集合,Linq-C#
抛砖引玉
在讲集合之前,先来看看他的表亲 数组
int[] a = new int[10];
通过这样的语句,我们声明了一个int数组,长度为10.
但是数组有个问题.如果这个数组未来根据业务需要要改变长度,添加新的数据进去,那么这个数组根本不成立了!因为数组不允许修改长度!
你还有一种极端的方法选择,那就是
Array.Resize(ref a,15);
Array.Resize方法首先会创建一个长度为15的数组,把原来的数组赋值给新数组,然后把原来的数组给删了!这意味着如果有什么代码在运行时监测原来的数组或者运用原来的数组,他就会出bug.
针对这个不可变性,在早期版本C#给出了一个解决方案是 ArrayList
ArrayList a = new ArrayList(10);
ArrayList是个类,但是他有点特殊,他是个集合类.全称非泛型集合类.但是我们先把专业术语抛开,来看看他有什么作用.
a.Add(99);
a.Add(99.99);
a.Add("99.99.99");
a.Add(1);
a.Remove(1);
通过ArrayList声明的集合可以随意修改,动态的增加集合长度.但是通过观察上面的操作又可以发现一个很严重的问题,那就是通过ArrayList声明的集合什么类型的数据都吃.这意味如果我不小心往里面加了一个不同类型的数据,我那些只针对一种数据类型操作的方法全部GG.
所以,数组很安全,但是他不能修改.ArrayList可以修改,但是他不安全.有什么东西可以兼具两者的优点呢?
答案就是
有个东西叫List
List
在使用List
List<int> a = new List<int>();
我想要什么类型的集合直接修改T就变成我想要的集合了.
同时List提供了一堆方法来支持增删改查.
但是我不打算在这里先展开来说他,我们来说些其他的.
集合初始化器
集合初始化器就是List vs = new List() { }后面的大括号,用法举例
List<Employee> vs = new List<Employee>()
{
new Employee(){ id = 1,name = "LittleA",salary = "High",child = 0},
new Employee(){ id = 2,name = "LittleB",salary = "Low",child = 3},
new Employee(){ id = 3,name = "LittleC",salary = "High",child = 1},
new Employee(){ id = 4,name = "LittleD",salary = "Medium",child = 2},
new Employee(){ id = 5,name = "LittleE",salary = "High",child = 0},
new Employee(){ id = 6,name = "LittleF",salary = "Low",child = 1},
};
虽然我在这里没有给出Employee类是怎样的,但这不重要,重要的是在一开始声明集合的时候传输数据用的东西就叫集合初始化器,也就是List()后面的{}.
自定义集合-遍历问题
实现了IEnumerable
我本来写了一大堆来讲解为什么,但发现我怎么讲都讲不好,但是MSDN里有个地方讲的很好
https://docs.microsoft.com/zh-cn/dotnet/api/system.collections.stack.getenumerator?view=netcore-3.1#System_Collections_Stack_GetEnumerator
同时该视频讲解了该问题https://www.bilibili.com/video/BV1J7411F7cZ?t=921&p=13
还有这个youtube视频(全英)https://www.youtube.com/watch?v=V-APRrWz_3o
但是我觉得,不必花时间了解这些细枝末节,我们只需要知道,我们有字典,哈希表,List等好用又强大的集合就行了.
标准查询运算符-Linq
如果要创建一个自定义集合就需要继承IEnumerable
扩展方法不知道什么意思?读读这个https://blog.csdn.net/XiuGaiZhong/article/details/105975852
Linq全名Language Integrated Query,译名标准查询运算符,读作英文Link,中文拟音林克.
为讲解后面的例子,我选择采用C#本质论里的例子,他的例子比较全面,而且更能体现Linq的用法.
