except Exception as e:
print(e)
exit()
# 判断是否有正确的响应,如没有正确响应则说明url出错,不能正确下载,退出程序
if response_head.status_code != 200:
print('下载出错!')
exit()
# 获取响应头中的文件大小
length = float(response_head.headers['content-length'])
# 下载文件,对文件进行分块下载,每次512kb,方便对文件目录实时读取获得已下载的大小
def write_video():
count = 0
with open(mp4_path, 'wb') as fp:
for chunk in response_head.iter_content(chunk_size=512):
if chunk:
fp.write(chunk)
count += len(chunk)
# 计算下载进度,用已下载的文件大小/文件总的大小
def progress_bar():
start = time.perf_counter()
while True:
down_size = os.path.getsize(mp4_path)
p = math.ceil((down_size / length) * 100) # 向上进行取整,确保下载完成是的进度为100%
dur = time.perf_counter() - start
print("\r", end="")
print("下载进度: {}%: ".format(p), "▋" * (p // 2), "{:.2f}s".format(dur), end="")
sys.stdout.flush()
time.sleep(0.05)
if p == 100:
break
print()
t1 = threading.Thread(target=write_video)
t1.start()
progress_bar()
t1.join()
self.path_log = os.path.join(os.getcwd(), mp4_path)
print('视频合并完成!视频路径:{0}'.format(self.path_log))2、m3u8视频下载方法
对于m3u8视频,首先需要输入m3u8文件对于的url,根据url获取m3u8文件,由于分片较多,所以这里可以采用多线程对m3u8内的ts多线程下载,也就是可以让每个线程负责一部分ts分片视频的下载,例如,本程序先获得m3u8文件的行数,然后将其平均分配成8个子文件,每个子文件的链接就作为一个线程进行下载,程序如下。
# 获取视频流切片m3u8的对应网址,下载视频切片就按照文件内的网址进行下载
def get_m3u8(self):
global response
try:
response = requests.get(url=self.url_m3u8, headers=self.headers)
except Exception as e:
print(e)
exit()
response_data = response.text
if response.status_code == 200:
with open('data.txt', 'w', encoding='utf-8') as fp:
fp.write(response_data)
print('链接获取完成!')
else:
print('网址解析出错!')
exit()
# 对文件的视频流地址进行提取并划分为8个文件,方便启用八线程下载
def spl_file(self):
# 对m3u8文件内容的行数和下载链接数进行统计,方便后续的文件分块和计算下载进度
with open('data.txt', 'r', encoding='utf-8') as fp:
while True:
self.count_line += 1
link = fp.readline()
if not link:
break
if link[:4] != "#EXT":
self.count += 1
with open('data.txt', 'r', encoding='utf-8') as fp:
flag, num = 0, 1
while True:
link = fp.readline()
if not link:
break
filename = 'filedir/' + 'thread' + str(num)
with open(filename, 'a') as fp1:
fp1.write(link)
flag += 1
n = math.ceil(self.count_line / 8) # 分为8个文件,方便8线程下载
if flag == n:
flag = 0
num += 1接下来,就是开启多线程对m3u8文件的ts链接进行下载,由于在对ts文件下载后需要对ts文件进行合并,所以ts的最终顺序需要保持和m3u8里的一致,那么对于多线程而言下载顺序不会从前到后保持一致,但是每一个线程内的下载的顺序是按照子文件的顺序进行的,所以这里利用线程号+下载时间进行标识就可以实现ts文件的顺序排序,程序如下。
# 根据获取的视频切片链接下载视频切片
def get_video_m3u8(self, *args):
filename, num = args[0], args[1]
try: # 处理m3u8内容少,不够8个线程时的异常
with open(filename, 'r', encoding='utf-8') as fp:
while True:
link = fp.readline()
if not link:
break
if link[:4] != "#EXT": # 提取出下载链接的行
if link[:4] != 'hhtp':
re_link = self.pre_url + '/' + link[:len(link) - 1] # 去掉换行符
else:
re_link = link[:len(link) - 1]
tmp = str(time.time()).split('.', 2) # 以下载时间对视频片段进行排序
# 为了保证视频切片有序,需要依照每个线程的进行变换,如线程1,编号1+下载时间.ts,线程2,编号2+下载时间.ts
tsName = 'videoTS/' + str(num) + '-' + ''.join(tmp) + '.ts'
fp_video = open(tsName, 'wb')
response = requests.get(url=re_link, headers=self.headers)
response_video = response.content
if response.status_code != 200:
print('下载出错!')
