Pandas学习(三)——索引器
3.1.1、DF的列索引
单列索引用df[col_name]或df.col_name或df[[col_name]],前两者返回Series,后者返回DF(DataFrame);
多列索引用df[[col_name1,col_name2,col_name3]],返回DF
dict1 = {'Name':['Mike','Lily','Jasmine','Hobo','Eddie'],
'Age':[21,8,21,8,10],'Sex':['M','F','M','Unknown','M'],
'Class':[2,1,2,3,3],
'Score':['8',89,100,99,96],'Grade':['A','B','S','A','A']}
df = pd.DataFrame(dict1,index=['stu'+str(i) for i in range(1,6)])
print(df['Name'],df['Name'].__class__)
# stu1 Mike
# stu2 Lily
# stu3 Jasmine
# stu4 Hobo
# stu5 Eddie
# Name: Name, dtype: object 3.1.2、Series的行索引
- 字符索引
单行索引用s[row_name],多行索引用s[[row_name1, row_name2, row_name3]] - 整数索引
同字符索引
如果是切片法,则是取出对应位置(从零开始)的值,并且包含两个端点。(我已经有点晕了=_=)
>>>s = pd.Series(['a', 'b', 'c', 'd', 'e', 'f'],index=[1, 3, 1, 2, 5, 4])
>>>s[1:-1:2]
3 b
2 d
dtype: object
>>>s[[1,3]]
1 a
1 c
3 b
dtype: object

一般我就用默认行索引(0,1,2,3……),列索引用字符串,应该不会有这种麻烦吧。。
3.1.3、loc索引器
对于DF如果不用索引器,必须采用切片法索引(即使单行也必须切片索引)
>>>df[0:1]
Name Age Sex Class Score Grade
stu1 Mike 21 M 2 8 A
>>>df[0]
KeyError: 0
这就是麻烦的地方,相对来说iloc或者loc索引器就很灵活很user-friendly,所以一般对DF无论是列索引还是行索引我都喜欢用iloc或者loc。这两个的区别在于“一种是基于元素的loc 索引器,另一种是基于位置的iloc 索引器”。

- *为单个元素
- *为列表
>>>df = df.set_index('Name')
>>>df
Age Sex Class Score Grade
Name
Mike 21 M 2 8 A
Lily 8 F 1 89 B
Jasmine 21 M 2 100 S
Hobo 8 Unknown 3 99 A
Eddie 10 M 3 96 A
>>>df.loc[['Mike','Jasmine'],['Score','Grade']]
Score Grade
Name
Mike 8 A
Jasmine 100 S
取值图解:

- *是切片,则包含两个端点,不允许有重复索引(一般不会吧)
- *是布尔列表,如果是复合条件,需用逻辑操作符
| & ~,分别代表或/且/非。
P.S. 这里不能用and或or或not,因为它们只能对单个bool变量操作

如果不是像教程里一样先把条件赋给condition,则一定要在loc中把条件用()括起来,否则报错
>>>df.loc[(df['Age']==21) & (df['Grade']=='A')] # 有括号
Age Sex Class Score Grade
Name
Mike 21 M 2 8 A
>>>df.loc[df['Age']==21 & df['Grade']=='A'] # 无括号
TypeError: Cannot perform 'rand_' with a dtyped [object] array and scalar of type [bool]
select_dtypes可以选出指定类型的列:
>>>df.dtypes # 先查看一下各列类型
Age int64
Sex object
Class int64
Score int64
Grade object
dtype: object
>>>df.select_dtypes('int64') # 使用select_dtypes方法选出int64的列
Age Class Score
Name
Mike 21 2 8
Lily 8 1 89
Jasmine 21 2 100
Hobo 8 3 99
Eddie 10 3 96
>>>df.loc[:,df.dtypes=='int64'] # 也可以用布尔索引结合loc方法
Age Class Score
Name
Mike 21 2 8
Lily 8 1 89
Jasmine 21 2 100
Hobo 8 3 99
Eddie 10 3 96
- *为函数,这个看起来就很复杂了
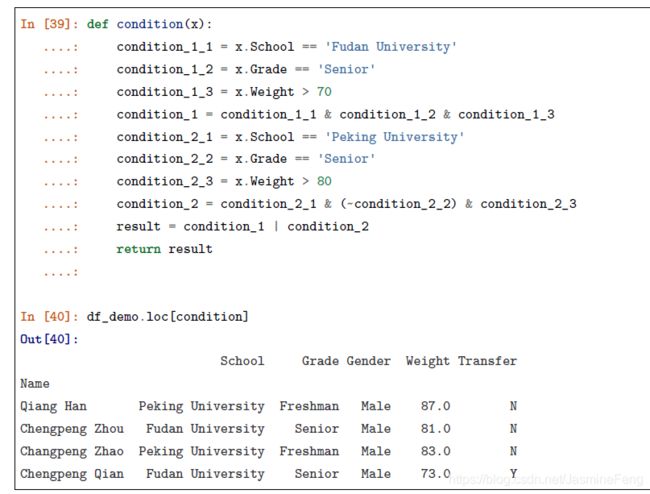
下面这个感觉完全没必要用lambda表达式,可能只是为了说明用法吧

