阿里云刘洋:基于eBPF的Kubernetes可观测最佳实践

嘉宾 | 刘洋
出品 | CSDN云原生
2022年8月9日,CSDN云原生系列在线峰会第15期“Prometheus峰会”上,阿里云技术专家刘洋为我们分享了基于eBPF的Kubernetes可观测最佳实践。
背景介绍
可观测是为了解决问题,在聊可观测之前应对问题排查的普适原则进行了解。
问题排查的原则
1、理解
以排查系统问题为例,首先需要理解系统以及基本的计算机科学知识,关注系统大图与运行细节,要对核心功能的算法和数据结构了然于心。
2、复现
在理解的基础上,还要能够复现问题,关注问题发生的触发条件并关注问题发生时数据现场的保留,包含指标、链路、日志、事件等。
3、定位
在保留现场信息以及理解系统的前提下,才可以定位问题。通过现场保留的数据可以进行关联分析,基于对系统的理解可以使用二分查找快速地定位根因。在定位的过程中,尤其要关注变更,大量系统问题都是由变更导致的。
4、修复
确定根因后再进行修复,既要治标也要治本,并且要充分验证,确保不引入新的问题。
以上为问题排查的普适原则,它不仅适用于系统问题的排查,也可以应用到生活的方方面面。
而可观测使得问题排查过程更加高效、稳定、低成本。可观测能够帮助我们理解系统,出现问题时保留更多的现场信息,使数据之间更加方便地关联,同时能够帮助我们做关联分析,最后验证修复是否正确。
Kubernetes可观测挑战
复杂度不断下沉的趋势使得可观测面临了很大的压力,Kubernetes的流行带来微服务架构的普及,多语言、多通信协议成为常态,这也在另一方面带来了挑战。
挑战 1:端到端观测复杂度上升,埋点成本居高不下,当前大量能力下沉到Kubernetes管控层、容器运行层、网络和操作系统层面,这些基础设施能力的下沉带来了很大挑战。
挑战 2:关注点的分离使得应用问题与底层问题无法自顶向下形成关联。
挑战 3:虽然工具数量众多,但上下文缺失、数据散落,导致我们无法通过这些数据很好地理解应用、现场的缺失,数据无法关联,使得问题排查效率低下。
因此,可观测需要有统一的技术来解决自身的复杂度。
基于eBPF的可观测实践分享
eBPF介绍
内核是可观测的绝佳位置,然而由于效率和安全问题一直无法实现。经过多年发展,eBPF技术为可观测打开了新的大门。
eBPF是一项可以安全地在内核中运行沙盒程序的技术,无需修改代码即可在内核用户态程序事件发生时运行,它具备4种特性。
- 无侵入:观测成本极低,应用无需修改任何代码,也无需重启进程。
- 动态可编程:无需重启探针,动态下发采集脚本。
- 高性能:自带JIT编译成Native代码,使探针能够获得内核本地运行的效率。
- 安全:Verifier机制限制eBPF脚本能够访问的内核函数,保证内核运行稳定。
除了这些特性外,eBPF的使用流程也非常方便。以监控应用性能为例,只需要加载编译eBPF程序监听网络的内核事件、解析网络协议,然后聚合成指标和Trace进行采集即可。
基于eBPF的统一可观测平台架构
eBPF得到了很多大公司的支持,发展十分迅猛。过去一年,阿里云可观测团队基于eBPF技术构建了统一可观测平台,其架构如下图所示。
自底向上分别是:数据采集层、数据处理层、数据存储层与数据服务层。
