技术分享:Flink源码分析-Task执行
本文作者:擎创科技 研发总监a coder
在介绍JobMaster之前,先插播一篇分析从Task被提交到TaskExecutor后到运行的过程。所有的分布式计算引擎都有一个序列化任务然后提交给各Worker节点去执行的过程,我们在开始开发Flink作业或者Spark作业时,也经常会遇到一些序列化相关的异常,所有这些都牵扯到几个问题:
- Flink如何来描述我们开发的数据处理逻辑(绝大部分是user Function)。
- Flink如何来序列化以及反序列化我们开发的数据处理逻辑。
- Flink最终如何执行我们开发的数据处理逻辑。
这几个问题包括了任务提交客户端、JobMaster 以及 TaskExecutor三个环节,牵扯到了StreamGraph,JobGraph,ExecutionGraph 以及 Task等概念。我准备采取倒序的方式,从后向前一段段进行分析,今天我们先分析Task被提交到Task Executor之后这一段,首先我们来看看Task提交的入口,从方法签名以及实现来看反序列化后的TaskInformation应该就包含了任务执行所需要的信息。
submitTask
public CompletableFuture submitTask(
TaskDeploymentDescriptor tdd,
JobMasterId jobMasterId,
Time timeout) {
//...
// deserialize the pre-serialized information
final JobInformation jobInformation;
final TaskInformation taskInformation;
try {
jobInformation = tdd.getSerializedJobInformation().deserializeValue(getClass().getClassLoader());
//反序列化拿到Task的信息
taskInformation = tdd.getSerializedTaskInformation().deserializeValue(getClass().getClassLoader());
} catch {}
...
Task task = new Task(
jobInformation,
taskInformation//,
//...
);
log.info("Received task {}.", task.getTaskInfo().getTaskNameWithSubtasks());
boolean taskAdded;
try {
taskAdded = taskSlotTable.addTask(task);
} catch (SlotNotFoundException | SlotNotActiveException e) {
throw new TaskSubmissionException("Could not submit task.", e);
}
if (taskAdded) {
//启动Task
task.startTaskThread();
taskCompletionTracker.trackTaskCompletion(task);
//...
}
} TaskInformation
public class TaskInformation implements Serializable {
private static final long serialVersionUID = -9006218793155953789L;
/** Job vertex id of the associated job vertex */
private final JobVertexID jobVertexId;
/** Name of the task */
private final String taskName;
/** The number of subtasks for this operator */
private final int numberOfSubtasks;
/** The maximum parallelism == number of key groups */
private final int maxNumberOfSubtaks;
/** Class name of the invokable to run */
private final String invokableClassName;
/** Configuration for the task */
private final Configuration taskConfiguration;
}这个类的结构比较简单,关键的成员有如下两个:
- invokableClassName,顾名思义以及根据注释这应该是后面需要构造以及执行的类的名称。
- taskConfiguration,其内部包含了一个Map结构来存储具体的序列化后的配置信息。
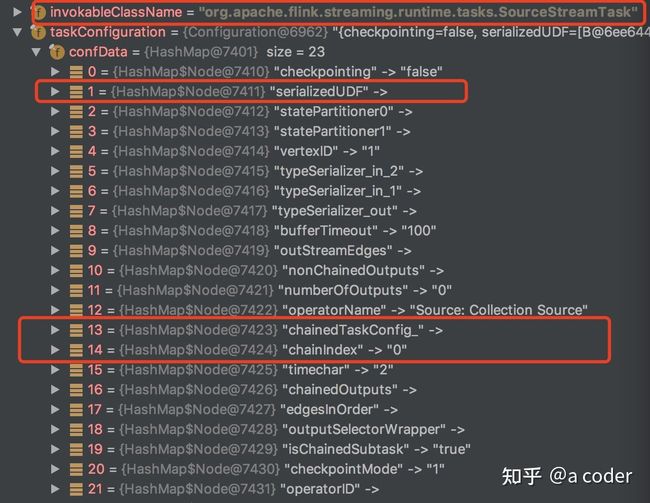
我通过代码调试,截取了一些这个结构实例化后的值作为参考:
- invokableClassName 为 SourceStreamTask
- taskConfiguration中有两个键值比较关键:serializedUDF 以及 chainedTaskConfig_。具体的用户后面会分析。
Task
我们先来看一下SourceStreamTask,从之前的代码注释(invokableClassName)来看,这个类会作为这个Task的创建以及调用入口,首先看看这个类的继承关系:

为了阅读方便,我去掉了范型以及接口的关系,上面的结构很清楚,下面大致介绍一下几个类的作用
- AbstractInvokable,下面是该类的介绍,意思很明确:所有TaskManager能执行的任务都是继承自它。
This is the abstract base class for every task that can be executed by a TaskManager.