NOTICE: 尽量不要使用链式索引,否则会弹warning,以前我不知道为啥,今天看了教程我终于明白了,下面展示一个自己的例子。
>>>df.loc[df['Age']==21] # 查看年龄21岁的学生的信息
Age Sex Class Score Grade
Name
Mike 21 M 2 8 A
Jasmine 21 M 2 100 S
>>>df.loc[df['Age']==21]['Score'] = 99 # 让这类学生的成绩为99
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
“一个值尝试被赋给一个DF切片的copy”,如果是赋给copy的话,那么是不共享地址的,也就是说原df的值没变,我们打印一下现在的df看看是不是这样。
>>>df
Age Sex Class Score Grade
Name
Mike 21 M 2 8 A
Lily 8 F 1 89 B
Jasmine 21 M 2 100 S
Hobo 8 Unknown 3 99 A
Eddie 10 M 3 96 A
果然,原来8分的现在还是8分,100分的还是100分。我们用warning中推荐的方法来再次赋值。
>>>df.loc[df['Age']==21,'Score'] = 99
>>>df
Age Sex Class Score Grade
Name
Mike 21 M 2 99 A
Lily 8 F 1 89 B
Jasmine 21 M 2 99 S
Hobo 8 Unknown 3 99 A
Eddie 10 M 3 96 A
现在就改变了,所以不推荐用链式索引,就是这个道理。
3.1.4、iloc索引器

iloc与布尔索引结合时,*只能是用Series的values,学到这里我好像突然明白为什么今天早晨写的一行代码运行不了了。

3.1.5、query方法

query可以缩短复杂布尔索引的代码长度。上面这个索引如果不用query方法的话,就用必须df[(df[col_name1]==val1) & (df[col)_name2]==val2) & (df[col_name3]>=val3)]这种格式,如果DF的名字不是df这么短的话可想而知代码会有多长。
P.S.
- 对于含有空格的列名,需要使用
col name的方式进行引用。 and,or``not和&,|,~可以换用- 对于between方法,要指定
engine=python - query的条件放在单引号内,如果判断涉及字符串,字符串应放在双引号内
>>>df.query('Age.between(8,22,inclusive=False)',engine='python')
Name Age Score Grade
Sex Class
M 2 Mike 21 8 A
2 Jasmine 21 100 S
F 3 Lily 10 99 A
>>>df.rename(columns={'Score':'Final score'},inplace=True)
df
Age Sex Class Final score Grade
Name
Mike 21 M 2 8 A
Lily 8 F 1 89 B
Jasmine 21 M 2 100 S
Hobo 8 Unknown 3 99 A
Eddie 10 M 3 96 A
>>>df.query('Age>8 and `Final score`>90')
Age Sex Class Final score Grade
Name
Jasmine 21 M 2 100 S
Eddie 10 M 3 96 A
-----------------------------------------------
今天才知道原来这个`符号不是单引号啊。。。我还输了半天单引号说怎么总报错啊
-----------------------------------------------
3.1.6、随机抽样
随机抽样可以在面对大数据集时从随机的行/列中抽样。
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)

这是来自官方文档的解释。
- n指定抽样数量
- frac指定抽样比例
- replace指定是否放回
- weights指定各样本被抽取到的概率
- random_state设定随机数种子
- axis为1则抽取列,为0则抽取行
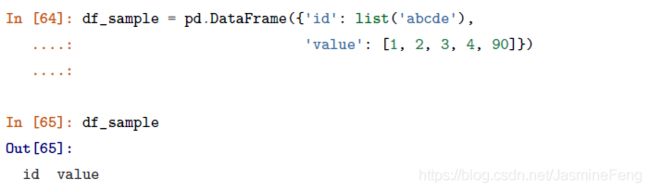