- 数据采集层:主要采用Tracepoints、Kprobre、eBPF函数抓取相关系统调用,关联进程容器信息,形成原始事件,并通过eBPF和Sysdig结合支持多内核版本。同时为了解决事件爆炸的问题,引入了事件过滤和高性能事件传输机制。
- 数据处理层:用户态获取到原始事件后,首先进行协议解析,生成指标、链路、日志等数据,这个过程中也会对信息做收敛。随后填充元信息,如K8s信息或自定义应用信息填充,最后监控数据会通过OpenTelemetry Collector输出。
- 数据存储层:默认情况下指标会使用influxDB存储在Prometheus,链路和日志使用SLS存储。
- 数据服务层:通过ARMS的前端以及Grafana呈现给用户多种多样的可观测服务。
如何进行无侵入式多语言的协议解析
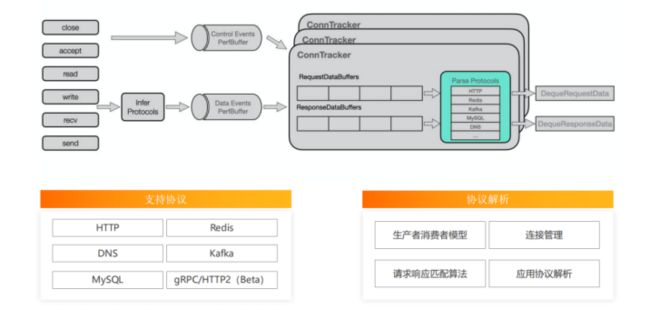
ARMS可观测团队关注eBPF在应用层的应用,通过监听网络内核调用、构建连接跟踪,将传输的网络包进行协议分析,得到应用层面的请求响应对,最终实现无侵入式地支持多语言场景下请求数、响应时间、错误数、黄金指标的监控。
线上问题与解决方法
在过去的生产实践中,我们遇到最多的问题主要有以下四个。
内核版本适配问题
eBPF在内核版本4.14以上才有较为成熟的支持,但线上依然存在很多老的内核版本,这部分我们使用Sysdig进行支持。高版本在CORE(Compile Once Run Everywhere)不成熟的情况下,使用动态下载内核头文件以及动态编译的方式进行支持。
内核事件爆炸
传统的监听Tracepoints、Kprobre会产生巨大的事件,给探针的性能造成巨大压力。为了解决这个问题,我们引入事件过滤机制,只处理网络调用事件,同时优化事件传输序列化,达到高性能事件传输的目的。
协议解析效率
为解决事件消费侧的协议解析效率低下问题,我们优化了高性能解析算法,如减少分析的字节数、优化匹配算法提升解析的效率,同时使用多线程、内存复用等工程手段提升协议解析效率。
指标时间线爆炸
所有事件最终都会聚合为指标、链路和日志,但指标个别维度的发散会对存储的稳定性造成极大的影响。为此,我们支持在写指标时进行维度收敛,如每个维度的基数不得超过100,超过后将被收敛成星号。
统一可观测交互界面
eBPF技术所具有的无侵入性与多语言支持的特性使得开箱即用成为了可能。基于此,阿里云可观测团队开始构建统一可观测界面。
统一告警
基于指标“开箱即用”的特点,我们设计了一套默认的告警模板,涵盖了应用层、K8s管控层、基础设施层和云服务层,提供了帮助用户快速发现问题的能力。
统一的关联分析逻辑
在eBPF保存现场数据且拥有告警提示的前提下,后续该如何统一进行关联分析、找到根因呢?
我们认为需要有一个界面来承载关联分析逻辑。
- 它应当目标明确,比如要解决容量规划问题、成本消耗问题还是应用性能问题。
- 它应当内容丰富,包含解决问题需要的所有内容,如指标、链路、日志、事件、问题的影响面、关联关系等。
- 它应当具备非常清晰的使用路径,能够回答当前是否有问题、未来是否有问题、问题的影响是什么、问题的根因是什么、用户能做什么等,以此一步步引导用户解决问题。
统一Grafana大盘
基于以上设想,我们推出了统一的Grafana大盘。它符合关联分析逻辑,无论是全局还是特定实体都有总览,能够发现、排查问题。它包含日志、事件、指标等多数据源,以告警异常阈值为驱动,整个大盘可以交互、跳转、定位根因,涵盖了K8s集群最核心的资源类型。
