043、TiDB特性_缓存表和分区表
针对于优化器在索引存在时依然使⽤全表扫描的情况下,使⽤缓存表和分区表是提升查询性能的有效⼿段。

缓存表
- 缓存表是将表的内容完全缓存到 TiDB Server 的内存中
- 表的数据量不⼤,⼏乎不更改
- 读取很频繁
- 缓存控制: ALTER TABLE table_name CACHE|NOCACHE;
# 使用trace跟踪下
tidb> TRACE SELECT * FROM test.c1;
+-------------------------------------------+-----------------+---
---------+
| operation | startTS |
duration |
+-------------------------------------------+-----------------+---
---------+
| trace | 18:39:25.485266 |
501.582µs |
| ├─session.ExecuteStmt | 18:39:25.485270 |
432.208µs |
| │ ├─executor.Compile | 18:39:25.485281 |
132.616µs |
| │ └─session.runStmt | 18:39:25.485433 |
249.488µs |
| │ └─UnionScanExec.Open | 18:39:25.485572 |
72.776µs |
| │ ├─TableReaderExecutor.Open | 18:39:25.485575 |
13.24µs |
| │ ├─buildMemTableReader | 18:39:25.485605 |
3.283µs |
| │ └─memTableReader.getMemRows | 18:39:25.485615 | # memTableReader.getMemRows 表示从缓存取数
20.558µs |
| ├─*executor.ProjectionExec.Next | 18:39:25.485712 |
12.911µs |
| │ └─*executor.UnionScanExec.Next | 18:39:25.485714 |
3.823µs |
| └─*executor.ProjectionExec.Next | 18:39:25.485733 |
8.943µs |
| └─*executor.UnionScanExec.Next | 18:39:25.485735 |
1.33µs |
+-------------------------------------------+-----------------+---
---------+
12 rows in set (0.00 sec)
小表缓存-原理

缓存租约
-
租约时间内,无法进行写操作
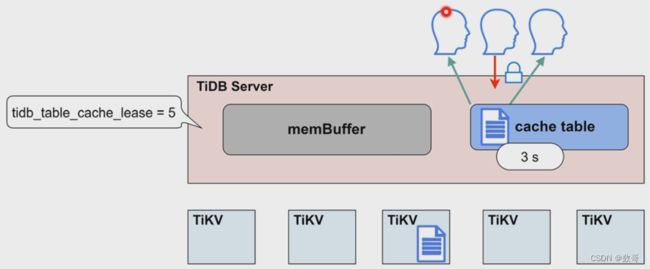
-
租约到期,数据过期
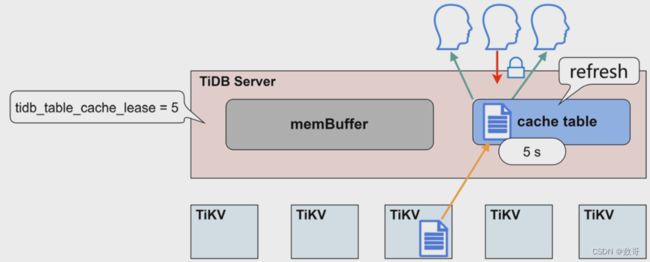
-
写操作不再被阻塞
-
读写直接到TiKV节点上执行

