python_day7_画图

json数据与python字典的相互转换
import json
列表,其中每个元素均为一个字典
data = [{"name": "张三", "age": 10},
{"name": "李四", "age": 13},
{"name": "jay", "age": 17}]
json.dumps()P:将列表转为json,解决中文乱码:ensure_ascii=False
json_str = json.dumps(data, ensure_ascii=False)
print(json_str)
print(f"数据类型为:{type(json_str)}")

将字典转为json数据
d = {"name": "java", "score": 90}
json_str = json.dumps(d)
print(json_str)
print(type(json_str))

json.loads():将json转为python数据类型
j_str = '[{"name": "张三", "age": 10}, {"name": "李四", "age": 13}, {"name": "jay", "age": 17}]'
list_j = json.loads(j_str)
print(list_j)
print(type(list_j))
j_str = '{"name": "java", "score": 90}'
dict_j = json.loads(j_str)
print(dict_j)
print(type(dict_j))

画一个简易折线图
# 导包
from pyecharts.charts import Line
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts
# 创建一个折线图对象
line = Line()
# 给折线图添加X轴数据
line.add_xaxis(['中国', 'USA', '不列颠'])
# 添加Y轴坐标
line.add_yaxis("GDP", [30, 20, 10])
# 设置全局配置
line.set_global_opts(
title_opts=TitleOpts(title='GDP展示',pos_left="center",pos_bottom="1%"), # 注意此处逗号
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True)
)
# 通过render()方法,将代码生成图像
line.render()

案例实战
绘制疫情数据折线图


json格式化,查看数据层级

导包
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts, LegendOpts, ToolboxOpts, VisualMapOpts
灵活使用print语句查看数据
数据准备
f_us = open("D:/美国.txt", "r", encoding="utf-8")
f_jp = open("D:/日本.txt", "r", encoding="utf-8")
f_in = open("D:/印度.txt", "r", encoding="utf-8")
us_data = f_us.read()
jp_data = f_jp.read()
in_data = f_in.read()
去除不合json规范的开头,也可以使用index(“{”)获取第一个左大括号索引,然后切片
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.strip("jsonp_1629350871167_29498(")
in_data = in_data.strip("jsonp_1629350745930_63180(")
去除不合json规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# print(in_data)
# print(type(in_data))
将json数据转为字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# print(in_dict)
# print(type(in_dict))
获取key:trend对应的value
# print(us_dict["data"][0]["trend"]["updateDate"])
us_trend_data = us_dict["data"][0]["trend"]
jp_trend_data = jp_dict["data"][0]["trend"]
in_trend_data = in_dict["data"][0]["trend"]
# print(in_trend_data)
# print(type(in_trend_data))
获取日期数据,作x轴(取2020年)
us_x_data = us_trend_data["updateDate"][:314]
jp_x_data = jp_trend_data["updateDate"][:314]
in_x_data = in_trend_data["updateDate"][:314]
# print(in_x_data)
获取确诊数据,作y轴(取2020年)
us_y_data = us_trend_data["list"][0]["data"][:314]
jp_y_data = jp_trend_data["list"][0]["data"][:314]
in_y_data = in_trend_data["list"][0]["data"][:314]
# print(us_y_data)
制作图表
line = Line()
添加x轴数据
line.add_xaxis(us_x_data)
# line.add_xaxis(jp_x_data)
# line.add_xaxis(in_x_data)
添加y轴数据。注意y轴数据写法!!!!!
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 写在最后为系列选项
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False))
设置全局选项
line.set_global_opts(
# 标题
title_opts=TitleOpts(title="2020年美日印确诊人数折线图", pos_bottom="1%", pos_left="center"), # 注意此处逗号
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
# visualmap_opts=VisualMapOpts(is_show=False)
)
通过render()方法,将代码生成图像
line.render()
关闭文件
f_us.close()
f_jp.close()
f_in.close()
效果图
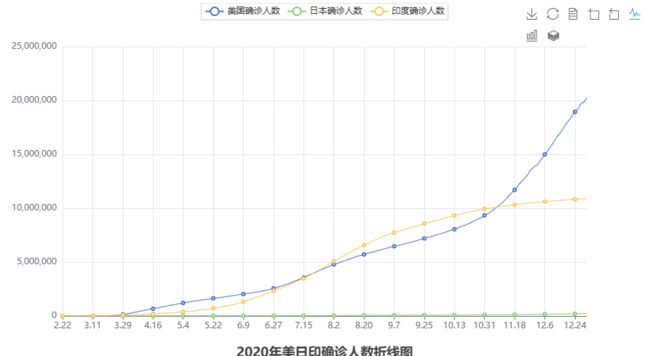
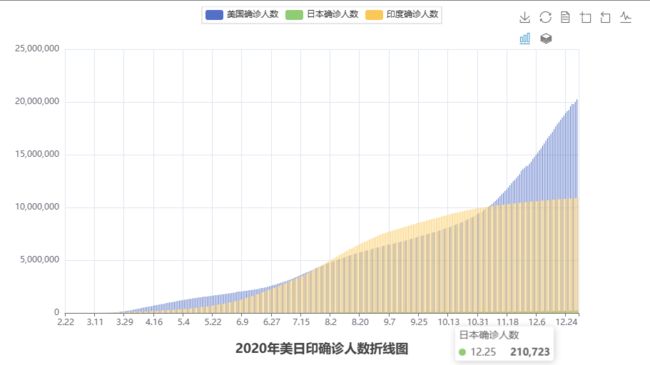

