C++并发编程(4):共享数据的问题、使用互斥量保护共享数据、死锁
在线程间共享数据
参考博客
线程间共享数据——使用互斥量保护共享数据
[c++11]多线程编程(四)——死锁(Dead Lock)
c++多线程之死锁
C++ 死锁及解决办法
共享数据的问题
设想你有一段时间和朋友合租公寓,公寓只有一个厨房和一个浴室。除非你们的感情格外深厚,否则不可能同时使用浴室。另外,假若朋友占用浴室很久,而你恰好也需要,便会感到不方便。类似地,假设你们使用的是组合烤箱,尽管可以同时烹饪,但若一人要烤香肠,同时另一人却要烘蛋糕,结果应该不会太好。并且,我们也清楚共用办公空间的烦恼:事情还没做完,有人却借走了工作所需之物,或者半成品被别人擅自更改
线程亦如此。若在线程之间共享数据,我们需要遵循规范:具体哪个线程按何种方式访问什么数据;还有,一旦改动了数据,如果牵涉到其他线程,它们要在何时以什么通信方式获得通知。同一进程内的多个线程之间,虽然可以简单易行地共享数据,但这不是绝对的优势,有时甚至是很大的劣势。不正确地使用共享数据,是产生与并发有关的错误的一个很大的诱因,其后果远比“香肠口味的蛋糕”严重
恶性条件竞争
诱发恶性条件竞争的典型场景是,要完成一项操作,却需改动两份或多份不同的数据,如上例中的两个链接指针。因为操作涉及两份独立的数据,而它们只能用单独的指令改动,当其中一份数据完成改动时,别的线程有可能不期而访。因为满足条件的时间窗口短小,所以条件竞争往往既难察觉又难复现。若改动操作是由连续不间断的CPU指令完成的,就不太有机会在任何的单次运行中引发问题,即使其他线程正在并发访问数据。只有按某些次序执行指令才可能引发问题。随着系统负载加重及执行操作的次数增多,这种次序出现的机会也将增加。“屋漏偏逢连夜雨”几乎难以避免,且这些问题偏偏会在最不合时宜的情况下出现。恶性条件竞争普遍“挑剔”出现的时机,当应用程序在调试环境下运行时,它们常常会完全消失,因为调试工具影响了程序的内部执行时序,哪怕只影响一点点
使用互斥量保护共享数据
在访问共享数据前,开发者可使用互斥量将相关数据锁住,并于访问结束后将数据解锁。因此,线程库需要保证当一个线程使用特定互斥量锁住共享数据时,其他线程仅可在数据被解锁后才能访问
lock()、 unlock()上锁解锁
C++中通过实例化std::mutex创建互斥量,通过调用成员函数lock()进行上锁,unlock()进行解锁
在实际中必须成对使用,一旦在函数中用了lock,则在函数出口处必须调用unlock
mutex my_mutex;
int a = 1;
bool func()
{
my_mutex.lock();
if(!a)
{
cout << "a = " << a << endl;
my_mutex.unlock();
return false;
}
my_mutex.unlock();
return true;
}
注意上述代码在return前均调用了unlock
RAII std::lock_guard
C++标准库为互斥量提供了一个RAII语法的模板类std::lock_guard,其会在构造的时候提供已锁的互斥量,并在析构的时候进行解锁,从而保证了一个已锁的互斥量总是会被正确的解锁
mutex my_mutex;
int a = 1;
bool func()
{
lock_guard<mutex> my_guard(my_mutex);
// my_mutex.lock();
if(!a)
{
cout << "a = " << a << endl;
// my_mutex.unlock();
return false;
}
// my_mutex.unlock();
return true;
}
可以通过限制lock_guard的作用域来提前释放锁
mutex my_mutex;
int a = 1;
bool func()
{
// lock_guard my_guard(my_mutex);
// my_mutex.lock();
if (!a)
{
{
lock_guard<mutex> my_guard(my_mutex);
cout << "a = " << a << endl;
}
// my_mutex.unlock();
return false;
}
// my_mutex.unlock();
return true;
}
面向对象设计准则:将互斥量作为data member置于类中
需要注意的是,互斥量与要保护的数据在类中需要被定义为private成员,所有成员函数均需在调用时对数据上锁,结束时对数据解锁,如此则可保证数据不被破坏
现实情况并非总是如此理想,应该意识到,如果一个成员函数返回的是保护数据的指针或引用,那么就一定存在数据破坏的可能性,原因在于使用者可以通过引用或指针直接访问数据,从而绕开互斥量的保护。因此,如果一个类使用互斥量来保护自身数据成员,其开发者必须谨小慎微地设计接口,确保互斥量能锁住任何对数据的访问,并且不留后门
class some_data
{
int a;
std::string b;
public:
void do_something();
};
class data_wrapper
{
private:
some_data data;
std::mutex m;
public:
template<typename Function>
void process_data(Function func)
{
std::lock_guard<std::mutex> l(m);
func(data); // 1 传递“保护”数据给用户函数
}
};
some_data* unprotected;
void malicious_function(some_data& protected_data)
{
unprotected=&protected_data;
}
data_wrapper x;
void foo()
{
x.process_data(malicious_function); // 2 传递一个恶意函数
unprotected->do_something(); // 3 在无保护的情况下访问保护数据
}
看起来process_data没有任何问题,但调用用户自定义的func则意味着foo可以绕过保护机制将函数malicious_function传入,在没有互斥量锁定的情况下调用do_something