Concrete tasks extend this class, for example the streaming and batch tasks.
- StreamTask,意思也很明确,所有的流处理任务都继承自它,每一个任务包含一个或多个算子,多个算子可以合成一条Chain,在一个线程内执行。
Base class for all streaming tasks. A task is the unit of local processing that is deployed
and executed by the TaskManagers. Each task runs one or more StreamOperators which form the Task's operator chain. Operators that are chained together execute synchronously in the same thread and hence on the same stream partition. A common case for these chains are successive map/flatmap/filter tasks.
- SourceStreamTask,故名思议代表一个流数据源的任务,它里面包含一个实际产生数据的SourceSource(包含了用户实现的SourceFunction)。
StreamTask for executing a StreamSource.
- OneInputStreamTask,有一个输入的流处理任务。
A StreamTask for executing a OneInputStreamOperator
其他的几个子类,大家可以自行去阅读,基本上每一个子类对应一类任务,包含了某一类算子。
Operator
上面的Task介绍里面,都提到了Operator,网上找到的Flink原理介绍文章里面,也可以常常看见"算子"。我们在开发Flink作业时,最常见的就是去实现一些Function,比如:SourceFunction,RichFlatMapFunction,MapFunction等等,这些Function被用来构造Operator,下面是StreamFlatMap算子的定义,从代码可以看到我们编写的FlatMapFunction作为构造参数来进行实例化StreamFlatMap算子。
//DataStream
public SingleOutputStreamOperator flatMap(FlatMapFunction flatMapper) {
TypeInformation outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper),
getType(), Utils.getCallLocationName(), true);
return transform("Flat Map", outType, new StreamFlatMap<>(clean(flatMapper)));
}
public class StreamFlatMap
extends AbstractUdfStreamOperator>
implements OneInputStreamOperator {
private static final long serialVersionUID = 1L;
private transient TimestampedCollector collector;
public StreamFlatMap(FlatMapFunction flatMapper) {
super(flatMapper);
chainingStrategy = ChainingStrategy.ALWAYS;
}
@Override
public void open() throws Exception {
super.open();
collector = new TimestampedCollector<>(output);
}
@Override
public void processElement(StreamRecord element) throws Exception {
collector.setTimestamp(element);
userFunction.flatMap(element.getValue(), collector);
}
} 那么这些Operator(算子) 是如何被嵌入到Task中间去执行的呢? 我们以StreamTask为例来一探究竟。
StreamTask
实例化
先来看一下StreamTask的实例化过程。回顾一下前面的TaskInformation里面,我们已经拿到了invokableClassName 以及 taskConfig,实例化代码如下,可以看到在初始化时,只是利用反射的方法找到构造函数,然后进行实例化,没有做额外的其他逻辑。
private static AbstractInvokable loadAndInstantiateInvokable(
ClassLoader classLoader,
String className,
Environment environment) throws Throwable {
final Class invokableClass;
try {
//根据className获取到其对应的类
invokableClass = Class.forName(className, true, classLoader)
.asSubclass(AbstractInvokable.class);
} catch (Throwable t) {
throw new Exception("Could not load the task's invokable class.", t);
}
Constructor statelessCtor;
try {
//找到其有Environment参数的构造函数
statelessCtor = invokableClass.getConstructor(Environment.class);
} catch (NoSuchMethodException ee) {
throw new FlinkException("Task misses proper constructor", ee);
}
// instantiate the class
try {