在教程所提供的例子中,设value一列为各样本被抽到的概率,由于e的概率达到了90%,且为有放回抽样,故抽样结果全部为e。
3.2.1、多级索引及其表的结构
为了下文说明方便,仿照教程重新创建一个DF。
>>>multi_index = pd.MultiIndex.from_product([['M','F','Unknown'],[1,2,3]],names=['Sex','Class'])
>>>multi_col = pd.MultiIndex.from_product([['Mid-term','Final'],['CN','UK','JP']],names=['score','Nationality'])
>>>df_multi = pd.DataFrame(np.random.randn(9,6)*5+80,index=multi_index,columns=multi_col).round()
>>>df_multi
score Mid-term Final
Nationality CN UK JP CN UK JP
Sex Class
M 1 81.0 77.0 80.0 89.0 81.0 82.0
2 83.0 82.0 76.0 72.0 80.0 82.0
3 81.0 75.0 77.0 79.0 72.0 79.0
F 1 74.0 86.0 80.0 89.0 81.0 83.0
2 86.0 80.0 77.0 79.0 82.0 83.0
3 88.0 75.0 75.0 82.0 77.0 80.0
Unknown 1 79.0 66.0 83.0 80.0 86.0 85.0
2 75.0 80.0 69.0 83.0 85.0 76.0
3 69.0 85.0 74.0 80.0 80.0 77.0
通过index和columns可以分别访问行、列索引。
通过这两个实例的get_level_values可以访问某一层的索引。
>>>df_multi.index
MultiIndex([( 'M', 1),
( 'M', 2),
( 'M', 3),
( 'F', 1),
( 'F', 2),
( 'F', 3),
('Unknown', 1),
('Unknown', 2),
('Unknown', 3)],
names=['Sex', 'Class'])
>>>df_multi.columns
MultiIndex([('Mid-term', 'CN'),
('Mid-term', 'UK'),
('Mid-term', 'JP'),
( 'Final', 'CN'),
( 'Final', 'UK'),
( 'Final', 'JP')],
names=['score', 'Nationality'])
>>>df_multi.index.get_level_values(1)
Int64Index([1, 2, 3, 1, 2, 3, 1, 2, 3], dtype='int64', name='Class') # 第1层行索引
对于多级索引需要用元组来代替元素。
>>>df_multi.loc[('M',2),'Mid-term']
Nationality
CN 83.0
UK 82.0
JP 76.0
Name: (M, 2), dtype: float64
布尔索引也可以使用:
>>>df_multi.loc[:,('Final','CN')].loc[df_multi['Final','CN']>80]
Sex Class
M 1 89.0
F 1 89.0
3 82.0
Unknown 2 83.0
Name: (Final, CN), dtype: float64
取多行/多列(交叉组合):
# 一班和二班的男性与未知性别中国同学
>>>df_multi.loc[(['M','Unknown'],[1,2]),(['Final','Mid-term'],'CN')]
score Mid-term Final
Nationality CN CN
Sex Class
M 1 81.0 89.0
2 83.0 72.0
Unknown 1 79.0 80.0
2 75.0 83.0
# 一班的男同学和二班的未知性别中国同学
>>>df_multi.loc[[('M',1),('Unknown',2)],(['Final','Mid-term'],'CN')]
score Mid-term Final
Nationality CN CN
Sex Class
M 1 81.0 89.0
Unknown 2 75.0 83.0