C++标准库并不能针对这种行为做出保护,因此必须谨记:切勿将受保护数据的指针或引用传递到互斥锁作用域之外
死锁
首先以一个最基本的例子来抽象什么是死锁:
面试官:“如果你能够讲清楚什么是死锁,我就给你发offer”
候选人:"如果你能够给我发offer,我就告诉你什么是死锁”
死锁是这样一种场景:存在一对线程,他们都需要执行一些操作,这些操作以锁住自己的互斥量作为开头,并且需要对方释放其持有的互斥量,在这种场景下没有线程能够正常工作,因为它们都在等待对方释放互斥量。当存在两个以上的互斥量锁定同一个操作时,死锁很容易发生
举个栗子,如果此时有一个线程A,按照先锁a,再锁b,而在此同时又有另外一个线程B,按照先锁b再锁a的顺序获得锁。如下图所示:
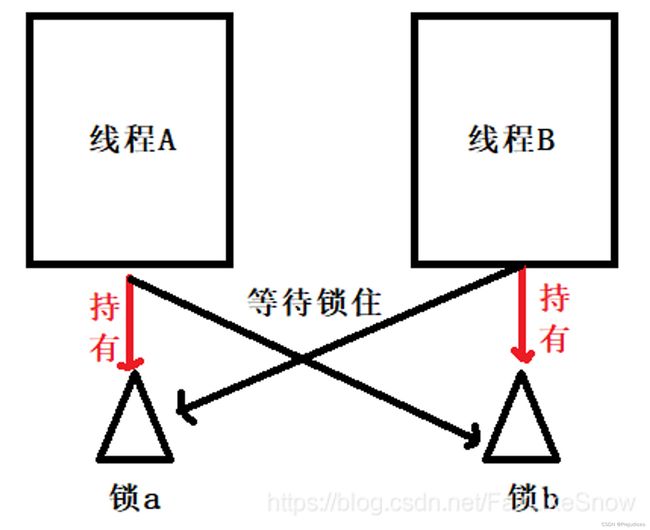
就如图这种情况下,线程A在等待锁b,可是锁b被锁住了,所以此时不能往下进行,需要等待锁b释放,而线程B先是锁住了锁b,在等待锁a的释放,这样就造成了线程A等线程B,线程B等待线程A,从而出现了死锁
#include 运行之后,你会发现程序会卡住,这就是发生死锁了。程序运行可能会发生类似下面的情况:
Thread A Thread B
_mu.lock() _mu2.lock()
//死锁 //死锁
_mu2.lock() _mu.lock()
常见的死锁情形
1、忘记释放锁
mutex _mutex;
void func()
{
_mutex.lock();
if (xxx)
return;
_mutex.unlock();
}
2、单线程重复申请锁
mutex _mutex;
void func()
{
_mutex.lock();
//do something....
_mutex.unlock();
}
void data_process() {
_mutex.lock();
func();
_mutex.unlock();
}
3、双线程多锁申请
mutex _mutex1;
mutex _mutex2;
void process1() {
_mutex1.lock();
_mutex2.lock();
//do something1...
_mutex2.unlock();
_mutex1.unlock();
}
void process2() {
_mutex2.lock();
_mutex1.lock();
//do something2...
_mutex1.unlock();
_mutex2.unlock();
}
4、环形锁申请
/*
* A - B
* | |
* C - D
*/
解决死锁的方法
1、可以比较mutex的地址,每次都先锁地址小的
如果硬性条件约束我们不得不获取多个锁并且不可使用std::lock,那么指导意见是在每一个线程中均保证以同样的顺序获取这些锁
if(&_mu < &_mu2){
_mu.lock();
_mu2.unlock();
}
else {
_mu2.lock();
_mu.lock();
}
2、尽量同时只对一个互斥锁上锁
{
std::lock_guard<std::mutex> guard(_mu2);
//do something
f << msg << id << endl;
}
{
std::lock_guard<std::mutex> guard2(_mu);
cout << msg << id << endl;
}
3、不要在互斥锁保护的区域使用用户自定义的代码,因为用户的代码可能操作了其他的互斥锁
{
std::lock_guard<std::mutex> guard(_mu2);
user_function(); // never do this!!!
f << msg << id << endl;
}
4、如果想同时对多个互斥锁上锁,要使用std::lock()
std::lock(_mu, _mu2);
5、使用层次锁
使用层次锁,将互斥锁包装一下,给锁定义一个层次的属性,每次按层次由高到低的顺序上锁
当代码试图执行上锁操作时,它会检查当前是否已持有来自低层次的锁,若有则禁止上锁当前互斥量
hierarchical_mutex high_level_mutex(10000);
hierarchical_mutex low_level_mutex(5000);
int do_low_level_stuff();
int low_level_func() {
std::lock_guard<hierarchical_mutex> lk(low_level_mutex);
return do_low_level_stuff();
}
void high_level_stuff(int some_param);
void high_level_func() {
std::lock_guard<hierarchical_mutex> lk(high_level_mutex);
high_level_stuff(low_level_func());
}
void thread_a() {
high_level_func();
}
hierarchical_mutex other_mutex(100);
void do_other_stuff();
void other_stuff() {
high_level_func();
do_other_stuff();
}
void thread_b() {
std::lock_guard<hierarchical_mutex> lk(other_mutex);
other_stuff();
}
thread_a遵守了层级规则,而thread_b没有。可以注意到,thread_a调用了high_level_func,因此高层级互斥量high_level_mutex被上锁,随后又试图去调用low_level_func,此时低层级互斥量low_level_mutex被上锁,这与上文提及的规则一致:先锁高层级再锁低层级
thread_b的运行则没有这么乐观,它先锁住了层级为100的other_mutex,并在之后试图去锁住高层级的high_level_mutex,此时会发生错误,可能会抛出一个异常,又或者直接终止程序