namespace AddisonWesley.Michaelis.EssentialCSharp.Chapter15.Listing15_09
{
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
Print(patents);
Console.WriteLine();
IEnumerable<Inventor> inventors = PatentData.Inventors;
Print(inventors);
}
private static void Print<T>(IEnumerable<T> items)
{
foreach (T item in items)
{
Console.WriteLine(item);
}
}
}
public class Patent
{
// Title of the published application
public string Title { get; set; }
// The date the application was officially published
public string YearOfPublication { get; set; }
// A unique number assigned to published applications
public string ApplicationNumber { get; set; }
public long[] InventorIds { get; set; }
public override string ToString()
{
return $"{ Title } ({ YearOfPublication })";
}
}
public class Inventor
{
public long Id { get; set; }
public string Name { get; set; }
public string City { get; set; }
public string State { get; set; }
public string Country { get; set; }
public override string ToString()
{
return $"{ Name } ({ City }, { State })";
}
}
public static class PatentData
{
public static readonly Inventor[] Inventors = new Inventor[]
{
new Inventor()
{
Name = "Benjamin Franklin",
City = "Philadelphia",
State = "PA",
Country = "USA",
Id = 1
},
new Inventor()
{
Name = "Orville Wright",
City = "Kitty Hawk",
State = "NC",
Country = "USA",
Id = 2
},
new Inventor()
{
Name = "Wilbur Wright",
City = "Kitty Hawk",
State = "NC",
Country = "USA",
Id = 3
},
new Inventor()
{
Name = "Samuel Morse",
City = "New York",
State = "NY",
Country = "USA",
Id = 4
},
new Inventor()
{
Name = "George Stephenson",
City = "Wylam",
State = "Northumberland",
Country = "UK",
Id = 5
},
new Inventor()
{
Name = "John Michaelis",
City = "Chicago",
State = "IL",
Country = "USA",
Id = 6
},
new Inventor()
{
Name = "Mary Phelps Jacob",
City = "New York",
State = "NY",
Country = "USA",
Id = 7
},
};
public static readonly Patent[] Patents = new Patent[]
{
new Patent()
{
Title = "Bifocals",
YearOfPublication = "1784",
InventorIds = new long[] { 1 }
},
new Patent()
{
Title = "Phonograph",
YearOfPublication = "1877",
InventorIds = new long[] { 1 }
},
new Patent()
{
Title = "Kinetoscope",
YearOfPublication = "1888",
InventorIds = new long[] { 1 }
},
new Patent()
{
Title = "Electrical Telegraph",
YearOfPublication = "1837",
InventorIds = new long[] { 4 }
},
new Patent()
{
Title = "Flying Machine",
YearOfPublication = "1903",
InventorIds = new long[] { 2, 3 }
},
new Patent()
{
Title = "Steam Locomotive",
YearOfPublication = "1815",
InventorIds = new long[] { 5 }
},
new Patent()
{
Title = "Droplet Deposition Apparatus",
YearOfPublication = "1989",
InventorIds = new long[] { 6 }
},
new Patent()
{
Title = "Backless Brassiere",
YearOfPublication = "1914",
InventorIds = new long[] { 7 }
},
};
}
}
整个程序被分为三个部分,Patent和Inventor类用来定义存放什么数据和怎么处理数据,PatentData用来实际传输数据,注意他是只读的.Main方法现在是把数据集合包装成IEnumerable
Where()
Where()用来查找指定的数据,消掉不符合条件的数据,返回一个新的集合.在该例中例如我想找到所有1900年以上的专利(专利的英文是Patent).
public static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
patents = PatentData.Patents.Where(p => p.YearOfPublication.ToInt() > 1900);
Print(patents);
}
如果你不知道为什么PatentData.Patents为什么可以使用Linq,那是因为有一句 类[] 变量名 = new 类[] 使之变成了集合类.
Where()方法有一个参数,那就是一个Func<>委托.(不清楚Func<>委托请看https://blog.csdn.net/XiuGaiZhong/article/details/106276131)这个委托的第一个泛型参数已经被确定是Patent了,因为编译器看你是在PatentData.Patents的基础上调用了该方法,就偷偷的帮你指定好了泛型类型.委托的返回值是bool.这个委托的含义就是叫你传一个判断方法用于查找数据.
这里我传的方法采用了lambda表达式(不清楚lambda看https://blog.csdn.net/XiuGaiZhong/article/details/106272513).参数p的类型是Patent,因为委托的参数类型已经被确定是Patent了,故lambda表达式也能确定该参数是Patent类型.YearOfPublication是Patent类里的字段,ToInt()是我在《this与base关键字-C#》写过的扩展方法,作用是将一个字符串直接转化为数字.整个lambda表达式的意思就是把年份转化为数字并与1900进行比较,匹配正确的结果则返回到patents里.
这句话的逻辑应该是这样的
foreach (Patent p in PatentData.Patents)
{
if (p.YearOfPublication.ToInt()>1900)
{
patents += p;
}
}
但是不能运行噢!请注意,这只是Where的逻辑,用于给你帮助理解.