统一拓扑图
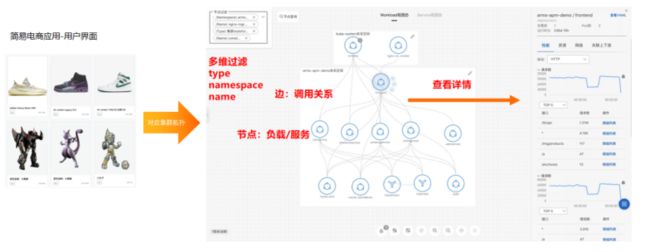
统一的拓扑大图具备拓扑感知、依赖分析、流量监控、上下文关联等特性,可以按维度筛选节点和边,构建业务语义化的视图。
Demo示例——基于eBPF的统一交互页面
在容器服务ACK进入一个集群后,点击运维管理,可以进入到集群拓扑功能页面,如下图所示。
若未安装eBPF探针,会提示安装,安装完成后便可开箱即用,可以获得整个集群的流量拓扑。页面中包含Deployment、Deamonset和Statfulset之间的流量关系,点击节点可以看到它对外提供的应用性能,也可以查看节点的上下游。通过上下游的查看,可以快速检查它是否按照预定的架构运行。
除了查看指标,还可以查看详情,如SQL语句及网络耗时、请求发到对端的时间、对端处理时间、响应内容的下载耗时等,这些信息可以帮助我们快速定位问题所在。同时还提供节点过滤的能力,能够快速过滤出用户感兴趣的节点。
Grafana统一的大盘为“1+N”的模式。“1”是指集群的全局大盘提供了整个集群最核心的资源总览,可以快速查看各类事件的个数及详情、节点与无状态应用Deployment是否健康以及有状态应用、Deamonset等。

每一个特定资源总览的结构是一致的,包含“总”和“分”。“总”是对整个集群进行概括的总结,可以快速通过阈值确认是否有问题,有问题的阈值会被高亮表示。如上图所示,可以看出有1个节点的CPU请求率过高,而具体哪一个节点的请求率过高,则由“分”负责查找,通过请求率排序,快速找到问题节点。
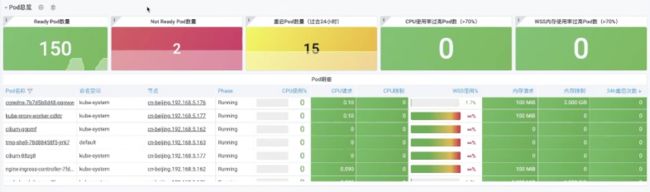
如上图所示,可以看到集群级别中有两个Pod不是Ready状态。通过对Phase进行排序,能够获取两个处于Pending状态的Pod。同时可以看到有15个Pod在过去24小时内存在重启行为,进行排序后也可以快速找到这些Pod。
前端应用的每一个Deployment或资源详情页也具备排查逻辑。概览中展示了管控层、CPU、网络、调度等情况,一眼便能知晓系统是否存在问题,可以快速查看问题所在。
总结与展望
阿里云可观测团队构建了Kubernetes统一监控,无侵入式地提供多语言、应用性能黄金指标,支持多种协议,结合Kubernetes管控层与网络系统层监控,提供全栈一体式的可观测体验。通过流量拓扑、链路、资源的关系,可进行关联分析,进一步提升在Kubernetes环境下排查问题的效率。
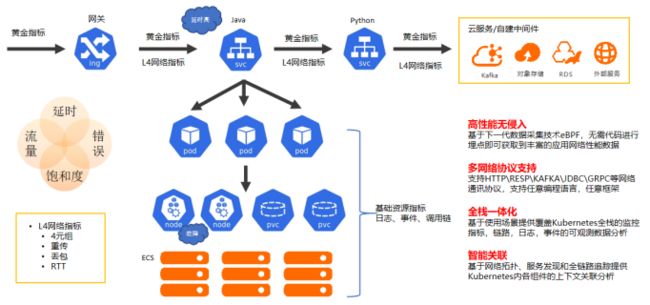
未来,阿里云可观测团队将进一步挖掘eBPF全覆盖、无侵入、可编程的特性,会在以下三个方面持续发力。
1、eAPM,围绕APM扩展边界,解决其侵入每种语言都需要单独埋点的问题以及在应用层面看不到的底层黑盒问题,主要包括几个方面:
- 无侵入式的多语言性能监控;
- 无侵入式的分布式链路追踪;
- 应用请求粒度的系统与网络分析。
2、提供工具,针对包括Tracing、Profiling以及内核事件在用户态进行处理的开发框架进行优化。
3、实现eBPF增强的内置指标、链路和日志,主要包括对应用协议的支持以及高阶的系统指标和网络指标。