//noinspection ConstantConditions --> cannot happen
//实例化Task
return statelessCtor.newInstance(environment);
} catch (InvocationTargetException e) {
// directly forward exceptions from the eager initialization
throw e.getTargetException();
} catch (Exception e) {
throw new FlinkException("Could not instantiate the task's invokable class.", e);
}
}invoke
所有Task调用开始执行的入口为invoke方法,以下为invoke方法的执行步骤介绍
invoke()
* +----> Create basic utils (config, etc) and load the chain of operators
* +----> operators.setup()
* +----> task specific init()
* +----> initialize-operator-states()
* +----> open-operators()
* +----> run()
* +----> close-operators()
* +----> dispose-operators()
* +----> common cleanup
* +----> task specific cleanup()
本文会详细介绍粗体的两个步骤(OperatorChain的构建 以及 Run),其他的步骤主要是一些任务、算子、状态的初始化以及回收,不影响执行的主体步骤,这里不再做分析。通过看invoke的代码,可以发现OperatorChain的构造在beforeInvoke方法中,而run的具体方法为runMailboxLoop。
@Override
public final void invoke() throws Exception {
try {
beforeInvoke();
// final check to exit early before starting to run
if (canceled) {
throw new CancelTaskException();
}
// let the task do its work
runMailboxLoop();
// if this left the run() method cleanly despite the fact that this was canceled,
// make sure the "clean shutdown" is not attempted
if (canceled) {
throw new CancelTaskException();
}
afterInvoke();
} catch (Throwable invokeException) {
failing = !canceled;
try {
cleanUpInvoke();
}
// TODO: investigate why Throwable instead of Exception is used here.
catch (Throwable cleanUpException) {
Throwable throwable =
ExceptionUtils.firstOrSuppressed(cleanUpException, invokeException);
ExceptionUtils.rethrowException(throwable);
}
ExceptionUtils.rethrowException(invokeException);
}
cleanUpInvoke();
}
protected void beforeInvoke() throws Exception {
disposedOperators = false;
LOG.debug("Initializing {}.", getName());
operatorChain = new OperatorChain<>(this, recordWriter);
mainOperator = operatorChain.getMainOperator();
// task specific initialization
init();
// save the work of reloading state, etc, if the task is already canceled
if (canceled) {
throw new CancelTaskException();
}
// -------- Invoke --------
}还是老规矩,我们以结果为导向,先分析runMailboxLoop,经过分析runMailboxLoop方法以及mailboxProcessor的构造,可以得出runMailboxLoop方法最终调用了processInput方法,具体的代码推导片段如下
public void runMailboxLoop() throws Exception {
mailboxProcessor.runMailboxLoop();
}
//mailboxProcesser的构造
this.mailboxProcessor = new MailboxProcessor(this::processInput, mailbox, actionExecutor);
//mailboxProcessor的runMailboxLoop方法实现
/** Runs the mailbox processing loop. This is where the main work is done. */
public void runMailboxLoop() throws Exception {
...
final MailboxController defaultActionContext = new MailboxController(this);
while (isMailboxLoopRunning()) {
// The blocking `processMail` call will not return until default action is available.