3.2.3、IndexSlice对象
使用这个对象切片前建议先索引排序!先索引排序!先索引排序!P.S. 行索引和列索引都排一下,我一开始只排了行索引,结果还是报错。
>>>df_multi.sort_index(inplace=True)
>>>df_multi.sort_index(axis=1, inplace=True)
>>>df_multi
score Final Mid-term
Nationality CN JP UK CN JP UK
Sex Class
F 1 74.0 77.0 82.0 84.0 86.0 81.0
2 80.0 85.0 74.0 76.0 78.0 77.0
3 89.0 79.0 86.0 82.0 87.0 72.0
M 1 82.0 82.0 80.0 77.0 80.0 74.0
2 78.0 71.0 76.0 77.0 77.0 78.0
3 82.0 80.0 75.0 81.0 72.0 78.0
Unknown 1 86.0 85.0 81.0 75.0 78.0 85.0
2 89.0 82.0 81.0 82.0 80.0 84.0
3 85.0 90.0 74.0 89.0 74.0 73.0
>>>idx = pd.IndexSlice # 定义一个IndexSlice
loc[idx[*,*]]用法,前一个*代表行的选择,后一个*代表列的选择。
现在取出行中从Unknown开始往下的、从Mid-term且UK一列往右的部分
>>>df_multi.loc[idx['Unknown':, ('Mid-term', 'JP'):]]
score Mid-term
Nationality JP UK
Sex Class
Unknown 1 78.0 85.0
2 80.0 84.0
3 74.0 73.0

我一开始看到这个布尔索引没看懂,理由是圈出来的这一列的和显然不大于零,后来我才明白,它算的是一整列的和,而这边只取了一整列中’A’及其之前的部分。
如果要取出前三行大于零的列也是可以的。
>>>df_ex.loc[idx[:'A', lambda x:x[:3].sum()>0]]
Big D E F
Small e f e
Upper Lower
A a 6 -2 9
b 3 5 -4
c 0 6 9
-
loc[idx[*,*], idx[*,*]]用法这种是最灵活的用法,可以对每层分别切片。
>>>df_multi.loc[idx['M':,:2],idx['Mid-term',:'JP']]
score Mid-term
Nationality CN JP
Sex Class
M 1 83.0 71.0
2 89.0 78.0
Unknown 1 81.0 82.0
2 81.0 77.0
3.2.4、多级索引的构造
除了set_index方法,常用的还有from_tuples, from_arrays, from_product。
- from_tuples, from_arrays


这两种方法传入的参数具有压缩与解压的关系。
>>>for x, y in zip(list('aabb'),['cat','dog']*2):
>>> print(x,y)
a cat
a dog
b cat
b dog
- from_product 通过作列表之间的笛卡尔积返回多重索引,索引的个数为个列表元素之积,比如下面每个列表中分别有3、2、4个元素,那么MultiIndex对象就共有 3 × 2 × 4 = 24 3\times2\times4=24 3×2×4=24个索引。
>>>multi_idx = pd.MultiIndex.from_product([list('abc'),[2,3],list('WXYZ')],names=['lower','number','upper'])
MultiIndex([('a', 2, 'W'),
('a', 2, 'X'),
('a', 2, 'Y'),
...
('c', 3, 'X'),
('c', 3, 'Y'),
('c', 3, 'Z')],
names=['lower', 'number', 'upper'])
>>>multi_idx.shape
(24,)
3.3.1、索引层的交换与删除
- 交换 (下面两种交换方法
axis=1交换列索引,axis=0交换行索引)
- swaplevel只能交换两层,以下是来自教程的例子
>>>L1,L2,L3 = ['A','B'],['a','b'],['alpha','beta']
>>>mul_index1 = pd.MultiIndex.from_product([L1,L2,L3],
>>>names=('Upper', 'Lower','Extra'))
>>>L4,L5,L6 = ['C','D'],['c','d'],['cat','dog']
>>>mul_index2 = pd.MultiIndex.from_product([L4,L5,L6],
>>>names=('Big', 'Small', 'Other'))
>>>df_ex = pd.DataFrame(np.random.randint(-9,10,(8,8)),index=mul_index1,columns=mul_index2)
>>>df
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
Upper Lower Extra
A a alpha -7 -9 5 -9 5 4 4 5
beta -9 6 -1 1 5 -7 3 -4
b alpha -4 -8 1 -2 1 6 2 5
beta 4 7 9 4 -8 4 -3 -6
B a alpha 3 6 -3 5 5 -6 -6 -8
beta 2 -8 5 -4 5 8 9 4
b alpha 4 -2 8 4 0 8 -3 -9
beta 8 -9 -8 -3 8 -9 -4 4
>>>df_ex.swaplevel(2,0,axis=1)
>>>df
Other cat dog cat dog cat dog cat dog
Small c c d d c c d d
Big C C C C D D D D
Upper Lower Extra
A a alpha -7 -9 5 -9 5 4 4 5
beta -9 6 -1 1 5 -7 3 -4
b alpha -4 -8 1 -2 1 6 2 5
beta 4 7 9 4 -8 4 -3 -6
B a alpha 3 6 -3 5 5 -6 -6 -8
beta 2 -8 5 -4 5 8 9 4
b alpha 4 -2 8 4 0 8 -3 -9
beta 8 -9 -8 -3 8 -9 -4 4
- reorder_levels从名字也可看出,这边level用了复数形式,所以它可以交换两个或两个以上的层
>>>df_ex.reorder_levels([0,2,1]) # axis缺省时交换行索引
Big C D
Small c d c d
Other cat dog cat dog cat dog cat dog
Upper Extra Lower
A alpha a -7 -9 5 -9 5 4 4 5
beta a -9 6 -1 1 5 -7 3 -4
alpha b -4 -8 1 -2 1 6 2 5
beta b 4 7 9 4 -8 4 -3 -6
B alpha a 3 6 -3 5 5 -6 -6 -8
beta a 2 -8 5 -4 5 8 9 4
alpha b 4 -2 8 4 0 8 -3 -9
beta b 8 -9 -8 -3 8 -9 -4 4
- 删除——droplevel方法
df.droplevel(level, axis=0)