exit()
fp_video.write(response_video)
fp_video.close()
except Exception as e:
print(e)
"""
下载进度条,用来显示下载进度
预先在spl_file()计算下载的总文件数:self.count
不停的监控已下载到文件夹的文件数量:progress
下载进度:p=progress / self.count
"""
def progress_bar(self):
start = time.perf_counter()
while True:
list_ts_path = os.listdir('videoTS')
progress = len(list_ts_path)
p = math.ceil((progress / self.count) * 100)
dur = time.perf_counter() - start
print("\r", end="")
print("下载进度: {}%: ".format(p), "▋" * (p // 2), "{:.2f}s".format(dur), end="")
sys.stdout.flush()
time.sleep(0.05)
if p == 100:
break
print()3、日志记录和重复下载提示
此外,程序还有日志记录方法和重复下载提示方法。日志记录文件记录了下载的时间,文件路径,和下载的url,每一行作为一次下载记录。重复下载提示,主要是在用户输入下载url的时候查看日志中是否已经存在下载记录,若存在下载记录并且文件目录的文件存在则提醒用户重复下载,若不存在则不提醒。程序如下所示。
# 下载日志,为了对每行进行编号,每次日志记录为一行,为了得到本行的行号,需要知道上一行的行号,+1操作后即是本行行号
# 同时,为了节省读取文件时间,每次获取上一行的行号,需要对日志文件从后向前读取最后一行,这里利用seek()方法
"""
seek()讲解:
1、fileObject.seek(offset[, whence])
2、offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
3、whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;
0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
"""
def download_log(self):
if not os.path.exists('log.txt'):
with open('log.txt', 'a', encoding='utf-8') as fp1:
fp1.write('##### download log ##### \n')
fp1.write('0: 时间\t\t路径\t\t网址\n')
try:
with open('log.txt', 'rb') as fp2: # 打开文件
off = -10 # 设置偏移量
while True:
if os.path.getsize('log.txt') == 0:
break
fp2.seek(off, 2)
lines = fp2.readlines() # 读取文件指针范围内所有行
if len(lines) >= 2: # 判断是否最后至少有两行,这样保证了最后一行是完整的
last_line = lines[-1] # 取最后一行
break
# 如果off为5时得到的readlines只有一行内容,那么不能保证最后一行是完整的
# 所以off翻倍重新运行,直到readlines不止一行
off *= 2
try:
self.num = str(last_line.decode())[:1]
if int(self.num) >= 100:
with open('log.txt', 'w', encoding='utf-8') as f:
f.write('##### download log ##### \n')
f.write('0: 时间\t\t路径\t\t网址\n')
self.num = 0
except Exception as e:
pass
except Exception as e:
pass
with open('log.txt', 'a', encoding='utf-8') as fp3:
timestamp = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
download_url = self.url_m3u8
line_num = str(int(self.num) + 1) + ': '
down_log = timestamp + ' ' + self.path_log + ' ' + download_url
fp3.write(line_num + down_log + '\n')
# 验证视频是否重复下载
def break_point(self):
# 首先对链接视频是否已经存在做一下验证,若已经存在提醒用户,不存在则下载
try: # 处理首次使用没有日志文件的异常
with open('log.txt', 'r', encoding='utf-8') as fp:
fp.readline()
fp.readline()
while True:
log_info = fp.readline()
if not log_info:
break
list_log_info = re.split(r'[ ]', log_info[:len(log_info) - 1])
if self.url_m3u8 == list_log_info[-1]:
if os.path.exists(list_log_info[-3]):
print('视频存在:', list_log_info[-3])
choose = input('是否重新下载!(1确认/其它取消):')
if choose == '1':
pass
else:
exit()
break
else:
pass
except Exception as e:
pass以上就是功能实现的主要程序介绍,完整程序请访问链接下载:https://github.com/Yang-Jianlin/Download_Video/blob/master/getVideo.py