-
数据更新完毕,租约继续开启
应用场景
- 每张缓存表的大小限制为64MB
- 适用于查询频繁、数据量不大、修改极少的场景
- 在租约(tidb_table_cache_lease) 时间内,写操作会被阻塞
- 当租约到期(tidb_table_cache_lease)时,读性能会下降
- 不支持对缓存表直接做DDL操作,需要先关闭
- 对于表加载较慢或者极少修改的表,可以适当延长tidb_table_cache_lease保持读性能稳定
分区表
分区类型与适用场景
- range: 分区剪裁,节省IO开销
- Hash: 用于大规模写入的情况下将数据打散,平均地分配到各个分区里
Range分区表
create table t1(x int) partition by name(x) (
partition p0 values less than(5),
partition p1 values less than (10));
)
分区类型与适⽤场景
- Range
分区裁剪, 节省 I/O 开销
/* Range Partition t1 */
drop table if exists test.t1;
create table test.t1 (x int) partition by range (x) (
partition p0 values less than (5),
partition p1 values less than (10));
insert into test.t1 values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
/* Check Partition Pruning */
explain select * from test.t1 where x between 1 and 4;
查看执行计划
mysql> explain select * from test.t1 where x between 1 and 4;
+-------------------------+-----------+-----------+------------------------+------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------+-----------+-----------+------------------------+------------------------------------+
| TableReader_9 | 12288.00 | root | | data:Selection_8 |
| └─Selection_8 | 12288.00 | cop[tikv] | | ge(test.t1.x, 1), le(test.t1.x, 4) |
| └─TableFullScan_7 | 491520.00 | cop[tikv] | table:t1, partition:p0 | keep order:false |
+-------------------------+-----------+-----------+------------------------+------------------------------------+
3 rows in set (0.03 sec)
/* Check regions */
show table test.t1 regions;
mysql> show table test.t1 regions;
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 5019 | t_79_ | t_80_ | 5020 | 1001 | 5020 | 0 | 0 | 0 | 67 | 877551 |
| 1002 | t_80_ | | 1003 | 1001 | 1003 | 0 | 0 | 0 | 24 | 421921 |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
2 rows in set (0.02 sec)
- Hash
可以⽤于⼤规模写⼊的情况下将数据打散, 平均地分配到各个分区⾥
/* Hash Partition t1 */
drop table if exists test.t1;
CREATE TABLE test.t1 (x INT)
PARTITION BY HASH(x)
PARTITIONS 4;
insert into test.t1 values (0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
insert into test.t1 select * from test.t1;
查看分区的执行计划
- 默认是通过mod方式分配分区
/* Check Partition Distribution */
explain select * from test.t1 where x=0;
explain select * from test.t1 where x=1;
explain select * from test.t1 where x=2;
explain select * from test.t1 where x=3;
explain select * from test.t1 where x=4;
explain select * from test.t1 where x=5;
explain select * from test.t1 where x=6;
explain select * from test.t1 where x=7;
explain select * from test.t1 where x=8;
explain select * from test.t1 where x=9;
/* Negative */
explain select * from test.t1 where x between 7 and 9;
mysql> explain select * from test.t1 where x between 7 and 9;
+------------------------------+----------+-----------+------------------------+------------------------------------+
| id | estRows | task | access object | operator info |
+------------------------------+----------+-----------+------------------------+------------------------------------+
| PartitionUnion_10 | 750.00 | root | | |
| ├─TableReader_13 | 250.00 | root | | data:Selection_12 |
| │ └─Selection_12 | 250.00 | cop[tikv] | | ge(test.t1.x, 7), le(test.t1.x, 9) |
| │ └─TableFullScan_11 | 10000.00 | cop[tikv] | table:t1, partition:p0 | keep order:false, stats:pseudo |
| ├─TableReader_16 | 250.00 | root | | data:Selection_15 |
| │ └─Selection_15 | 250.00 | cop[tikv] | | ge(test.t1.x, 7), le(test.t1.x, 9) |
| │ └─TableFullScan_14 | 10000.00 | cop[tikv] | table:t1, partition:p1 | keep order:false, stats:pseudo |
| └─TableReader_19 | 250.00 | root | | data:Selection_18 |
| └─Selection_18 | 250.00 | cop[tikv] | | ge(test.t1.x, 7), le(test.t1.x, 9) |
| └─TableFullScan_17 | 10000.00 | cop[tikv] | table:t1, partition:p3 | keep order:false, stats:pseudo |
+------------------------------+----------+-----------+------------------------+------------------------------------+
10 rows in set (12.69 sec)
查看region分布情况
/* Check regions */
# 查看对应的region情况,在4个region上
mysql> show table test.t1 regions;
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 9003 | t_84_ | t_85_ | 9004 | 1001 | 9004 | 0 | 18449249 | 14117466 | 13 | 141205 |
| 9005 | t_85_ | t_86_ | 9006 | 1001 | 9006 | 0 | 18443067 | 14024508 | 10 | 58475 |
| 9007 | t_86_ | t_87_ | 9008 | 1001 | 9008 | 0 | 12295360 | 8703102 | 5 | 27228 |
| 1002 | t_87_ | | 1003 | 1001 | 1003 | 0 | 12295959 | 9218671 | 4 | 26666 |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
4 rows in set (2 min 46.43 sec)