以上来自官方文档。
- level指定要删除的索引,可以是整数,也可是列表,如果是列表就代表要删除的一堆索引;
- axis=1删除列索引,axis=0删除行索引,缺省值为0。
3.3.2、索引属性的修改
- 索引层名字的修改——rename_axis方法
原来的DF中score首字母没有大写,Class表示班级。
>>>df_multi
score Final Mid-term
Nationality CN JP UK CN JP UK
Sex Class
F 1 88.0 86.0 77.0 72.0 77.0 85.0
2 77.0 91.0 82.0 83.0 84.0 77.0
3 80.0 83.0 80.0 88.0 78.0 79.0
M 1 75.0 78.0 83.0 83.0 71.0 76.0
2 74.0 75.0 82.0 89.0 78.0 89.0
3 82.0 74.0 85.0 90.0 83.0 79.0
Unknown 1 78.0 83.0 79.0 81.0 82.0 74.0
2 79.0 81.0 82.0 81.0 77.0 84.0
3 76.0 82.0 87.0 76.0 81.0 80.0
现在让score首字母大写,Class变成Grade年级:
>>>df_multi.rename_axis({'score':'Score','Class':'Grade'})
Score Final Mid-term
Nationality CN JP UK CN JP UK
Sex Grade
F 1 88.0 86.0 77.0 72.0 77.0 85.0
2 77.0 91.0 82.0 83.0 84.0 77.0
3 80.0 83.0 80.0 88.0 78.0 79.0
M 1 75.0 78.0 83.0 83.0 71.0 76.0
2 74.0 75.0 82.0 89.0 78.0 89.0
3 82.0 74.0 85.0 90.0 83.0 79.0
Unknown 1 78.0 83.0 79.0 81.0 82.0 74.0
2 79.0 81.0 82.0 81.0 77.0 84.0
3 76.0 82.0 87.0 76.0 81.0 80.0
- 对索引值的修改——rename方法
“如果是多级索引需要指定修改的层号level”
现在把性别中的F和M改成全称:
>>>df_multi.rename(index={'F':'Female','M':'Male'},level=0)
score Final Mid-term
Nationality CN JP UK CN JP UK
Sex Class
Female 1 88.0 86.0 77.0 72.0 77.0 85.0
2 77.0 91.0 82.0 83.0 84.0 77.0
3 80.0 83.0 80.0 88.0 78.0 79.0
Male 1 75.0 78.0 83.0 83.0 71.0 76.0
2 74.0 75.0 82.0 89.0 78.0 89.0
3 82.0 74.0 85.0 90.0 83.0 79.0
Unknown 1 78.0 83.0 79.0 81.0 82.0 74.0
2 79.0 81.0 82.0 81.0 77.0 84.0
3 76.0 82.0 87.0 76.0 81.0 80.0
这两个修改索引名与索引值的方法也可以传入函数作为参数。
现在把行的索引名全部改成小写,列的索引名全部改成大写:
>>>df_multi.rename_axis(columns=lambda x:x.upper(),index=lambda x:x.lower())
SCORE Final Mid-term
NATIONALITY CN JP UK CN JP UK
sex class
F 1 88.0 86.0 77.0 72.0 77.0 85.0
2 77.0 91.0 82.0 83.0 84.0 77.0
3 80.0 83.0 80.0 88.0 78.0 79.0
M 1 75.0 78.0 83.0 83.0 71.0 76.0
2 74.0 75.0 82.0 89.0 78.0 89.0
3 82.0 74.0 85.0 90.0 83.0 79.0
Unknown 1 78.0 83.0 79.0 81.0 82.0 74.0
2 79.0 81.0 82.0 81.0 77.0 84.0
3 76.0 82.0 87.0 76.0 81.0 80.0
如果要替换全部的索引值,可以用迭代器实现。
>>>new_idx = iter(list('987654321'))