Print方法是该例提供用于遍历集合并打印的方法.同样因为参数的类型使该方法的泛型被隐式声明了.
结果:

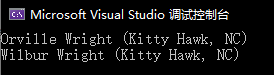
现在要求查找发明家里城市既处于Kitty Hawk,国家又在USA的,该怎么做
public static void Main()
{
IEnumerable<Inventor> patents = PatentData.Inventors;
patents = PatentData.Inventors.Where(x => x.City == "Kitty Hawk" && x.Country == "USA");
Print(patents);
}
基本思路没有变.因为要求同时匹配两个目标,所以添加了一个逻辑运算符&&.如果你忘了&&是什么意思,他的意思是 和.和代表着如果左边为true而且右边也为true时,他返回一个true.
结果:
Orderby() Thenby()
当你要对一个集合进行排序的时候就可以使用Orderby().Sort()也可以完成排序,但是他有一个很严重的问题就是我该按照什么东西进行排序.Sort()对于一个例如全是数字,全是字母的集合可以轻松完成排序,但若是一个类,例如该例的Patent,我到底是该按照名字排序,还是公开日期排序?Sort()他根本不知道也没法知道啊.
对于这种需要人为指定排序逻辑的问题,我们有Orderby().
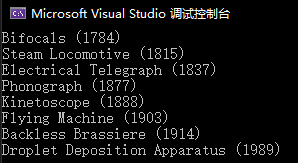
现在要求对专利排序,顺序为升序,按照专利的公开日期排序.
public static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
patents = PatentData.Patents.OrderBy(x => x.YearOfPublication);
Print(patents);
}
OrderyBy要求指定一个方法来告诉该按照哪个属性来排序,为了按照专利的公开日期排序,那当然是x.YearOfPublication. x.YearOfPublication就代表Patents的YearOfPublication.
结果:
现在要求对Inventor排序,按照id排序,顺序为降序
Orderby有个降序排序的兄弟叫OrderByDescending.Descending的意思是降序.
public static void Main()
{
IEnumerable<Inventor> inventors = PatentData.Inventors;
inventors = inventors.OrderByDescending(x => x.Id);
Print(inventors);
}
结果:

如果要先进行id排序再进行名称排序怎么办?这时候就要用到ThenBy()了.ThenBy()的作用也是排序,但是他需要跟在Orderby后面.例如第一次排序里有id里有两个相同的,Orderby没处理好,Thenby就接着处理那两个没处理好的数据
顺便一提,Thenby也有个降序排序的兄弟叫ThenbyDescending.
inventors = PatentData.Inventors.OrderByDescending(x => x.Id).ThenBy(x => x.Name);
由于数据比较特殊,没能体现出Thenby的作用,但是大家只要理解作用就行.
这种两个方法写在一行的书写方式叫做链式书写,从左往右顺序执行.
Select()
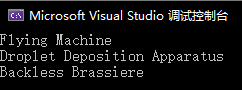
在找到所有1900年以上的专利之后,我只想要这些专利的名字,该怎么做?
Select()就可以做到这点.现在Patent里有四个属性,Title,YearOfPublication,ApplicationNumber和InventorIds.如果只需要某个属性的数据,用Select()就可以选择了.
IEnumerable<Patent> patents = PatentData.Patents;
patents = PatentData.Patents.Where(p => p.YearOfPublication.ToInt() > 1900);
IEnumerable<string> author;
author = patents.Select(x => x.Title);
Print(author);
我在Select里的lambda表达式表明我只需要Title这个属性的数据,现在author这个变量就只有author的集合了.
结果:
Select()的作用专业说法是将序列中的每个元素投影到新表单.我们来看看C#本质论里对Select运用更灵活的例子
public static void Main()
{
string rootDirectory = Directory.GetCurrentDirectory();
string searchPattern = "*";
IEnumerable<string> fileList = Directory.EnumerateFiles(
rootDirectory, searchPattern);
IEnumerable<(string FileName, long Size)> items = fileList.Select(
file =>
{
FileInfo fileInfo = new FileInfo(file);
return (
FileName: fileInfo.Name,
Size: fileInfo.Length
);
});
Print(items);
}
这段程序用到了文件操作,我就粗略的讲讲这段程序干了什么.他首先取得了某个文件夹里的所有文件路径的集合.然后把这些文件路径拆分成文件名和文件大小并返回了一个新的集合.这就是Select的强大之处,他向原来的集合添加了新的属性,还转化了原集合里属性的类型.原本是string path的集合,变成了string name+long size的集合.