processMail(localMailbox, false);
if (isMailboxLoopRunning()) {
//开始执行
mailboxDefaultAction.runDefaultAction(
defaultActionContext); // lock is acquired inside default action as needed
}
}
}
protected void processInput(MailboxDefaultAction.Controller controller) throws Exception {
//执行入口
InputStatus status = inputProcessor.processInput();
if (status == InputStatus.MORE_AVAILABLE && recordWriter.isAvailable()) {
return;
}
if (status == InputStatus.END_OF_INPUT) {
controller.allActionsCompleted();
return;
}
}终于来到了真正的入口InputProcessor,StreamTask里面并没有去实例化这个对象,我们以OneInputStreamTask为例进行分析,inputProcessor的实例化在init方法中,inputProcessor的processInput方法经过几次中转,最终调用到了mainOperator.processElement方法,具体代码如下:
public void init() throws Exception {
StreamConfig configuration = getConfiguration();
int numberOfInputs = configuration.getNumberOfNetworkInputs();
if (numberOfInputs > 0) {
DataOutput output = createDataOutput(numRecordsIn);
StreamTaskInput input = createTaskInput(inputGate);
//构造Processor需要input, output 以及 operatorChain
inputProcessor = new StreamOneInputProcessor<>(input, output, operatorChain);
}
}
private DataOutput createDataOutput(Counter numRecordsIn) {
return new StreamTaskNetworkOutput<>(
mainOperator, getStreamStatusMaintainer(), inputWatermarkGauge, numRecordsIn);
}
private StreamTaskInput createTaskInput(CheckpointedInputGate inputGate) {
int numberOfInputChannels = inputGate.getNumberOfInputChannels();
StatusWatermarkValve statusWatermarkValve = new StatusWatermarkValve(numberOfInputChannels);
TypeSerializer inSerializer =
configuration.getTypeSerializerIn1(getUserCodeClassLoader());
return new StreamTaskNetworkInput<>(
inputGate, inSerializer, getEnvironment().getIOManager(), statusWatermarkValve, 0);
}
public final class StreamOneInputProcessor implements StreamInputProcessor {
private final StreamTaskInput input;
private final DataOutput output;
private final BoundedMultiInput endOfInputAware;
public StreamOneInputProcessor(
StreamTaskInput input, DataOutput output, BoundedMultiInput endOfInputAware) {
this.input = checkNotNull(input);
this.output = checkNotNull(output);
this.endOfInputAware = checkNotNull(endOfInputAware);
}
@Override
public InputStatus processInput() throws Exception {
InputStatus status = input.emitNext(output);
...
}
}
public final class StreamTaskNetworkInput implements StreamTaskInput {
@Override
public InputStatus emitNext(DataOutput output) throws Exception {
while (true) {
// get the stream element from the deserializer
if (currentRecordDeserializer != null) {
DeserializationResult result;
try {
result = currentRecordDeserializer.getNextRecord(deserializationDelegate);
} catch (IOException e) {
throw new IOException(
String.format("Can't get next record for channel %s", lastChannel), e);
}
if (result.isBufferConsumed()) {
currentRecordDeserializer.getCurrentBuffer().recycleBuffer();
currentRecordDeserializer = null;
}
if (result.isFullRecord()) {
processElement(deserializationDelegate.getInstance(), output);
return InputStatus.MORE_AVAILABLE;
}
}
Optional bufferOrEvent = checkpointedInputGate.pollNext();
if (bufferOrEvent.isPresent()) {
// return to the mailbox after receiving a checkpoint barrier to avoid processing of
// data after the barrier before checkpoint is performed for unaligned checkpoint
// mode
if (bufferOrEvent.get().isBuffer()) {
processBuffer(bufferOrEvent.get());
} else {
processEvent(bufferOrEvent.get());
return InputStatus.MORE_AVAILABLE;
}
} else {
if (checkpointedInputGate.isFinished()) {
checkState(
checkpointedInputGate.getAvailableFuture().isDone(),
"Finished BarrierHandler should be available");
return InputStatus.END_OF_INPUT;
}
return InputStatus.NOTHING_AVAILABLE;
}
}
}
private void processElement(StreamElement recordOrMark, DataOutput output) throws Exception {
if (recordOrMark.isRecord()) {
output.emitRecord(recordOrMark.asRecord());
} else if (recordOrMark.isWatermark()) {
statusWatermarkValve.inputWatermark(
recordOrMark.asWatermark(), flattenedChannelIndices.get(lastChannel), output);
} else if (recordOrMark.isLatencyMarker()) {
output.emitLatencyMarker(recordOrMark.asLatencyMarker());
} else if (recordOrMark.isStreamStatus()) {
statusWatermarkValve.inputStreamStatus(
recordOrMark.asStreamStatus(),
flattenedChannelIndices.get(lastChannel),
output);
} else {
throw new UnsupportedOperationException("Unknown type of StreamElement");
}
}
private void processEvent(BufferOrEvent bufferOrEvent) {
// Event received
final AbstractEvent event = bufferOrEvent.getEvent();
// TODO: with checkpointedInputGate.isFinished() we might not need to support any events on
// this level.