>>>df_multi.rename(index=lambda x:next(new_idx), level=1, inplace=True)
>>>df_multi
score Final Mid-term
Nationality CN JP UK CN JP UK
Sex Class
F 9 88.0 86.0 77.0 72.0 77.0 85.0
8 77.0 91.0 82.0 83.0 84.0 77.0
7 80.0 83.0 80.0 88.0 78.0 79.0
M 6 75.0 78.0 83.0 83.0 71.0 76.0
5 74.0 75.0 82.0 89.0 78.0 89.0
4 82.0 74.0 85.0 90.0 83.0 79.0
Unknown 3 78.0 83.0 79.0 81.0 82.0 74.0
2 79.0 81.0 82.0 81.0 77.0 84.0
1 76.0 82.0 87.0 76.0 81.0 80.0
- 对索引值的修改——map函数
- map函数和rename函数的区别在于前者可以统一修改不同层的索引值,而后者只能指定某一层(level)。
下面把性别全部改成小写, 新 的 班 级 编 号 = 10 − 原 班 级 编 号 新的班级编号=10-原班级编号 新的班级编号=10−原班级编号
>>>new_idx = df_multi.index.map(x[0].lower(),str(10-int(x[1])))
>>>df_multi.index = new_idx
>>>df_multi
score Final Mid-term
Nationality CN JP UK CN JP UK
Sex Class
f 1 88.0 86.0 77.0 72.0 77.0 85.0
2 77.0 91.0 82.0 83.0 84.0 77.0
3 80.0 83.0 80.0 88.0 78.0 79.0
m 4 75.0 78.0 83.0 83.0 71.0 76.0
5 74.0 75.0 82.0 89.0 78.0 89.0
6 82.0 74.0 85.0 90.0 83.0 79.0
unknown 7 78.0 83.0 79.0 81.0 82.0 74.0
8 79.0 81.0 82.0 81.0 77.0 84.0
9 76.0 82.0 87.0 76.0 81.0 80.0
- map函数还可以用于多级索引的压缩与反向展开。
>>>df_multi.index = df_multi.index.map(lambda x:x[0]+x[1])
>>>df_multi
score Final Mid-term
Nationality CN JP UK CN JP UK
f1 88.0 86.0 77.0 72.0 77.0 85.0
f2 77.0 91.0 82.0 83.0 84.0 77.0
f3 80.0 83.0 80.0 88.0 78.0 79.0
m4 75.0 78.0 83.0 83.0 71.0 76.0
m5 74.0 75.0 82.0 89.0 78.0 89.0
m6 82.0 74.0 85.0 90.0 83.0 79.0
unknown7 78.0 83.0 79.0 81.0 82.0 74.0
unknown8 79.0 81.0 82.0 81.0 77.0 84.0
unknown9 76.0 82.0 87.0 76.0 81.0 80.0
>>>df_multi.index = df_multi.index.map(lambda x:(x[:-1],x[-1]))
>>>df_multi
score Final Mid-term
Nationality CN JP UK CN JP UK
f 1 88.0 86.0 77.0 72.0 77.0 85.0
2 77.0 91.0 82.0 83.0 84.0 77.0
3 80.0 83.0 80.0 88.0 78.0 79.0
m 4 75.0 78.0 83.0 83.0 71.0 76.0
5 74.0 75.0 82.0 89.0 78.0 89.0
6 82.0 74.0 85.0 90.0 83.0 79.0
unknown 7 78.0 83.0 79.0 81.0 82.0 74.0
8 79.0 81.0 82.0 81.0 77.0 84.0
9 76.0 82.0 87.0 76.0 81.0 80.0
3.3.3、索引的设置与重置
- 索引的设置——set_index方法
前面没有对set_index方法细讲,其实它有个重要的参数append,如果append为真,那么“保留原来的索引,直接把新设定的添加到原索引的内层”:

- 索引的重置——reset_index方法
如果对设置的索引不满意又不想直接删掉它,可以用这个方法,并且设置drop=False(不设置也行,因为缺省值就是False)。反之,如果设为True,那就是真的扔掉了。

3.3.4、索引的变形
- reindex方法
该方法适用的场合是“给定一个新的索引,把原表中相应的索引对应元素填充到新索引构成的表中”。

由于Gender列和1004行原来不在表中,所以加入后对应元素为缺失值。 - reindex_like方法
该方法跟numpy中的np.ones_like和np.zeros_like一类的函数比较像,构造出的表与原表使用同样地索引,形状也相同。
3.4.1、集合的运算法则
四种运算分别是交、并、差、对等差。

3.4.2、一般的索引运算
运算用到的方法与上图中对应的英文一致。
>>>id1 = pd.Index(['a','b','c'])
>>>id2 = pd.Index(['b','c','d','e'])
>>>id1.intersection(id2)
Index(['b', 'c'], dtype='object')
>>>id1.union(id2)
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
>>>id1.difference(id2)
Index(['a'], dtype='object')
>>>id1.symmetric_difference(id2)
Index(['a', 'd', 'e'], dtype='object')
P.S.交、并、对等差的运算还可以通过符号&,|,^来实现,如果求差,那么因为
S A − S B = ( S A △ S B ) ∩ S A \mathrm{S}_A-\mathrm{S}_B=(\mathrm{S}_A\triangle\mathrm{S}_B)\cap\mathrm{S}_A SA−SB=(SA△SB)∩SA
故(id1^id2)&id1可以等价实现id1与id2的差集。
“若两张表需要做集合运算的列并没有被设置索引,一种办法是先转成索引,运算后再恢复,另一种方法是利用isin函数”。第二种方法也就是进行布尔运算取值。
个人觉得但是第二种方法好像有局限性,在于取交集很方便,但作其他运算相对麻烦点,大概要做取反什么的,可能脑子转不过弯来。
还是先set_index再reset_index比较好,代码也具有可读性~
----------------------------------
今天学了至少6个小时,不愧是我! 2020-12-21 22:33
----------------------------------
练习
3.5.1、公司员工数据集
![]()
>>>query1 = df.query('age<=40 and department.isin(["Dairy", "Bakery"]) and gender=="M"', engine='python')
>>>query2 = df.loc[(df['age'] <= 40) & (df['department'].isin(['Dairy', 'Bakery'])) & (df['gender'] == 'M'), :]
>>>print((query1.index == query2.index).all())
True
query方法中用isin或in均可,前者要带上engine='python',loc方法貌似只能用isin,用in就报错。。。另外三个字符串Dairy,Bakery,M必须放在双引号内。
![]()
现在发现query方法特别好用嘿嘿!
>>>query3 = df.query('EmployeeID % 2 == 1').iloc[:,[1,3,-2]]
>>>print(query3)
birthdate_key city_name job_title
1 1/3/1957 Vancouver VP Stores
3 1/2/1959 Vancouver VP Human Resources
5 1/9/1962 Vancouver Exec Assistant, VP Stores
6 1/13/1964 Vancouver Exec Assistant, Legal Counsel
8 1/23/1967 Terrace Store Manager
... ... ... ...
6276 9/28/1989 Trail Cashier
6277 4/7/1990 Nanaimo Cashier
6278 10/18/1990 Abbotsford Dairy Person
6280 9/26/1993 Prince George Cashier
6281 2/11/1994 Trail Cashier
[3126 rows x 3 columns]
这个地方答案取了第0列、第2列和倒数第2列,可能因为实际生活中的第1个指的就是许多编程语言中的第0个,但是按照我的习惯,第0个就是第0个,这是为了避免我自己产生混淆(之前的博客中也经常说axis=0是在第0个维度上),所以我取了第1列、第3列、倒数第2列。其实问题不大~