Where加Select,是不是有点像Excel操作呢.
Count()
count是计数的意思,count()顾名思义就是计数器方法.
现在要求取得专利里所有19世纪公布专利总和,怎么做?
public static void Main()
{
IEnumerable<Patent> patents = PatentData.Patents;
int Sum = patents.Count(x => x.YearOfPublication.StartsWith("18"));
Console.WriteLine(Sum);
}
StartsWith是一个String类方法,作用是如果开头的几个字符匹配参数就返回true,否则false.Count方法对集合进行了遍历然后自增计数器,最后返回的结果是

推迟执行
由于Linq的参数基本都是委托,lambda在定义的时候不是先出发的,而是传给委托,委托传给Linq,Linq被调用,然后lambda才被调用的.很简单的概念.
Join
讲到这里我们需要换个新的案例
(还是C#本质论的)
namespace AddisonWesley.Michaelis.EssentialCSharp.Chapter15.Listing15_19
{
using System;
using System.Collections.Generic;
using System.Linq;
public class Program
{
public static void Main()
{
}
}
public class Department
{
public long Id { get; set; }
public string Name { get; set; }
public override string ToString()
{
return Name;
}
}
public class Employee
{
public int Id { get; set; }
public string Name { get; set; }
public string Title { get; set; }
public int DepartmentId { get; set; }
public override string ToString()
{
return $"{ Name } ({ Title })";
}
}
public static class CorporateData
{
public static readonly Department[] Departments =
new Department[]
{
new Department()
{
Name = "Corporate",
Id = 0
},
new Department()
{
Name = "Human Resources",
Id = 1
},
new Department()
{
Name = "Engineering",
Id = 2
},
new Department()
{
Name = "Information Technology",
Id = 3
},
new Department()
{
Name = "Philanthropy",
Id = 4
},
new Department()
{
Name = "Marketing",
Id = 5
},
};
public static readonly Employee[] Employees = new Employee[]
{
new Employee()
{
Name = "Mark Michaelis",
Title = "Chief Computer Nerd",
DepartmentId = 0
},
new Employee()
{
Name = "Michael Stokesbary",
Title = "Senior Computer Wizard",
DepartmentId = 2
},
new Employee()
{
Name = "Brian Jones",
Title = "Enterprise Integration Guru",
DepartmentId = 2
},
new Employee()
{
Name = "Anne Beard",
Title = "HR Director",
DepartmentId = 1
},
new Employee()
{
Name = "Pat Dever",
Title = "Enterprise Architect",
DepartmentId = 3
},
new Employee()
{
Name = "Kevin Bost",
Title = "Programmer Extraordinaire",
DepartmentId = 2
},
new Employee()
{
Name = "Thomas Heavey",
Title = "Software Architect",
DepartmentId = 2
},
new Employee()
{
Name = "Eric Edmonds",
Title = "Philanthropy Coordinator",
DepartmentId = 4
}
};
}
}
观察数据,我们可以推断出Employee的DepartmentId与Department的Id是对应的.问题是,既然他们是对应的,那怎么通过这层关系来使两个集合合并在一起并得到我们想要得列表?Join()可以办到这一点.
public static void Main()
{
IEnumerable <Department> departments = CorporateData.Departments;
IEnumerable<Employee> employees = CorporateData.Employees;
var items = departments.Join
(employees,
x => x.Id,
y => y.DepartmentId,
(x,y)=>(x.Name,y.Name,y.Title)
);
foreach (var item in items)
{
Console.WriteLine(item);
}
}
前两句应该没什么好讲了吧.从第三条语句开始就有所改变了.首先我用var来声明数据类型,让编译器智能感知,如果我不用var会变成怎么样?来看看

按照书写习惯我们都是先写类型再写后面的语句,如果我先想好写什么类型就要先想好要接收怎样的返回值.然后就在无谓的地方上浪费了很多时间,用var隐式声明变量轻松搞定.
Join有很多参数,第一个参数的意思是要和什么类进行连接,department当然要与employee连接.第二个参数是委托,意思是叫你指定Department的哪个属性是关键属性,第三个也是委托,意思是叫你指定Employee的哪个属性是关键属性.从逻辑上我们能观察出Id和DepartmentId应该是相等关系,所以指定这两个属性.最后一个参数与Select的参数类似,叫你指定哪些东西组成新的集合.
