mysql参数优化
#Max_connections
1)参数优化
Max_connections *****
Mysql的最大连接数,如果服务器并发请求量比较大,可以调高这个值(要建立在机器可以支撑的情况下,因为连接数越来越多,mysql会为每个连接提供缓冲区,就会消耗更多内存,所以不能随便的调高该值
最大连接数 show variables like ‘max_connections’;
响应的连接数 show status like ‘max_used_connections’;
查看响应的连接数:
max_used_connections / max_connections * 100% (理想值≈ 85%)
如果max_used_connections跟max_connections相同 那么就是max_connections设置过低或者超过服务器负载上限了,低于10%则设置过大。
max_used_connections数量就是当前连接数量。
MySQL的max_connections参数用来设置最大连接(用户)数。每个连接MySQL的用户均算作一个连接,max_connections的默认值为151。
与max_connections有关的特性
MySQL无论如何都会保留一个用于管理员(SUPER)登陆的连接,用于管理员连接数据库进行维护操作,即使当前连接数已经达到了max_connections。因此MySQL的实际最大可连接数为max_connections+1;
这个参数实际起作用的最大值(实际最大可连接数)为16384,即该参数最大值不能超过16384,即使超过也以16384为准;
增加max_connections参数的值,不会占用太多系统资源。系统资源(CPU、内存)的占用主要取决于查询的密度、效率等;
Threads_connected 跟show processlist结果相同,表示当前连接数。准确的来说,Threads_running是代表当前并发数
mysql> show variables like ‘max_connections’;
mysql> show status like ‘Max_used_connections’;
Vim /etc/my.cnf max_connections=1024
back_log
查看mysql 当前系统默认back_log值,命令:show variables like ‘back_log’;
判断依据:show full processlist
Vim /etc/my.cnf
Back_log=xxxx
back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。也就是说,如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。将会报:
unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时.
back_log值不能超过TCP/IP连接的侦听队列的大小。若超过则无效,查看当前系统的TCP/IP连接的侦听队列的大小命令:
cat /proc/sys/net/ipv4/tcp_max_syn_backlog,目前系统为1024。对于Linux系统推荐设置为大于512的整数。
修改系统内核参数,可以编辑/etc/sysctl.conf去调整它。如:net.ipv4.tcp_max_syn_backlog = 2048,改完后执行sysctl -p 让修改立即生效。
wait_timeout和interactive_timeout
wait_timeout – 指的是mysql在关闭一个非交互的连接之前所要等待的秒数
interactive_time – 指的是mysql在关闭一个交互的连接之前所要等待的秒数(交互连接如mysql gui tool中的连接)
wait_timeout:对性能的影响
(1)如果设置大小,那么连接关闭的很快,从而使一些持久的连接不起作用
(2)如果设置太大,容易造成连接打开时间过长,在show processlist时,能看到太多的sleep状态的连接,从而造成too many connections错误
(3)一般希望wait_timeout尽可能地低,(wait_timeout=120,interactive_timeout=1200)
说明:长连接的应用,为了不反复的分配和回收资源,降低额外开销,一般我们会将wait_timeout设定的比较小,interactive_timeout要和应用开发人员沟通长连接的应用是否很多,如果他们需要长连接,那么这个值不用修改
interactive_timeout的设置将要对你的web application没有多大的影响
key_buffer_size
mysql> show variables like “key_buffer_size%”;
1)myisam表的索引缓冲区 2)临时表缓冲区
mysql> show status like “created_tmp%”; created_tmp_tables/(created_tmp_disk_tables + created_tmp_tables) 越高越好
create_tmp_disk_tables/(created_tmp_disk_tables + created_tmp_tables) 控制在5% ~ 10%之间
计算基于内存的临时表的利用率,我们要关注creted_tmp_disk_tables是否过多,从而认定当前服务器运行的状态
Mysqldump可以产生大量临时表,导致利用率上升,但是可以忽略
sort_buffer_size (session独享)
1 Sort_Buffer_Size 是一个connection级参数,在每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。
2 Sort_Buffer_Size 并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。
3 文档说“On Linux, there are thresholds of 256KB and 2MB where larger values may significantly slow down memory allocation”
据说Sort_Buffer_Size 超过2KB的时候,就会使用mmap() 而不是 malloc() 来进行内存分配,导致效率降低。
max_allowed_packet
mysql> show VARIABLES like ‘%max_allowed_packet%’;