if (event.getClass() == EndOfPartitionEvent.class) {
// release the record deserializer immediately,
// which is very valuable in case of bounded stream
releaseDeserializer(bufferOrEvent.getChannelInfo());
}
}
private void processBuffer(BufferOrEvent bufferOrEvent) throws IOException {
lastChannel = bufferOrEvent.getChannelInfo();
checkState(lastChannel != null);
currentRecordDeserializer = recordDeserializers.get(lastChannel);
checkState(
currentRecordDeserializer != null,
"currentRecordDeserializer has already been released");
currentRecordDeserializer.setNextBuffer(bufferOrEvent.getBuffer());
}
private static class StreamTaskNetworkOutput extends AbstractDataOutput {
private final OneInputStreamOperator operator;
private StreamTaskNetworkOutput(
OneInputStreamOperator operator,
StreamStatusMaintainer streamStatusMaintainer,
WatermarkGauge watermarkGauge,
Counter numRecordsIn) {
super(streamStatusMaintainer);
this.operator = checkNotNull(operator);
this.watermarkGauge = checkNotNull(watermarkGauge);
this.numRecordsIn = checkNotNull(numRecordsIn);
}
@Override
public void emitRecord(StreamRecord record) throws Exception {
numRecordsIn.inc();
operator.setKeyContextElement1(record);
//这里开始调用operator
operator.processElement(record);
}
} 接下来的问题就是要搞清楚mainOperator的来历,发现mainOperator和OperatorChain都是在beforeInvoke方法中构造的,代码片段如下,而且mainOperator也是来自OperatorChain,看来所有的谜底都需要去OperatorChain去寻找了。
protected void beforeInvoke() throws Exception {
disposedOperators = false;
LOG.debug("Initializing {}.", getName());
operatorChain = new OperatorChain<>(this, recordWriter);
mainOperator = operatorChain.getMainOperator();
...
}OperatorChain
几乎所有的逻辑都在OperatorChain的构造函数里面,包括算子的构造 以及 算子之间Chain关系的构建,算子关联关系的构建是通过递归去创建的,单纯看代码比较绕,大致的过程如下:
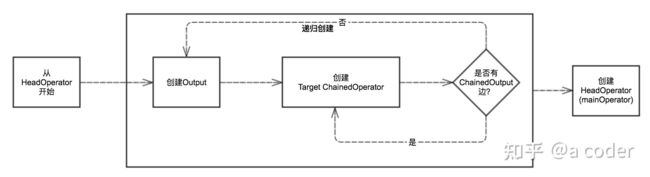
大致的过程就是,遍历需要Chain在一起的所有Operator,针对每一个判断其是否有输出到下一个Operator的边,如果有则去递归创建Operator,最终递归退出后,得到了一个可以递归指向所有Operator的Output,最后再拿这个Output去创建MainOperator 或者 老版本里面的HeadOperator,得到了大致如下的一个Chain,每个算子在执行完毕后,调用Output去collect,而Output的collect方法里面会去push给它的下一个Operator
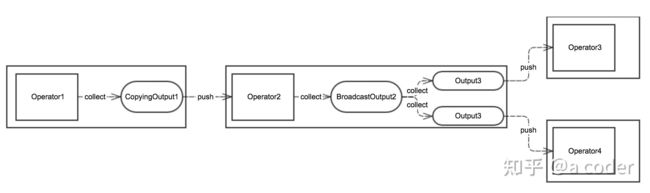
Output有几种实现,最常用的有CopyingChainingOutput,下面是其实现,可以看到每次在push给下一个Operator时,会先用序列化器执行一次深copy,数据量大的情况下应该会有性能的损耗,可以通过env.getConfig().enableObjectReuse()避免深copy。
final class CopyingChainingOutput extends ChainingOutput {
@Override
public void collect(StreamRecord record) {
if (this.outputTag != null) {
// we are not responsible for emitting to the main output.