然后这个Join就把两个列表里的成员进行匹配,如果发现有Department.Id与Employee.DepartmentId有相等的,就会返回Department.Name,Employee.Name和Employee.Title.
最后一个foreach用于打印结果:
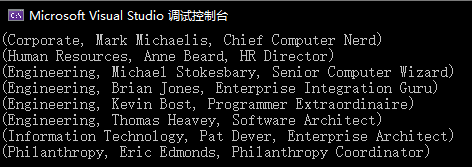
可以清晰的看到哪个人是哪个部门的.
GroupBy()
如果我们想把雇员按照部门进行分组该怎么做?使用GroupBy()方法就行了.
public static void Main()
{
IEnumerable <Department> departments = CorporateData.Departments;
IEnumerable<Employee> employees = CorporateData.Employees;
var items = departments.Join
(employees,
x => x.Id,
y => y.DepartmentId,
(x,y)=>(x.Name,y.Name,y.Title)
);
var itemGroup = items.GroupBy(x => x.Item1);
foreach (var item in itemGroup)
{
Console.WriteLine();
foreach (var x in item)
{
Console.WriteLine(x);
}
Console.WriteLine(item.Count());
}
}
对上个例子的结果执行了GroupBy.GroupBy的参数很简单,就是指定一个方法,告诉GroupBy按照什么进行分组.x.Item1代表着上例的x.Name,也就是Department.Name.为什会变成Item1是因为我在上例的lambda里没有明确的指定名字,所以编译器自动编了个名字叫Item1.
注意GroupBy返回的东西是个俄罗斯套娃,集合里面套着集合,所以需要一个双重循环来输出里面的实际内容.
结果:

GroupJoin
GroupJoin很像是Group和Join的结合版,但又不是.
public static void Main()
{
IEnumerable <Department> departments = CorporateData.Departments;
IEnumerable<Employee> employees = CorporateData.Employees;
var items = departments.GroupJoin
(employees,
x => x.Id,
y => y.DepartmentId,
(x, y) => (x.Id, x.Name, y)
);
foreach (var item in items)
{
Console.WriteLine(item.Name+" "+item.Id);
foreach (var x in item.y)
{
Console.WriteLine("\t"+x);
}
}
}

这里最大的问题在于到底是按照什么逻辑分组的.可惜我也不知道答案,也没有人解释这一点.
ToList()
实际中List
没啥案例,字面意思应该就懂了吧.
查询表达式-Linq
查询表达式版的Linq是语言更简洁更易懂的Linq方法.不再需要一个方法里写这个那个lambda表达式.让我们来看看例子
from in where select
public static void Main()
{
var employees = CorporateData.Employees;
var employee = from item in employees
where item.DepartmentId == 2
select item.Name;
foreach (var x in employee)
{
Console.WriteLine(x);
}
}
from in相当于foreach,让item去遍历employees这个集合,where后面的是个布尔判断,意思是找部门ID有没有等于2的人,如果有就select他的名字.

这就是部门id为2的人的名字,这种Linq是不是很好懂很好写?
我这里就不多讲这种Linq了,如果有兴趣了解可以百度.
Linq 101 Samples
2020年了,微软官方给出了Linq的案例供大家理解学习,以dotnet try的方式.
首先要安装.Net Core SDK 3.0https://dotnet.microsoft.com/download/dotnet-core/3.0
然后cmd运行 dotnet tool install --global dotnet-try 安装dotnet try工具
最后下载案例https://github.com/dotnet/try-samples#basics根据该github页面的指示打开案例
最后就可以在本地打开一个网页.
Dictionary与HashTable
Dictionary
Dictionary<int, string> testDictionary = new Dictionary<int, string>();
testDictionary.Add(1, "abandon");
testDictionary.Add(2, "ability");
testDictionary.Add(3, "able");
foreach (var a in testDictionary)
{
Console.WriteLine($"Dictionary's key is {a.Key} and value is {a.Value}");
}
结果:

字典(Dictionary)是一个泛型集合.哈希表(HashTable)则是非泛型集合,他和字典的功能基本相似,不同的是哈希表可以存任意类型的值.
另外字典与哈希表都要求键不重复.这种键值表虽然麻烦,但是好处是查找值的速度非常快.