mysql根据配置文件会限制server接受的数据包大小。
有时候大的插入和更新会被max_allowed_packet 参数限制掉,导致失败,必须设置为1024的倍数
join_buffer_size(session独享)
Join Buffer 可被用于联接是ALL、index、和range的类型;每次联接使用一个Join Buffer,因此多表的联接可以使用多个Join Buffer;Join Buffer在联接发生之前进行分配,在SQL语句执行完后进行释放;Join Buffer只存储要进行查询操作的相关列数据,而不是整行的记录。
innodb_log_file_size
MySQL的InnoDB 存储引擎使用一个指定大小的Redo log空间(一个环形的数据结构)。Redo log的空间通过innodb_log_file_size和innodb_log_files_in_group(默认2)参数来调节。将这俩参数相乘即可得到总的可用Redo log 空间。尽管技术上并不关心你是通过innodb_log_file_size还是innodb_log_files_in_group来调整Redo log空间,不过多数情况下还是通过innodb_log_file_size 来调节。
为InnoDB引擎设置合适的Redo log空间对于写敏感的工作负载来说是非常重要的。然而,这项工作是要做出权衡的。你配置的Redo空间越大,InnoDB就能更好的优化写操作;然而,增大Redo空间也意味着更长的恢复时间当出现崩溃或掉电等意外时。
关于恢复时间,并不好预测对于一个指定的 innodb_log_file_size 值出现崩溃是需要多长的恢复时间–他取决于硬件能力、MySQL版本以及工作负载等因素。然而,一般情况下我们可以按照每1GB的Redo log的恢复时间大约在5分钟左右来估算。如果恢复时间对于你的使用环境来说很重要,我建议你做一些模拟测试,在正常工作负载下(预热完毕后)模拟系统崩溃,来评估更准确的恢复时间。
虽然恢复时间可以作为一个限制innodb_log_file_size的参考因素,也还有一些别的方式可以观察该参数设置是否“合理”(尤其是如果你安装了PMM: Percona Monitoring and Management)
read_buffer_size,read_rnd_buffer_size,bulk_insert_buffer_size
bulk_insert_buffer_size = n 为一次插入多条新记录的INSERT命令分配的缓存区长度(默认设置是8M)。
key_buffer_size = n 用来存放索引区块的RMA值(默认设置是8M)。
join_buffer_size = n 在参加JOIN操作的数据列没有索引时为JOIN操作分配的缓存区长度(默认设置是128K)。
max_heap_table_size = n HEAP数据表的最大长度(默认设置是16M); 超过这个长度的HEAP数据表将被存入一个临时文件而不是驻留在内存里。
max_connections = n MySQL服务器同时处理的数据库连接的最大数量(默认设置是100)。
query_cache_limit = n 允许临时存放在查询缓存区里的查询结果的最大长度(默认设置是1M)。
query_cache_size = n 查询缓存区的最大长度(默认设置是0,不开辟查询缓存区)。
query_cache_type = 0/1/2
查询缓存区的工作模式:0, 禁用查询缓存区; 1,启用查询缓存区(默认设置); 2,”按需分配”模式,只响应SELECT SQL_CACHE命令。
read_buffer_size = n
为从数据表顺序读取数据的读操作保留的缓存区的长度(默认设置是128KB); 这个选项的设置值在必要时可以用SQL命令SET SESSION read_buffer_size = n命令加以改变。
read_rnd_buffer_size = n
类似于read_buffer_size选项,但针对的是按某种特定顺序(比如使用了ORDER BY子句的查询)输出的查询结果(默认设置是256K)。
sort_buffer = n 为排序操作分配的缓存区的长度(默认设置是2M); 如果这个缓存区太小,则必须创建一个临时文件来进行排序。
table_cache = n 同时打开的数据表的数量(默认设置是64)。
tmp_table_size = n
临时HEAP数据表的最大长度(默认设置是32M); 超过这个长度的临时数据表将被转换为MyISAM数据表并存入一个临时文件。
thread_cache_size
show global status like ‘Thread%’;
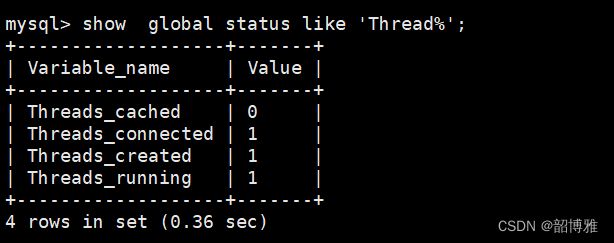
threads_cache:代表当前线程缓存中有多少空闲线程
Threads_connected:当前被使用的线程数
Threads_created:代表子服务器启动,创建过的线程数,如果发现Threads_created值过大的话,表明MySQL服务器一直在创建线程,这也是比较耗资源,可以适当增加配置文件中thread_cache_size值
Threads_running:代表非休眠线程的数量,而非正在使用的线程数量
thread_cache_size
thread_cache_size:当客户端断开之后,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未达上限)
即可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,增加这个值可以改善系统性能。
thread_cache_size大小的设置:
如果是短连接,适当设置大一点,因为短连接往往需要不停创建,不停销毁,如果大一点,连接线程都处于取用状态,不需要重新创建和销毁,所以对性能肯定是比较大的提升。
对于长连接,不能保证连接的稳定性,所以设置这参数还是有一定必要,可能连接池的问题,会导致连接数据库的不稳定性,也会出现频繁的创建和销毁,但这个情况比较少,如果是长连接,可以设置成小一点,一般在50-100左右。
查询thread_cache_size设置
show global status like’thread_cache_size’;
优化方法:
1、mysql> set global thread_cache_size=16
2、编辑/etc/my.cnf 更改/添加
thread_concurrency = 16
3、mysql kill线程
mysqladmin start slave stop slave kill某个连接到mysqlServer的线程