df1 = df.set_index(['department', 'job_title', 'gender']).swaplevel(0, 2) # 把后三列设为索引后交换内外两层
df1 = df1.reset_index('job_title', drop=False) # 恢复中间一层
df1.rename_axis(index={'gender': 'Gender'}, inplace=True) # 修改外层索引名为Gender
new_idx = df1.index.map(lambda x: x[0] + '_' + x[1])
df1.index = new_idx # 用下划线合并两层行索引
original_idx = df1.index.map(lambda x:tuple(x.split('_')))
df1.index = original_idx # 把行索引拆分为原状态
df1.rename_axis(index=['gender','department'],inplace=True) # 修改索引名为原表名称
df1 = df1.reset_index() # 恢复默认索引
col0 = list(df.columns) # 获取原表列的相对位置
df2 = df1.loc[:,col0] # 将列保持为原表的相对位置
print(df2)

答案中
- 取最后三列用的是
df.columns[-3:].tolist(),这么做更简洁一点,就不用一个个输字符串了 - 添加下划线用了字符串的
join方法,即'_'.join(x),在字符串较长的时候这种方法是很省事的 - 把列排成原表中的相对位置用了
reindex方法,比我的loc方法更高级一些,说明我reindex掌握得还不够熟练啊! - 用
df.equals(df2)可以判断两个表是否相同
3.5.2、巧克力数据集

可以考虑使用rename或map方法,前者更直接一些。
>>>df = pd.read_csv('E:\\DataWhale组队学习\\data\\chocolate.csv')
>>>df1 = df.rename(columns=lambda x:x.replace('\n',' '))
>>>df2 = df.copy()
>>>df2.columns = df.columns.map(lambda x:x.replace('\n',' '))
>>>print(df2.head())
Company Review Date Cocoa Percent Company Location Rating
0 A. Morin 2016 63% France 3.75
1 A. Morin 2015 70% France 2.75
2 A. Morin 2015 70% France 3.00
3 A. Morin 2015 70% France 3.50
4 A. Morin 2015 70% France 3.50
>>>print(df1.equals(df2))
True
![]()
我发现这个Cocoa Percent这一栏竟然是字符型的,没法求中位数,所以我用了apply方法先转成浮点数,转的时候发现也不能直接转,因为百分号没法转。。。所以只取了前两个字符,坑真多啊!
(答案更合理一些,取倒数第一个字符前的所有字符,因为可能是小数)
>>>df1.loc[:, 'Cocoa Percent'] = df1.loc[:, 'Cocoa Percent'].apply(lambda x: float(x[:2]) / 100)
>>>cocoa_median = df1['Cocoa Percent'].median()
>>>print(cocoa_median)
0.7
>>>query1 = df1.query('Rating<2.75 and `Cocoa Percent`>@cocoa_median')
>>>print(query1.head())
Company Review Date Cocoa Percent Company Location Rating
38 Alain Ducasse 2013 0.75 France 2.50
39 Alain Ducasse 2013 0.75 France 2.50
96 Ara 2014 0.72 France 2.50
130 Artisan du Chocolat 2009 0.75 U.K. 2.50
132 Artisan du Chocolat 2009 0.72 U.K. 1.75

>>>df1.set_index(['Review Date','Company Location'],inplace=True)
>>>df1.sort_index(inplace=True)
>>>df1.sort_index(axis=1,inplace=True) # 可以省略这步
>>>exclusion = ['France','Canada','Amsterdam','Belgium']
>>>idx = pd.IndexSlice
>>>print(df1.loc[idx[2012:,~df1.index.get_level_values(1).isin(exclusion)],:])
Cocoa Percent Company Rating
Review Date Company Location
2012 Australia 0.70 Bahen & Co. 3.00
Australia 0.70 Bahen & Co. 2.50
Australia 0.70 Bahen & Co. 2.50
Australia 0.75 Cravve 3.25
Australia 0.65 Cravve 3.25
... ... ... ...
2017 U.S.A. 0.70 Spencer 3.75
U.S.A. 0.70 Spencer 3.50
U.S.A. 0.70 Spencer 2.75
U.S.A. 0.70 Xocolla 2.75
U.S.A. 0.70 Xocolla 2.50
[972 rows x 3 columns]
这里可以不用对列索引排序,因为取值不需要考虑列索引,但为了培养我排序的习惯,我还是都排一下吧,无大碍~
然后Index对象的get_level_values方法可以获取该层所有索引值。