PS:完整代码
# 处理数据
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts, LegendOpts, ToolboxOpts, VisualMapOpts
f_us = open("D:/美国.txt", "r", encoding="utf-8")
f_jp = open("D:/日本.txt", "r", encoding="utf-8")
f_in = open("D:/印度.txt", "r", encoding="utf-8")
us_data = f_us.read()
jp_data = f_jp.read()
in_data = f_in.read()
# 去除不合json规范的开头,也可以使用index("{")获取第一个左大括号索引,然后切片
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.strip("jsonp_1629350871167_29498(")
in_data = in_data.strip("jsonp_1629350745930_63180(")
# 去除不合json规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# print(in_data)
# print(type(in_data))
# 将json数据转为字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# print(in_dict)
# print(type(in_dict))
# 获取key:trend对应的value
# print(us_dict["data"][0]["trend"]["updateDate"])
us_trend_data = us_dict["data"][0]["trend"]
jp_trend_data = jp_dict["data"][0]["trend"]
in_trend_data = in_dict["data"][0]["trend"]
# print(in_trend_data)
# print(type(in_trend_data))
# 获取日期数据,作x轴(取2020年)
us_x_data = us_trend_data["updateDate"][:314]
jp_x_data = jp_trend_data["updateDate"][:314]
in_x_data = in_trend_data["updateDate"][:314]
# print(in_x_data)
# 获取确诊数据,作y轴(取2020年)
us_y_data = us_trend_data["list"][0]["data"][:314]
jp_y_data = jp_trend_data["list"][0]["data"][:314]
in_y_data = in_trend_data["list"][0]["data"][:314]
# print(us_y_data)
# 制作图表
line = Line()
# 添加x轴数据
line.add_xaxis(us_x_data)
# line.add_xaxis(jp_x_data)
# line.add_xaxis(in_x_data)
# 添加y轴数据。注意y轴数据写法!!!!!
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 写在最后为系列选项
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False))
# 设置全局选项
line.set_global_opts(
# 标题
title_opts=TitleOpts(title="2020年美日印确诊人数折线图", pos_bottom="1%", pos_left="center"), # 注意此处逗号
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
# visualmap_opts=VisualMapOpts(is_show=False)
)
# 通过render()方法,将代码生成图像
line.render()
# 关闭文件
f_us.close()
f_jp.close()
f_in.close()