return;
}
pushToOperator(record);
}
@Override
public void collect(OutputTag outputTag, StreamRecord record) {
if (this.outputTag == null || !this.outputTag.equals(outputTag)) {
// we are not responsible for emitting to the side-output specified by this
// OutputTag.
return;
}
pushToOperator(record);
}
@Override
protected void pushToOperator(StreamRecord record) {
try {
// we know that the given outputTag matches our OutputTag so the record
// must be of the type that our operator (and Serializer) expects.
@SuppressWarnings("unchecked")
StreamRecord castRecord = (StreamRecord) record;
numRecordsIn.inc();
StreamRecord copy = castRecord.copy(serializer.copy(castRecord.getValue()));
input.setKeyContextElement(copy);
input.processElement(copy);
} catch (ClassCastException e) {
if (outputTag != null) {
// Enrich error message
ClassCastException replace =
new ClassCastException(
String.format(
"%s. Failed to push OutputTag with id '%s' to operator. "
+ "This can occur when multiple OutputTags with different types "
+ "but identical names are being used.",
e.getMessage(), outputTag.getId()));
throw new ExceptionInChainedOperatorException(replace);
} else {
throw new ExceptionInChainedOperatorException(e);
}
} catch (Exception e) {
throw new ExceptionInChainedOperatorException(e);
}
}
} 最后还有一个问题,就是算子里面真正的数据处理逻辑(我们自己写的那些Function的类),是在什么时候构建的?
还记得我们上面的taskConfig里面有一个键值为"serializedUDF"的配置项吗?经过观察,Flink只是简单把我们写的那些Function类以及相关的Operator简单粗暴的序列化为Byte数组,然后塞到这个键里面,最后在TaskExecutor侧构建OperatorChain时,进行直接的反序列化。所以如果我们自己的开发的Function类里面,有不可序列化的变量,则会报异常:
StreamOperatorFactory operatorFactory =
configuration.getStreamOperatorFactory(userCodeClassloader);
public > T getStreamOperatorFactory(ClassLoader cl) {
try {
return InstantiationUtil.readObjectFromConfig(this.config, SERIALIZEDUDF, cl);
}
}
public static T readObjectFromConfig(Configuration config, String key, ClassLoader cl)
throws IOException, ClassNotFoundException {
byte[] bytes = config.getBytes(key, null);
if (bytes == null) {
return null;
}
return deserializeObject(bytes, cl);
}
总结一下牵扯到的这几个概念:
- Task:(AbstractInvokable,StreamTask,OneInputStreamTask) 是TaskExecutor的执行入口,通过反射的方法去构建,之后调用其invoke方法去执行。
- Processor: 负责给Task接收数据的类(StreamOneInputProcessor,StreamTwoInputProcessor),如果是SourceStreamTask的话逻辑不同,因为SourceStreamTask自己产生数据。其收到数据后,会传递给OperatorChain中的第一个Operator。
- OperatorChain:第一个Operator收到数据后,通过Output作为连接纽带,依次传给所有的Operator。
- Operator:Operator收到数据后,调用userFunction去进行数据处理,之后通过其Output传给下一个Operator,Operator的构建是简单粗暴的Java序列化/反序列化。
到这里,我们就了解了从TaskExecutor收到Task请求到执行的过程,接下来的文章,我们会分析从收到Dispatcher的job提交请求(submitJob(JobGraph jobGraph)),到提交任务Task到TaskExecutor第二个环节。
#Flink#